
- 모델에 데이터 먹이기
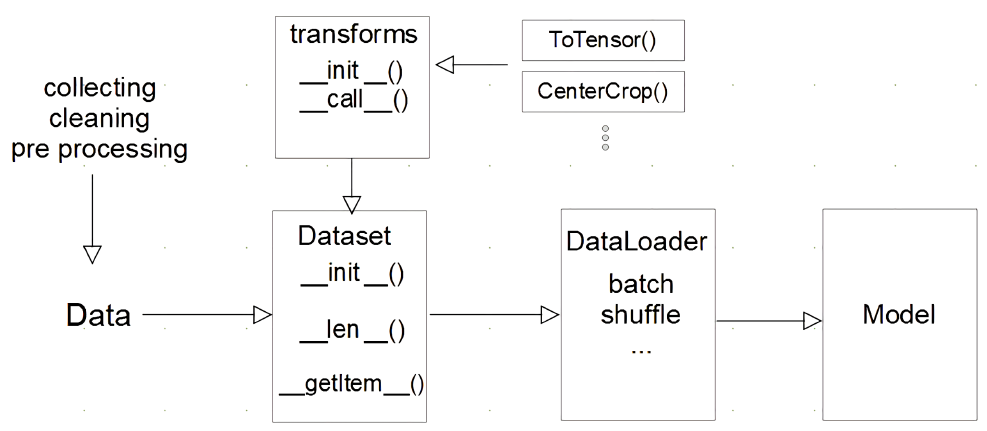
__getitem__(): map_style 하나의 데이터를 불러올 때 어떻게 반환해 주는지 정의- transforms: 전처리하거나 data augumentation시 변형 (Tensor로 바꿈)
- DataLoader: 묶어서 모델에 feeding
- batch를 만들어 주거나 batch를 만들 때 suffle하여 데이터 섞어줌
Dataset 클래스
- 데이터 입력 형태를 정의하는 클래스
- 데이터를 입력하는 방식의 표준화
- Image, Text, Audio 등에 따른 다른 입력 정의
import torch
from torch.utils.data import Dataset
class CustomDataset(Dataset):
def __init__(self, text, labels): # 초기 데이터 생성 방법 지정 (ex. image data에서 directory(folder)지정)
self.labels = labels # label과 text가 어디에서 생성되는지 정의
self.data = text
def __len__(self):
return len(self.labels) # 데이터 전체 길이
def __getitem__(self, idx): # index값을 주었을 때 반환되는 데이터의 형태 (X, y)
label = self.labels[idx] # array type
text = self.data[idx] # list type
sample = {"Text": text, "Class": label} # dict type로 반환(classification 문제에서 주로)
return sampleDataset 클래스 생성시 유의점
- 데이터 형태에 따라 각 함수를 다르게 정의함 Image, Text, Audio..
- 모든 것을 데이터 생성 시점(init)에 처리할 필요는 없음
: image의 Tensor 변화는 학습에 필요한 시점에 변환 (transform 함수 이용)
getitem을 할 때 변환된 Tensor를 반환하는 것 X (CPU와 GPU의 역할 바뀜. C: 데이터 변환 G:학습 → 병렬 처리 가능 C: Tensor로 변환하여 G에 넘겨줌) - 데이터 셋에 대한 표준화된 처리방법 제공 필요
→ 후속 연구자 또는 동료에게는 빛과 같은 존재 - 최근에는 HuggingFace 등 표준화된 라이브러리 사용
DataLoader 클래스
- Data의 Batch를 생성해주는 클래스
- Dataset: 하나의 데이터를 어떻게 가져올 것인가
- Dataloader: 그 인덱스를 가지고 여러개의 데이터를 한번에 묶어서 모델에 던져줌
- 학습직전(GPU feed전) 데이터의 변환을 책임
- Tensor로 변환 + Batch 처리가 메인 업무
- 병렬적인 데이터 전처리 코드의 고민 필요
## Dataset 생성
text = ['Happy', 'Amazing', 'Sad', 'Unhapy', 'Glum']
labels = ['Positive', 'Positive', 'Negative', 'Negative', 'Negative']
MyDataset = CustomDataset(text, labels)
## DataLoader generator
MyDataLoader = DataLoader(MyDataset, batch_size=2, shuffle=True) # Dataset을 Dataloader에 넣어줌. batchsize는 2, 순서 섞어
next(iter(MyDataLoader))
# {'Text': ['Glum', 'Sad'], 'Class': ['Negative', 'Negative']}
## 위의 값을 가지고 GPU에 넣어줄 수 있음
MyDataLoader = DataLoader(MyDataset, batch_size=2, shuffle=True)
for dataset in MyDataLoader: # 하나의 epic이 됨
print(dataset)
# {'Text': ['Glum', 'Unhapy'], 'Class': ['Negative', 'Negative']}
# {'Text': ['Sad', 'Amazing'], 'Class': ['Negative', 'Positive']}
# {'Text': ['Happy'], 'Class': ['Positive']}
## batch size가 2라서 2 2 1DataLoader의 파라미터들
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None, *, prefetch_factor=2,
persistent_workers=False)- sampler, batch_sampler: 데이터를 어떻게 뽑을 지 index 지정
- collate_fn: [[Data, Label], [Data, Label], ..., [Data, Label]] 형태를 [[Data, Data, ... Data], [Label, Label, ..., Label]] 형태로 변경시켜줌
- variable length
- text 처리시 글자 수 맞춰줄 때 (0으로 padding할 때)

Hi there 👋