데이터베이스를 선택하거나 설계할 때, 우리는 종종 "데이터를 어디에, 어떻게 저장할 것인가?"라는 근본적인 질문에 직면합니다. 이때 가장 중요한 결정 중 하나가 바로 메모리 기반 DBMS(In-Memory DBMS)와 디스크 기반 DBMS(Disk-Based DBMS) 중 어떤 방식을 택할 것인지입니다. 이 두 방식은 단순히 저장 위치의 차이를 넘어 성능, 안정성, 비용, 그리고 내부 아키텍처까지 모든 면에서 각기 다른 특징과 트레이드오프를 가집니다.
이번 글에서는 메모리 기반 DBMS와 디스크 기반 DBMS의 핵심 특징과 장단점을 비교 분석하고, 시스템 장애에도 데이터를 안전하게 지키는 Write-Ahead Log(WAL)의 마법, 그리고 현대 데이터베이스 시스템을 관통하는 주요 설계 원칙인 버퍼링, 불변성, 정렬성에 대해 깊이 있게 살펴보겠습니다. 마지막으로, 다양한 실제 서비스 시나리오를 통해 어떤 상황에 어떤 DB 구조를 선택하는 것이 합리적인지 함께 고민해 보겠습니다.
1. 메모리 기반 DBMS (In-Memory DBMS): 속도의 극한을 추구하다
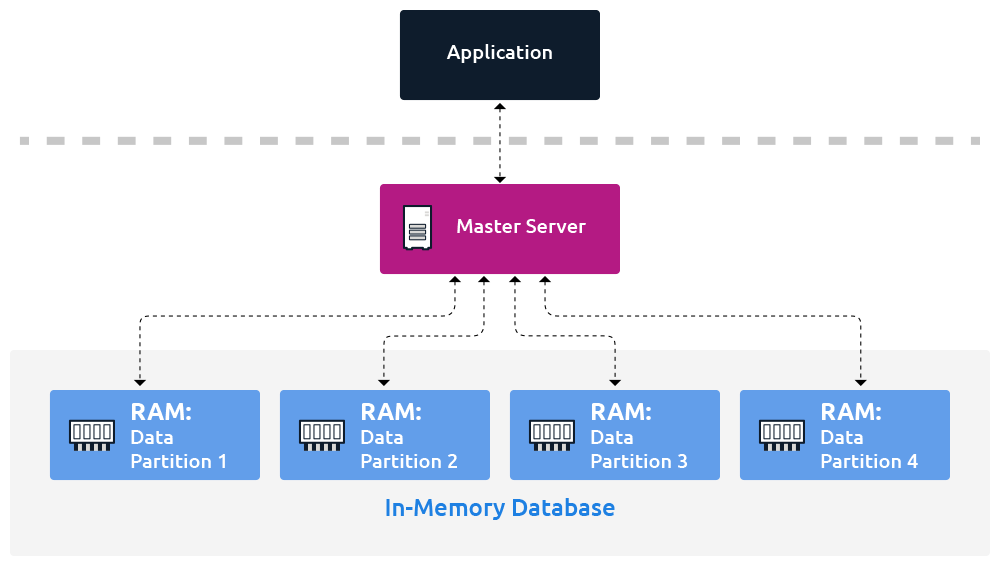
메모리 기반 DBMS는 이름에서 알 수 있듯이, 데이터를 거의 전적으로 RAM(Random Access Memory)에 저장하고 처리합니다. 디스크는 주로 트랜잭션 로그 기록이나 주기적인 백업, 즉 데이터 복구 및 지속성(Durability) 확보 용도로만 제한적으로 사용됩니다.
👍 장점:
- 압도적인 속도: 디스크 접근(수 밀리초)보다 수십에서 수백 배 빠른 메모리 접근(수십~수백 나노초) 속도를 활용하여 매우 낮은 지연 시간(Low Latency)과 높은 처리량(High Throughput)을 달성합니다.
- 간단한 데이터 구조 설계 가능성: 메모리 내에서는 포인터 참조만으로도 데이터에 빠르게 접근할 수 있어, 디스크 I/O를 고려한 복잡한 데이터 구조나 직렬화 오버헤드를 줄일 수 있습니다.
👎 단점:
- 내구성 부족 (Durability 취약점): RAM은 휘발성 저장 매체이므로, 시스템 충돌(Crash)이나 정전 발생 시 저장된 데이터가 유실될 위험이 존재합니다.
- 추가적인 하드웨어 및 복구 메커니즘 요구: 데이터 유실 방지를 위해 무정전 전원 공급 장치(UPS), 배터리 백업 RAM(BBRAM), 비휘발성 메모리(NVM), 그리고 정교한 디스크 백업 및 로그 기반 복구 전략(WAL, Checkpointing 등)이 필수적으로 요구됩니다.
- 높은 비용: 동일 용량 대비 RAM 가격이 디스크(SSD, HDD)보다 훨씬 비싸므로, 대규모 데이터를 모두 RAM에 유지하려면 상당한 비용이 소요됩니다.
실제 운영 환경에서는...
순수하게 메모리에만 데이터를 저장하고 지속성을 전혀 보장하지 않는 시스템은 드뭅니다. 대부분의 실용적인 메모리 기반 DBMS는 주기적인 디스크 스냅샷(Checkpointing)과 Write-Ahead Logging(WAL) 기법을 함께 사용하여, 빠른 성능을 유지하면서도 시스템 장애 시 데이터를 복구할 수 있도록 설계됩니다.
🤔 꼬리 질문: 메모리 기반 DBMS를 선택할 때, 비용 외에 가장 중요하게 고려해야 할 기술적 트레이드오프는 무엇이라고 생각하시나요? 모든 데이터를 메모리에 올리는 것이 항상 최선일까요?
2. 디스크 기반 DBMS (Disk-Based DBMS): 안정성과 대용량 데이터 처리의 강자
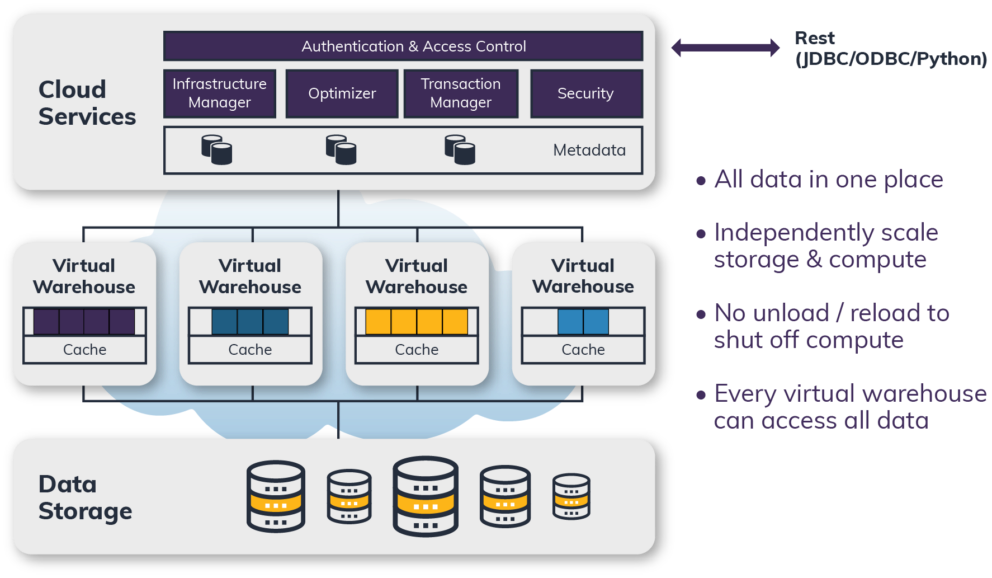
디스크 기반 DBMS는 데이터를 주로 디스크(SSD, HDD)와 같은 영구 저장 장치에 저장하며, 메모리(RAM)는 자주 접근하는 데이터를 빠르게 읽기 위한 캐시(Buffer Pool) 또는 정렬, 조인 등의 작업을 위한 임시 저장 공간으로 활용합니다.
👍 장점:
- 높은 내구성 (Durability): 디스크는 비휘발성 저장 매체이므로, 시스템 전원이 꺼지거나 장애가 발생해도 데이터가 안전하게 보존됩니다.
- 낮은 저장 비용: 테라바이트(TB) 이상의 대용량 저장 공간을 RAM에 비해 훨씬 저렴한 비용으로 구성할 수 있습니다.
- 다양한 최적화된 저장 구조 활용: B-Tree, LSM-Tree와 같은 효율적인 인덱스 구조, 정교한 버퍼 관리 알고리즘, 슬롯 페이지(Slotted Page) 등 디스크 I/O를 최소화하고 데이터 접근 효율을 높이기 위한 다양한 기술이 발전해 왔습니다.
👎 단점:
- 상대적으로 느린 속도: 디스크의 물리적인 헤드 이동이나 플래시 메모리 접근은 RAM 접근보다 본질적으로 느릴 수밖에 없습니다. 특히 랜덤 디스크 접근(Random I/O)은 성능 병목의 주요 원인이 됩니다.
- 복잡한 디스크 I/O 최적화 필요: 성능을 높이기 위해 버퍼 관리, 페이지 교체 알고리즘, 데이터 배치, 인덱스 설계 등 복잡한 최적화 기법이 요구됩니다.
- 페이지 단위 읽기의 비효율 가능성: 데이터를 페이지(블록) 단위로 읽고 쓰므로, 작은 크기의 데이터를 읽거나 쓸 때도 불필요하게 큰 데이터 단위를 처리해야 하는 비효율이 발생할 수 있습니다.
메모리 vs. 디스크: 단순한 저장 매체의 차이를 넘어서
"메모리 기반 데이터베이스를 단순히 거대한 페이지 캐시를 가진 디스크 기반 데이터베이스라고 말하는 것은 부당합니다." 라는 문구는 중요한 점을 시사합니다. 디스크 기반 시스템에서 데이터 페이지가 메모리에 캐시되어 있더라도, 데이터의 직렬화/역직렬화 형식, 디스크 접근에 최적화된 데이터 레이아웃 등으로 인해 순수 메모리 기반 시스템만큼의 최적화를 이루기는 어렵습니다.
메모리 환경에서는 포인터를 직접 참조하는 것이 빠르지만, 디스크 환경에서는 이러한 방식이 비효율적입니다. 디스크 기반 저장 구조는 넓고 얕은 트리 구조를 선호하는 경향이 있으며, 가변 크기 데이터 처리 등에도 특별한 고려가 필요합니다. 반면, 메모리 기반 시스템은 더 다양한 자료구조와 최적화 기법을 자유롭게 선택하고 구현할 수 있습니다.
🤔 꼬리 질문: SSD 기술의 발전으로 디스크 I/O 속도가 과거에 비해 매우 빨라졌습니다. 이러한 상황이 메모리 기반 DBMS와 디스크 기반 DBMS의 선택 기준에 어떤 영향을 미칠 것이라고 생각하시나요?
3. 시스템 장애에도 데이터가 살아남는 이유: Write-Ahead Log (WAL)의 마법
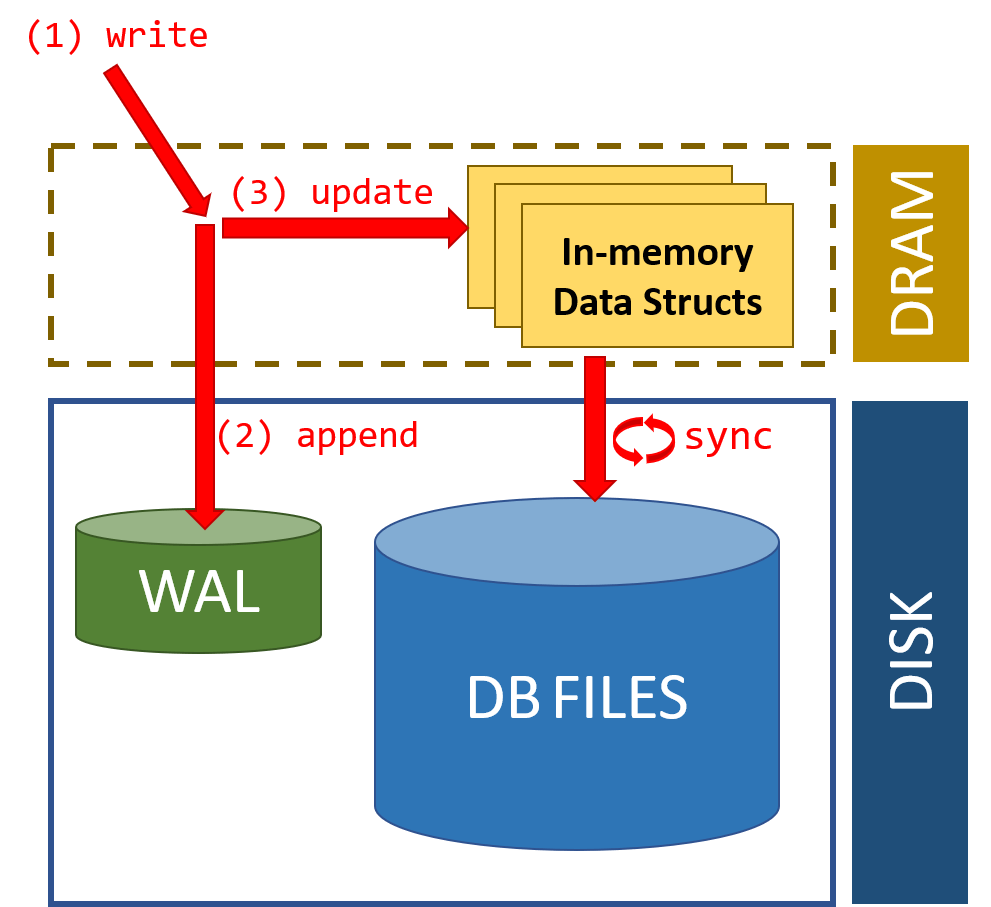
"시스템이 갑자기 다운되었는데, 어떻게 데이터가 안전하게 복구될 수 있을까요?" 많은 개발자들이 SQL은 능숙하게 사용하지만, 데이터베이스 내부의 이러한 복구 메커니즘에 대해서는 깊이 알지 못하는 경우가 많습니다. PostgreSQL, MySQL(InnoDB), MongoDB, Kafka 등 수많은 데이터 시스템이 장애나 전원 끊김에도 데이터를 안전하게 지키는 비결, 그 중심에는 바로 Write-Ahead Log (WAL), 또는 리두 로그(Redo Log)라고 불리는 기술이 있습니다.
WAL은 단순한 백업 로그가 아닙니다!
WAL은 시스템 장애 상황에서도 데이터의 내구성을 보장하고 일관된 상태로 시스템을 복구하는 핵심 메커니즘입니다. WAL이 강력한 이유는 다음과 같은 기능들을 수행하기 때문입니다.
- 내구성 (Durability) 확보:
- 데이터베이스는 실제 데이터 페이지를 변경하기 전에, 해당 변경 내용을 먼저 WAL(로그 버퍼를 거쳐 디스크의 로그 파일)에 순차적으로 안전하게 기록합니다.
- 트랜잭션이 커밋(Commit)되기 전에 관련된 모든 로그 레코드가 WAL에 먼저 기록되고 디스크에 플러시(Flush)되는 것을 보장합니다. (PostgreSQL의 경우
fsync)
- 크래시 복구 (Crash Recovery):
- 시스템이 예기치 않게 중단되었다가 재시작될 때, DBMS는 WAL을 읽어 마지막 체크포인트(Checkpoint) 이후에 기록된 로그들을 재실행(Redo)하여, 커밋되었지만 실제 데이터 파일에는 아직 반영되지 않았던 변경 사항들을 복원합니다. 이를 통해 데이터베이스를 장애 발생 직전의 일관된 상태로 되돌릴 수 있습니다.
- 복제 동기화 (Replication Synchronization):
- 분산 데이터베이스 시스템이나 데이터베이스 복제 환경에서, WAL은 변경 사항에 대한 신뢰할 수 있는 순차적인 스트림(Ordered Stream of Changes) 역할을 합니다. Primary(Master) 서버에서 발생한 변경 로그(WAL)를 Secondary(Replica/Slave) 서버로 전송하고 재실행함으로써, 데이터 복제를 정확하고 일관되게 수행할 수 있습니다. (MongoDB, Kafka 등에서도 유사한 로그 기반 복제 메커니즘 활용)
- 성능 향상 기여:
- WAL은 로그를 디스크에 순차적으로 기록(Sequential I/O)하는 구조입니다. 이는 디스크 헤드의 움직임을 최소화하여 랜덤 I/O보다 훨씬 빠릅니다.
- 실제 데이터 페이지 변경은 메모리(버퍼 풀)에서 우선 처리하고, 디스크에는 나중에 비동기적으로 또는 체크포인트 시점에まとめて 반영함으로써, 트랜잭션 처리 중 발생하는 디스크 I/O 부담을 줄여 응답 성능을 향상시킵니다. (작고 정렬된 로그 스캔 비용도 상대적으로 낮음)
체크포인팅 (Checkpointing)과의 관계:
WAL이 계속 누적되면 복구 시간이 길어질 수 있습니다. 체크포인팅은 특정 시점에 메모리(버퍼 풀)의 변경된 데이터 페이지들을 디스크의 실제 데이터 파일에 기록(Flush)하고, 해당 시점까지의 WAL 정보는 더 이상 복구에 필요하지 않음을 표시하는 과정입니다. 이를 통해 WAL의 크기를 관리하고, 장애 발생 시 복구해야 할 로그의 양을 줄여 복구 시간을 단축합니다.
🤔 꼬리 질문: WAL 방식이 성능에 미치는 긍정적인 영향과 부정적인 영향은 각각 무엇일까요? WAL 파일 관리가 제대로 되지 않으면 어떤 문제가 발생할 수 있을까요?
4. 현대 데이터베이스 시스템을 관통하는 설계 원칙: 버퍼링, 불변성, 정렬성
현대 데이터베이스 시스템은 단순히 데이터를 저장하는 것을 넘어, 고성능과 안정성을 달성하기 위해 정교한 내부 설계 원칙을 따릅니다. 그중에서도 버퍼링(Buffering), 불변성(Immutability), 정렬성(Ordering)은 핵심적인 개념입니다.
◼️ Buffering (버퍼링): 디스크 I/O 비용 절감의 기술
- 개념: 디스크는 데이터를 블록(페이지) 단위로 읽고 씁니다. 버퍼링은 데이터를 메모리(버퍼 풀)에 일시적으로 모아두었다가, 한 번에 디스크에 효율적으로 기록하거나, 자주 접근하는 데이터를 메모리에서 빠르게 제공하는 전략입니다.
- 효과: 디스크 I/O 횟수를 줄여 전체적인 성능을 향상시킵니다. 특히 B-Tree와 같은 인덱스 구조에서 메모리 내 버퍼를 활용하면(예: Lazy B-Trees), 실제 디스크 접근을 최소화하여 읽기/쓰기 비용을 크게 절감할 수 있습니다.
- 고려사항: "버퍼링은 비용을 줄이기 위한 선택지이지, 필수가 아니다. 시스템 설계자는 이를 적극적으로 활용하거나 완전히 배제할 수도 있다."는 말처럼, 모든 시스템에 버퍼링이 동일하게 적용되지는 않으며, 워크로드 특성에 따라 그 효율성이 달라질 수 있습니다.
◼️ Immutability (불변성): 데이터 일관성과 성능 확보의 열쇠
- 개념: 불변성은 한번 기록된 데이터를 직접 수정(덮어쓰기)하지 않고, 변경 사항이 발생하면 항상 새로운 위치에 데이터를 추가(Append-only)하거나 복사하여 수정(Copy-on-Write)하는 방식을 의미합니다.
- 구현 예시:
- LSM-Tree (Log-Structured Merge Tree): Cassandra, HBase, RocksDB 등 많은 NoSQL 및 스토리지 엔진에서 사용되는 자료구조로, 모든 쓰기 작업을 정렬된 형태로 메모리(Memtable)에 기록 후, 이를 불변 파일(SSTable) 형태로 디스크에 순차적으로 기록합니다. 업데이트나 삭제는 새로운 데이터를 추가하거나 삭제 표시(Tombstone)를 하는 방식으로 처리됩니다.
- Bw-Tree: 전통적인 B-Tree가 제자리 수정(In-place update) 방식을 사용하는 것과 달리, Bw-Tree는 불변성을 도입하여 동시성 제어와 쓰기 성능을 개선한 B-Tree의 변형입니다.
- 장점:
- 동시성 제어 용이: 데이터가 직접 변경되지 않으므로 잠금(Lock) 메커니즘을 단순화하거나 회피할 수 있어 동시성을 높입니다.
- 로그 기반 복구 및 스냅샷 용이: 변경 이력이 순차적으로 기록되므로 특정 시점으로의 복구나 스냅샷 생성이 용이합니다.
- 캐시 일관성 유지 용이: 데이터가 불변이므로 캐시된 데이터의 유효성을 판단하기 쉽습니다.
- 순차 쓰기로 인한 쓰기 성능 향상: 디스크에 순차적으로 데이터를 기록하므로 랜덤 쓰기보다 훨씬 빠릅니다.
◼️ Ordering (정렬성): 쿼리 성능을 좌우하는 데이터 배치 전략
- 개념: 데이터가 디스크나 메모리에 어떤 순서로 저장되느냐는 특정 유형의 쿼리 성능에 매우 큰 영향을 미칩니다.
- 영향:
- 키(Key) 순서로 정렬된 구조 (예: B-Tree 인덱스, 정렬된 SSTable): 특정 키 값 조회뿐만 아니라, 범위 조회(Range Query, 예:
WHERE age BETWEEN 20 AND 30)나 순서 기반 조회(ORDER BY)에 매우 강력한 성능을 제공합니다. - 정렬되지 않은 구조 (예: Heap Table): 데이터 삽입(Append)은 빠를 수 있지만, 특정 데이터를 찾기 위해서는 전체를 스캔해야 하므로 조회 성능이 떨어질 수 있습니다. (물론 별도의 인덱스를 통해 보완 가능)
- 데이터 압축 효율: 유사한 데이터가 인접하게 저장될수록 압축 효율이 높아지므로, 정렬 방식은 스토리지 효율성에도 영향을 미칩니다.
- 키(Key) 순서로 정렬된 구조 (예: B-Tree 인덱스, 정렬된 SSTable): 특정 키 값 조회뿐만 아니라, 범위 조회(Range Query, 예:
💡 인덱스 구조와 간접 참조 (Indirection)
- Primary Index vs. Secondary Index: Primary Index는 주로 데이터 레코드를 고유하게 식별하고 물리적인 저장 위치와 직접적으로 관련된 인덱스입니다. Secondary Index는 Primary Key가 아닌 다른 컬럼을 기준으로 생성된 인덱스입니다.
- 간접 참조 (Indirection): Secondary Index가 데이터 레코드의 실제 물리적 주소를 직접 가리키지 않고, 대신 Primary Key 값을 가리키도록 설계하는 방식입니다. 실제 데이터에 접근하려면 Secondary Index 탐색 → Primary Key 획득 → Primary Index 탐색 → 데이터 레코드 접근의 과정을 거치게 됩니다. (예: MySQL InnoDB의 Secondary Index)
- 트레이드오프:
- 장점 (쓰기 중심): 데이터 레코드의 물리적 위치가 변경되더라도(예: 페이지 분할, 데이터 이동), Secondary Index는 Primary Key 값만 가지고 있으므로 Secondary Index 전체를 업데이트할 필요가 없어 쓰기(특히 업데이트) 비용을 줄일 수 있습니다.
- 단점 (읽기 중심): Secondary Index를 통한 데이터 조회 시, 두 번의 인덱스 탐색이 필요하므로 읽기 성능이 다소 저하될 수 있습니다.
실무 팁: 쓰기 작업이 매우 빈번한(Write-heavy) 시스템에서는 간접 참조 방식이 유리할 수 있고, 읽기 작업이 훨씬 많은(Read-heavy) 시스템에서는 Secondary Index가 데이터 위치를 직접 가리키는 방식이 더 빠를 수 있습니다.
🤔 꼬리 질문: 불변성(Immutability)을 가진 데이터 구조가 동시성 제어에 유리한 이유는 무엇일까요? 또한, 불변성으로 인해 발생할 수 있는 단점(예: 공간 사용량 증가, 가비지 컬렉션 필요성)은 어떻게 해결할 수 있을까요?
5. 시나리오별 데이터베이스 설계 선택: 정답은 없지만 최선은 있다!
지금까지 살펴본 다양한 데이터베이스의 특징과 설계 원칙을 바탕으로, 실제 서비스 시나리오별로 어떤 데이터베이스 구조를 선택하는 것이 합리적일지 고민해 보겠습니다.
시나리오 #1: 글로벌 메시징 서비스의 데이터 저장 구조 설계
- 요구사항:
- 전 세계 수억 명 사용자, 초당 수십만 건의 메시지 전송 (고성능, 저지연)
- 메시지 빠른 전송, 필요시 삭제/복구 가능
- 채팅 히스토리 24개월 보존, 실시간 검색 가능
- 장애 시 데이터 유실 제로 (높은 내구성)
- 클라우드 기반, 비용 효율성 중요
- 핵심 질문:
- 메시지 저장소: In-Memory vs. Disk-Based?
- 실시간 복제 전략은?
- 장애 복구와 성능을 동시에 만족시키려면?
- 설계 방향 (복합 구조):
- 실시간 메시지 처리 (In-Memory + WAL):
- Redis Streams 또는 유사 인메모리 큐/DB: 메시지 수신 및 임시 저장, 순서 보장, 빠른 전송 처리에 활용. (응답 지연 20ms 이내 목표)
- WAL (Write-Ahead Log): 모든 수신 메시지 로그를 EBS와 같은 영구 디스크에 순차 기록하여 내구성 확보. 장애 발생 시 WAL 기반으로 정확한 복구.
- Checkpointing: 주기적으로 인메모리 상태의 스냅샷을 디스크에 저장하여 복구 시간 단축.
- 고비용 해결: 모든 메시지가 아닌, "최근 X분/X시간"의 활성 대화만 메모리에 유지하고, 나머지는 디스크 기반 DB로 이전하는 전략 (Tiered Storage).
- 장기 보존 및 검색 (Disk-Based):
- PostgreSQL (Row-Oriented) 또는 Cassandra (Column-Family):
- PostgreSQL: ACID 트랜잭션, 강력한 SQL 기능, 성숙한 기술. 사용자 계정 정보, 친구 관계 등 관계형 데이터 관리에 적합. 채팅 히스토리 저장 및 기본적인 검색(날짜 범위 등)에 활용 가능.
- Cassandra: 뛰어난 쓰기 성능, 수평 확장성, 고가용성. 대량의 메시지 데이터(수 TB 이상)를 시간 기반 파티셔닝 등으로 분산 저장.
- B-Tree 또는 LSM-Tree 기반 인덱스: 과거 대화 검색, 특정 조건(날짜, 사용자 등) 검색 최적화.
- 캐싱: 자주 조회되는 최근 메시지나 사용자 정보는 Redis 등으로 캐싱하여 응답 속도 향상.
- PostgreSQL (Row-Oriented) 또는 Cassandra (Column-Family):
- 복제 및 데이터 파이프라인 (CDC + 메시지 큐):
- Kafka 또는 유사 메시지 큐: 인메모리 DB에서 처리된 메시지나 Disk-Based DB의 변경 사항(CDC - Change Data Capture 활용)을 비동기적으로 Kafka에 발행.
- 다양한 소비자(Consumer):
- Disk-Based DB로의 데이터 적재 (장기 보존용)
- Elasticsearch로의 데이터 동기화 (전문 검색 기능용)
- 분석 시스템으로의 데이터 전송
- 백업 및 복구 (클라우드 스토리지 활용):
- S3 또는 유사 객체 스토리지: DB 스냅샷, WAL 아카이브 로그 등을 주기적으로 백업하여 재해 발생 시 완전 복원 가능하도록 준비.
- 실시간 메시지 처리 (In-Memory + WAL):
- 참고 아키텍처:
- WhatsApp: Erlang 기반 인메모리 큐 + RocksDB(LSM-Tree 기반 임베디드 스토리지 엔진) 디스크 저장.
- LINE: 메시지 초기 처리 Redis → Kafka CDC → HBase(Column-Family)에 장기 저장.
- Discord: 실시간 채팅은 인메모리 기술 활용, 영구 데이터는 ScyllaDB(Cassandra 호환) 및 PostgreSQL 사용.
시나리오 #2: 실시간 재고/주문 관리 시스템 (예: 대형 이커머스)
- 요구사항:
- 수천~수만 개 상품의 재고 변동 즉시 반영.
- 초당 수만 건 이상의 주문 동시 처리.
- 이중 결제, 재고 초과 구매(Overselling) 절대 방지.
- 장애 시에도 재고/주문 내역 정확히 복구 (강한 일관성 및 내구성).
- 설계 선택 (In-Memory + Disk-Based RDBMS 조합):
- 재고 확인 및 임시 예약 (In-Memory):
- Redis (또는 유사 인메모리 DB): 주문 시점의 상품 재고 상태를 매우 빠르게 확인하고 원자적 연산(Atomic Operation, 예:
DECRBY)으로 감소. - 분산 락(Distributed Lock) 활용: 동일 상품에 대한 동시 주문으로 인한 Race Condition 방지.
- 임시 예약 (TTL 활용): 재고 감소 후 실제 결제가 완료될 때까지 일정 시간(예: 5분) 동안 해당 재고를 임시 예약 상태로 설정 (Redis Key에 TTL 적용). 결제 실패 시 롤백 용이.
- Redis (또는 유사 인메모리 DB): 주문 시점의 상품 재고 상태를 매우 빠르게 확인하고 원자적 연산(Atomic Operation, 예:
- 주문 확정 및 영구 저장 (Disk-Based RDBMS):
- PostgreSQL 또는 MySQL (InnoDB):
- 모든 주문 정보는 WAL에 먼저 기록된 후, 최종적으로 RDBMS에 ACID 트랜잭션을 통해 안전하게 확정 저장.
- 결제 완료, 배송 정보 업데이트, 고객 서비스 이력 등 주문 생명주기 전반을 관리.
- PostgreSQL 또는 MySQL (InnoDB):
- 비동기 처리 (메시지 큐):
- 주문 확정 후, 재고 차감 확정, 결제 시스템 연동, 배송 시스템 알림 등 후속 작업들은 메시지 큐(Kafka, RabbitMQ)를 통해 비동기적으로 처리하여 주문 처리 응답 시간을 단축.
- 재고 확인 및 임시 예약 (In-Memory):
- 이유:
- 실시간 재고 확인 및 선점에는 속도가 생명이므로 인메모리 DB가 적합.
- 실제 주문 데이터의 정확성과 일관성, 내구성은 RDBMS의 ACID 트랜잭션으로 보장.
- 두 시스템의 장점을 결합하여 속도와 안정성을 동시에 확보.
시나리오 #3: 대규모 A/B 테스트 로그 분석 플랫폼 (예: 콘텐츠 추천 서비스)
- 요구사항:
- 수천만 사용자의 클릭/시청/구매 등 행동 로그 실시간 수집.
- 실시간 대시보드에서 트래픽 추이, 전환율 등 A/B 테스트 결과 분석.
- 분석은 주로 집계(Aggregation) 및 필터(Filtering) 기반 조회.
- 데이터의 완전한 정확성보다는 분석 속도와 시스템 확장성 우선.
- 설계 선택 (스트리밍 처리 + Column-Oriented 분석 DB + Data Lake):
- 로그 수집 및 실시간 스트림 처리:
- Kafka: 대량의 로그 데이터를 안정적으로 수집하는 메시지 브로커.
- Apache Flink 또는 Apache Spark Streaming: Kafka로부터 로그 스트림을 받아 실시간으로 집계, 변환, 간단한 분석 수행.
- 실시간 분석 및 대시보드용 저장소 (Column-Oriented):
- ClickHouse, Apache Druid, 또는 Google BigQuery (스트리밍 삽입): 스트림 처리 결과를 저장하여 실시간 대시보드(예: Grafana, Superset, Looker)에서 빠르게 조회 및 시각화.
- 컬럼 지향 저장 방식을 통해 특정 필드 기준 집계 및 필터링 성능 최적화.
- 장기 보존 및 심층 분석 (Data Lake):
- 원본 로그 데이터 또는 Flink/Spark 처리 결과(중간 데이터)를 Parquet, ORC와 같은 컬럼 기반 파일 포맷으로 변환하여 S3, GCS, HDFS와 같은 저렴한 객체 스토리지(Data Lake)에 장기 보존.
- 필요시 Spark SQL, Presto/Trino, Athena 등을 사용하여 Data Lake에 저장된 데이터에 대해 복잡한 배치 분석 수행.
- 로그 수집 및 실시간 스트림 처리:
- 이유:
- 실시간 분석 요구사항과 대용량 로그 데이터 처리를 동시에 만족시켜야 함.
- Column-Oriented DB는 집계 및 필터링 쿼리에 매우 효율적.
- Data Lake는 저렴한 비용으로 모든 원시 데이터를 저장하고, 필요에 따라 다양한 방식으로 분석할 수 있는 유연성을 제공.
- 인메모리 DB는 주로 실시간 스트림 처리 과정에서의 상태 저장(Flink/Spark의 State Backend)이나, 아주 최근 데이터에 대한 빠른 조회를 위한 보조적인 역할로 사용될 수 있음.
시나리오 #4: 글로벌 소셜미디어 타임라인 서비스 (예: 트위터, 인스타그램 피드)
- 요구사항:
- 수백만, 수억 명의 사용자가 자신의 뉴스피드/타임라인을 실시간으로 스크롤.
- 새로운 게시물, 좋아요, 댓글 등 사용자 활동이 즉시 반영되어야 함.
- 최신 게시물은 매우 빠르게 로드되어야 하며, 오래된 게시물은 상대적으로 느려도 무방.
- 읽기(Read)와 쓰기(Write) 작업 모두 매우 빈번하며, 데이터는 시간 흐름에 따라 중요도가 감소하는 경향.
- 설계 선택 (In-Memory + Disk-Based NoSQL (LSM-Tree) + 검색 엔진 조합):
- 최신 피드 및 핫 콘텐츠 캐싱 (In-Memory):
- Redis (Sorted Set, List 등): 각 사용자의 개인화된 타임라인 중 최신 N개의 게시물 ID 목록을 우선순위(시간, 관련도 등) 기반으로 Redis Sorted Set에 저장하여 매우 빠르게 조회. "핫"한 게시물이나 사용자 정보도 캐싱.
- TTL(Time-To-Live) 활용: 일정 시간이 지난 데이터는 Redis에서 자동으로 제거하여 메모리 사용량 관리.
- 전체 게시물 데이터 영구 저장 (Disk-Based NoSQL - LSM-Tree):
- Apache Cassandra 또는 ScyllaDB: 수십억, 수백억 건의 게시물 데이터를 사용자 ID 및 시간 기반 파티셔닝을 통해 분산 저장. LSM-Tree 구조 덕분에 높은 쓰기 처리량 보장.
- 타임라인 조회 시, Redis에서 캐시 미스(Cache Miss)가 발생하면 Cassandra/ScyllaDB에서 해당 사용자의 오래된 게시물을 페이지네이션하여 조회.
- 텍스트 검색 기능 (검색 엔진):
- Elasticsearch 또는 OpenSearch: 게시물 내용에 대한 전문 검색 기능을 제공하기 위해, Cassandra/ScyllaDB의 데이터를 비동기 CDC(Change Data Capture) 파이프라인을 통해 검색 엔진으로 동기화.
- 최신 피드 및 핫 콘텐츠 캐싱 (In-Memory):
- 이유:
- 다층적(Tiered) 스토리지 전략: 가장 빈번하게 접근되고 최신성이 중요한 데이터는 가장 빠른 인메모리 DB에, 전체 데이터는 확장성과 쓰기 성능이 뛰어난 디스크 기반 NoSQL에, 검색 기능은 전문 검색 엔진에 분담.
- 각 데이터 저장소가 자신의 강점에 맞는 역할만 수행하도록 하여 전체 시스템의 성능과 효율성 극대화.
- LSM-Tree 기반 NoSQL은 키-범위 스캔(Key-Range Scan, 예: 특정 사용자의 특정 시간 범위 게시물 조회)에 비교적 효율적이므로 타임라인 조회에 적합.
🤔 꼬리 질문: 위 시나리오들 외에, 여러분이 경험했거나 고민해 본 서비스에서 어떤 데이터베이스 조합이 가장 효과적이었는지, 그리고 그 이유는 무엇이었는지 이야기해 주실 수 있나요? 특정 기술 선택의 성공/실패 경험이 있다면 공유해주세요!
결론: 데이터베이스 선택, 정답은 없지만 최적의 균형점을 찾아라!
메모리 기반 DBMS와 디스크 기반 DBMS, 그리고 그 안의 다양한 아키텍처와 설계 원칙들은 각각 뚜렷한 장점과 트레이드오프를 가지고 있습니다. WAL을 통한 내구성 확보, 버퍼링/불변성/정렬성을 활용한 성능 최적화, 그리고 서비스 시나리오에 맞는 DB 조합 선택은 성공적인 시스템 구축의 핵심입니다.
"하나의 기술이 모든 문제를 해결할 수 있다"는 생각보다는, 애플리케이션의 구체적인 요구사항(성능, 내구성, 비용, 확장성, 일관성 수준, 개발 용이성 등)을 면밀히 분석하고, 각 기술의 특성을 정확히 이해하여 가장 합리적인 균형점을 찾는 것이 중요합니다. 이 글이 여러분의 데이터베이스 시스템 설계 여정에 깊이 있는 통찰과 실질적인 도움을 제공했기를 바랍니다.
