
옛날 초창기 구글은 문장들을 단어 단위로 쪼개고 글 번호를 붙이는 Tokenizing방법을 사용하였다. 기술이 많이 발전하여 지금은 검색에 더 최적화 된 개발툴들이 많이 생겨났다. 대표적으로 ELK Stack이 있는데, 여기서 ELK란 Elasticsearch, Logstash, Kibana 이 셋의 조합이다. Elasticsearch는 모든 데이터를 색인하여 저장하고 검색, 집계 등을 수행하며 결과를 클라이언트에 전달하는 무료 오픈 소스 검색 및 분산 엔진이다. Elasticsearch는 단순 검색 기능으로 모니터링 및 머신러닝 등의 복잡한 기능은 처리하지 않기 때문에 Logstash를 이용하여 RDBMS(MySQL)의 데이터를 알맞게 변환하여 Elasticsearch에 제공한다. kibana는 Elasticsearch와 연동되는 시각적인 도구로써 통계, 그래프 같은 요소들을 손쉽게 볼 수 있다.
이러한 ELK Stack과 Redis를 활용하여 아래와 같이 검색 프로세스를 구성해보았다.
📌 Search Process
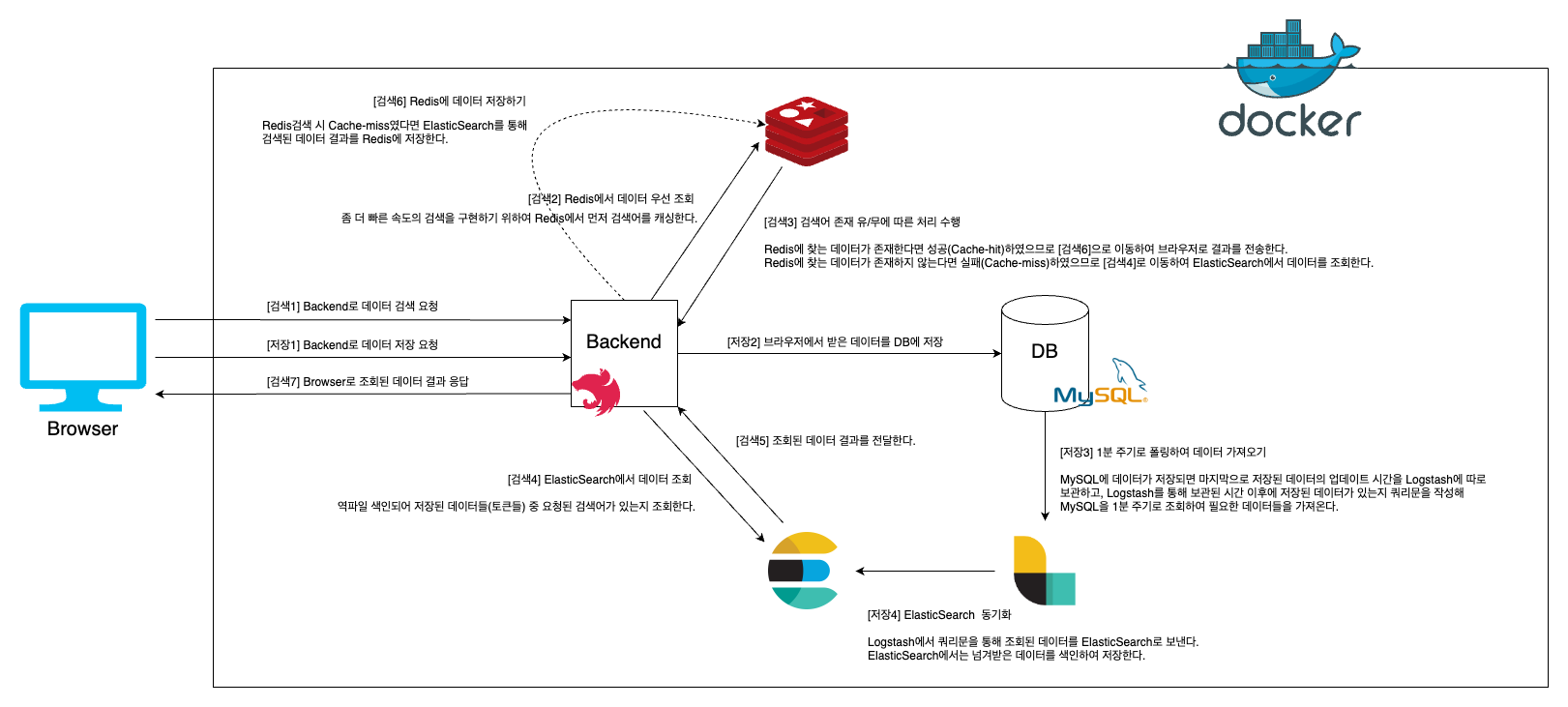
먼저 검색을 진행하기 이전에 데이터 저장 요청이 왔을 때에 수행해야하는 프로세스가 있다.
데이터 저장 프로세스
-
브라우저로부터 데이터 저장 요청이 오면 Backend는 전달받은 데이터를 DB에 저장한다. 이때 저장된 데이터는 UpdatedAt이라는 컬럼을 가지고 새로 추가되거나 수정되었을 때의 시간을 가지고 있다.
-
Logstash는 1분 주기로 마지막으로 저장된 데이터의 UpdatedAt컬럼과 현재 저장된 데이터의 UpdatedAt을 비교하여 추가로 데이터가 저장되었을 경우 쿼리문을 통해 데이터를 가져와 Elasicsearch로 보낸다.
-
Elasticsearch에서는 넘겨받은 데이터를 색인하여 저장한다.
검색 프로세스
-
브라우저로부터 검색 요청이 들어오면 좀 더 빠른 속도의 검색을 구현하기 위하여 백엔드에서는 먼저 Redis에서 먼저 검색어를 찾는다. 만약 Redis에 찾는 데이터가 존재한다면 성공(Cache-hit)하였으므로 브라우저에 조회된 데이터 결과를 보낸다. Redis에 찾는 데이터가 없다면 실패(Cache-miss)하였으므로 Elasticsearch에서 검색어를 조회한다.
-
이전에 Redis에서 찾는 데이터가 없었다면 Elasticsearch에서 조회된 데이터를 Redis에 key-value를 검색어-결과값 형태로 저장해주어 이후에 다시 동일한 검색어로 검색 요청이 왔을 때 Elasticsearch까지 오지 않고도 Redis에서 검색 프로세스가 완료되도록 한다. => 속도 개선
-
Elasicsearch에서 조회된 데이터를 브라우저로 전달해준다.
📌 정리
- 검색 요청이 들어왔을 때 DB에서 조회를 하게 되면 속도가 매우 느려진다. 따라서 DB에 데이터가 추가되면 Logstash를 통하여 Elasticsearch에 원본 데이터를 저장하고 Redis와 Elasticsearch를 활용하여 조금 더 빠른 검색 기능을 완성할 수 있었다.
