
Llama2
- 지금은 Alpaca, mistral, Solar, Orion 등 다양한 오픈소스 LLM이 등장하였지만 작년 9월까지만 하더라도 라마는 sLLM 분야에서 가장 강력한 오픈소스였습니다.
- 기존 Llama1처럼 인터넷 데이터를 크롤링하여 약 2조개 정도의 토큰을 모았고, 사전 학습을 통해 Llama2가 생성이 되었습니다.
모델 소개
-
메타에서 개발한 오픈소스 LLM 모델로, 해당 모델은 7B, 13B, 70B까지 파라미터가 다양하고, Chat 모델은 특히 대화용 서비스에 최적화 되어 있습니다.
=> Llama2-Chat 버전은 RLHF방식을 사용하여 대화 애플리케이션에 최적화 될 수 있게 됩니다. -
기존 Llama1보다 훈련 말뭉치를 40%늘렸고, 문맥길이 또한 2048 -> 4096으로 2배 정도 늘었습니다.
=> 가장 사실적인 출처의 내용에 대해 upsampling하여 지식을 높이고, 환상(할루시네이션)을 줄이고자 노력하였다고, 논문에 쓰여있네요 -
토크나이저의 경우 SentencePiece를 Base로 BPE 알고리즘을 적용하였습니다.
BPE 알고리즘은 간단하게 설명드리자면, 기계는 모르는 단어가 등장하면 그 단어를 UNK라고 표현을 하는데, 모르는 단어로 인해 문제를 푸는 것이 까다로워지게 됩니다.
그래서 하나의 단어를 여러 개의 subword로 분리하여 UNK 문제에 대해 대응이 가능한 알고리즘이라고 아시면 될 거 같네요.
해당 부분은 제가 잘못 이해할 수 있어, 혹시 잘못되었다면 알려주시면 감사하겠습니다.
사용 방법
1) 우선 Meta의 Llama2에 대한 권한을 부여 받기 위해 https://llama.meta.com/ 해당 사이트에 로그인 한 뒤, 권한을 요청해야 합니다.
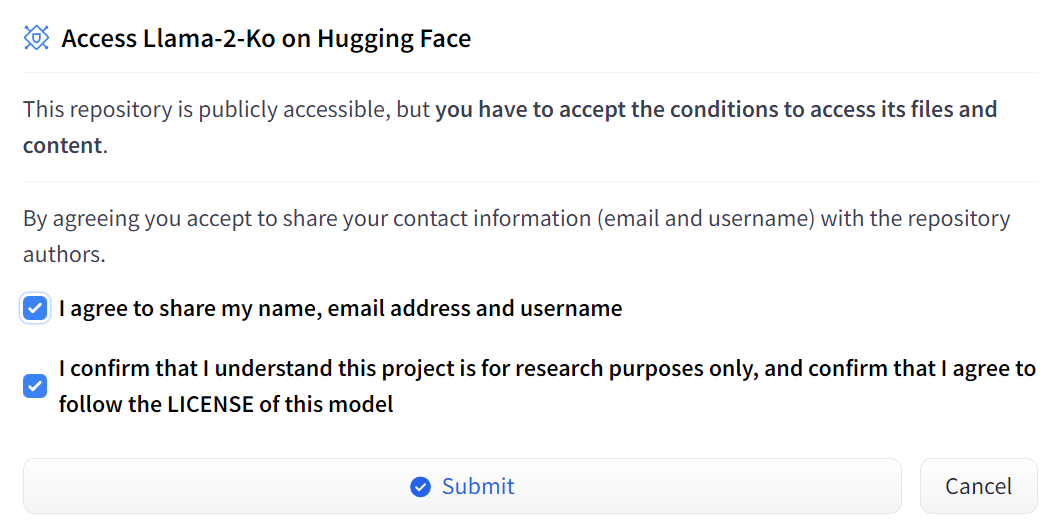
2) 권한을 부여 받았으면, 허깅페이스에 들어가서, https://huggingface.co/meta-llama/Llama-2-7b-chat-hf 아래 요구사항 입력 후, 엑세스 권한을 부여 받게 되면 사용이 가능합니다.
-> 여기서 주의할점은 Meta에서 인증한 이메일과 허깅페이스 이메일이 같아야 허깅페이스에서 제공하는 가이드라인에 따라 모델을 실행할 수 있습니다.
3) 허깅페이스 가이드라인에 따라 모델 사용하기
-> 주의할점은 해당 모델을 사용하기 위해서는 많은 메모리가 필요하므로 기본적으로 노트북에서는 7B 모델로 진행하는 것이 좋습니다.
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf")
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-hf")
generate_text = pipeline(model=model, tokenizer=tokenizer,task='text-generation')
res = generate_text("질문할 내용 입력")
print(res[0]["generated_text"])- 위 결과를 수행하면 Llama2는 한국어가 모델에서 0.6% 밖에 없다보니 답변이 대체적으로 영어로 나오고, 말도 앞뒤가 안 맞게 출력이 됩니다.
- 그래서 해당 모델을 서비스로 사용하고자 한다면 Fine-tuning을 통해서 각 도메인에 맞게 학습을 시키면 될 거 같네요.
- 오늘은 Llam2 모델 소개 및 사용방법에 대해 알아봤는데, 다음번에는 파인튜닝을 시도하는 방법에 대해 포스팅 하겠습니다.
