
● 오늘의 공부
- 서울시 cctv 분석
- 서울시 인구 확인
- pandas 기초 기능
♟️pandas
- Python에서 R 만큼의 강력한 데이터 핸들링 성능을 제공하는 모듈
- 단일 프로세스에서는 최대 효율
- 코딩 가능하고 으용 가능한 엑셀로 받아들여도 됨
- 데이터를 불러오고 읽는데 최적인 프로그램
- import pandas as pd 로 씀
 시작전 ds_study를 활성화시켜주고 jupyter notebook을 실행할 폴더를 찾아준다.
시작전 ds_study를 활성화시켜주고 jupyter notebook을 실행할 폴더를 찾아준다.
♟️CCTV 분석
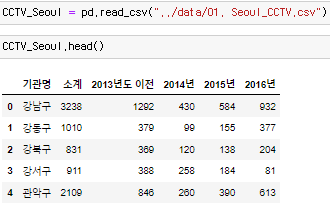 서울시 CCTV 현황 부르기, head()의 기본값은 5이다. 추가로 불러오거나 적게 불러올려면 ()안에 원하는 숫자를 채워넣어주면 된다.
서울시 CCTV 현황 부르기, head()의 기본값은 5이다. 추가로 불러오거나 적게 불러올려면 ()안에 원하는 숫자를 채워넣어주면 된다.
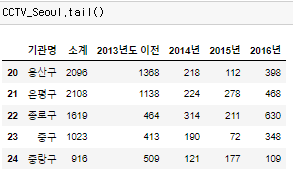 반대로 tail()을 이용하면 끝에서부터 5개를 불러온다. tail()을 이용하면 총 인덱스가 몇인지 알 수 있는 장점이 있다.
반대로 tail()을 이용하면 끝에서부터 5개를 불러온다. tail()을 이용하면 총 인덱스가 몇인지 알 수 있는 장점이 있다.
가로는 인덱스, 세로는 columns, 내부값은 value이다.
 columns 값은 리스트형태로 불러올수 있다. 앞전에 python에서 했던 리스트 자료구조에서 리스트는 각각 인덱스를 불러올수 있고 수정이나 변환, 추가가 가능했다.
columns 값은 리스트형태로 불러올수 있다. 앞전에 python에서 했던 리스트 자료구조에서 리스트는 각각 인덱스를 불러올수 있고 수정이나 변환, 추가가 가능했다.
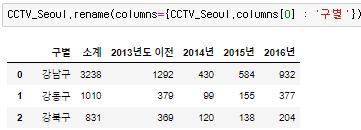 rename 함수로 colums 이름 변경이 가능하다.
rename 함수로 colums 이름 변경이 가능하다.
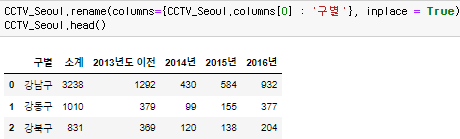 이때 inplace = True 를 붙이면 원본에도 바뀐 값이 저장이 된다. 기재하지 않으면 추가 작업을할때 불러오면 다시 이전값으로 돌아간다.
이때 inplace = True 를 붙이면 원본에도 바뀐 값이 저장이 된다. 기재하지 않으면 추가 작업을할때 불러오면 다시 이전값으로 돌아간다.
♟️인구수 분석
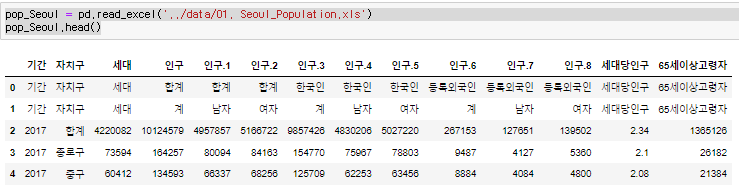 excel은 마찬가지로 pd.read에서 excel을 불러오고 경로를 추가하면 된다.
excel은 마찬가지로 pd.read에서 excel을 불러오고 경로를 추가하면 된다.
위에 불러온 엑셀같은 경우는 인덱스에 필요 없는 부분이 너무 많아서 날려버리려고 할때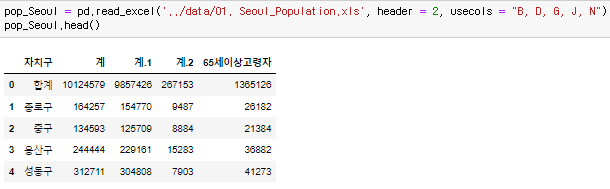 head에서 2개를 날리고 필요한 columns를 불러오면 된다. 그리고 columns 값을 바꾸기 위해 rename(columns = {}, inplace = True) 를 써준다.
head에서 2개를 날리고 필요한 columns를 불러오면 된다. 그리고 columns 값을 바꾸기 위해 rename(columns = {}, inplace = True) 를 써준다. 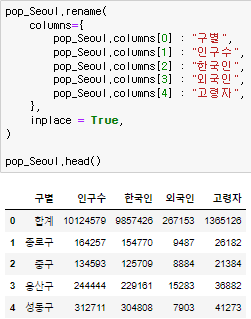
♟️Series
pd.Series() 으로 구현한다. Index와 Value로 이루어져있고 한가지 데이터 타입만 가질 수 있다. 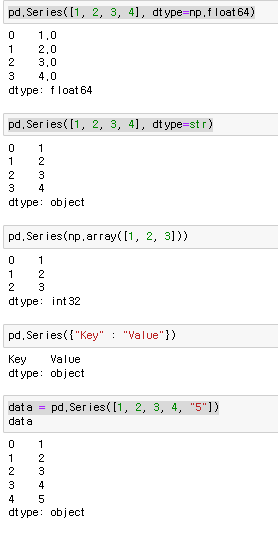
♟️DataFrame
pd.DafaFrame() 으로 구현한다. Index, columns, value로 이루어져있다.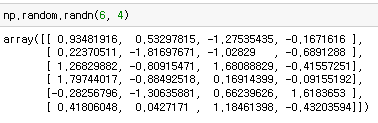 표준정규분포에서 샘플링한 난수 생성. 6개의 Index와 4개의 columns
표준정규분포에서 샘플링한 난수 생성. 6개의 Index와 4개의 columns
♟️데이터 프레임 정보 탐색
그리고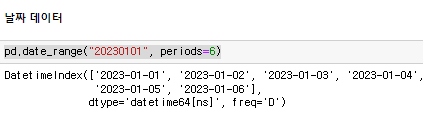 날짜 데이터를 통해 6개의 Index를 만들어주면
날짜 데이터를 통해 6개의 Index를 만들어주면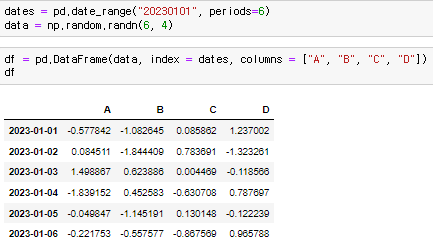
data, index = dates(날짜 데이터), columns는 직접 입력. 을 통해 DataFrame을 만들수 있다.
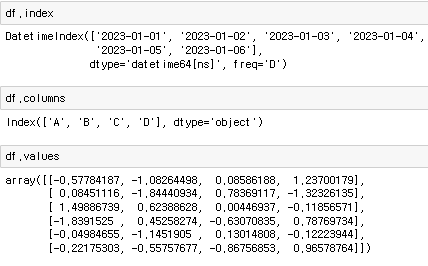 이렇게 만든 DataFrame의 각각의 요소들은 물론 호출이 가능하고
이렇게 만든 DataFrame의 각각의 요소들은 물론 호출이 가능하고 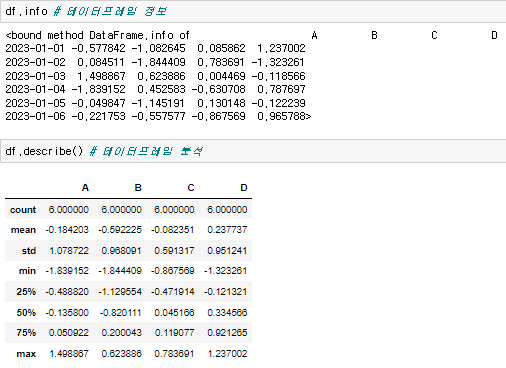 정보와 각종 값 분석도 가능하다.
정보와 각종 값 분석도 가능하다.
♟️데이터 정렬
sort_values() 로 구현. 특정 기준에 따라 컬럼(열)을 정렬한다.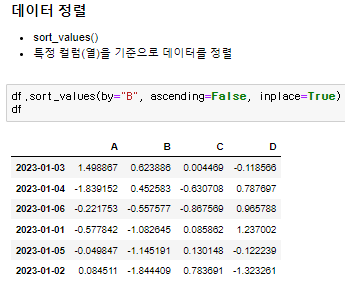
♟️데이터 선택
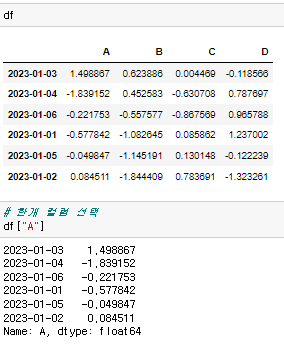 원하는 컬럼을 불러올 수 있다. 컬럼은 숫자가 아니라 문자형이어야 한다.
원하는 컬럼을 불러올 수 있다. 컬럼은 숫자가 아니라 문자형이어야 한다.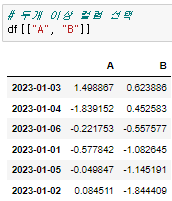 두개 이상의 컬럼을 선택할 때는 리스트 안에 넣어서 입력해야 출력이 된다.
두개 이상의 컬럼을 선택할 때는 리스트 안에 넣어서 입력해야 출력이 된다.
♟️슬라이싱
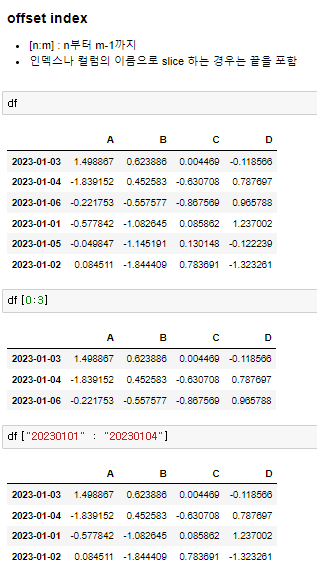
♟️loc을 이용한 슬라이싱
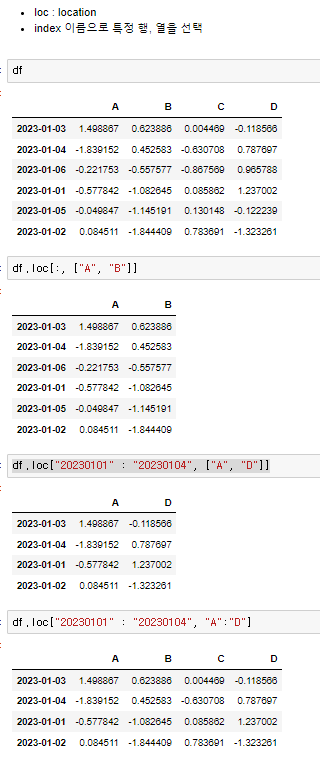
♟️iloc를 이용한 슬라이싱
iloc : inter location, 즉 컴퓨터가 인식하는 인덱스 값으로 선택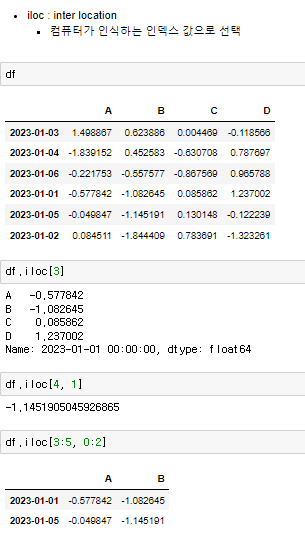
♟️조건문
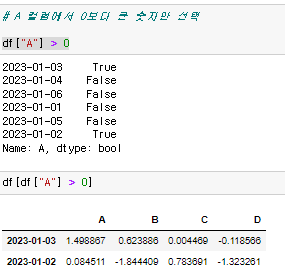 전체 데이터중 columns A의 값이 0보다 큰 것을 출력. 0보다 크면 True 나옴. 이 값을 다시 마스킹해서 출력
전체 데이터중 columns A의 값이 0보다 큰 것을 출력. 0보다 크면 True 나옴. 이 값을 다시 마스킹해서 출력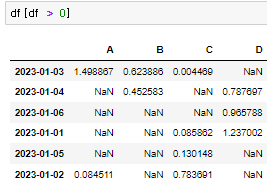 Nan : Not a Number
Nan : Not a Number
♟️컬럼추가
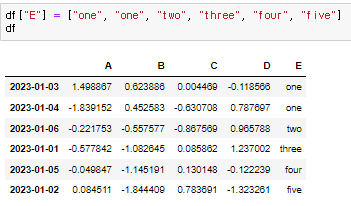 기존 컬럼이 없으면 추가, 있으면 수정을 한다.
기존 컬럼이 없으면 추가, 있으면 수정을 한다.
♟️컬럼 제거
del, drop 을 사용
♟️del
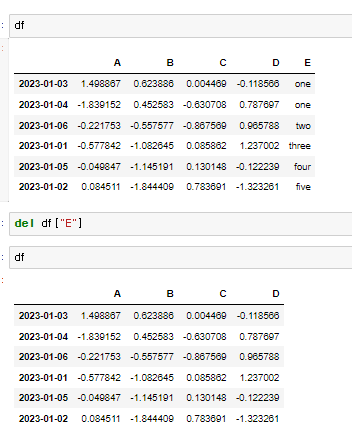
♟️drop
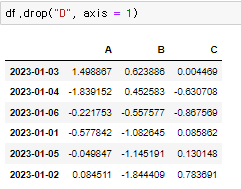 지우고 싶은 행(열)과 axis를 입력. axis = 0 일때 가로, axis = 1일때 세로
지우고 싶은 행(열)과 axis를 입력. axis = 0 일때 가로, axis = 1일때 세로
♟️isin()
특정 요소가 있는지 확인
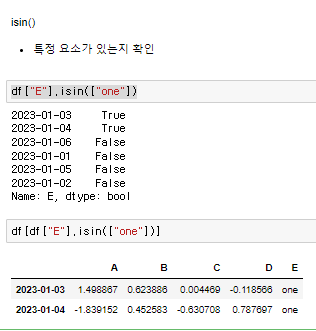 마찬가지로 마스킹을 해서 그 값들만 출력
마찬가지로 마스킹을 해서 그 값들만 출력
♟️apply()
원하는 기능 추가
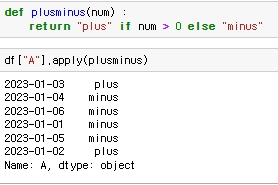 직접 만든 함수도 추가 가능
직접 만든 함수도 추가 가능
♟️오늘의 공부를 마치며
드디어 EDA 부분에 들어왔다. 생각보다 setup에 많은 시간이 걸렸고 머리속에 들어오는 양도 너무 많아 헷갈린다. python을 처음 배울때보다 더 복잡한거 같다.
