Data Augmentation
Learning representation of dataset
-
현실의 데이터를 모두 가질 수는 없다. 우리는 실제 데이터의 분포와 데이터셋의 분포를 비슷하게하기위해 data augmentation을 이용한다.
-
numpy, opencv 등을 사용할 수 있다.
-
rotate, flip, crop
-
affine
affine은 연속된 이미지를 잇는 작업에서 많이 쓰인다고 한다.
3개의 점을 기준으로 변환한다.
CutMix
cutmix를 사용할때는 잘린 패치가 과연 해당 클래스를 잘 나타낼 수 있는지 확인하는 것이 매우 중요하다.
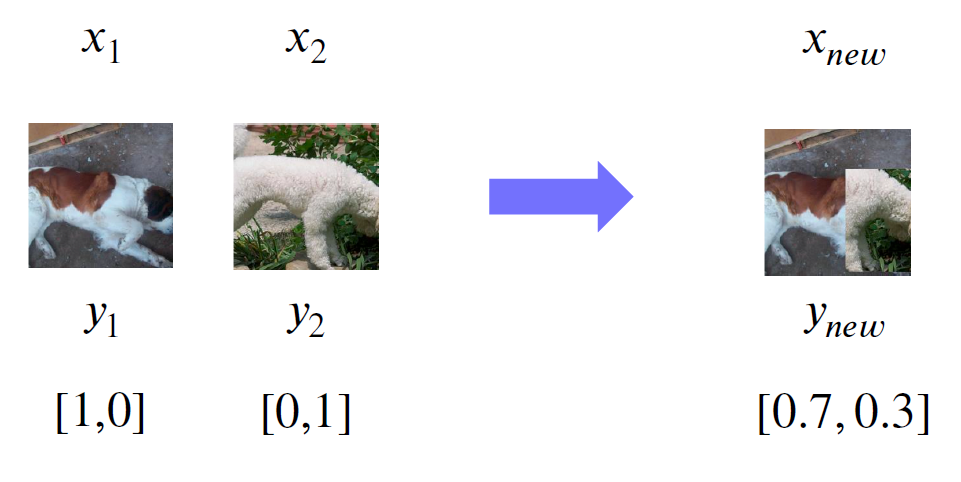
의문점
cutmix를 사용하면 각 레이블에 해당하는 부분이 어디인지 파악하면서 학습하기 때문에 localization 능력이 올라갈 것이라고 생각되는데, localization을 위해서는 각 레이블의 crop이미지를 학습하는 것도 가능하지 않은가?
RandAugment
n개의 transform, m개의 transform의 정도의 랜덤한 조합의 augmentation을 하는 것이다.
논문
질문
모든 조합의 augment조합의 성능을 보고 가장 좋은 조합의 augmentation을 추천하는 것인가?
-> 피어세션에서의 결론은 아니다.
랜덤하게 적용될 후보군을 지정하면 다양하게 자동으로 지정이 되는 것에서 그치는 것 같다.

Leveraging pre-trained information
Transfer learning
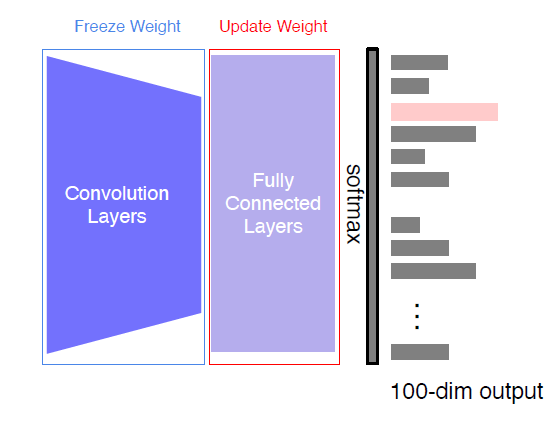
feature extractraction
기존 모델 freeze, classifier trainable
fine tuning
기존 모델, classifier 모두 trainable
기존 모델 low lr, classifier high lr로 적용하는 방법도 존재
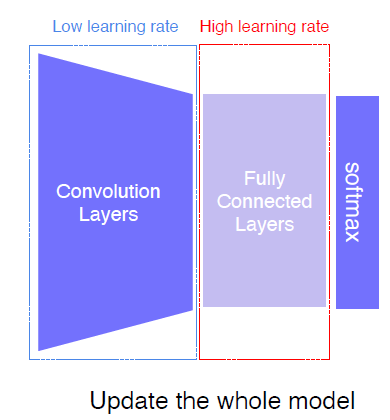
- 초반 lr 0.0000001
- 중반 lr 0.00001
- fc-layer lr 0.001
과 같은 방식으로 100배씩 lr을 늘려가는 recipe도 있다고 한다.
lr을 layer별로 다르게 주는 것은 optimizer에 weight를 주는 것과 비슷하게 설정할 수 있다고 한다.
Knowledge distillation
아래와 같은 목적으로 사용됌
- model compression
- pseudo labeling
label이 없을때
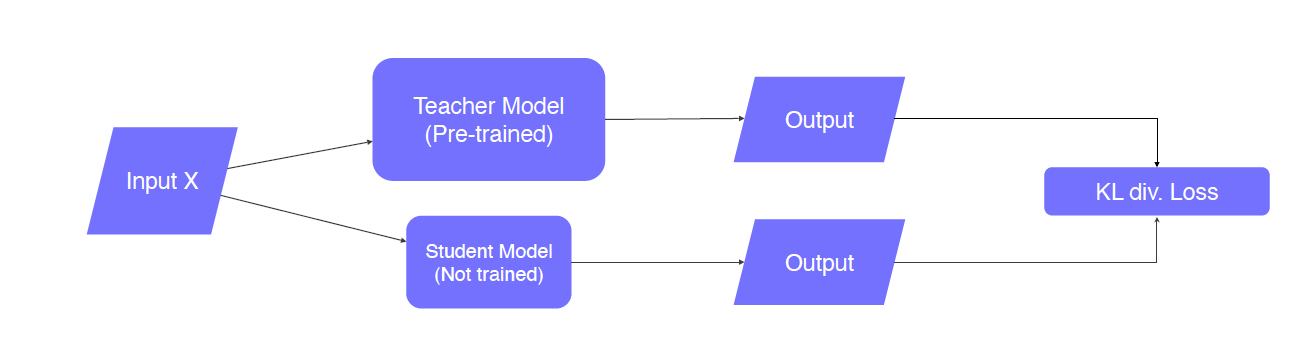
teacher model, student model의 output 분포를 kld loss를 통해 서로 비슷해지도록 학습 이때, KLD loss는 student model에만 전달된다.
label이 있을때
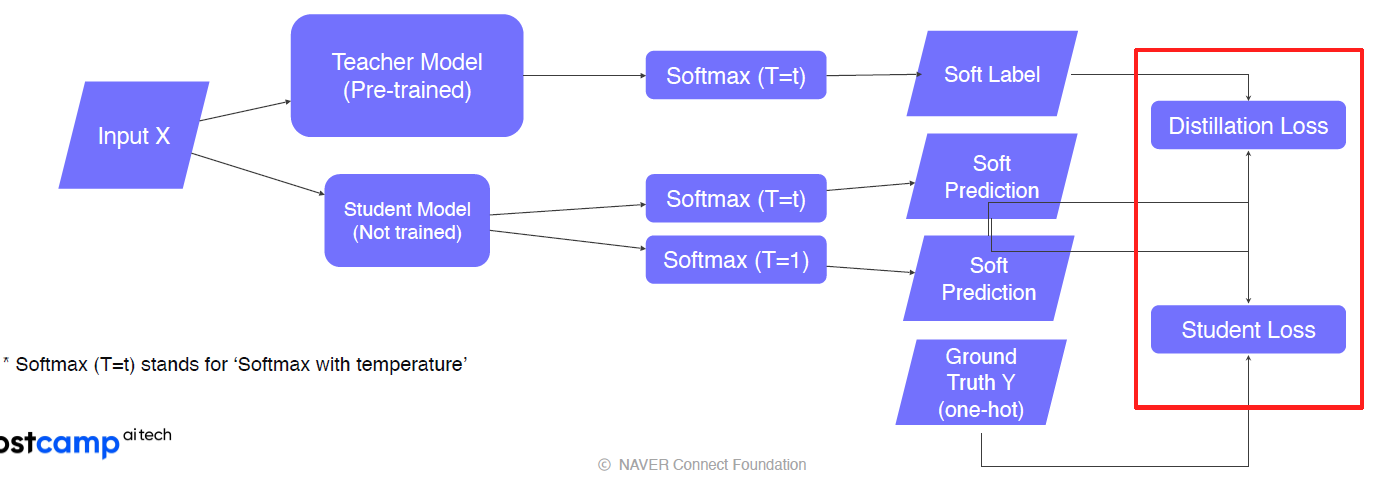
-
teacher - student
teacher model, student model의 inference를 비슷하게 하기 위해서 kld loss를 student model에 전파 -
student - data with label
student는 soft predict, label은 hard label, cross-entropy사용
-> 최종적으로 kld loss, cross-entropy loss의 weighted sum을 backpropagation
- teacher의 pre-trained task와 student의 task가 같지않아도 된다. 이유는 teacher의 soft label을 학습하는 것은 label각각을 학습한다기보다 전체적인 예측의 경향성을 학습하는 것이기 때문이다.
질문
-
soft label vs label smoothing 차이점?
soft label은 teacher model의 예측의 불확실성을 나타내는 용도label smoothing은 hard label을 완화하는 것
Leveraging unlabeled dataset for training
Semi-suprevised learning
- labeled data로 train
- unlabeled data pseudo labeing
- labeled data + psedo label data 로 train
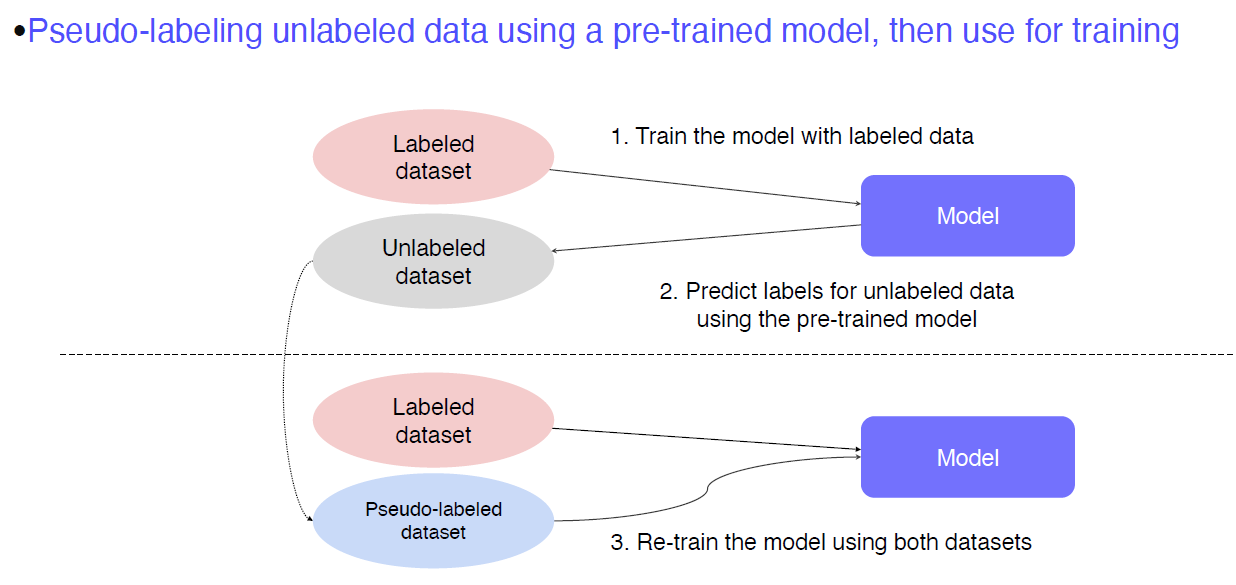
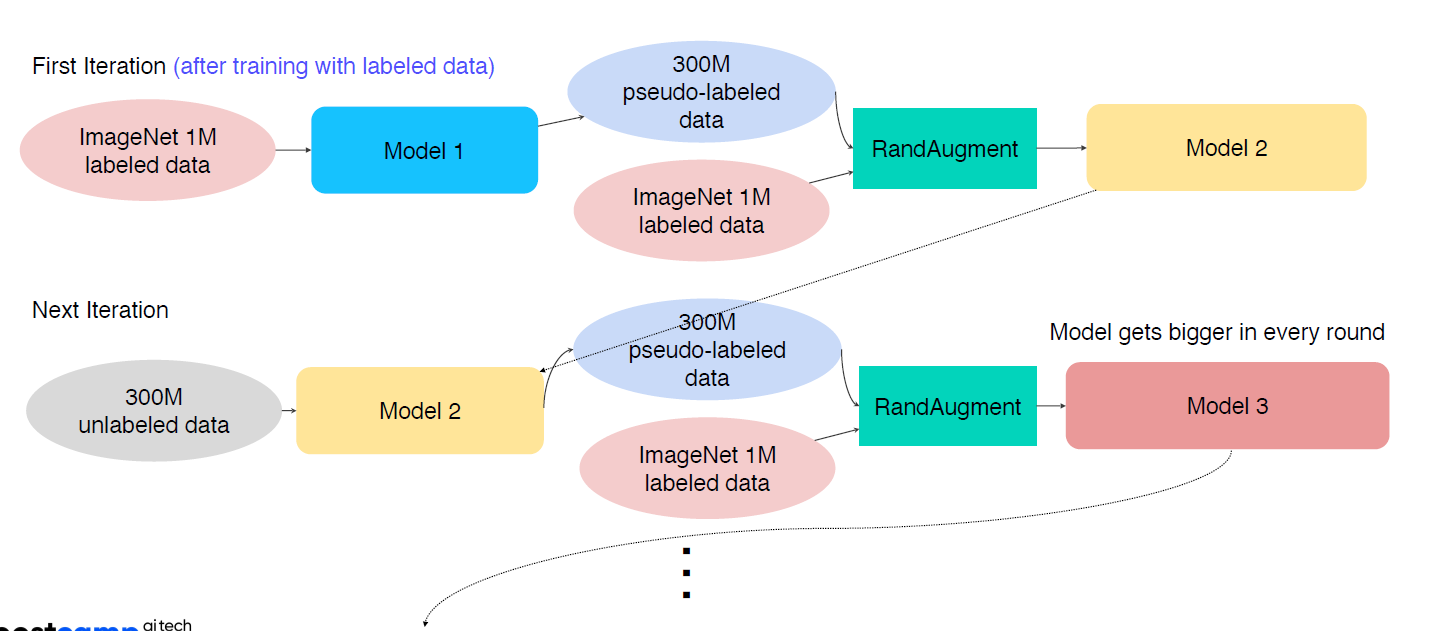
Self-training
-
labeled data(상대적으로 적은 크기) 로 teacher model train
-
unlabeled data(데이터 크기 큼) pseudo labeling
-
pseudo labeled data + labeled data -> random aug -> studnet model train
-
학습된 student model은 teacher model이 되어서 pseudo labeling 진행
-
pseudo labeled data + labeled data -> random aug -> studnet model train
위의 과정 반복 -
student model은 점점 커진다.
-
self-training에서 model의 크기가 커지는 이유는?
→ Iteration이 진행됨에 따라 좋은 data의 수가 늘어나고 그 정보를 충분히 학습하기 위해 parameter 수가 더 큰 모델을 새로운 학습 모델로 설정하기 때문이다.