
FCN의 한계점
- 국소적인 파악만 해서 객체의 크기가 큰 경우 잘 파악하지 못한다.

- 크기가 작은 객체 잘잡지 못한다.
- upsampling 절차가 간단하여 디테일한 모습을 파악하지 못한다.

-> 위의 문제점을 upsampling하는 방법을 좀 더 발전시켜서 완화하기도하고,
-> receptive field를 넓혀서 전체적 맥락을 더 잘파악하게 하는 방법도 있다.
Decoder를 개선한 모델
DeconvNet
- 대칭적인 형태

- unpooling
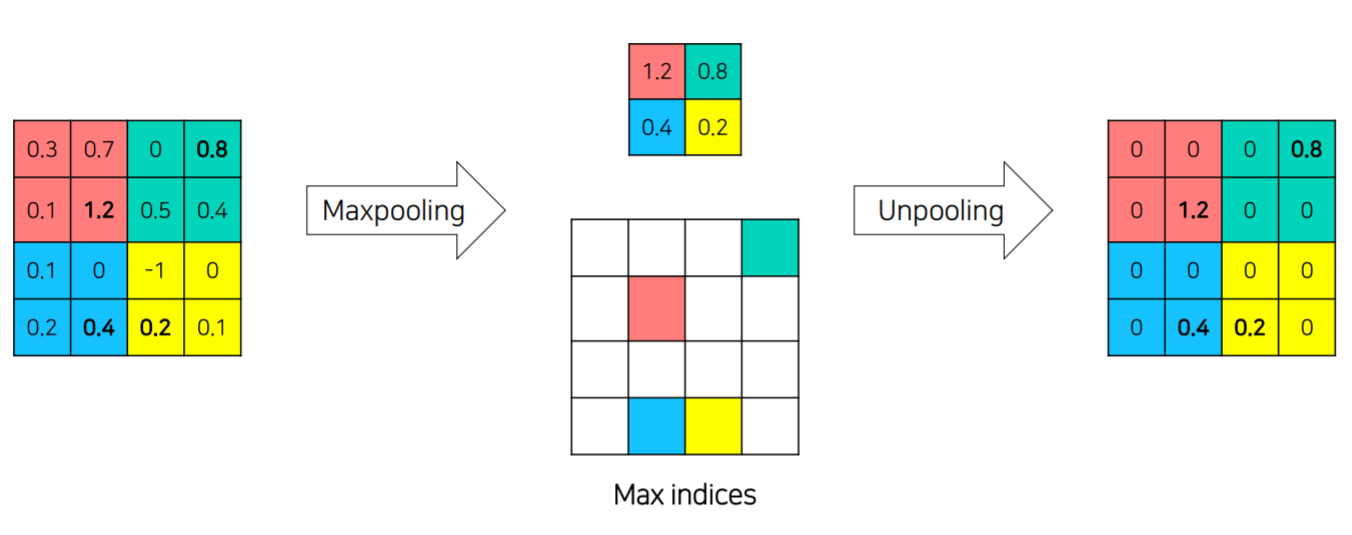
max pooling을 할때 max값이 있었던 위치정보를 기억해둔후 복원하는 것이다. - trasposed conv
학습가능한 파라미터로 upsampling하는 과정
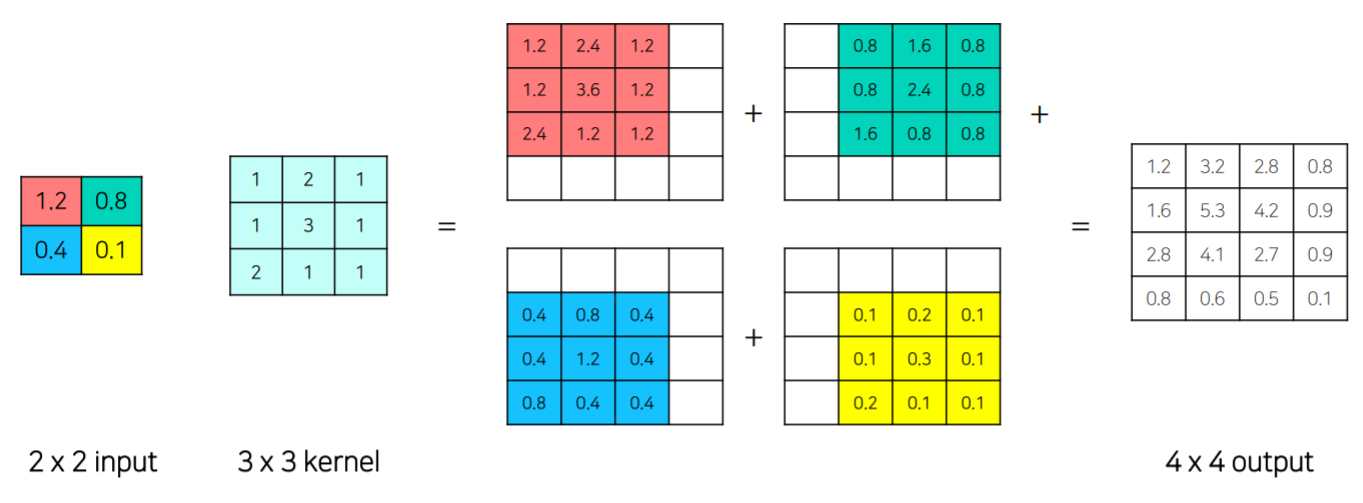
- unpooling으로 외곽잡고, transposed conv로 빈부분을 채운다.
-> FCN에 비해서 디코더가 unpooling과 deconv로 더욱 풍성해짐
SegNet
DeconvNet의 real-time 버전
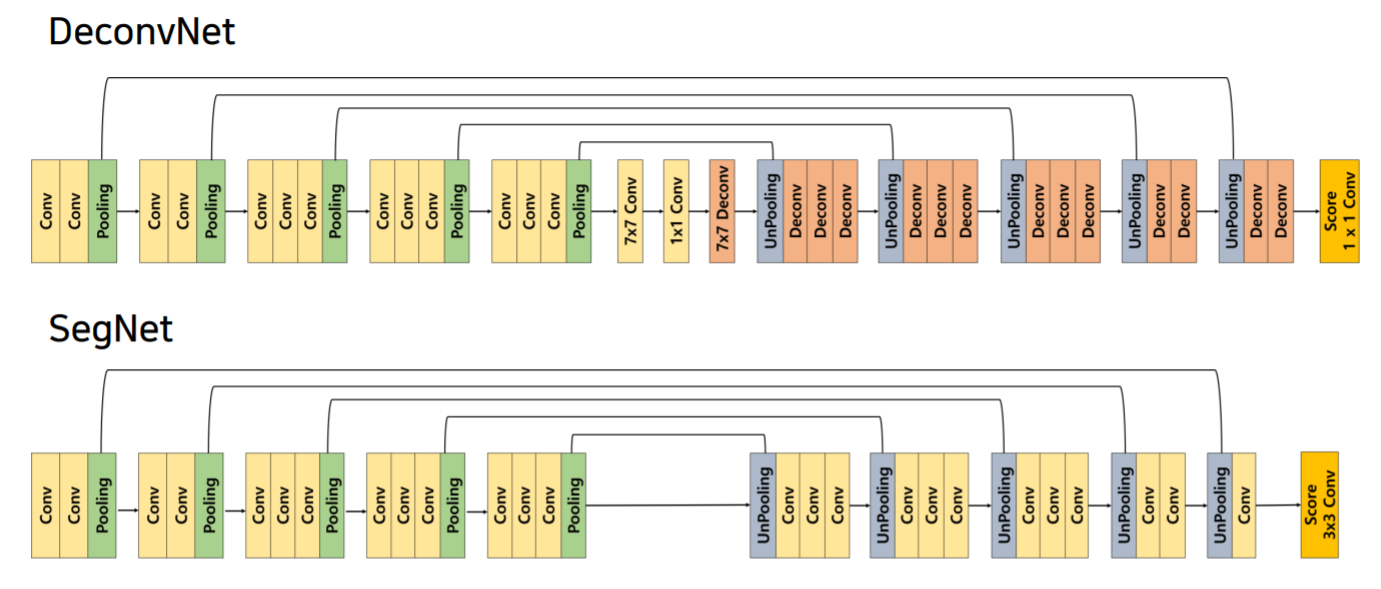
- 중간 conv 제거
- transposed conv -> conv
- 마지막 score layer 3x3 conv
Receptive field를 확장한 모델
receptive field
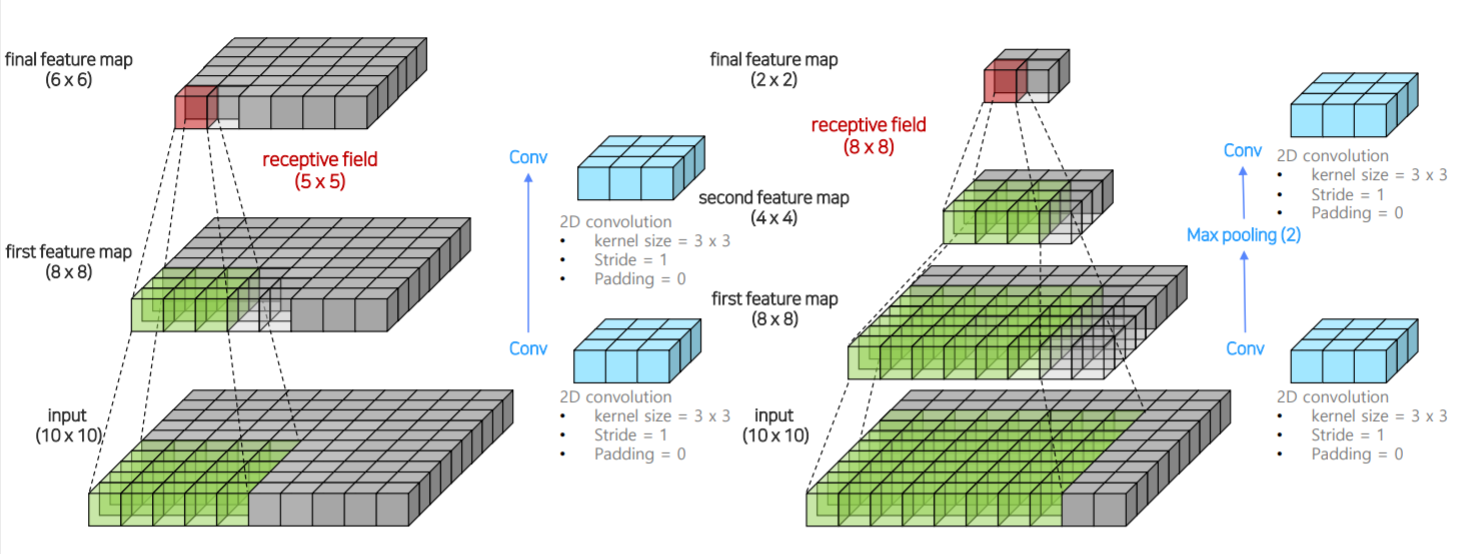
- 3x3 conv -> 3x3 conv
receptive field = 5x5 - 3x3 conv -> maxpooling -> 3x3 conv
receptive field = 8x8
max pooling으로 더 넓직넓직하게 정보를 훑게되고 이는 더 넓은 receptive field를 가지게 만들어줌.
Dilated convolution
pooling은 receptive field를 넓혀주는 장점이 있지만 정보의 손실을 초래한다.
(receptive field 이하 rf로 통칭)
필터의 크기를 키우면 rf가 넓어지지만 parameter 증가
dilated convolution은 filter 중간에 0을 넣어 parameter수는 같지만 필터의 크기가 커진다.

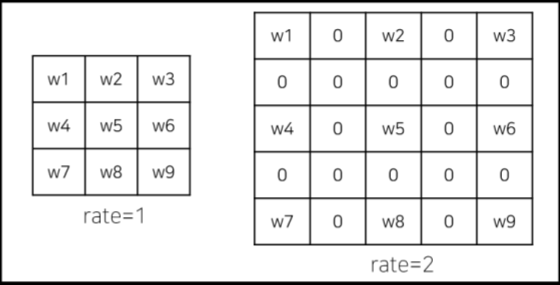
DeepLab v1
NCF와 비슷하게 생겼다. 근데 차이점은
- Dilated conv, pooling kernel size 키우기를 통해 rf를 키웠다는 것.
- Bi-linear interpolation 사용
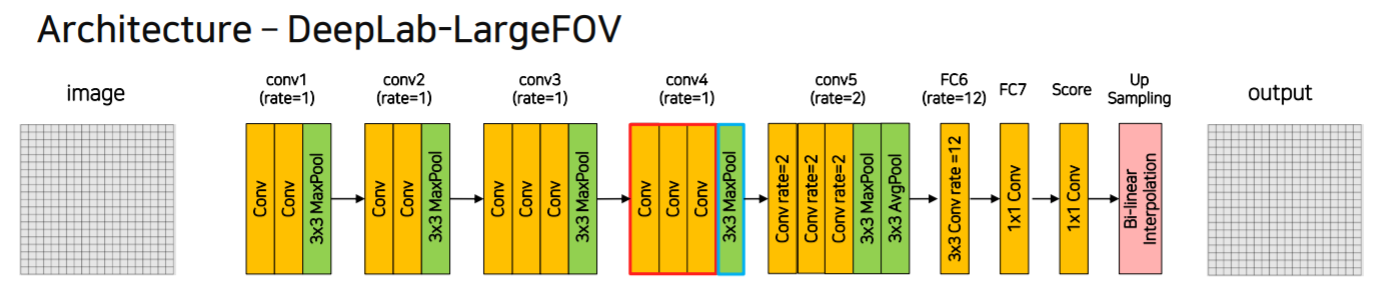
모델 구조
- conv3까지는 2배씩 줄어서 w,h가 1/8 되고 이후는 same conv
- Bi-linear interpolation에서 8배 키움
- conv5는 dilated rate=2, fc6은 12
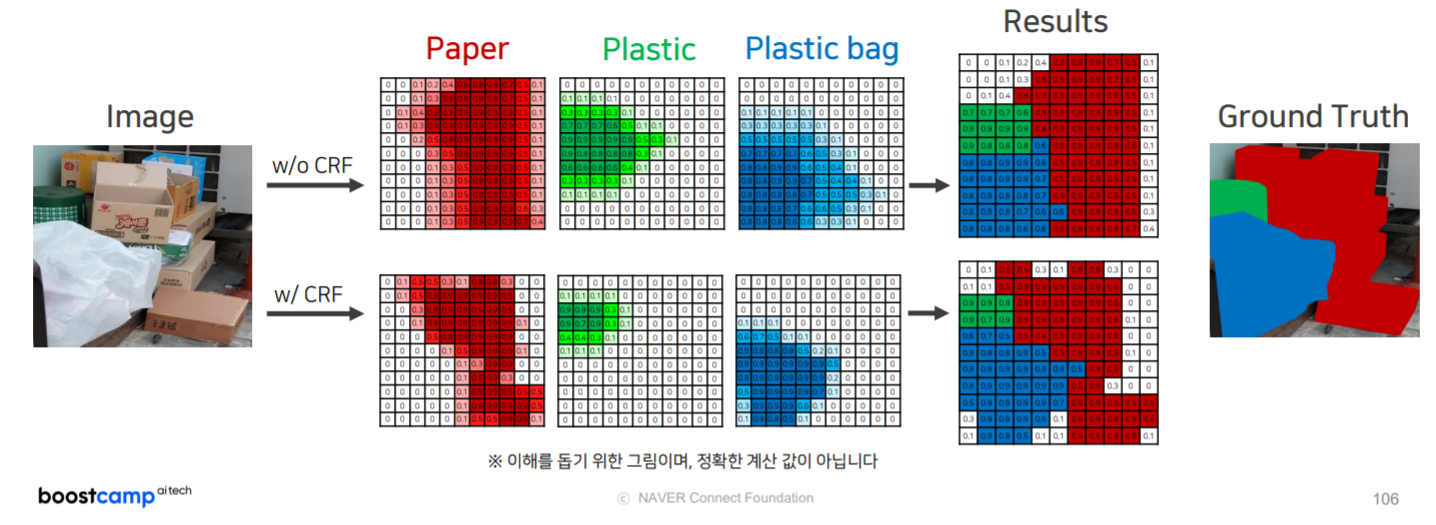
CRF
bilinear interpolation을 보완할 수 있는 방법
- 색상이 유사한 픽셀이 가까이 위치하면 같은 범주에 속함
- 색상이 유사해도 픽셀의 거리가 멀다면 같은 범주에 속하지 않음
위의 원리로 픽셀값을 재조정
각 클래스별로 CRF진행 후, 이를 합친다.
iteration을 반복할수록 결과물이 나아진다.
DilatedNet
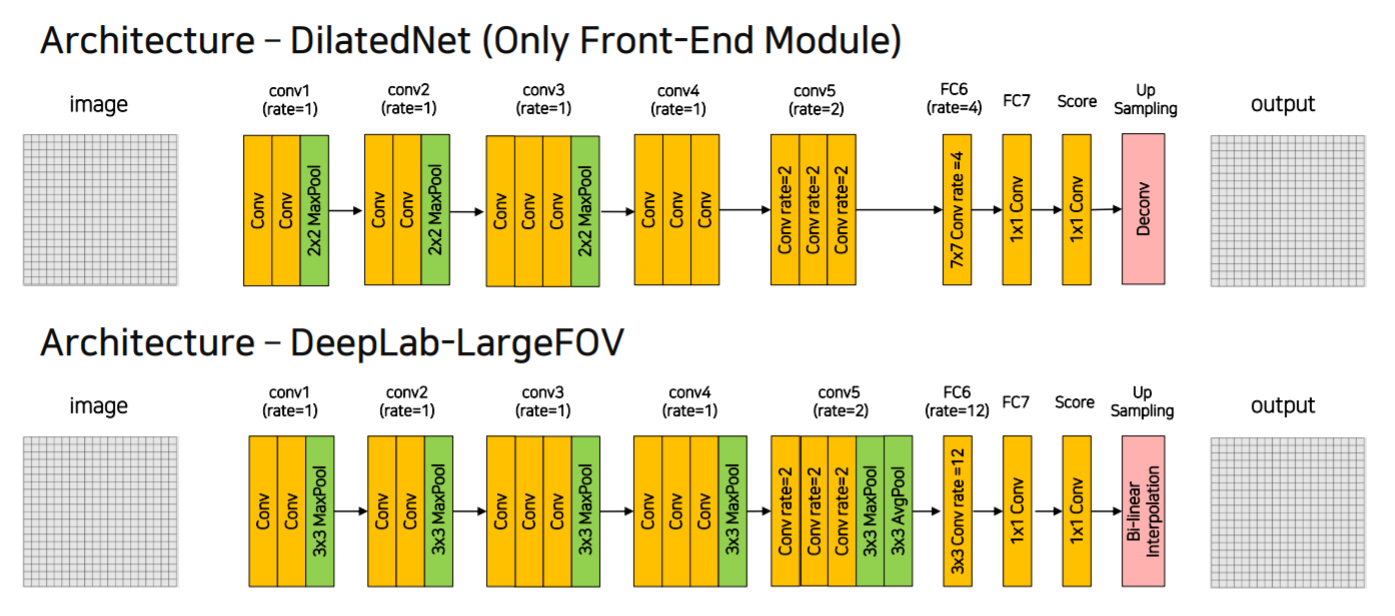
- 2x2 pooling
- conv4, conv5에서의 pooling 삭제
- fc6에서의 dilation rate = 4
- interpolation 대신 deconv 사용
Basic Context module
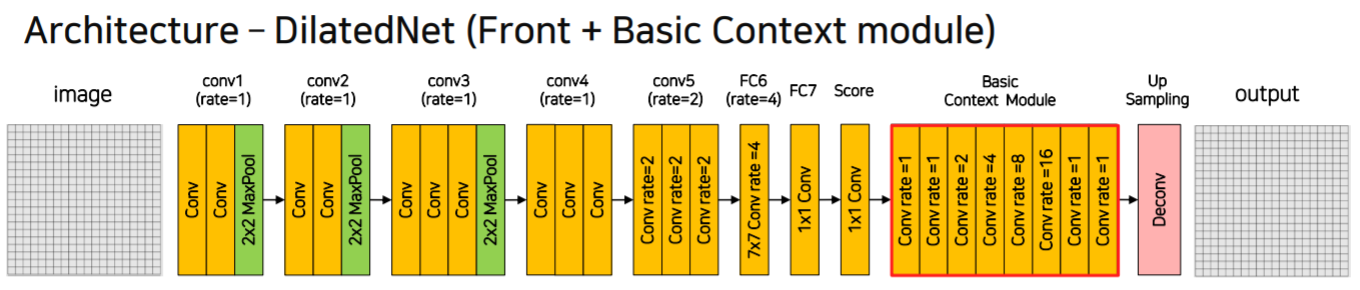
- 다양한 크기의 dilation rate를 적용함 이를 통해 다양한 크기의 receptive field를 가지게 되고 다양한 크기의 물체 탐지 가능
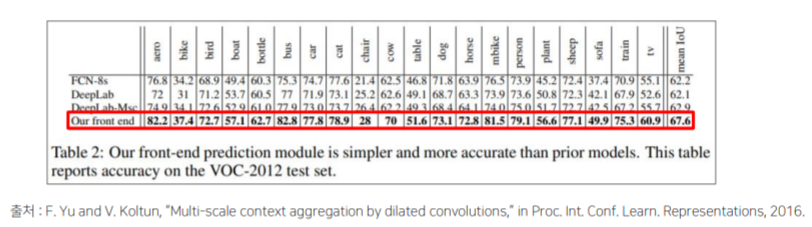
DeepLab에 비해 우수한 성능을 보이며,
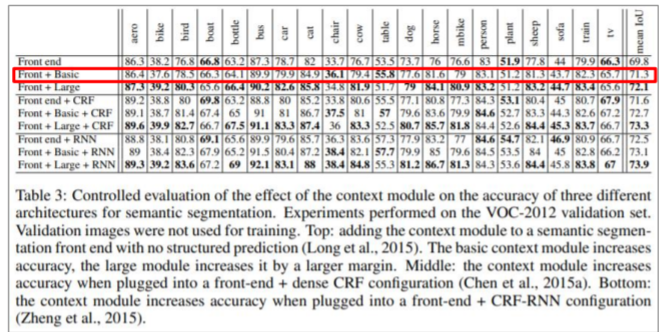
context module 추가하면 더 성능이 좋아진다.

Skip Connection을 활용한 모델
FC DenseNet
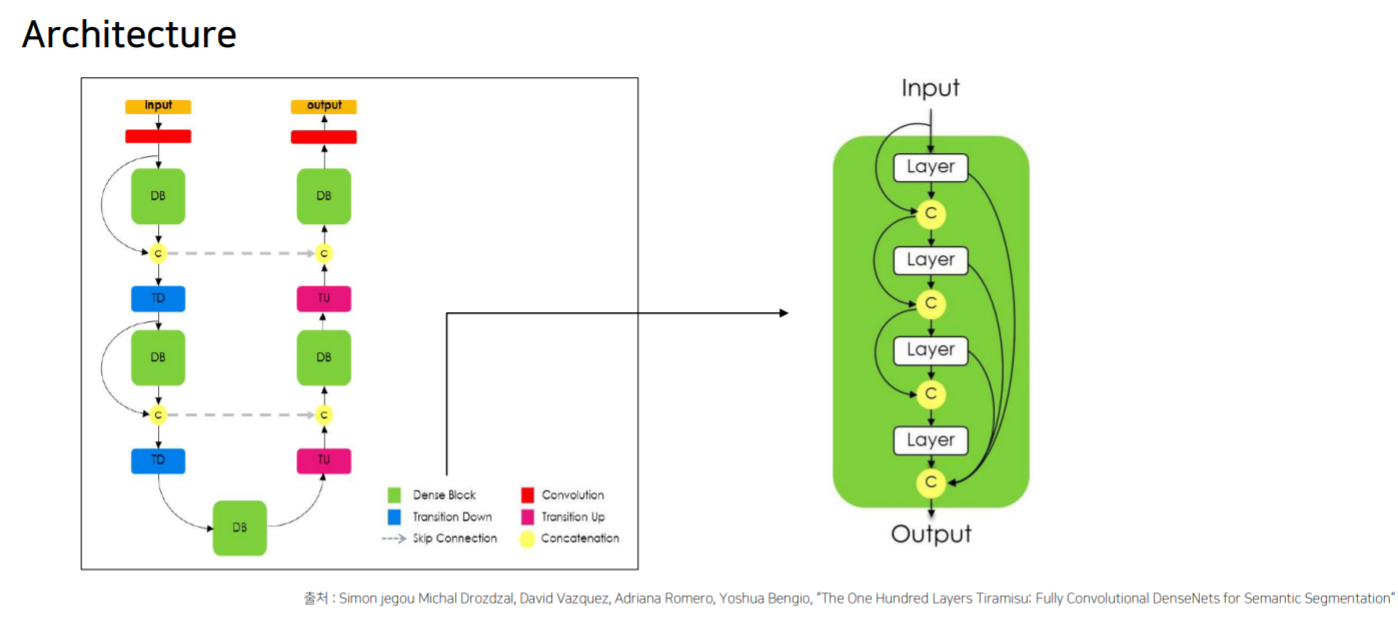
Unet
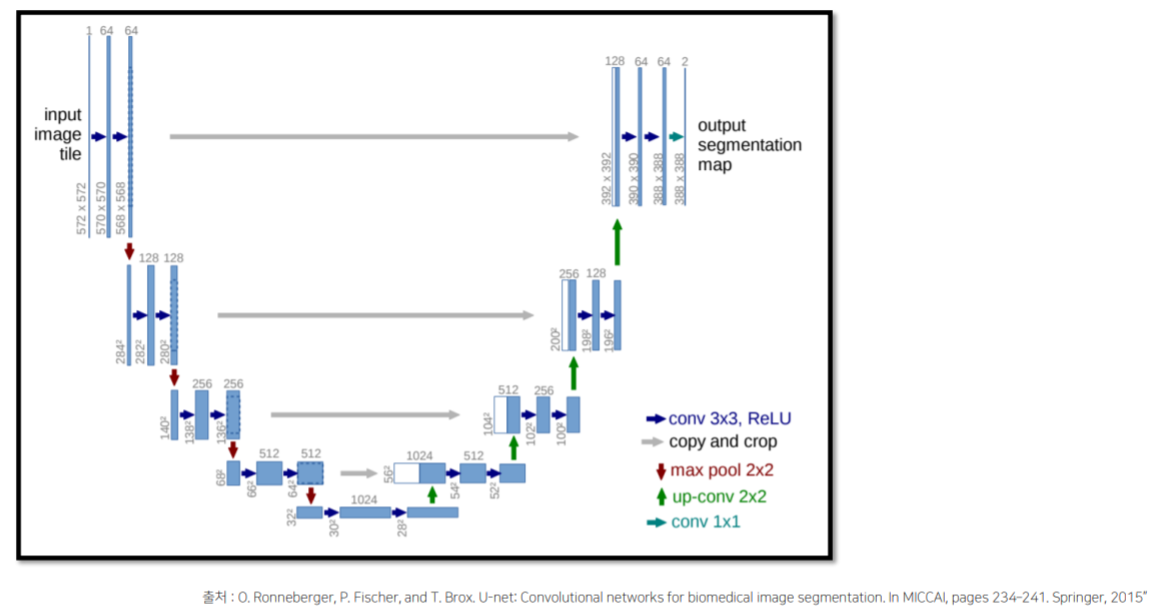
refernce
모든 이미지는 커넥트재단 boostcamp ai tech 교육자료입니다.
네이버 커넥트재단 - 재활용 쓰레기 데이터셋 / CC BY 2.0

중요한 것은 속력이 아니라 방향성, 공부하며 메모를 남기는 공간입니다.