
● 오늘의 공부
- 서울시 범죄 데이터 개요
- 데이터 정리
- Pandas pivot table
- google API 설치
♟️Pandas pivot table
필요한 값 : index, columns, values, aggfunc
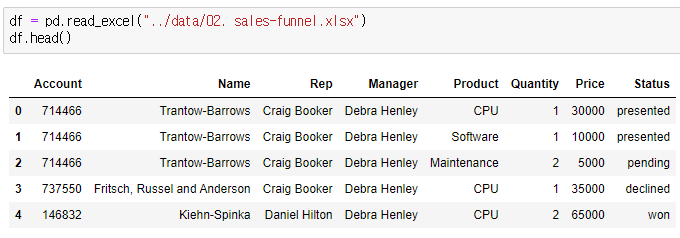 엑셀을 열려고 하는데 계속 "Use pip or conda to install openpyxl" 이라는 에러가 나왔는데 스스로 찾아봐서 conda에서 pip install openpyxl 이라고 하니까 열렸다. 스스로 에러를 해결한 나 아주 칭찬해.
엑셀을 열려고 하는데 계속 "Use pip or conda to install openpyxl" 이라는 에러가 나왔는데 스스로 찾아봐서 conda에서 pip install openpyxl 이라고 하니까 열렸다. 스스로 에러를 해결한 나 아주 칭찬해.
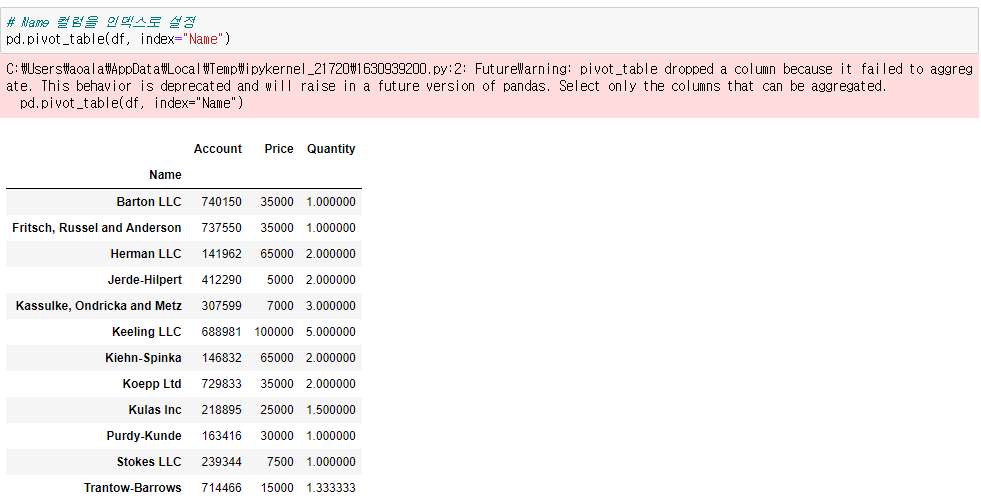
pd.pivot_table() 에서 사용할 데이터와 어떤 컬럼을 인덱스로 쓸지 정해준다
음....???? 아...알겠습니다...무사히 프로젝트 끝내게 해주세요
아...알겠습니다...무사히 프로젝트 끝내게 해주세요
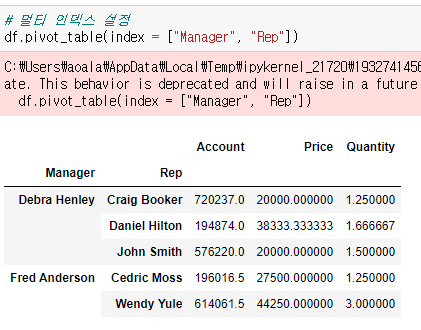
이미 pandas 를 import 했기 때문에 바로 df.pivot_table()에서 여러개의 인덱스를 한번에 지정할 수 있다. 두 개 이상의 인덱스를 만드는거기 때문에 리스트를 이용해서 담아준다.
♟️Python 모듈 설치
♟️pip 명령
- python의 공식 모듈 관리자
- pip list
- pip install module_name
- pip uninstall module_name
♟️conda 명령
- conda list
- conda install module_name
- conda uninstall module_name
- conda install -c channel_name module_name
- 지정된 베포 채널에서 모듈 설치
♟️데이터 설정
♟️values 설정
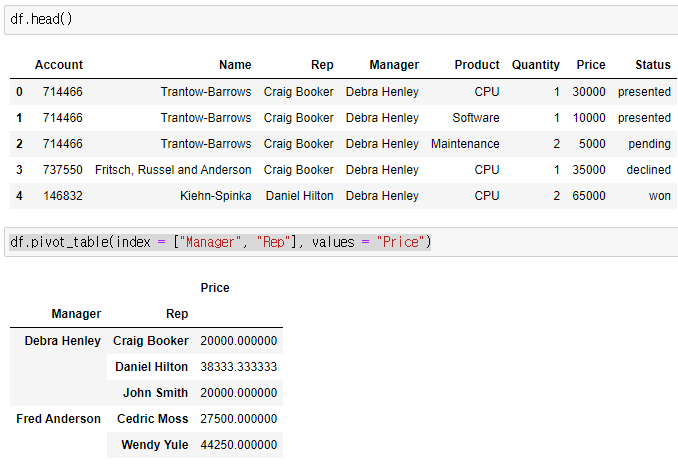 values를 Price로 잡아주고 aggfunc에 덧셈과 덧셈을 한 데이터의 갯수를 구한다.
values를 Price로 잡아주고 aggfunc에 덧셈과 덧셈을 한 데이터의 갯수를 구한다.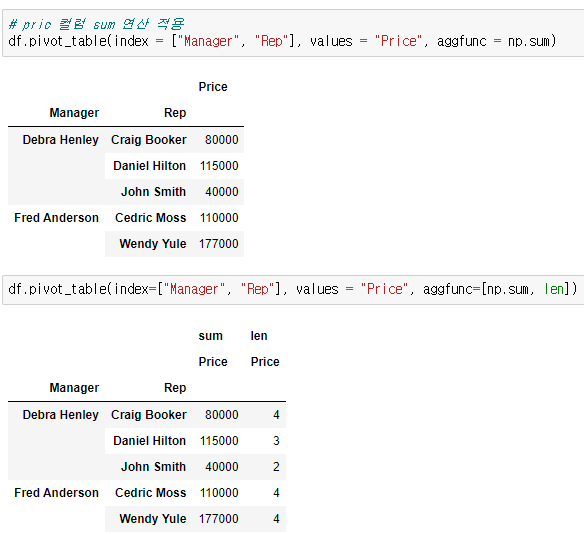
♟️columns 설정
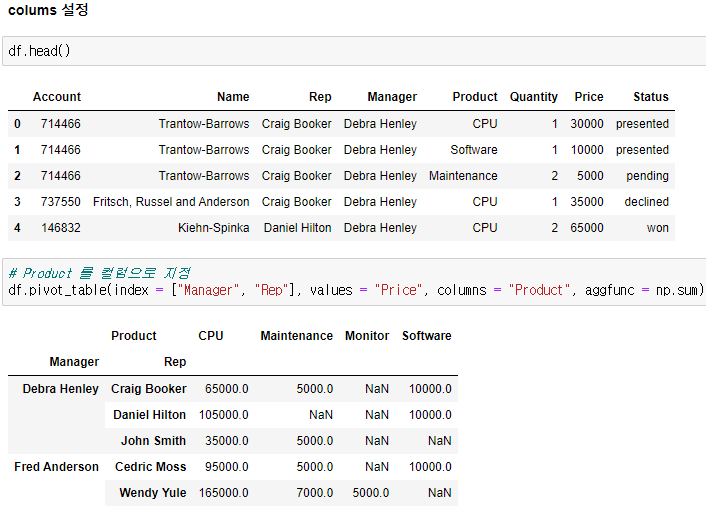
Product 안에도 여러개의 종류가 있는데 Product를 columns로 쓰고 싶으면 columns = "Product"로 하면 된다.
♟️Nan 값 처리
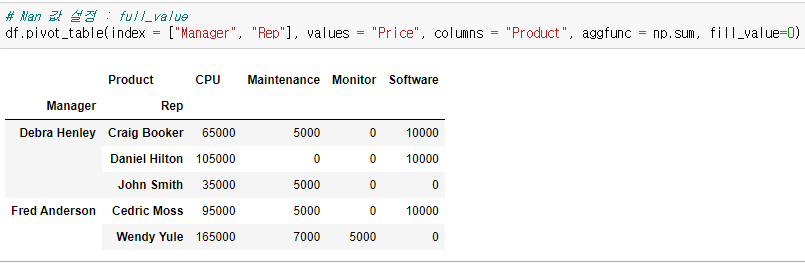
fill_value 를 사용한다. aggfunc에서 fill_value = 0 을 입력하면 Nan 값이 0으로 채워진다.
♟️여러 개의 index, values 설정
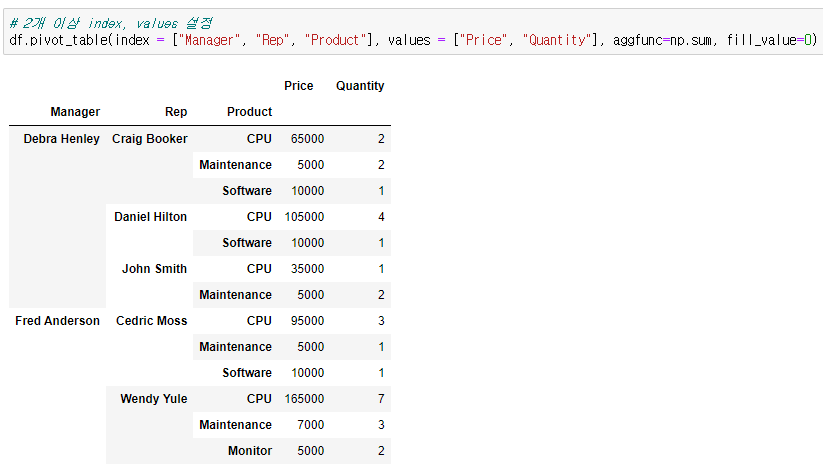 여러 개를 설정하는거라서 앞에서와 마찬가지로 리스트 안에 넣어서 나열해주면 된다
여러 개를 설정하는거라서 앞에서와 마찬가지로 리스트 안에 넣어서 나열해주면 된다
♟️aggfunc 2개 이상 설정
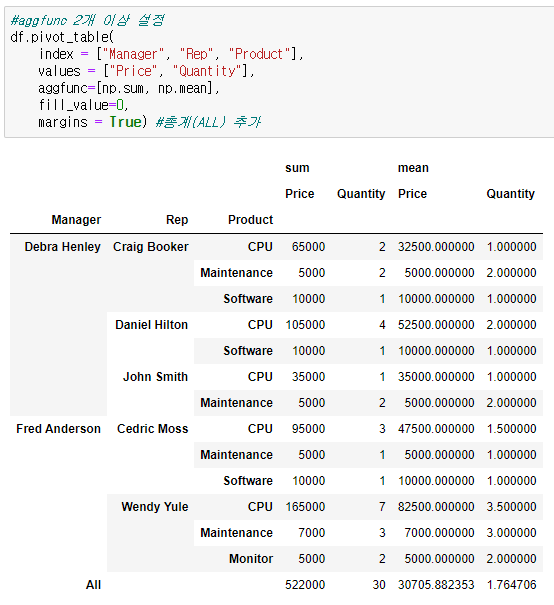
np.sum 과 np.mean 합계와 평균을 aggfunc에 넣고 margins 라는 총계도 추가할 수 있다.
♟️데이터 개요
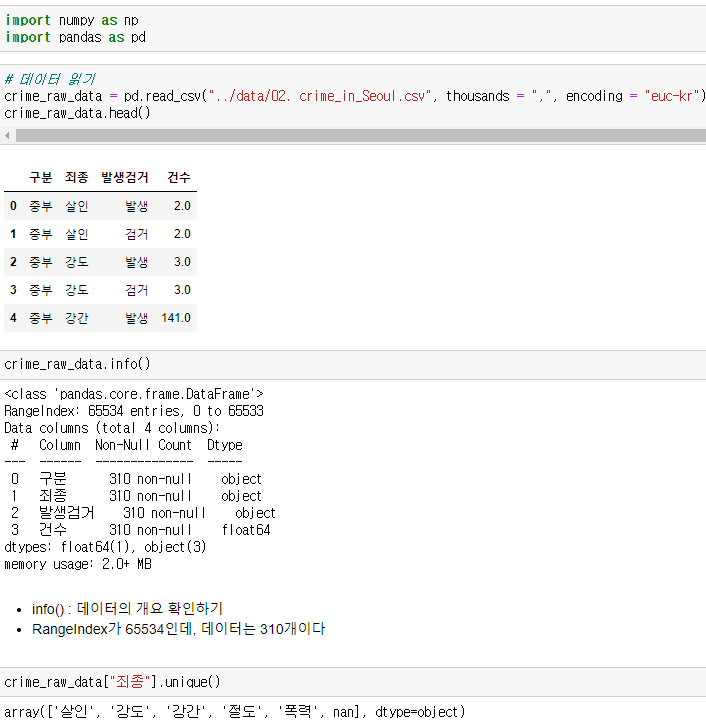
죄종이라는 columns을 봤는데 맨 마지막에 nan 값이 있다. 특정 컬럼에 uniqie 조사를 했는데 nan값이 들어가있으면 isnull() 함수를 통해 nan값이 어디에 있는지 찾아서 마스킹해주면 데이터 형태로 반환된다. 위에서 RangeIndex는 65534개인데 데이터는 310개이다. 즉, null, 미확인 값이 많기 때문에 notnull()을 통해서 값이 확인된 부분만 사용하기로 한다.
isnull() 함수를 통해 nan값이 어디에 있는지 찾아서 마스킹해주면 데이터 형태로 반환된다. 위에서 RangeIndex는 65534개인데 데이터는 310개이다. 즉, null, 미확인 값이 많기 때문에 notnull()을 통해서 값이 확인된 부분만 사용하기로 한다. notnull()을 통해 나온 부분을 다시 원래 crime_raw_data에 할당하면 값이 null인 약 65000개의 값은 버리고 사용할 수 있다.
notnull()을 통해 나온 부분을 다시 원래 crime_raw_data에 할당하면 값이 null인 약 65000개의 값은 버리고 사용할 수 있다.
♟️현황 데이터 정리
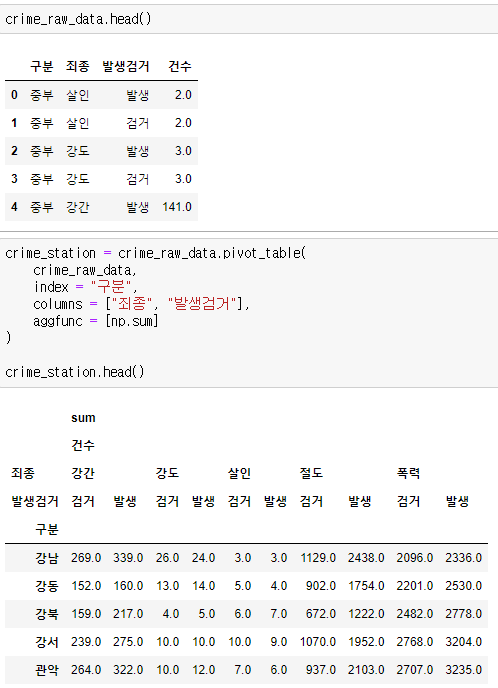 pivot_table을 쓰기 위해서 사용할 데이터, index, columns, values, aggfunc 을 입력했다.
pivot_table을 쓰기 위해서 사용할 데이터, index, columns, values, aggfunc 을 입력했다.
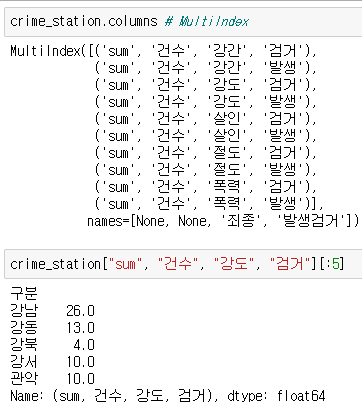
입력 후 index나 columns에 접근도 가능하다. 접근한 columns에서 날리고 싶은게 있을때는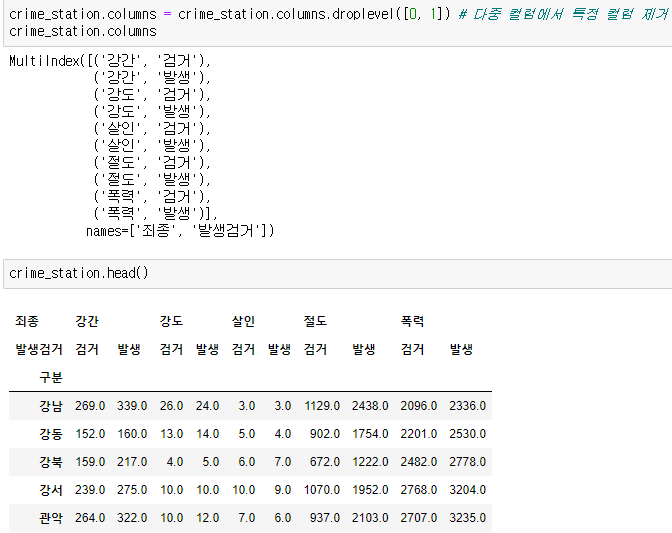
droplevel을 이용해 지우고 싶은 columns에 인덱스를 입력한다.
♟️google API 설치

