
💡 각각 network의 parameter의 수, depth 유의깊게 보기!
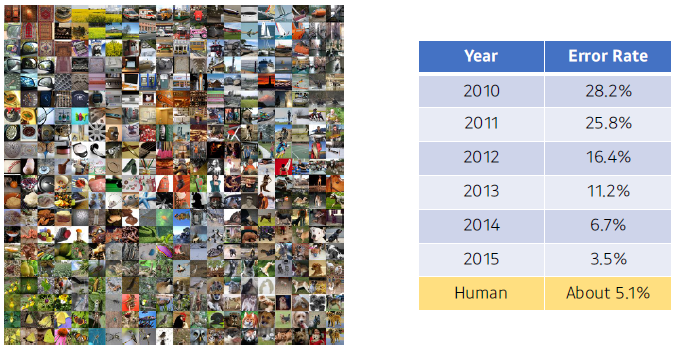
ILSVRC (ImageNet Large-Scale Visual Recognition Challenge)
- Classification / Detection / Localization / Segmentation
- 1,000 different categories
- Over 1 million images
- Training set: 456,567 images
AlexNet
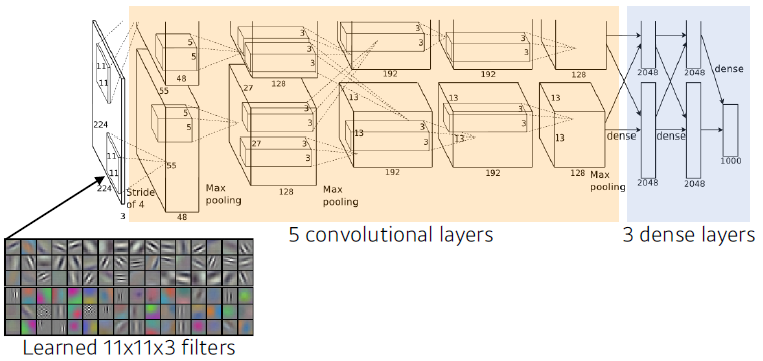
- input이 11x11 → 5x5 → 3x3 사용
- 상대적으로 더 많은 파라미터 필요
- 8 depths
- key ideas
- Rectified Linear Unit (ReLU) activation
- non-linear
- slope가 1
- GPU implementation (2 GPUs)
- 네트워크가 두개로 나뉘어 있음 (GPU 부족)
- Local response normalization, Overlapping pooling
- LRN: 어떤 입력공간에서 response가 많이 나오면 몇개를 kill > 최종적으로 sparse하게 (but 최근 활용 x)
- Data augmentation
- Dropout
- Rectified Linear Unit (ReLU) activation
- ReLU activation
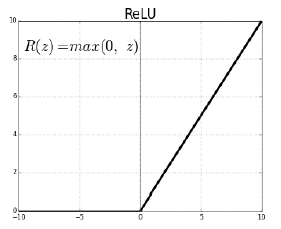
- Preserves properties of linear models
- Easy to oprimize with gradient descent
- Good generalization
- Overcome the vanishing gradient problem
- sigmoid나 tanh는 gradient는 0에 가까워져서 vanishing problem 있었음
VGGNet : repeated 3x3 blocks
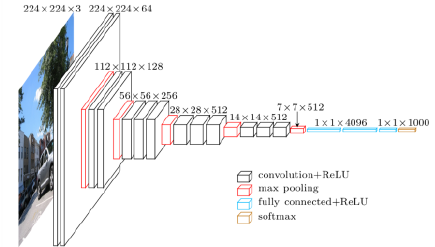
-
Increasing depth with 3*3 convolution filters (with stride 1)
-
1*1 convolution for fully connected layers
-
Dropout (p=0.5)
-
VGG16, VGG19 : layer의 개수에 따라
-
why 3*3 convolution?
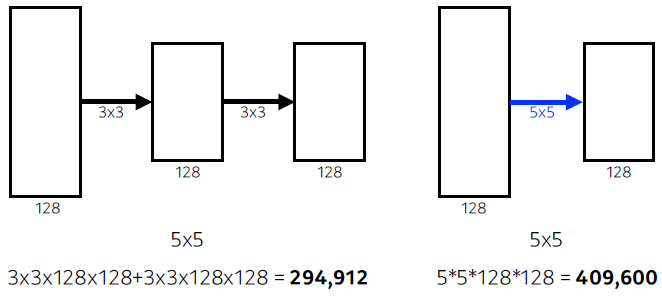
- Receptive field numbers of params
- filter가 커지면 고려되는 input의 크기가 커짐
- receptive field 수용영역
- 내가 하나의 convolution feature map 값을 갖기 위해 고려할 수 있는 입력의 Dimension
- receptive field 수용영역
- 3x3을 두번하는 것과 5x5를 한번하는 것은 receptive field 차원에서 같음
- 가장 마지막에 있는 하나의 값은 중간 feature map의 3x3을 보게 되고 걔는 다시 input의 3x3 → 결국 5x5의 픽셀값이 합쳐진 값이 됨
GoogLeNet : 1x1 convolution
-
1x1 convolution: dimension(channel) reduction 효과가 있음
- parameter수를 줄일 수 있음
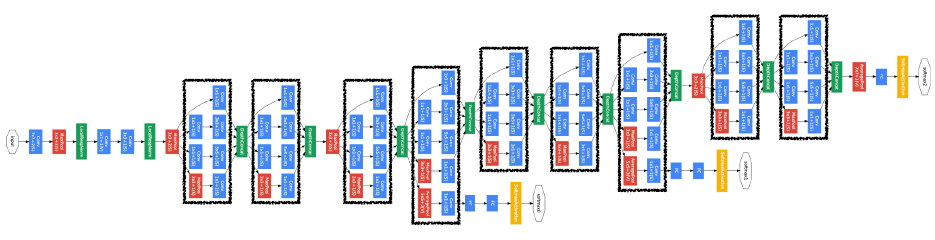
-
22 layers
-
combined network-in-network (NiN) with inception blocks
- 비슷한 모양의 네트워크가 여러번 반복
Inception blocks
-
하나의 입력이 들어왔을 때 여러개로 퍼졌다가 하나로 합쳐지게 됨
- convolution 전에 1x1 conv 해주기
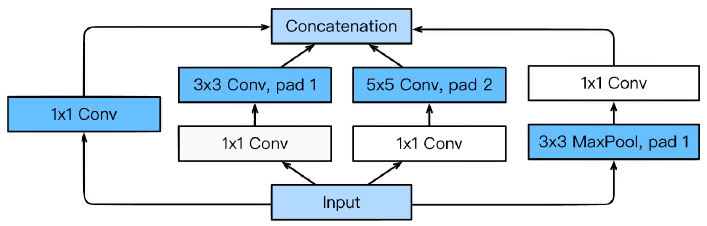
-
benefits: Reduce the number of parameter
- recall how the number of parameters is computed
- 1*1 convolution can be seen as channel-wise dimension reduction
-
benefit of 1*1 convolution
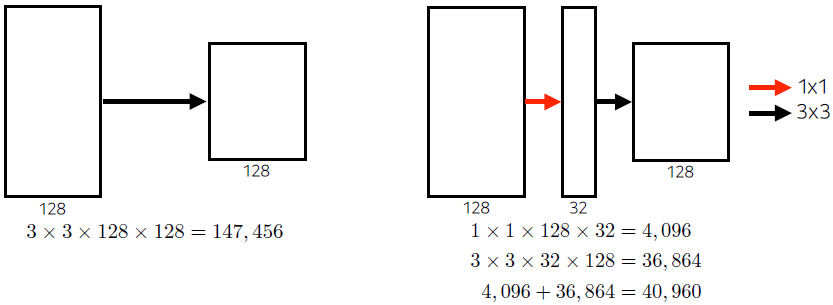
- 1x1 conv를 통해 128 channel을 32로 줄임
- receptive field 차원에서는 같음
- about 30% reduce of the number of parameters
ResNet : skip-connection
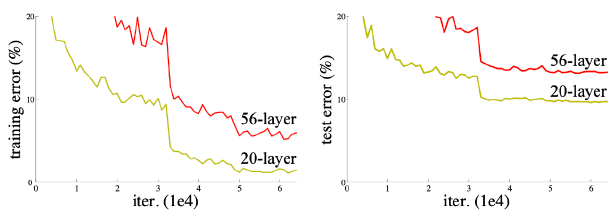
- generalization performance: training에러가 줄어듦에도 불구하고 test error와 차이 많아
- overfittinf: slope가 아에 반대
- Deeper neural networks are hard to train 아에 학습이 안되는 현상
- overfitting is usually caused by an excessive number of parameters.
- but, not in this case
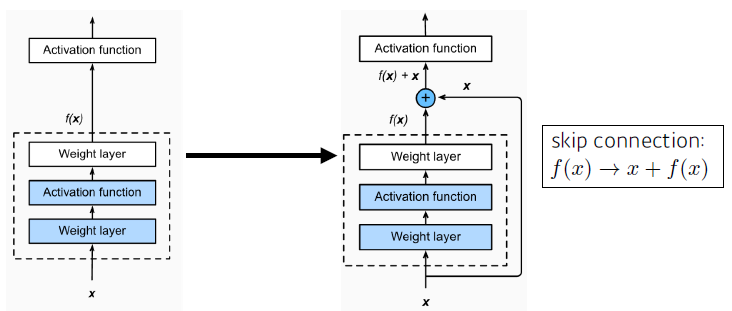
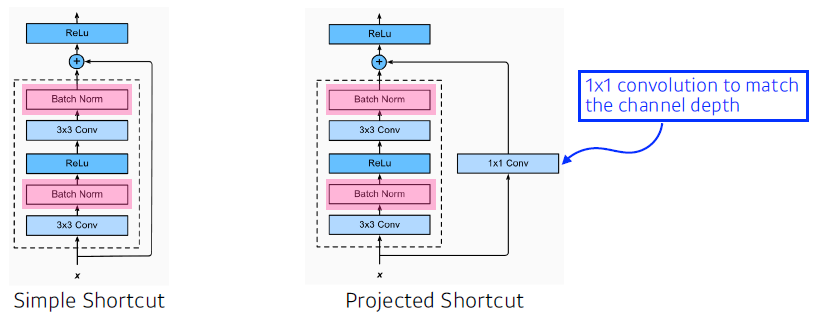
- Add an identity map (skip connection)
- x를 뉴럴 네트워크의 출력값에 더해줌
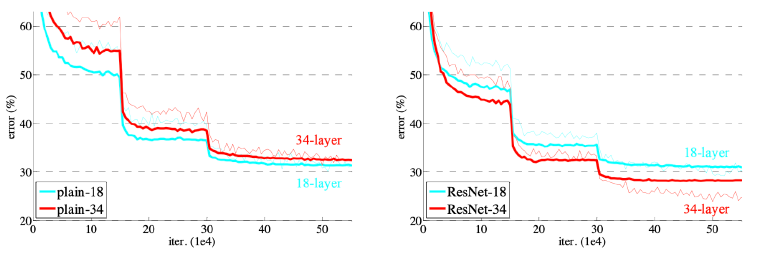
- 이제서야 34 layer가 더 잘해. 깊게 쌓을 수 있음
- x를 뉴럴 네트워크의 출력값에 더해줌
- Add an identity map after nonlinear activations
- 더해주려면 차원이 같아야 함 → 1x1 conv로 차원 맞춰줌
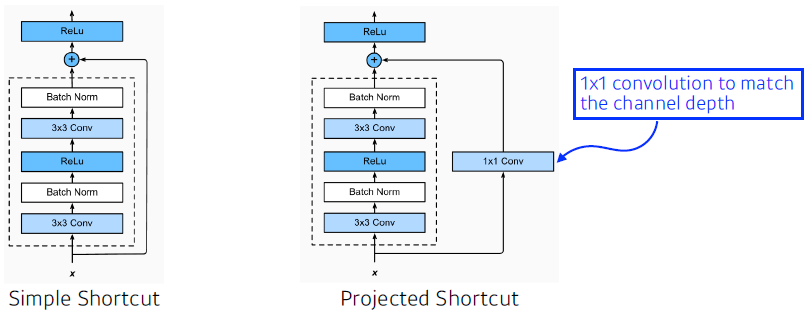
- 더해주려면 차원이 같아야 함 → 1x1 conv로 차원 맞춰줌
- Batch normalization after convolutions
- bottleneck architecture
- 채널을 줄이고 늘리기 위해 사용
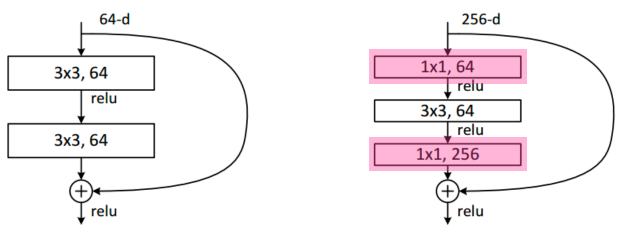
- 채널을 줄이고 늘리기 위해 사용
- performance increases while parameter size decreases.
DenseNet : concatenation
- 더하면 섞이니까 더하지 말고 concat하자
- DenseNet uses concatenation instead of addition
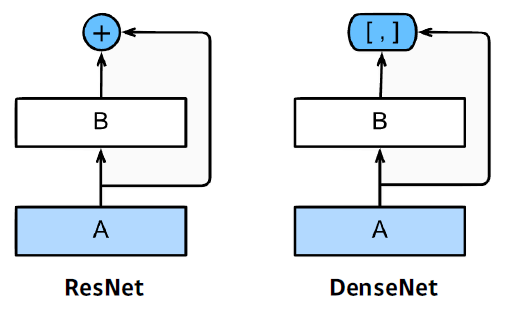
- concet하면 채널이 기하급수적으로 커짐 → parameter수도 같이 커짐
- 중간에 한번씩 채널을 줄여
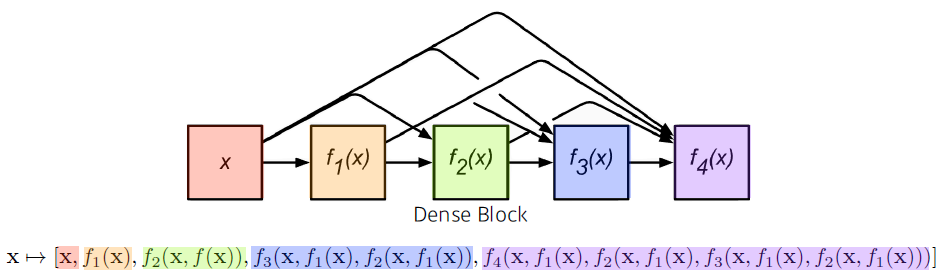
- 중간에 한번씩 채널을 줄여
Dense Block
- each layer concatenates the feature maps of all preceding layers
- the number of channels increses geometrically
Transition Block
- BatchNorm → 11 conv → 22 AvgPooling
- Dimension reduction


Hi there 👋