greedy search
-
하이퍼파라미터 (Hyper parameter) 최적화 기법 중 하나
-
리스트로 하이퍼파라미터 값을 넘겨 모든 조합에 대해 모델 성능 평가, 최적 조합을 찾는 방식
-
GridSearchCV클래스를 통해 적용param_grid: 튜닝할 파라미터 지정 (딕셔너리의 리스트)- ex) 선형 SVM 의 경우 regularization parameger C (
svc__C)를 튜닝 - ex) RBF 커널 SVM 의 경우
svc__C,svc__gamma를 튜닝 (svc__gamma 는 커널 SVM만 해당)
- ex) 선형 SVM 의 경우 regularization parameger C (
best_score_: 최상의 모델 점수best_params_: 최상의 점수를 얻은 모델의 파라미터best_estimator_: 최상의 점수를 얻은 모델.
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
pipe_svc = make_pipeline(StandardScaler(),
SVC(random_state=1))
param_range = [0.0001, 0.001, 0.01, 0.1, 1.0, 10.0, 100.0, 1000.0]
param_grid = [{'svc__C': param_range,
'svc__kernel': ['linear']},
{'svc__C': param_range,
'svc__gamma': param_range,
'svc__kernel': ['rbf']}]
gs = GridSearchCV(estimator=pipe_svc,
param_grid=param_grid,
scoring='accuracy',
refit=True,
cv=10,
n_jobs=-1)
gs = gs.fit(X_train, y_train)
print(gs.best_score_)
print(gs.best_params_)
0.9846859903381642
{'svc__C': 100.0, 'svc__gamma': 0.001, 'svc__kernel': 'rbf'}clf = gs.best_estimator_
# refit=True로 지정했기 때문에 다시 fit() 메서드를 호출할 필요가 없습니다.
# clf.fit(X_train, y_train)
print('테스트 정확도: %.3f' % clf.score(X_test, y_test))nested cross-validation (중첩 교차 검증)
- 여러 종류의 머신러닝 알고리즘을 비교하는데 사용
- k-fold cross validation 을 위해 훈련 폴드, 테스트 폴드로 나누고
- 훈련 폴드 안에서 다시 훈련 폴드, 검증 폴드로 나누어 k-fold cross validation 수행
- 테스트 폴드를 사용해 모델 성능 평가
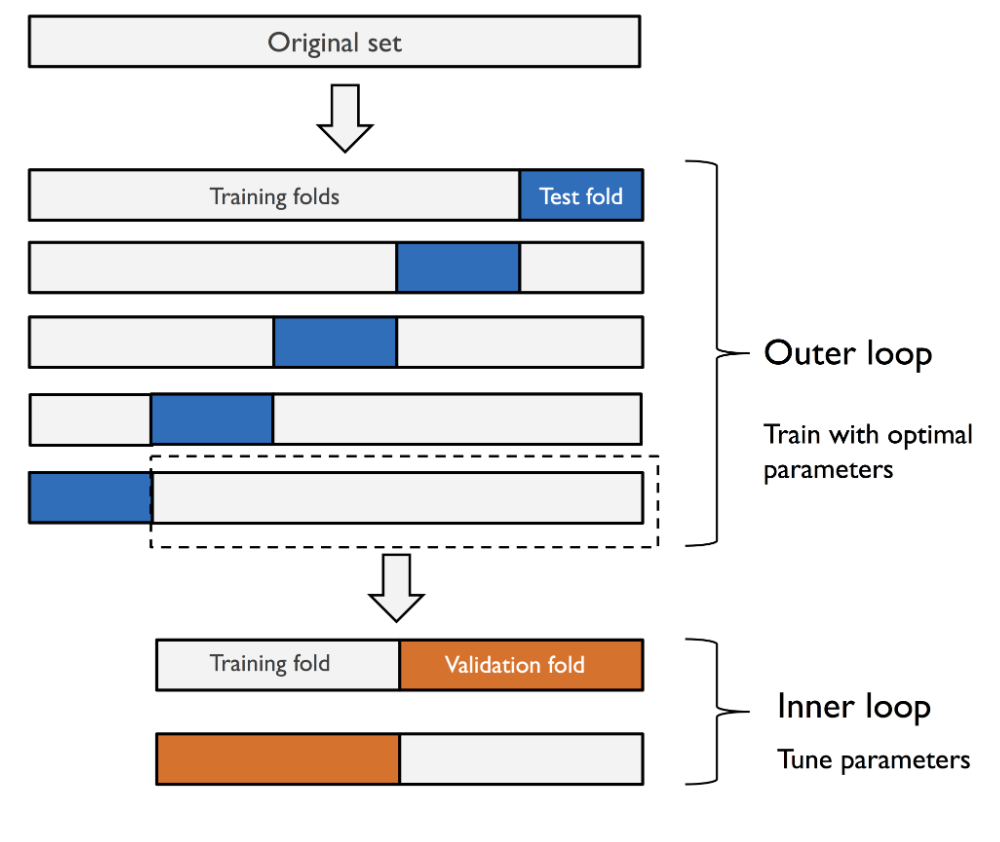
- ex) SVM 튜닝
gs = GridSearchCV(estimator=pipe_svc,
param_grid=param_grid,
scoring='accuracy',
cv=2)
scores = cross_val_score(gs, X_train, y_train,
scoring='accuracy', cv=5)
print('CV 정확도: %.3f +/- %.3f' % (np.mean(scores),
np.std(scores)))- ex) Decission Tree 튜닝
from sklearn.tree import DecisionTreeClassifier
gs = GridSearchCV(estimator=DecisionTreeClassifier(random_state=0),
param_grid=[{'max_depth': [1, 2, 3, 4, 5, 6, 7, None]}],
scoring='accuracy',
cv=2)
scores = cross_val_score(gs, X_train, y_train,
scoring='accuracy', cv=5)
print('CV 정확도: %.3f +/- %.3f' % (np.mean(scores),
np.std(scores)))reference
- 서적 '머신러닝 교과서 with 파이썬, 사이킷런, 텐서플로 개정 3판'0
