
GPT-3.5 파인튜닝
- 이번에 LLM 관련 프로젝트를 하는데, 오픈소스로 공개된 여러 모델들을 사용을 해봤는데, 기대했던 성능이 잘 안나와서 GPT-3.5를 파인튜닝 시도를 해보았습니다.
파인튜닝을 하기에 앞서 준비해야 할 사항이 있습니다.
1) gpt에 파인튜닝 할 데이터셋(chat-completion 형식의 jsonl 파일)
2) OpenAI token
3) 파인튜닝에 사용할 모델(ex : davinci-002,gpt-3.5-turbo-0125, gpt-4-0613)
OpenAI 파인튜닝 가이드라인
- 데이터 세트 준비

gpt-3.5-turbo를 사용하려면 위와 같은 데이터 형식을 지정을 해야합니다.
- 우선 저는 파인튜닝을 하기 위해 csv 파일을 준비했습니다.
- 이제 준비한 csv 파일을 jsonl 형식으로 변경을 해주어야 하는데, openai에서는 데이터 유효성 검사 및 재형식화를 해주는데 도움을 주는 CLI 데이터 준비 도구가 있습니다.
openai tools fine_tunes.prepare_data -f 로컬_파일위치/사용할데이터.csv
- 위와 같은 명령어를 사용해주면 jsonl 형식에 맞게 데이터 세트를 변환해줍니다.
- 이제 데이터도 준비가 완료 되었으므로, colab 혹은 주피터에서 파일을 업로드하고, 파인튜닝 준비를 해봅시다.
- 교육 파일 업로드
from openai import OpenAI
client = OpenAI("나의 API 키")
client.files.create(file=open('jsonl 데이터', 'rb'),
purpose = 'fine-tune')- 결과로 file객체의 id와 bytes, purpose가 나올 것입니다.
- 위와 같이 이제 제가 만든 jsonl 파일을 업로드 하고, 파인튜닝을 시도해봅니다.
- 미세 조정된 모델 만들기
from openai import OpenAI
client = OpenAI()
client.fine_tuning.jobs.create(
training_file="file-abc123",
model="gpt-3.5-turbo") 
- 하지만 위와 같이 데이터 형식이 맞지 않아 오류가 발생했습니다.
- 무슨 문제인지 파악하려고 했는데, gpt-3.5-turbo는 Prompt-Completion 형식을 이제 지원하지 않고, Chat-Completion 형식만 지원하는 거 같아 보입니다.
- 다시 한번 데이터 세트 형식을 수정해주어야 할 거 같습니다.
- Chat-completion 형식은 아래와 같습니다.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already."}]}
- 데이터 세트 다시 준비하기
# 프롬프트 구성(Chat-completion 형식)
# system, user, assistant에 대한 데이터를 준비해서 학습 데이터로 생성해야함.
training_data = []
system_message = "저는 대화용 챗봇 입니다." # 여기에 들어갈 말은 임의로 설정하셔도 됩니다.
def prepare_example_conversation(row):
messages = []
messages.append({"role": "system", "content": system_message})
messages.append({"role": "user", "content": row['prompt']})
messages.append({"role": "assistant", "content": row["completion"]})
return {"messages": messages}
training_data = training_df.apply(prepare_example_conversation, axis=1).tolist()
# 학습 데이터를 파일로 저장
def write_jsonl(data_list: list, filename: str) -> None:
with open(filename, "w") as out:
for ddict in data_list:
jout = json.dumps(ddict) + "\n"
out.write(jout)
training_file_name = "resume_finetune_training.jsonl"
write_jsonl(training_data, training_file_name)
- 위와 같이 수정한 후, jsonl로 변환하니 파인튜닝 모델이 잘 돌아감을 확인할 수 있습니다.
- 결과 확인
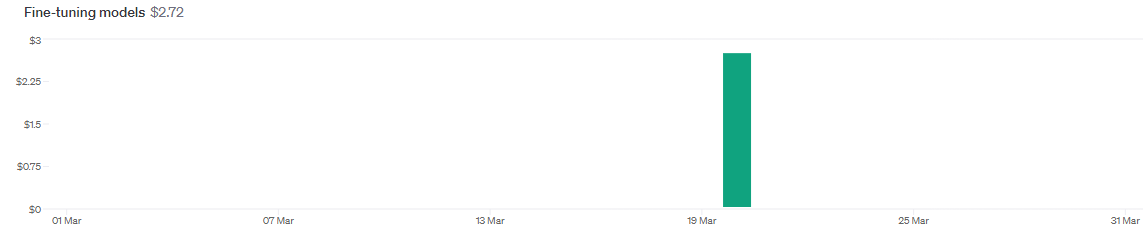
- 저는 3 epochs로 훈련을 하였는데, 약 20분 정도 걸리고, 자기소개서 데이터셋이다보니, 토큰 수가 많아, 학습하는데 약 3$ 정도 나왔네요
- 파인튜닝 비용을 보고싶다면 OpenAI playground의 USAGE를 가면 볼 수 있습니다.

NLP Developer