
Important Concepts in Optimization
Generalization
- how well the learned model will behave on unseen data
- 학습 데이터에 대해서 성능이 안좋으면 generalization perfomance가 좋다고 해서 test data에서의 성능이 좋다고 말할 수 없음
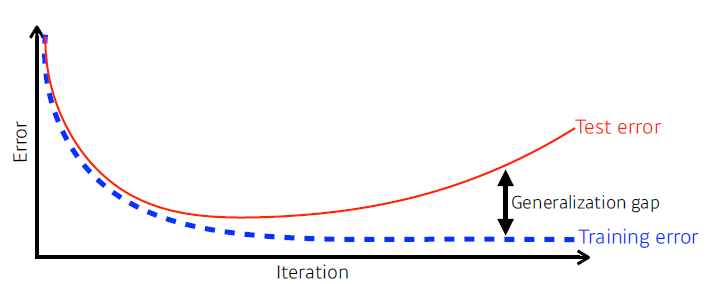
- 학습 데이터에 대해서 성능이 안좋으면 generalization perfomance가 좋다고 해서 test data에서의 성능이 좋다고 말할 수 없음
Under-fitting vs Over-fitting
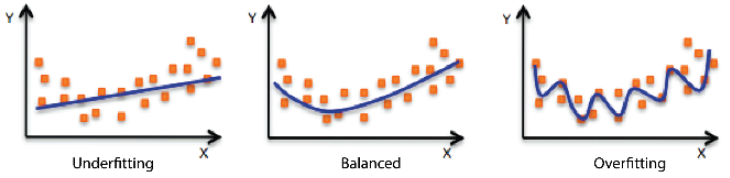
- overfitting: 학습데이터에서 잘 작동, 테스트데이터에서 잘 작동 X
Cross validation
- Cross-validation is a model validation technique for assessing how the model will generalize to an independent (test) data set.
- train과 validation data 나누기
- cross validation을 활용해 최적의 hyperparameter(learning rate, 네트워크의 크기, 어떤 loss function,,) set을 찾고, hyperparameter를 고정한 상태에서 모든 데이터를 전부 사용
- test data는 학습의 어떤 방법으로도 사용X
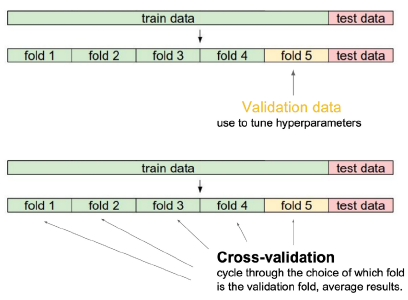
- test data는 학습의 어떤 방법으로도 사용X
Bias-variance tradeoff
-
underfitting과 overfitting
-
variance: 출력이 얼마나 일관적으로 나오는가 (탄착군)
- variance가 낮으면 보통 간단한 모델
- variance가 크면 비슷한 입력이 들어와도 출력이 많이 달라짐 > overfitting 가능성 up
-
bias: 비슷한 입력에 대해 크게 분산되더라도 평균적으로 정답에 근접
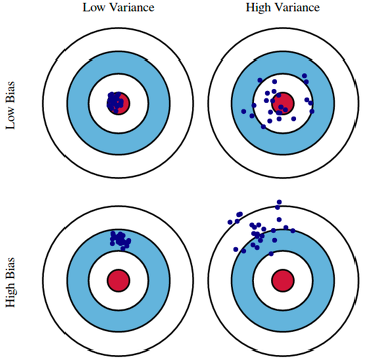
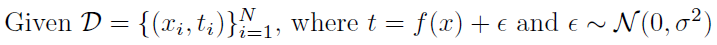
-
We can derive that what we are minimizing (cost) can be decomposed into three different parts: bias^2, variance, and noise.
-
내 학습 data에 noise가 껴 있다고 가정을 했을 때 내가 이 noise가 껴 있는 target data를 minimize하는 것은 3가지 파트로 나뉠 수 있음
- 내가 minimize 하는 값은 1개의 값이지만 이 값이 사실은 3가지 component로 이루어져 있음
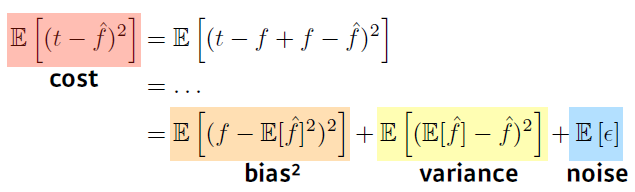
- 내가 minimize 하는 값은 1개의 값이지만 이 값이 사실은 3가지 component로 이루어져 있음
-
bias를 줄이게 되면 variance가 높아질 가능성이 커지고 반대의 상황도 동일
-
근본적으로 학습데이터에 noise가 껴 있을 경우에는 bias와 variance를 둘 다 줄일 수 있는건 얻기 힘듦.
Bootstrapping
- Bootstrapping is any test or metric that uses random sampling with replacement.
- 학습 데이터 전체 중 일부만 사용하여(subsampling) 여러개의 모델을 만듦
- 하나의 입력에 대해 각각의 모델이 다른 값 예측 가능
- 이 모델들이 예측하는 값들이 얼마나 일치를 이루는지 보고 전체적인 모델의 uncertainty를 예측하고자 함
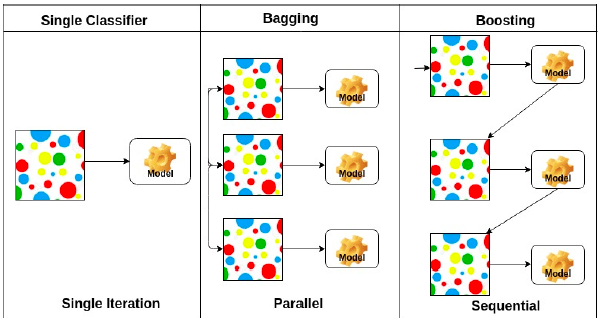
Bagging and boosting
- Bagging(Bootstrapping aggregating)
- Multiple models are being trained with bootstrapping.
- ex) Base classifiers are fitted on random subset where individual predictions are aggregated (voting or averaging).
- 일반적으로 앙상블이라고도 함
- Boosting
- It focuses on those specific training samples that are hard to classify.
- A strong model is built by combining weak learners in sequence where each learner learns from the mistakes of the previous weak learner.
- 간단한 모델을 만들어 80퍼가 잘 되고 20퍼가 잘 안되면 다음 모델은 20퍼가 잘 되도록 맞춰서 새로 go, 반복
Practical Gradient Descent Methods
Gradient Descent Methods
- Stochastic gradient descent
- Update with the gradient computed from a single sample.
- 한번에 하나의 data만 보고 gradient 구하고 update
- Mini-batch gradient descent
- Update with the gradient computed from a subset of data.
- Batch gradient descent
- Update with the gradient computed from the whole data.
- 모든것의 평균으로!
Batch-size Matters
- 한개를 쓰면 너무 오래걸리고 전체를 한번에 활용하자니 network GPU 모자라고
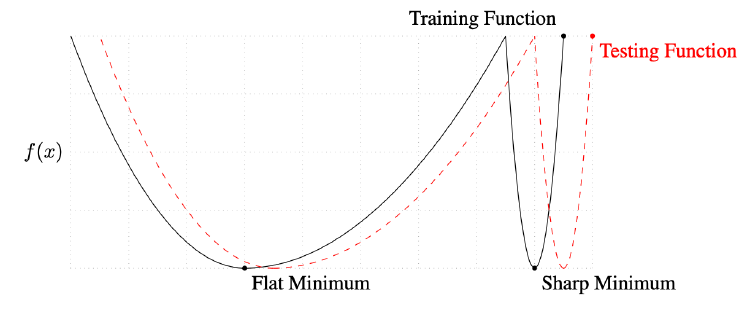
- "We ... present numerical evidence that supports the view that large batch methods tend to converge to sharp minimizers of the training and testing functions. In contrast, small-batch methods consistently converge to flat minimizers... this is due to the inherent noise in the gradient estimation."
-
batch size가 512, 1024처럼 크게 되면 sharp minimizer라는 것에 도달하게 됨
-
small batch size를 활용하게 되면 flat minimizer에 도달
-
batch size를 작게 쓰는 것이 좋다 (sharp보다 flat이 좋음)
-
testing function의 minimum을 찾고싶음!
-
flat minimizer는 generalizing performance가 높다
-
-
Gradient Descent Methods
(Stochastic) gradient descent
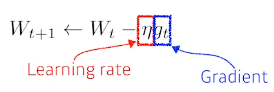
- step size(learning rate)를 잡는 것이 너무 어려움
Momentum: 관성
- 이전 방향을 이어가자
- gradient가 굉장히 왔다갔다해도 어느정도 잘 학습
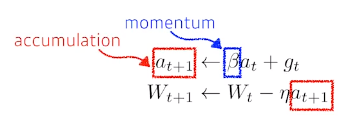
- hyperparameter 가 momentum을 잡게 되고 라고 불리우는 gradient가 현재 들어왔다면 다음(t+1번째)은 gradient 정보를 그냥 버리고 만 사용하는 것이 아니라 라고 불리우는 momentum에 해당하는 term이 그 값을 계속 가지고 있음
- momentum과 현재 gradient를 합친 accumulation으로 update를 시킴
Nesterov accelerated gradient
- NAG는 한 번 이동
- a라고 불리우는 현재 정보가 있으면 그 방향으로 가보고 그 간 곳에서 gradient를 계산한 것을 가지고 accumulation.
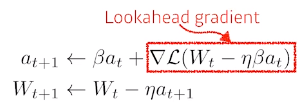
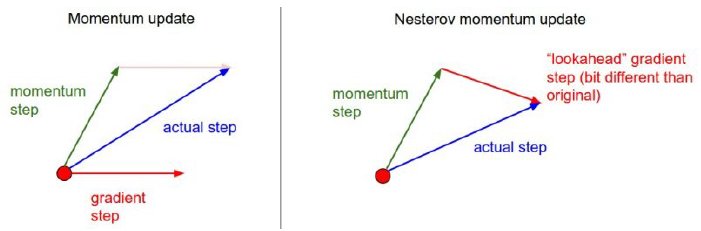
- momentum은 local minimum에 들어가야 되는데 계속 왔다갔다해서 local minimum에 쉽게 도달 X
- NAG는 한번 지나간 그 점에서 gradient를 계산하기 때문에 local minimum이 한쪽 아래로 흐름
- momemtum보다 NAG가 봉우리에 조금 더 빨리 도달할 수 있음
Adagrad
- Adagrad adapts the learning rate, performing larger updates for infrequent and smaller updates for frequent parameters.
- 뉴럴 네트워크의 파라미터가 얼만큼 지금까지 많이 변해왔는지(변하지 않았는지) 관찰
- 많이 변한 파라미터는 적게 변화시키고 안 변한 파라미터는 많이 변화시켜
- : 파라미터가 얼마나 변했는지 (Sum of gradient squares)
- 역수를 취해 많이 변하면 적게 변화시킴
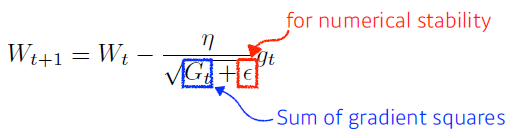
- but 가 계속 커지기 때문에 결국에는 이 가 무한대로 가게 되면 분모가 무한대가 되어 업데이트가 되지 않음
- 뒤로 가면 갈수록 학습이 멈추게 됨
Adadelta
- Adadelta extends Adagrad to reduce its monotonically decreasing the learning rate by restricting the accumulation window
- adagrad가 가지는 가 계속해서 커지는 현상을 막음
- 현재 time step 가 주어졌을 때 window size만큼의 파라미터, 시간에 대한 gradient의 변화를 봄
- window size가 관건. window size만큼 데이터를 가지고 있어야 해서 메모리에 무리
- exponential moving average를 통해 업데이트
- time window 만큼의 값을 저장하고 평균값을 갖고 있는 것처럼 볼 수 있음
- 현재 time step 가 주어졌을 때 window size만큼의 파라미터, 시간에 대한 gradient의 변화를 봄
- there is no learning rate in Adadelta
- 바꿀 수 있는 요소가 많이 없음
- 가 비슷한 역할 수행하게 됨
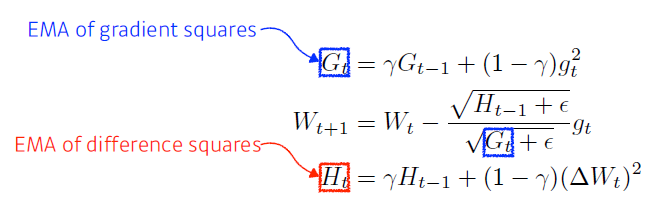
RMSprop
- RMSprop is an unpublished, adaptive learning rate method proposed by Geoff Hinton in his lecture
- gradient squares에 대한 것을 그냥 더하는 것이 아니라 exponential moving average를 사용
- 라는 stepsize 사용
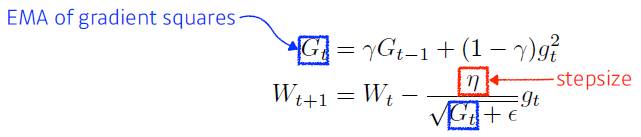
Adam
- Adaptive Moment Estimation leverages both past gradients and squared gradients
- adam effectively combines momentum with adaptive learning rate approach
- gradient squares를 EMA에 취하는 것과 동시에 momentum을 같이 활용
- hyperparameters
- : momentum을 얼마나 유지시킬지
- : gradient squares에 대한 EMA 정보
- : learning rate
- : division by zero를 막기 위함 (default: )
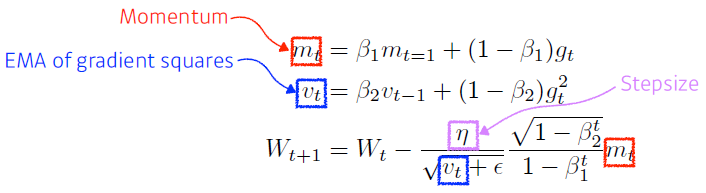
Regularization
: 규제
- 학습을 방해
- 학습데이터에만 잘 동작하는 것이 아니라 테스트데이터에도 잘 동작하도록
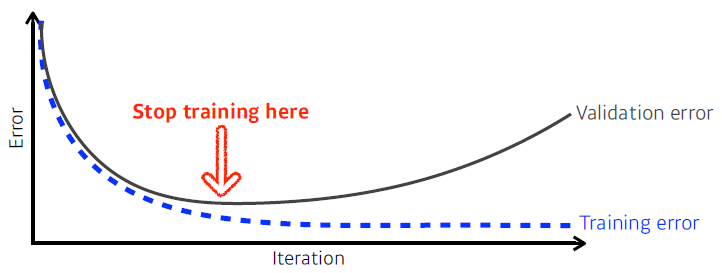
Early stopping
- Note that we need additional validation data to do early stopping.
Parameter norm penalty (weight decay)
- It adds smoothness to the function space
- 뉴럴 네트워크 파라미터가 너무 커지지 않게 해 줌
- 네트워크 파라메터들을 전부 제곱한 다음 더한 값을 줄이기
- 뉴럴 네트워크가 만들어내는 함수의 공간속에서 함수를 최대한 부드러운 함수로
-
부드러운 함수일수록 generalization perfomance가 높을 것이다.
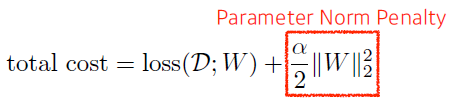
-
Data augmentation
- more data are always welcomed
- 표현력 향상
- however, in most cases, training data are given in advance
- In such cases, we need data augmentation
Noise robustness
- add random noises inputs or weights
- 입력데이터와 neural network weight에 noise 집어넣기

Label smoothing
- data augumentation과 유사, but 얘는 data 두개를 뽑아서 섞어
- decision boundary를 부드럽게 만들어 주는 효과
- Mix-up constructs augmented training examples by mixing both input and output of two randomly selected training data.
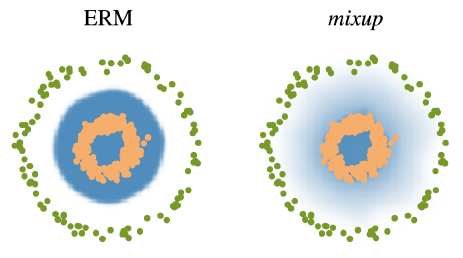
- CutMix constructs augmented training examples by mixing inputs with cut and paste and outputs with soft labels of two ramdomly selected training data

Dropout
- In each forward pass, randomly set some neurons to zero.
- neural network의 weight를 0으로 바꿔
- dropout ratio 면 50퍼센트를 0으로 바꿈
- 각각의 뉴런들이 좀 더 robust한 feature를 잡을 수 있음
Batch normalization
- Batch normalization compute the empirical mean and variance independently for each dimension (layers) and normalize.
- 내가 BN을 적용하고자하는 layer에 stastices를 정규화시킴
- 평균을 빼고 표준편차를 나눔
- Internal covariant(feature) shift를 줄인다 → 그러면서 network가 잘 학습이 된다라고 설명
- 논란중,,
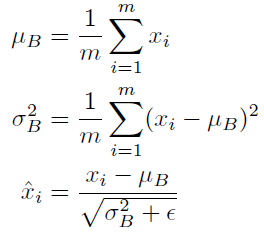
- 논란중,,
- There are different variance of normalizations
- BN은 layer 전체에 대한걸 줄였다면 얘는 일부~
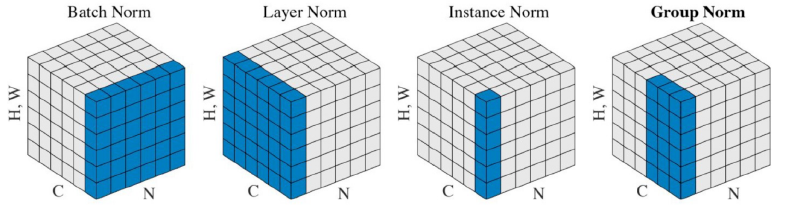
- BN은 layer 전체에 대한걸 줄였다면 얘는 일부~

Hi there 👋