백엔드 서비스를 개발하고 운영하는 과정에서 시스템의 상태를 정확히 파악하고, 문제가 발생했을 때 신속하게 원인을 찾아 해결하는 능력은 매우 중요합니다. 이때 가장 기본적이면서도 강력한 도구가 바로 로그(Log)와 메트릭(Metric)입니다. 이 두 가지를 효과적으로 수집하고 활용하는 것은 안정적인 서비스 운영의 핵심이라고 할 수 있습니다.
이번 글에서는 로그와 메트릭의 기본 개념부터 시작하여, 왜
System.out.println대신 로깅 프레임워크를 사용해야 하는지, 그리고 Spring Boot 환경에서 메트릭 수집을 위한 강력한 추상화 라이브러리인 마이크로미터(Micrometer), 마지막으로 실질적인 로깅 구현을 위한 Logback 프레임워크의 아키텍처와 설정 방법까지 깊이 있게 다뤄보겠습니다.
1. 로그(Log)와 메트릭(Metric): 무엇이 다르고 왜 중요할까?
◼️ 로그 (Log): 시간의 흐름에 따른 사건의 기록
- 정의: 로그는 서버나 애플리케이션이 동작하는 동안 발생하는 상태 변화나 주요 이벤트, 오류 정보 등을 시간 순서대로 기록한 결과입니다. 마치 시스템의 일기와 같다고 할 수 있습니다.
- 목적:
- 오류 추적 및 문제 해결: 시스템 장애 발생 시 로그를 분석하여 문제의 원인을 파악하고 디버깅하는 데 결정적인 단서를 제공합니다.
- 행위 감사 및 보안 분석: 특정 작업의 수행 기록, 사용자 접근 기록 등을 통해 보안 사고를 추적하거나 규정 준수를 위한 감사 자료로 활용됩니다.
- 서비스 동작 이해: 시스템의 특정 기능이 어떻게 동작하는지, 어떤 흐름으로 데이터가 처리되는지 등을 이해하는 데 도움을 줍니다.
- 특징: 주로 텍스트 기반의 이벤트 데이터이며, 특정 시점에 발생한 구체적인 사건에 대한 정보를 담고 있습니다.
◼️ 메트릭 (Metric): 시스템 상태를 나타내는 정량적 지표
- 정의: 메트릭은 시스템의 성능, 상태, 사용량 등에 대한 통계적이고 정량적인 정보를 의미합니다. 특정 시점 또는 기간 동안의 시스템 상태를 숫자로 표현합니다.
- 목적:
- 현재 상태 모니터링: CPU 사용량, 메모리 사용량, 디스크 공간, 네트워크 트래픽, 요청 처리량(TPS/RPS), 응답 시간 등을 실시간으로 파악하여 시스템이 정상적으로 동작하는지 감시합니다.
- 성능 병목 지점 분석: 어떤 부분에서 성능 저하가 발생하는지, 리소스가 부족한지 등을 파악하여 최적화 작업을 수행합니다.
- 용량 계획 (Capacity Planning): 현재 사용량 추세를 분석하여 향후 필요한 리소스 규모를 예측하고 증설 계획을 수립합니다.
- 비즈니스 현황 파악: 일일 활성 사용자(DAU), 사용자 리텐션, 서비스별 요청 수 등 비즈니스 KPI와 관련된 지표를 수집하여 서비스 성장 및 사용자 행동을 분석합니다.
- 특징: 주로 숫자 형태의 시계열 데이터(시간에 따라 변화하는 데이터)이며, 집계(Aggregation) 및 시각화(Visualization)를 통해 추세를 파악하고 이상 징후를 감지하는 데 활용됩니다.
🤔 경험 공유: 로그와 메트릭 수집 경험
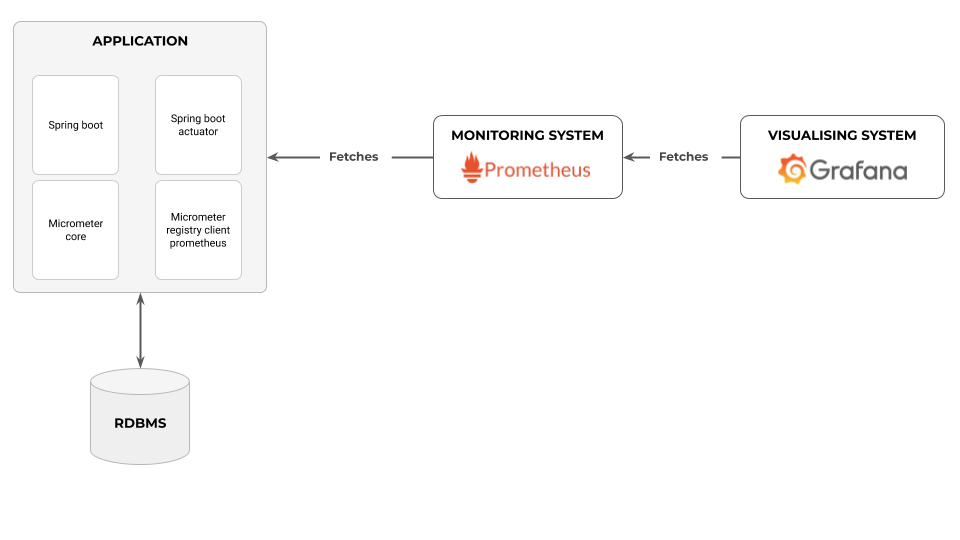
저의 경우, Spring Boot Actuator를 활용하여 애플리케이션 메트릭을 수집하고, 이를 Prometheus에 저장한 뒤 Grafana를 통해 시각화하여 모니터링 대시보드를 구축한 경험이 있습니다. 주요 수집 지표는 다음과 같습니다.
- 시스템 리소스: CPU 사용량, 메모리 사용량, JVM 힙(Heap) 사용량
- 애플리케이션 내부 상태: Tomcat 스레드 풀 활성 스레드 수, 데이터베이스 커넥션 풀 상태(활성/유휴 커넥션 수)
- 오류 발생 현황:
ERROR레벨 로그 발생 빈도로깅은 Logback 프레임워크를 사용했으며, 로그는 Loki에 7일간 보관하도록 설정했습니다. 특히, 분산 환경에서 요청 추적을 용이하게 하기 위해 MDC(Mapped Diagnostic Context)를 활용하여 각 로그에 트랜잭션 ID나 사용자 ID 등을 포함시켰습니다.
🤓 수집 이유:
- CPU, 메모리, JVM 사용량: 서비스의 전반적인 안정성과 리소스 포화 상태를 파악하여 잠재적인 문제를 사전에 감지하기 위함입니다.
- 톰캣 스레드 풀 및 DB 커넥션 풀 상태: 웹 서버의 동시 요청 처리 능력과 데이터베이스 접근 관련 병목 현상을 모니터링하여, 사용자 요청 처리에 지연이 발생하거나 시스템이 불안정해지는 상황을 신속히 파악하고 대응하기 위함입니다.
- ERROR 레벨 로그 증가량: 예상치 못한 오류 발생 빈도를 추적하여 심각한 버그나 시스템 이상을 즉시 인지하고 조치하기 위함입니다.
2. 로깅, 왜 System.out.println 대신 로깅 프레임워크를 써야 할까?
"간단하게 System.out.println()으로 로그를 찍으면 되지 않나요?" 라고 생각할 수 있습니다. 하지만 실제 운영 환경에서는 다음과 같은 이유로 로깅 프레임워크(예: Logback, Log4j2, SLF4J) 사용이 강력히 권장됩니다.
- 성능 고려:
System.out.println()은 동기적으로 동작하며, 특히 많은 양의 로그를 출력할 경우 I/O 대기로 인해 애플리케이션 성능에 부정적인 영향을 미칠 수 있습니다. 로깅 프레임워크는 비동기 로깅, 버퍼링 등 성능 최적화 기능을 제공합니다. - 로그 레벨 제어: 로깅 프레임워크는
TRACE,DEBUG,INFO,WARN,ERROR등 다양한 로그 레벨을 지원합니다. 이를 통해 개발 환경에서는 상세한 디버그 로그를, 운영 환경에서는 심각한 오류 위주의 로그만 선택적으로 출력하도록 유연하게 제어할 수 있습니다.System.out.println()은 이러한 레벨 구분이 어렵습니다. - 다양한 출력 대상(Appender): 콘솔뿐만 아니라 파일(일별 롤링, 크기별 롤링), 데이터베이스, 네트워크 소켓(예: ELK Stack, Loki로 전송) 등 다양한 대상으로 로그를 보낼 수 있습니다.
- 유연한 출력 형식(Layout/Encoder): 로그 메시지의 출력 형식을 자유롭게 커스터마이징할 수 있습니다. (타임스탬프, 스레드 이름, 클래스명, 로그 레벨 등 포함)
- 환경별 설정 분리 및 필터링: 개발, 스테이징, 운영 등 환경별로 다른 로깅 설정을 적용하거나, 특정 조건(예: 특정 패키지, 특정 마커)에 따라 로그 출력을 필터링하는 고급 기능을 제공합니다.
- 중앙 집중식 로그 관리 용이: 외부 로그 수집 시스템과의 연동이 용이하여, 여러 서버에서 발생하는 로그를 중앙에서 통합적으로 관리하고 분석할 수 있습니다.
결론적으로, System.out.println()은 간단한 테스트나 디버깅에는 유용할 수 있지만, 실제 서비스 운영 환경에서는 로깅 프레임워크가 제공하는 강력하고 유연한 기능을 활용하는 것이 훨씬 효율적이고 안정적입니다.
3. 마이크로미터(Micrometer): 애플리케이션 메트릭 수집의 표준 인터페이스
서비스를 안정적으로 운영하기 위해서는 애플리케이션의 CPU, 메모리, 커넥션 사용량, 고객 요청 수 등 다양한 지표(메트릭)를 지속적으로 모니터링해야 합니다. 이를 통해 문제 발생을 사전에 감지하고, 실제 문제가 발생했을 때 원인을 신속하게 파악하여 대처할 수 있습니다.
예를 들어, 메모리 사용량이 급증하는 것을 모니터링 시스템을 통해 발견했다면, 메모리 누수 관련 코드를 빠르게 찾아 수정할 수 있을 것입니다.
현재 시장에는 Prometheus, Datadog, New Relic, Dynatrace 등 수많은 모니터링 툴이 존재합니다. 이러한 툴을 사용하려면 시스템의 다양한 지표를 각 툴이 요구하는 형식에 맞춰 전달해야 합니다.
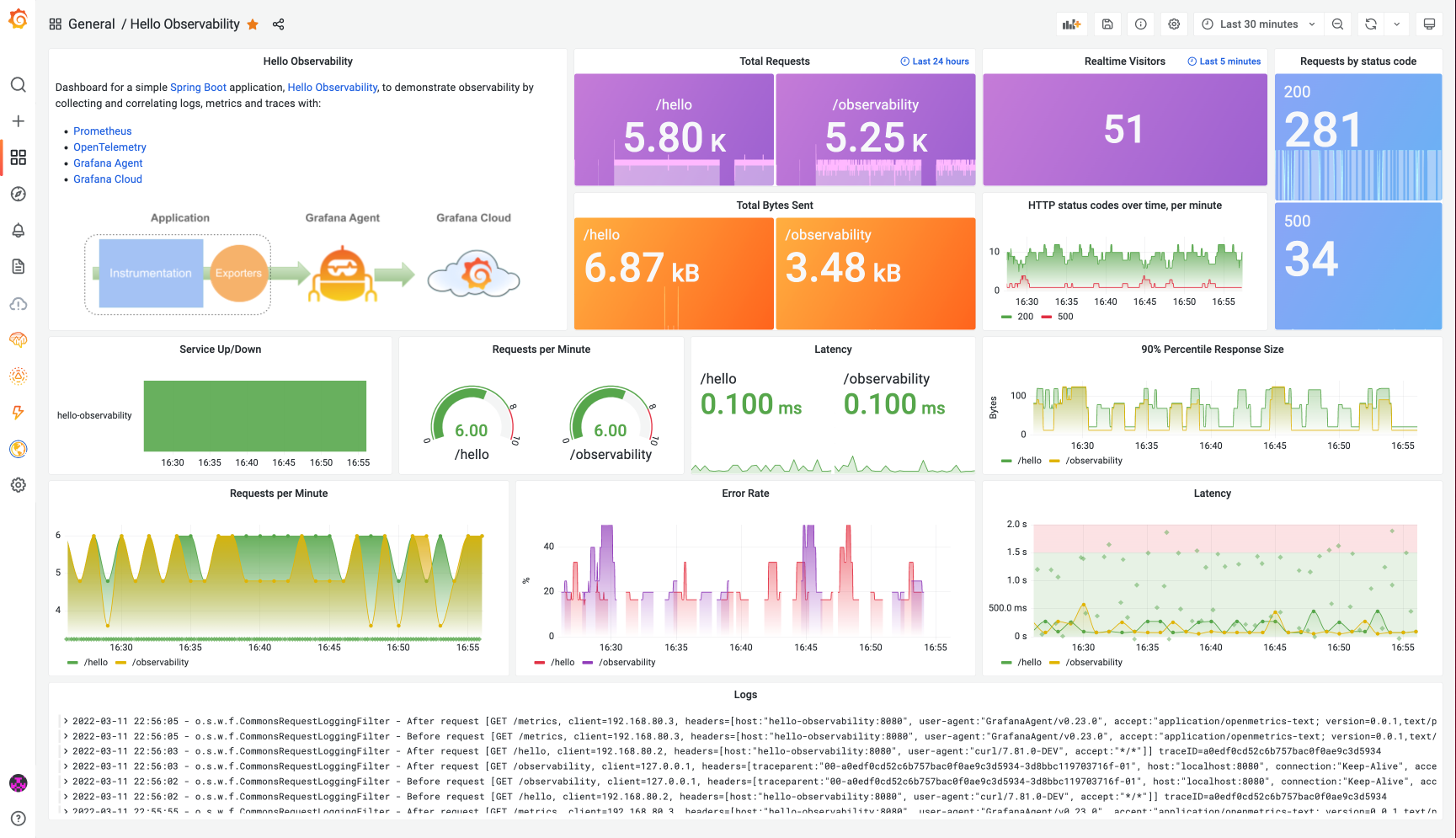
만약 모니터링 툴을 JMX에서 Prometheus로 변경한다면 어떻게 될까요? 기존에 JMX 형식에 맞춰 작성했던 메트릭 수집 코드를 모두 Prometheus 형식으로 변경해야 하는 번거로움이 발생합니다.
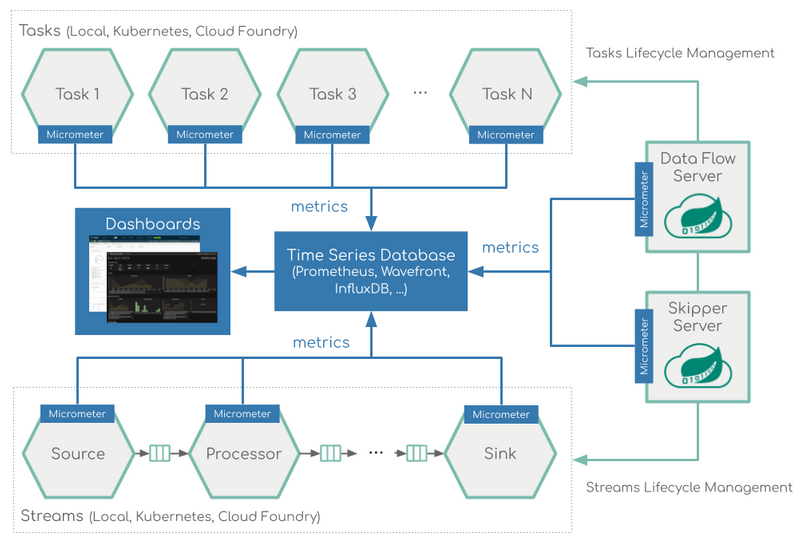
이러한 문제를 해결하기 위해 등장한 것이 바로 마이크로미터(Micrometer) 라이브러리입니다.
◼️ 마이크로미터란? 애플리케이션 메트릭 파사드(Facade)
마이크로미터는 다양한 모니터링 시스템에 대한 측정 지표(메트릭) 수집 인터페이스를 추상화한 라이브러리입니다. 마치 SLF4J가 다양한 로깅 구현체에 대한 추상화를 제공하는 것처럼, 마이크로미터는 다양한 모니터링 툴에 대한 "계측(Instrumentation) 파사드" 역할을 합니다.
- 표준화된 메트릭 수집 방식: 개발자는 마이크로미터가 제공하는 표준 API를 사용하여 애플리케이션의 메트릭을 한 번만 계측하면 됩니다.
- 모니터링 툴 유연성: 실제 사용하는 모니터링 툴에 맞는 마이크로미터 구현체(Registry) 의존성만 추가하면, 별도의 코드 변경 없이 해당 툴로 메트릭을 전송할 수 있습니다. 나중에 모니터링 툴을 변경하더라도 애플리케이션 코드는 그대로 유지한 채 구현체만 교체하면 됩니다.
- Spring Boot Actuator 기본 내장: Spring Boot Actuator는 마이크로미터를 기본으로 내장하고 있어, 별도의 복잡한 설정 없이도 다양한 기본 메트릭을 손쉽게 수집하고 노출할 수 있습니다.
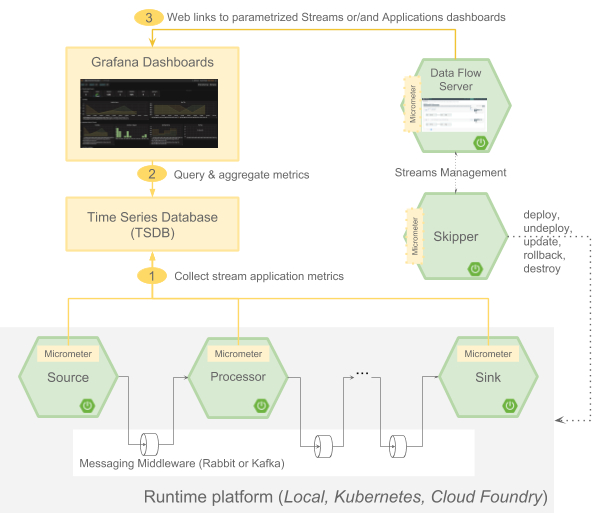
◼️ 액추에이터와 마이크로미터를 통한 메트릭 확인
Spring Boot Actuator를 사용하면 /actuator/metrics 엔드포인트를 통해 마이크로미터가 수집하고 있는 다양한 메트릭 목록을 확인할 수 있습니다.
- 전체 메트릭 목록 조회:
http://localhost:8080/actuator/metrics - 특정 메트릭 상세 조회:
http://localhost:8080/actuator/metrics/{metric.name}(예:jvm.memory.used) - 태그(Tag)를 이용한 필터링:
http://localhost:8080/actuator/metrics/{metric.name}?tag=KEY:VALUE(예:jvm.memory.used?tag=area:heap)http.server.requests메트릭의 경우uri,method,status,exception,outcome등의 태그를 사용하여 세분화된 분석이 가능합니다.
◼️ 마이크로미터가 기본 제공하는 다양한 메트릭 종류
마이크로미터와 액추에이터는 다음과 같이 다양한 종류의 메트릭을 자동으로 수집하여 제공합니다.
- JVM 메트릭 (
jvm.*): 메모리 및 버퍼 풀 사용량, 가비지 컬렉션 통계, 스레드 활용도, 클래스 로딩 수, JIT 컴파일 시간 등 - 시스템 메트릭 (
system.*,process.*,disk.*): CPU 사용량, 파일 디스크립터 수, 시스템 가동 시간, 사용 가능한 디스크 공간 등 - 애플리케이션 시작 메트릭 (
application.started.time,application.ready.time): 애플리케이션 시작 및 요청 처리 준비 완료까지 걸린 시간 - Spring MVC 메트릭 (
http.server.requests): URI별, HTTP 메서드별, 상태 코드별 요청 수, 응답 시간, 예외 발생 수 등 - 데이터소스 메트릭 (
jdbc.connections.*, HikariCP의 경우hikaricp.*): 최대/최소/활성/대기 커넥션 수 등 커넥션 풀 상태 - 로그 메트릭 (
logback.events): Logback 사용 시 TRACE, DEBUG, INFO, WARN, ERROR 레벨별 로그 발생 수 - Tomcat 메트릭 (
tomcat.*): (설정 활성화 필요:server.tomcat.mbeanregistry.enabled: true) 최대 스레드 수, 현재 바쁜 스레드 수, 세션 관련 정보 등 - 기타: HTTP 클라이언트(RestTemplate, WebClient), 캐시, 작업 실행 및 스케줄링, Spring Data Repository, MongoDB, Redis 등 다양한 통합 지원
- 사용자 정의 메트릭: 애플리케이션 고유의 비즈니스 지표(예: 주문 수, 취소 수)도 마이크로미터 API를 사용하여 직접 정의하고 수집할 수 있습니다.
이러한 메트릭들은 Prometheus와 같은 시계열 데이터베이스(TSDB)에 지속적으로 저장하고, Grafana와 같은 대시보드 툴을 사용하여 시각화함으로써 시스템 상태를 한눈에 파악하고 이상 징후를 신속하게 감지하는 데 활용됩니다.
4. 효과적인 로깅 전략: Logback 깊이 이해하기
앞서 로깅 프레임워크의 필요성을 언급했습니다. Spring Boot는 기본적으로 SLF4J API와 Logback 구현체를 사용합니다. Logback의 아키텍처와 주요 설정 요소를 이해하면 더욱 효과적인 로깅 전략을 수립할 수 있습니다.
◼️ 로깅이란? 기록의 기술
- 정의: 프로그램이 동작하는 동안 발생하는 모든 중요한 일(이벤트)을 기록하는 행위입니다.
- 로깅 대상 ("모든 일"의 범위):
- 서비스 동작 상태: 시스템의 주요 흐름(HTTP 요청/응답, 트랜잭션 처리, DB 쿼리 등), 개발자가 의도한 예외 발생 상황 등을 기록합니다.
- 장애 상황: 개발자가 의도하지 않은 예외(NullPointerException, IOException 등) 또는 시스템 오류 발생 시 관련 정보를 기록합니다.
- 로깅 시점: 프로젝트의 성격, 팀의 규칙, 기획 단계의 요구사항 등에 따라 결정됩니다. 일반적으로는 위에서 언급한 '서비스 동작 상태'와 '장애 상황'을 최소한의 기준으로 삼고, 필요에 따라 추가적인 로깅 지점을 정의합니다.
◼️ 로그 레벨: 정보의 중요도에 따른 분류
로그 레벨은 기록할 로그의 중요도를 나타내며, 이를 통해 특정 레벨 이상의 로그만 선택적으로 출력할 수 있습니다. 일반적인 로그 레벨 순서(낮은 중요도 → 높은 중요도)는 다음과 같습니다.
- TRACE: 가장 상세한 정보. 개발 단계에서 특정 버그를 추적하기 위해 사용되며, 프로덕션 환경에서는 거의 사용하지 않습니다.
- DEBUG: 개발 단계에서 디버깅 목적으로 유용한 상세 정보.
- INFO: 시스템의 주요 동작 상태나 의미 있는 이벤트 정보. (예: 서버 시작/종료, 사용자 로그인, 주요 기능 처리 완료, 개발자가 의도한 예외 상황)
- WARN: 현재는 오류가 아니지만, 향후 문제가 될 수 있는 잠재적인 위험 요소나 경고성 메시지. (예: deprecated API 사용, 설정 값 누락으로 인한 기본값 사용)
- ERROR: 요청 처리 중 발생한 오류나 예기치 않은 예외로 인해 정상적인 기능 수행에 실패한 상황. 프로그램이 종료될 정도는 아니지만 즉각적인 확인이 필요한 문제.
- FATAL: 매우 심각한 오류로 인해 애플리케이션이 더 이상 정상적으로 작동할 수 없는 상태. (일반적으로 애플리케이션 코드에서 직접 사용하는 경우는 드뭅니다.)
활용 기준 예시:
- ERROR, WARN: 시스템 운영 중 개발자가 예상하지 못한 예외나 문제 상황 발생 시 사용. (알림 설정 대상)
- INFO, DEBUG, TRACE: 개발자가 의도적으로 남기는 정보성 로그나 예외 상황, 디버깅용 상세 정보.
◼️ 로깅 vs. 디버깅
- 디버깅: 개발 환경에서 코드 실행을 단계별로 추적하고 변수 값, 메모리 상태 등을 실시간으로 확인하며 문제를 분석하는 가장 강력한 방법입니다.
- 로깅: 디버깅 도구를 사용할 수 없는 환경(예: 운영 서버, 원격 환경)이나, 특정 시점의 상태를 기록하여 사후 분석이 필요한 경우에 사용되는 필수적인 방법입니다.
◼️ SLF4J (Simple Logging Facade for Java): 로깅 추상화의 힘
- 정의: SLF4J는 다양한 로깅 프레임워크(Logback, Log4j2, java.util.logging 등)에 대한 추상화 인터페이스(Facade)를 제공하는 라이브러리입니다.
- 장점:
- 구현체 유연성: 애플리케이션 코드에서는 SLF4J API를 사용하여 로깅 로직을 작성하고, 배포 시점에 원하는 실제 로깅 프레임워크(구현체)를 선택하여 연결(바인딩)할 수 있습니다.
- 코드 변경 최소화: 나중에 로깅 프레임워크를 변경하더라도, SLF4J를 사용했다면 애플리케이션의 로깅 코드를 거의 수정할 필요가 없습니다. (의존성 변경만으로 가능)
- SLF4J 동작 구조 (일반적인 흐름):
- 애플리케이션 코드 → SLF4J API (Logger, LoggerFactory 등 인터페이스) → SLF4J Binding (구현체 연결 어댑터, 예:
logback-classic) → 로깅 프레임워크 구현체 (예:logback-core가 실제 로깅 처리) - (선택 사항) Bridge 모듈: 다른 로깅 API(예:
java.util.logging,log4j 1.x) 호출을 SLF4J API로 전달해주는 어댑터. 레거시 코드 통합 시 유용.
- 애플리케이션 코드 → SLF4J API (Logger, LoggerFactory 등 인터페이스) → SLF4J Binding (구현체 연결 어댑터, 예:
◼️ Logback 아키텍처 및 주요 설정 요소
Logback은 SLF4J의 대표적인 구현체 중 하나이며, 다음과 같은 세 가지 주요 모듈로 구성됩니다.
logback-core: Appender와 Layout 인터페이스 등 Logback의 핵심 기능을 제공하며, 다른 두 모듈의 기반이 됩니다.logback-classic:logback-core를 확장하고 SLF4J API를 구현합니다. 우리가 일반적으로 사용하는ch.qos.logback.classic.Logger클래스를 포함하며, SLF4J의LoggerFactory가 이 클래스의 인스턴스를 반환합니다.logback-access: 서블릿 컨테이너(Tomcat, Jetty 등)와 통합되어 HTTP 접근 로그(Access Log) 기능을 제공합니다. (일반적인 애플리케이션 로깅과는 별개)
Logback 설정 파일 (logback-spring.xml 또는 logback.xml)의 핵심 구성 요소:
<configuration>: 최상위 루트 엘리먼트.<appender>("어디에 기록할까?"): 로그 이벤트를 실제 목적지(콘솔, 파일 등)에 기록하는 역할을 합니다.ConsoleAppender: 콘솔에 로그를 출력합니다.FileAppender: 단일 파일에 로그를 기록합니다.RollingFileAppender: 날짜, 파일 크기 등 특정 조건에 따라 로그 파일을 롤링(분할 및 아카이브)합니다. 운영 환경에서 가장 많이 사용됩니다.
<encoder>/<layout>("어떻게 출력할까?"): 로그 이벤트의 출력 형식을 지정합니다.<pattern>엘리먼트를 사용하여 타임스탬프, 스레드 이름, 로그 레벨, 로거 이름, 메시지 등을 포함하는 상세한 출력 패턴을 정의할 수 있습니다. (예:%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n)- FileAppender 계열은 주로
<encoder>를, ConsoleAppender는<layout>이나<encoder>를 사용합니다.
<logger>("어떤 로그를, 어떤 레벨로 기록할까?"): 특정 패키지나 클래스에 대한 로그 레벨과 사용할 Appender를 지정합니다. 로거는 계층 구조를 가집니다.<root>: 모든 로거의 최상위 로거. 기본 로그 레벨과 사용할 Appender를 설정합니다. 특정<logger>에서 설정하지 않은 경우<root>설정을 상속받습니다.<springProfile name="...">(Spring Boot 환경): 특정 Spring 프로파일(예:dev,prod,test)이 활성화될 때만 적용되는 설정을 정의할 수 있습니다. 이를 통해 환경별로 다른 로깅 전략을 쉽게 구현할 수 있습니다. (예: 개발 환경에서는 콘솔에 DEBUG 레벨 로그 출력, 운영 환경에서는 파일에 INFO 레벨 로그 기록 및 ERROR 레벨은 별도 파일 기록)- 필터 (
<filter>): Appender 레벨에서 특정 조건(예: 로그 레벨)에 따라 로그 이벤트를 수락(ACCEPT)하거나 거부(DENY)할 수 있습니다. (예:LevelFilter를 사용하여 특정 Appender에는 특정 레벨의 로그만 기록) - 롤링 정책 (
<rollingPolicy>):RollingFileAppender사용 시 로그 파일을 어떻게 롤링할지 정의합니다. (예:SizeAndTimeBasedRollingPolicy- 시간 및 크기 기반 롤링)<fileNamePattern>: 롤링된 파일의 이름 패턴 지정.<maxFileSize>: 개별 로그 파일의 최대 크기.<maxHistory>: 보관할 아카이브 파일의 최대 기간(일 수).<totalSizeCap>: 전체 아카이브 파일의 최대 총 크기.
<include resource="...">: 공통 설정 부분을 별도 파일로 분리하고 메인 설정 파일에서 포함시켜 가독성과 재사용성을 높일 수 있습니다.
예시: logback-spring.xml 설정 (운영 환경 - 파일 로깅, 레벨별 분리)
<configuration>
<timestamp key="BY_DATE" datePattern="yyyy-MM-dd"/>
<property name="LOG_PATTERN" value="%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %highlight(%-5level) %cyan(%logger{36}) - %msg%n"/>
<springProfile name="prod">
<!-- INFO 레벨 로그 파일 어펜더 -->
<appender name="FILE-INFO" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>./logs/info/${BY_DATE}.log</file>
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>INFO</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
<encoder>
<pattern>${LOG_PATTERN}</pattern>
</encoder>
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<fileNamePattern>./logs/backup/info/info-%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<maxFileSize>100MB</maxFileSize>
<maxHistory>30</maxHistory>
<totalSizeCap>3GB</totalSizeCap>
</rollingPolicy>
</appender>
<!-- ERROR 레벨 로그 파일 어펜더 (WARN 레벨도 포함 가능) -->
<appender name="FILE-ERROR" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>./logs/error/${BY_DATE}.log</file>
<filter class="ch.qos.logback.classic.filter.ThresholdFilter"> <!-- WARN 레벨 이상만 기록 -->
<level>WARN</level>
</filter>
<encoder>
<pattern>${LOG_PATTERN}</pattern>
</encoder>
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<fileNamePattern>./logs/backup/error/error-%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<maxFileSize>100MB</maxFileSize>
<maxHistory>30</maxHistory>
<totalSizeCap>1GB</totalSizeCap>
</rollingPolicy>
</appender>
<root level="INFO">
<appender-ref ref="FILE-INFO"/>
<appender-ref ref="FILE-ERROR"/>
</root>
</springProfile>
<springProfile name="dev,local">
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>${LOG_PATTERN}</pattern>
</encoder>
</appender>
<root level="DEBUG"> <!-- 개발 환경에서는 DEBUG 레벨까지 출력 -->
<appender-ref ref="CONSOLE"/>
</root>
</springProfile>
</configuration>주의: 로그 메시지 포매팅 시, logger.info("User " + userId + " logged in"); 과 같이 문자열 결합(+)을 사용하는 것보다 logger.info("User {} logged in", userId); 와 같이 파라미터화된 메시징(Parameterized Messaging)을 사용하는 것이 성능상 유리합니다. 로그 레벨이 비활성화되어 실제 로그가 출력되지 않더라도, 문자열 결합 방식은 불필요한 문자열 객체 생성 및 연산 오버헤드가 발생할 수 있기 때문입니다.
결론
로그와 메트릭은 백엔드 시스템의 건강 상태를 진단하고 문제를 해결하는 데 있어 의사의 청진기와 CT 촬영 장비와도 같습니다. 마이크로미터를 통해 표준화된 방식으로 메트릭을 수집하고, SLF4J와 Logback을 통해 유연하고 강력한 로깅 시스템을 구축함으로써, 우리는 더욱 안정적이고 예측 가능한 서비스를 운영할 수 있습니다.
단순히 정보를 기록하는 것을 넘어, 수집된 로그와 메트릭을 어떻게 분석하고 활용하여 서비스 개선으로 이끌어낼 것인지 고민하는 것이 진정한 프로 개발자의 자세일 것입니다. 이 글이 여러분의 로깅 및 모니터링 전략 수립에 조금이나마 도움이 되었기를 바랍니다.
