
Introduction
What make you a good deep learner?
- 구현 실력: pytorch
- 수학: 선형대수학, 확률론
- 현재 어떤 트렌드?
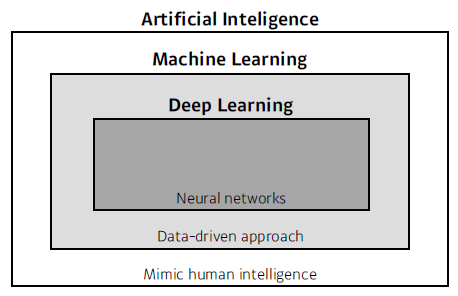
인공지능?
- AL/ML/DL
Key Components
- data
- model
- 이미지를 라벨로 바꿔주기
- CNN,,,
- loss
- 학습 시키기 위한
- regression: 제곱 최소화
- 분류: cross entropy
- algorithm
- loss funcion 최소화
- stochastic gradient descent, Adam,,
- loss funcion 최소화
Data
풀고자하는 문제에 의존적임
- classification
- 강아지와 고양이 분류
- semantic segmentation
- 픽셀별로 어떤 클래스에 속하는지 분류
- detection
- bounding box 찾기
- pose estimation
- 3(2)차원 스켈레톤 정보
- visual QnA
- 질문에 대한 답
Model
같은 데이터가 주어졌다하더라도 모델의 성질에 따라 다른 결과
- AlexNet
- GoogLeNet
- ResNet
- DenseNet
- LSTM
- Deep AutoEncoders
- GAN
Loss
The loss function is a proxy of what we want to achieve.
근사치: 우리가 원하는 값을 항상 이룬다는 보장은 없음
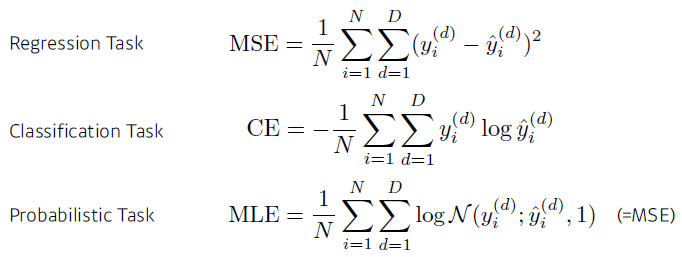
Optimization Algorithm
data, model, loss function이 정해져 있을 때 network를 어떻게 줄일지?
- first order method
- 뉴럴 네트워크의 파라메터를 loss function에 대해 1차 미분한 정보를 활용: SGD
- SGD 변형> Momentum, NAG, Adagrad, Adadelta, Rmsprop, Adam,,
- Regulizer: 학습을 할 때 있어서 학습이 오히려 잘 안되게 하는 것들
- 우리의 목적: loss function을 단순히 줄이기 X, model이 학습하지 않은 data에서 잘 동작하기
- Dropout, Early Stopping, k-fold validation, Weight decay, Batch normalization, Mixup, Ensemble, Baysian Optimization
Historical Review
2012 - AlexNet
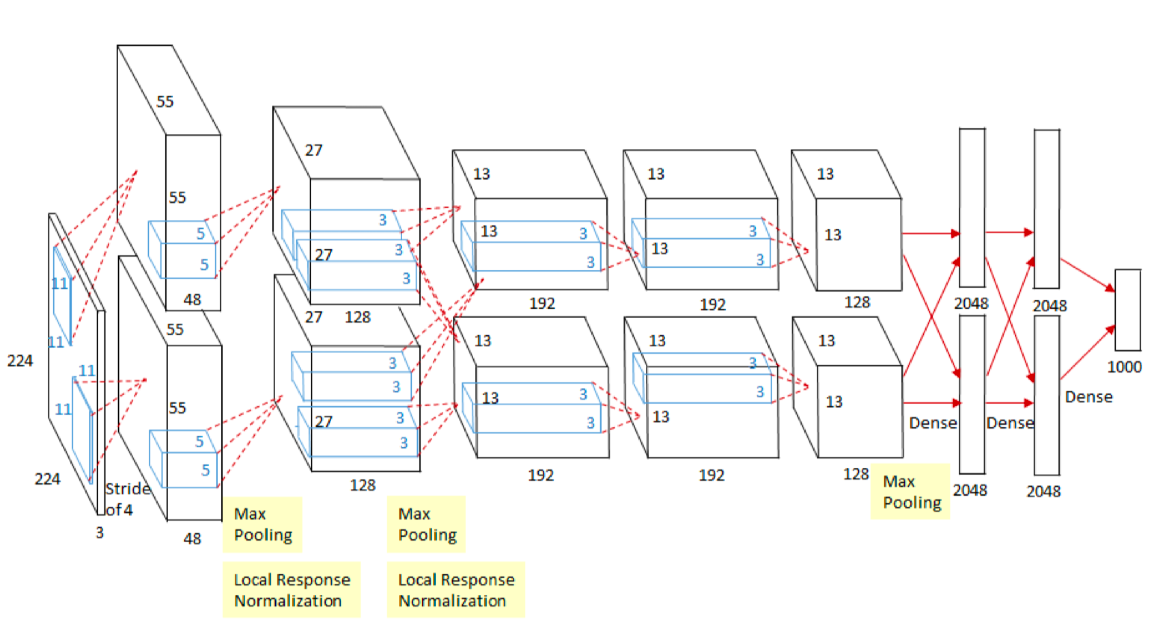
convolution nerual network 기반
224x224 이미지가 들어왔을 때 분류하는 것
이전에는 커널기반, SVM,,, 사용 > 패러다임의 변화
2013 - DQN
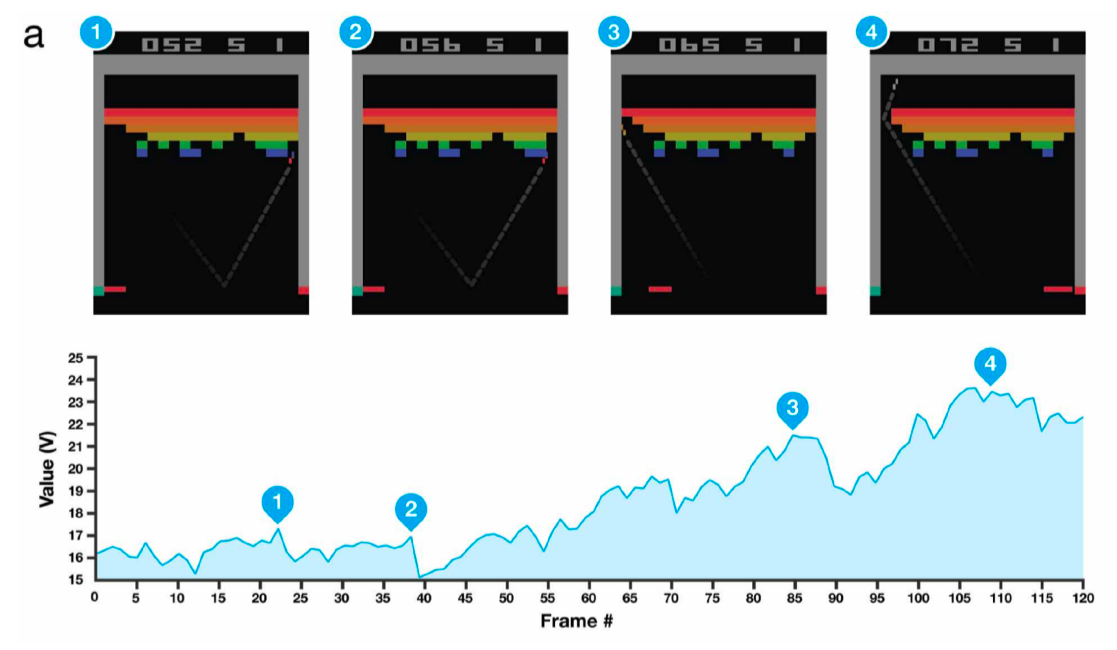
Deepmind: 이세돌 vs alphgo
강화학습 Q learning 기반
2014 - Encoder/Decoder
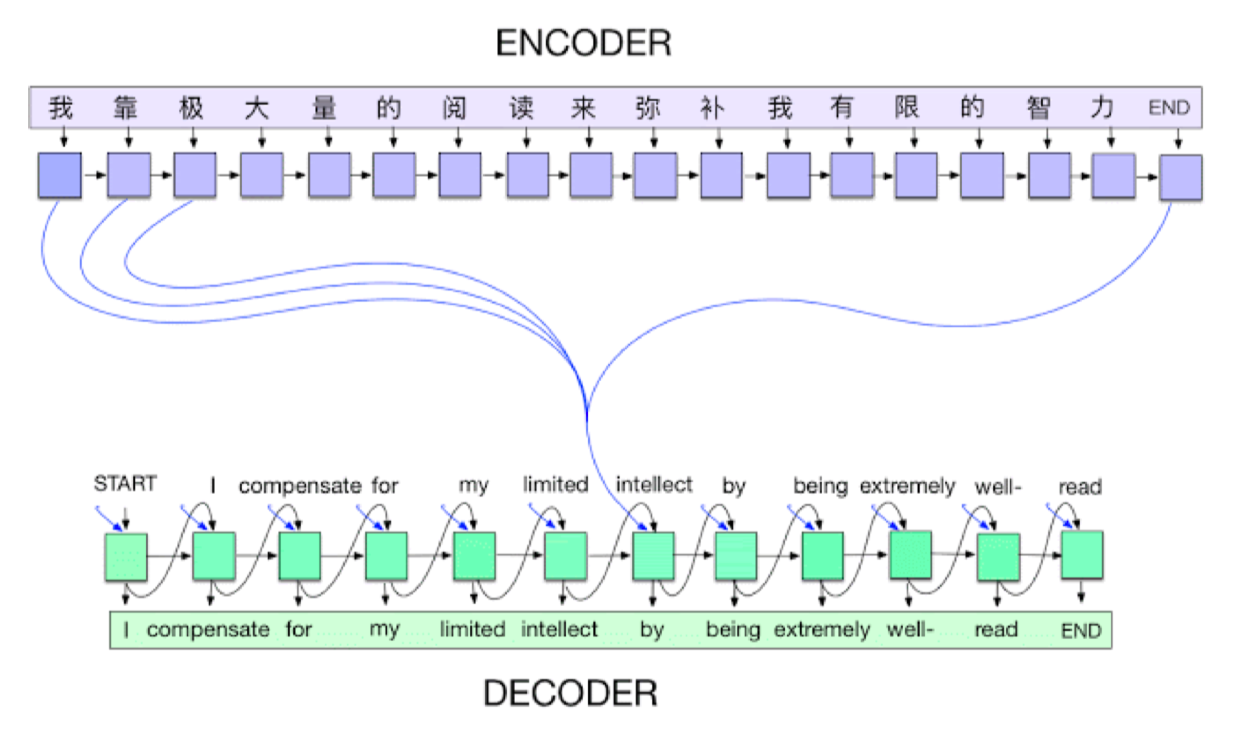
NMT(nerual machine translation) 문제를 풀기 위해
단어의 연속 sequence
2014 - Adam Optimizer
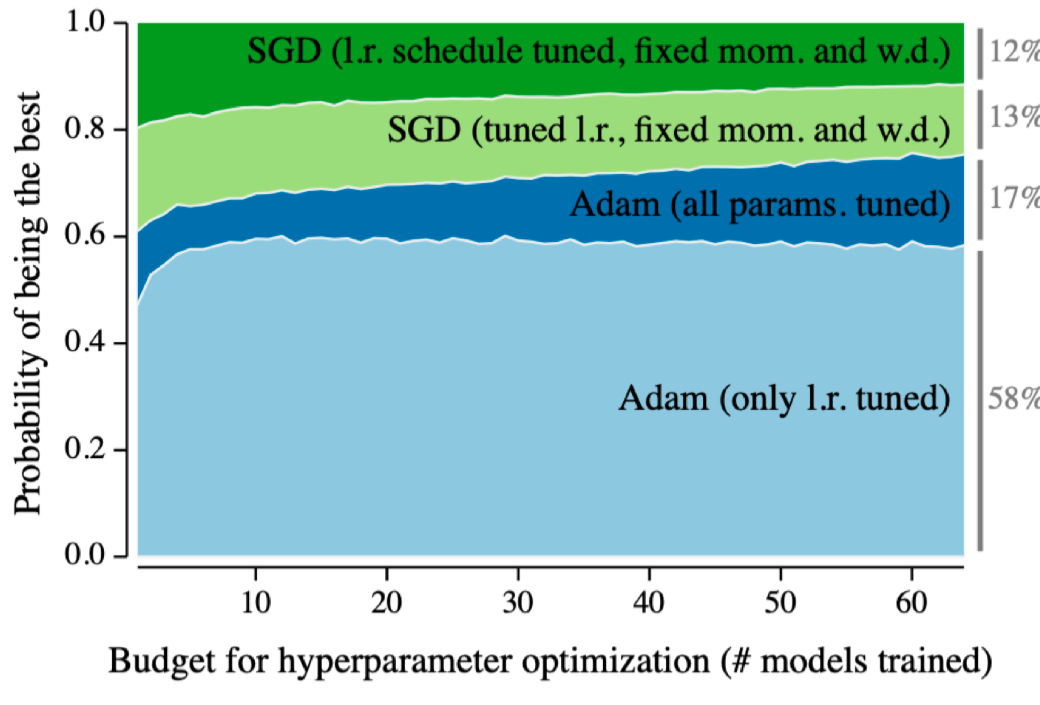
- Adaptive Momentum optimizer
- 다양한 hyperparameter search
- optimizer, base learning rate, learning rate 스케쥴링
- computing resource 부족,,
- adam: 왠만하면 잘 된다ㅋㅋㅋ
2015 - Generative Adversarial Network

- 이미지를 어떻게 만들어낼까?
- 네트워크가 generator와 discriminator 두개를 만들어 학습
2015 - Residual Networks
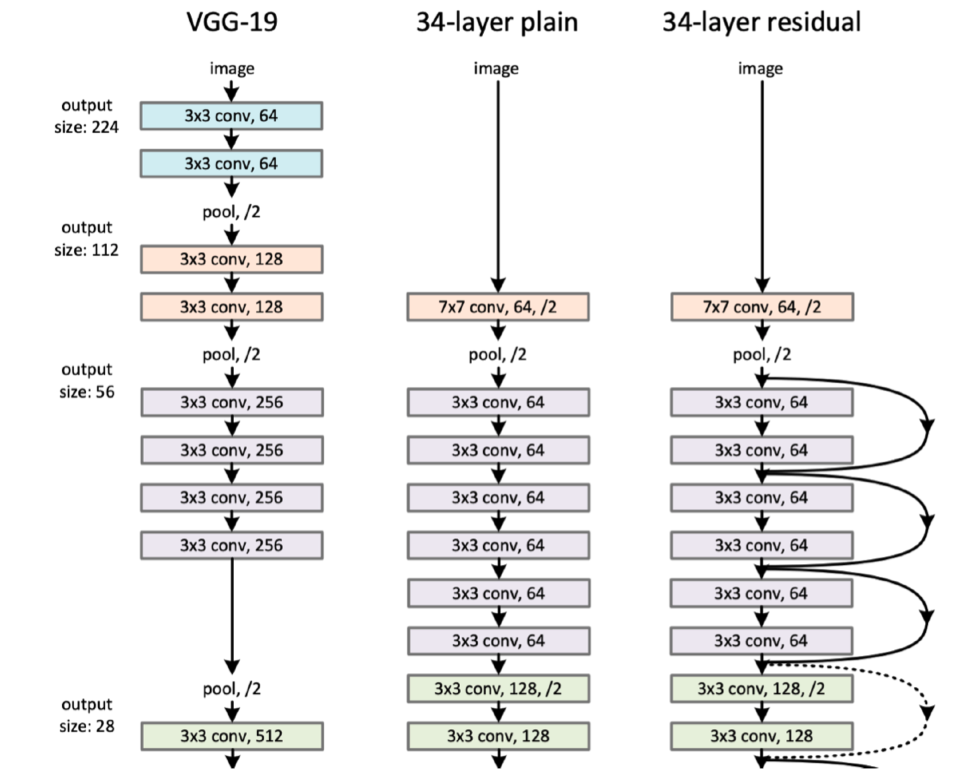
- ResNet
- 딥러닝이 딥러닝이 가능해짐
- 왜 딥러닝이냐? network를 깊게 쌓기 때문에
- 이전에는 network를 깊게 쌓으면 좋지 않은 성능,, (test에서)
- resnet이후에는 바뀜: network를 깊게 쌓을 수 있도록
2017 - Transformer
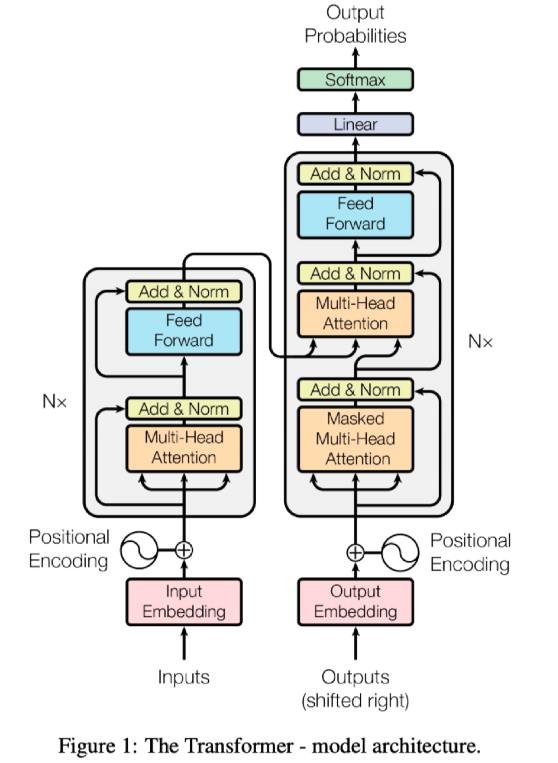
Attention Is All You Need
Attention=Transformer
recurrent 뉴런 구조를 거의 다 대체
2018 - BERT (fine-tuned NLP models)
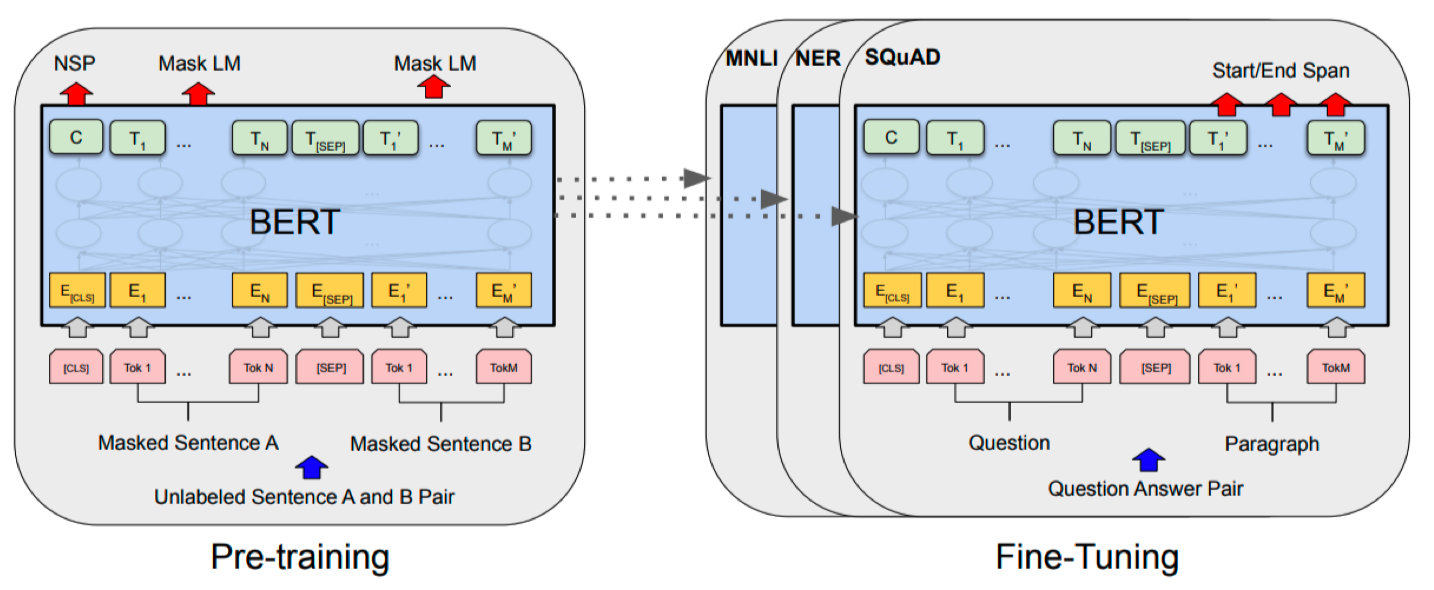
- Bidirectional Encoder Representations from Transformers
- 자연어 처리 문제: language model을 학습(이전에 단어들이 주어졌을 때 다음 단어가 뭘지)
2019 - BIG Language Models
- OpenAI, GPT-3
- BERT의 끝판왕!
- 여러가지 sequencial 모델들을 만들 수 있게 됨
- 굉장히 많은 parameter로 되어있음: 175billion parameters
2020 - Self Supervised Learning
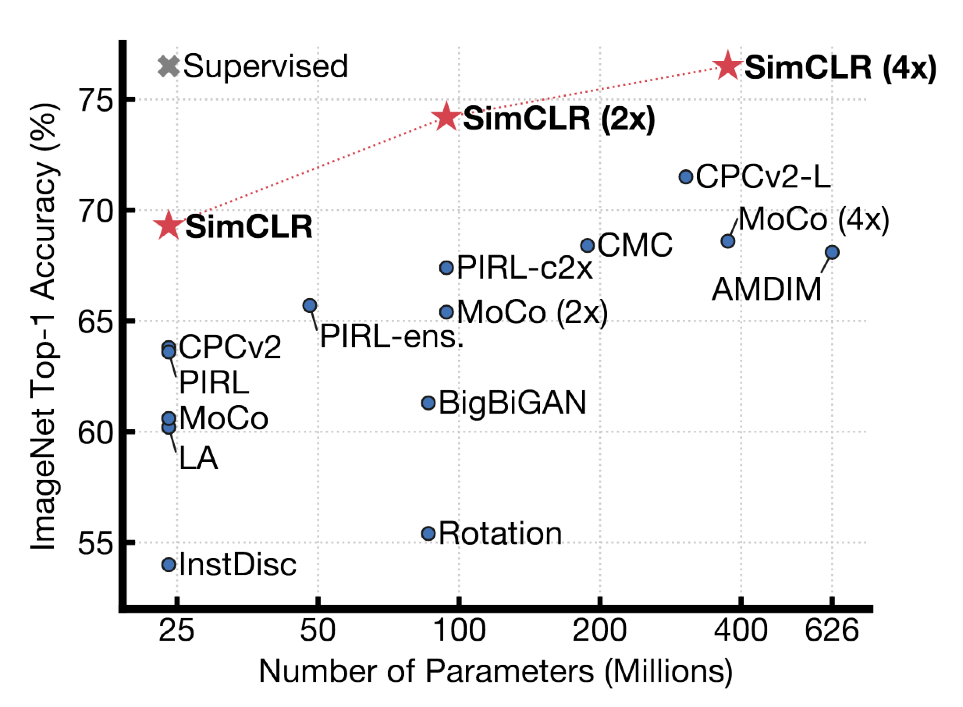
- google의 SimSLR
- 학습 data 외에 label을 모르는 data를 학습에 같이 활용하겠다.
- unsupervised learning
- 내가 풀고자 하는 문제에 대해 잘 알고있음(domain)> data 만들어내자

Hi there 👋