Learning curve (학습 곡선)
-
편향(bias)이 높으면 (=underfitting) 훈련 정확도, 교차 검증 정확도가 모두 낮게 나타남
-
분산(variance)이 높으면 (=overfitting) 훈련 정확도, 교차 검증 정확도의 차이가 크게 나타남
-
learning_curve 함수로 학습 곡선 생성
- 훈련 정확도, 테스트 정확도를 그래프로 표현
- 기본적으로 k-fold cross-validation (k-겹 교차검증) 수행
cvparameter 로 k 값 지정
-
feel_between 함수로 평균 정확도의 표준편차를 그려 추정 분산(variance) 표시
import matplotlib.pyplot as plt
from sklearn.model_selection import learning_curve
pipe_lr = make_pipeline(StandardScaler(),
LogisticRegression(penalty='l2', random_state=1,
max_iter=10000))
train_sizes, train_scores, test_scores =\
learning_curve(estimator=pipe_lr,
X=X_train,
y=y_train,
train_sizes=np.linspace(0.1, 1.0, 10),
cv=10,
n_jobs=1)
train_mean = np.mean(train_scores, axis=1)
train_std = np.std(train_scores, axis=1)
test_mean = np.mean(test_scores, axis=1)
test_std = np.std(test_scores, axis=1)
plt.plot(train_sizes, train_mean,
color='blue', marker='o',
markersize=5, label='Training accuracy')
plt.fill_between(train_sizes,
train_mean + train_std,
train_mean - train_std,
alpha=0.15, color='blue')
plt.plot(train_sizes, test_mean,
color='green', linestyle='--',
marker='s', markersize=5,
label='Validation accuracy')
plt.fill_between(train_sizes,
test_mean + test_std,
test_mean - test_std,
alpha=0.15, color='green')
plt.grid()
plt.xlabel('Number of training examples')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
plt.ylim([0.8, 1.03])
plt.tight_layout()
plt.show()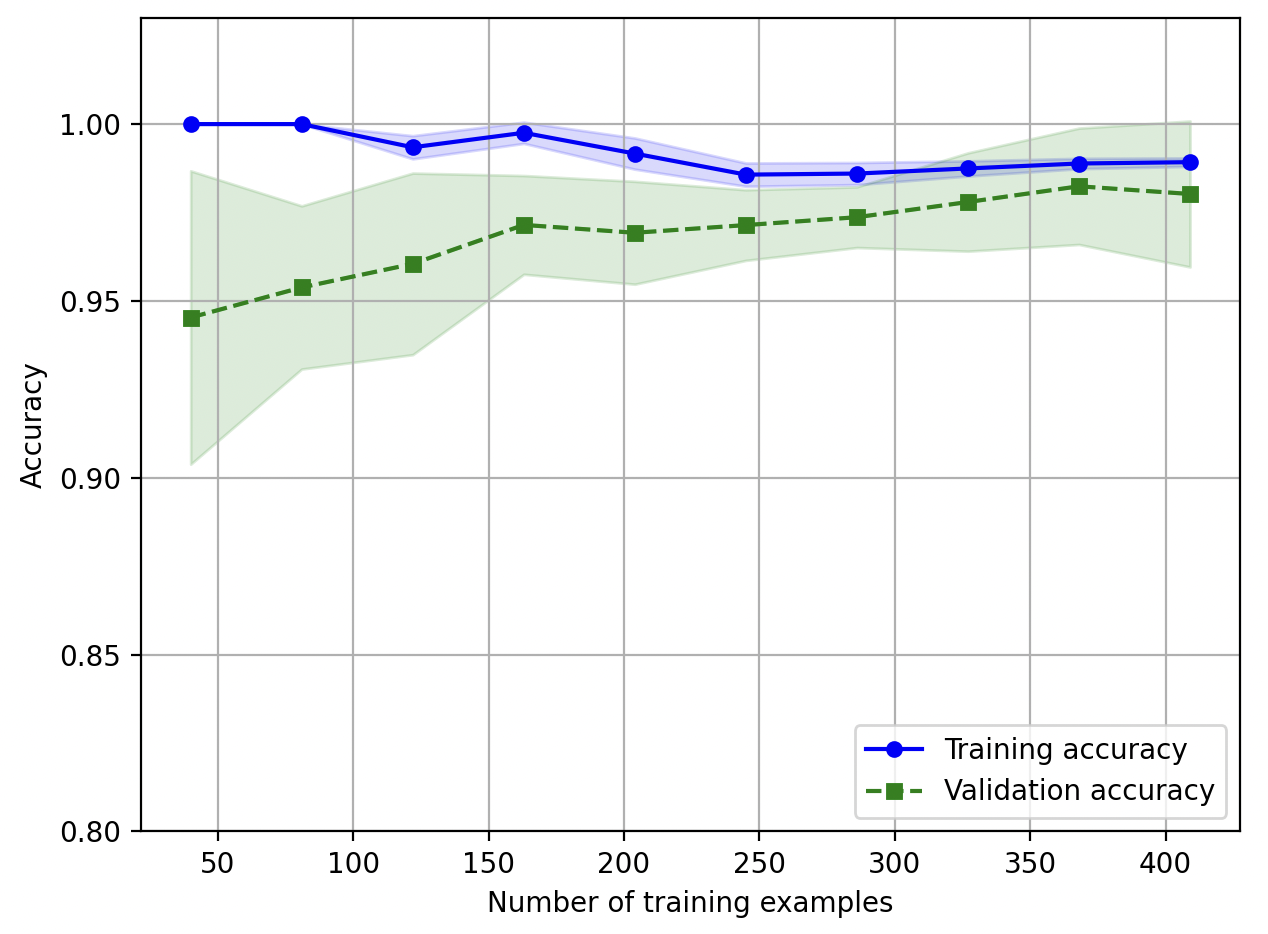
validation curve (검증 곡선)
- 검증 곡선은 모델 파라미터 값을 그리는 곡선
- ex) logistic regression 의 regularization parameter (규제 파라미터) 등
- 기본적으로 k-fold cross-validation (k-겹 교차검증) 수행
- ex) LogisticRegression 의 regularization parameter C 평가
logisticregression__C를 파라미터로 지정하여 평가 대상으로 선택param_range: 값 범위 지정
from sklearn.model_selection import validation_curve
param_range = [0.001, 0.01, 0.1, 1.0, 10.0, 100.0]
train_scores, test_scores = validation_curve(
estimator=pipe_lr,
X=X_train,
y=y_train,
param_name='logisticregression__C', # 로지스틱 회귀 규제 파라미터 평가
param_range=param_range, # 값의 범위 지정
cv=10)
train_mean = np.mean(train_scores, axis=1)
train_std = np.std(train_scores, axis=1)
test_mean = np.mean(test_scores, axis=1)
test_std = np.std(test_scores, axis=1)
plt.plot(param_range, train_mean,
color='blue', marker='o',
markersize=5, label='Training accuracy')
plt.fill_between(param_range, train_mean + train_std,
train_mean - train_std, alpha=0.15,
color='blue')
plt.plot(param_range, test_mean,
color='green', linestyle='--',
marker='s', markersize=5,
label='Validation accuracy')
plt.fill_between(param_range,
test_mean + test_std,
test_mean - test_std,
alpha=0.15, color='green')
plt.grid()
plt.xscale('log')
plt.legend(loc='lower right')
plt.xlabel('Parameter C')
plt.ylabel('Accuracy')
plt.ylim([0.8, 1.0])
plt.tight_layout()
# plt.savefig('images/06_06.png', dpi=300)
plt.show()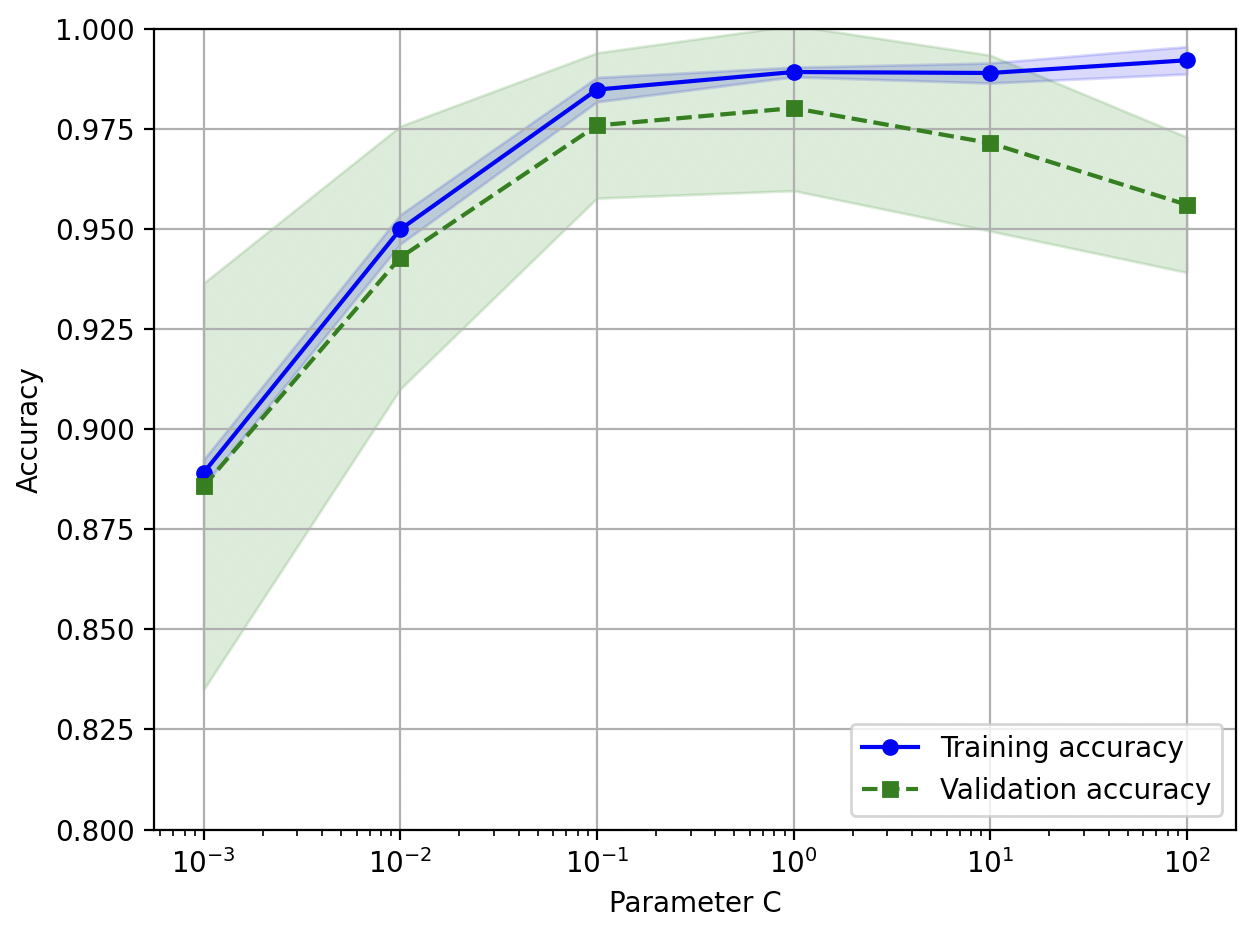
reference
- 서적 '머신러닝 교과서 with 파이썬, 사이킷런, 텐서플로 개정 3판'
