
● 오늘의 공부
- Pandas의 반복문
- Google Maps를 이용한 데이터 정리
- 데이터 정리
- Seaborn
♟️for반복문
Pandas에 잘 맞춰진 반복문용 명령 iterrows()
- Pandas 데이터 프레임은 대부분 2차원
- 이럴때 for문을 사용하면 n번째라는 지정을 반복하면 가독성이 떨어짐
- Pandas 데이터 프레임으로 반복문을 만들때는 iterrows() 옵션을 사용하면 편함
- 받을때, 인덱스와 내용으로 나누어 받는 것에 주의
♟️Google Maps를 이용한 데이터 정리
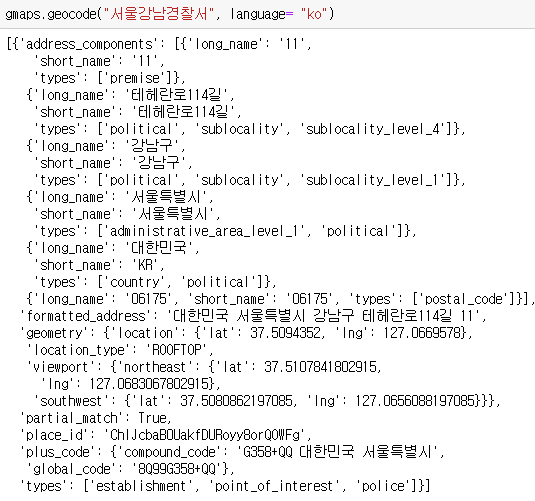 Google Maps를 이용하면 import를 했을때 이렇게 딕셔너리 형태로 정보가 뜬다.
Google Maps를 이용하면 import를 했을때 이렇게 딕셔너리 형태로 정보가 뜬다.
 이렇게 나온 데이터의 길이는 1이고 호출이 가능하다. get() 함수를 써 데이터 안에서 호출할 정보를 부르고 다시 안에 세부정보를 호출한다. 이렇게 가능한것이 다 딕셔너리 형태이기 때문에 가능하다.
이렇게 나온 데이터의 길이는 1이고 호출이 가능하다. get() 함수를 써 데이터 안에서 호출할 정보를 부르고 다시 안에 세부정보를 호출한다. 이렇게 가능한것이 다 딕셔너리 형태이기 때문에 가능하다.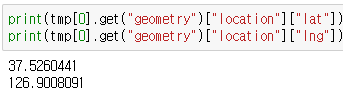
 주소를 불러올때도 마찬가지로 get()을 쓰고 문자열을 띄어쓰기 기준으로 나눌 수 있는 split()을 써서 리스트 형태로 받아준다. 리스트 형태로 반환된 데이터는 또 호출이 가능하기 때문에 2번째 인덱스에 있는 '구'를 가져와준다.
주소를 불러올때도 마찬가지로 get()을 쓰고 문자열을 띄어쓰기 기준으로 나눌 수 있는 split()을 써서 리스트 형태로 받아준다. 리스트 형태로 반환된 데이터는 또 호출이 가능하기 때문에 2번째 인덱스에 있는 '구'를 가져와준다.
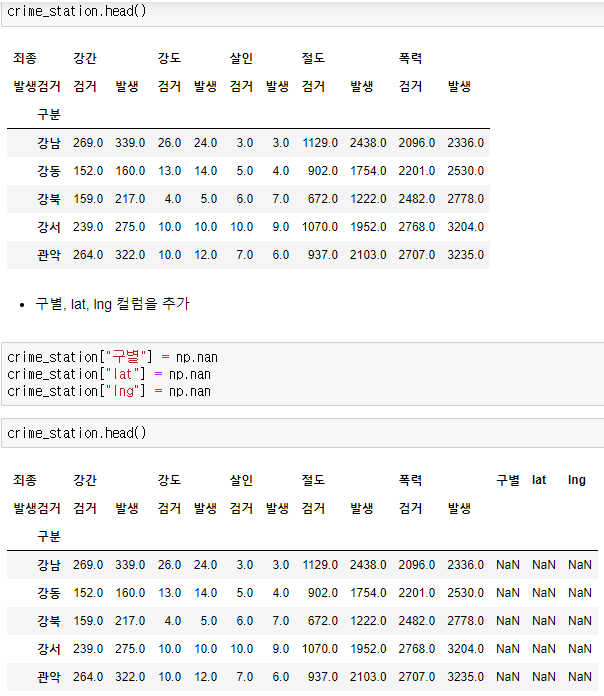
- 경찰서 이름에서 소속된 구 이름 얻기
- 구 이름과 위도 경도 정보를 저장할 준비
- 반복문을 이용해서 위 표의 NaN을 모두 채우기
- iterrows()

 반복문을 이용해서 google maps에 넣을 이름을 만들어주고 google api에 넣어서 돌린 값을 받는다. 여기서 아까한거처럼 split()[2]로 구 위치를 받고 위도 경도를 다 받아서 데이터 프레임에 넣어준다.
반복문을 이용해서 google maps에 넣을 이름을 만들어주고 google api에 넣어서 돌린 값을 받는다. 여기서 아까한거처럼 split()[2]로 구 위치를 받고 위도 경도를 다 받아서 데이터 프레임에 넣어준다.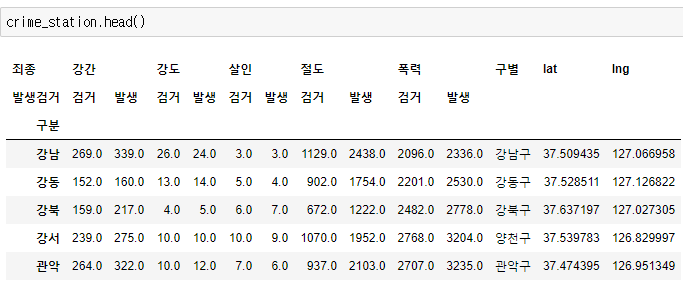
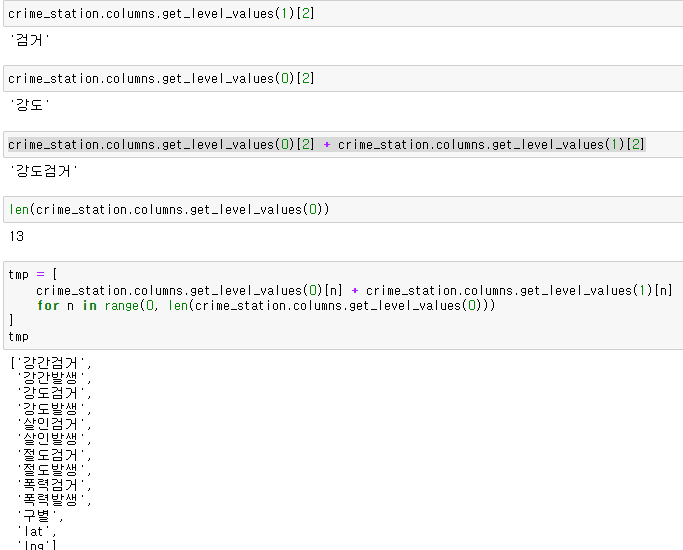
get_level_values()를 통해 columns에 level을 호출할 수 있다. 그리고 호출된 데이터들은 각각 str타입이어서 더할수 있다. 반복문을 이용해 get_level_values()를 통해 얻은 columns들을 다 더해준다. 그리고 나서 crime_station.columns에 방금 합친 tmp를 넣으면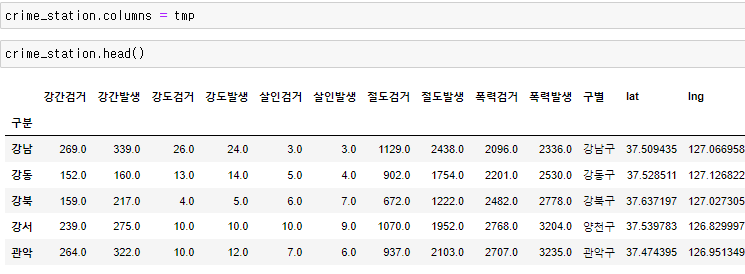
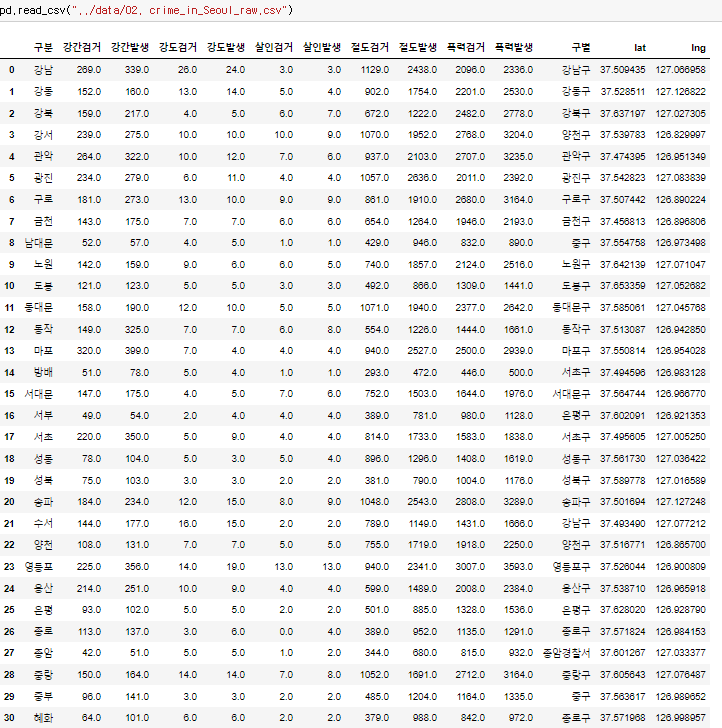
♟️구별 데이터로 정리
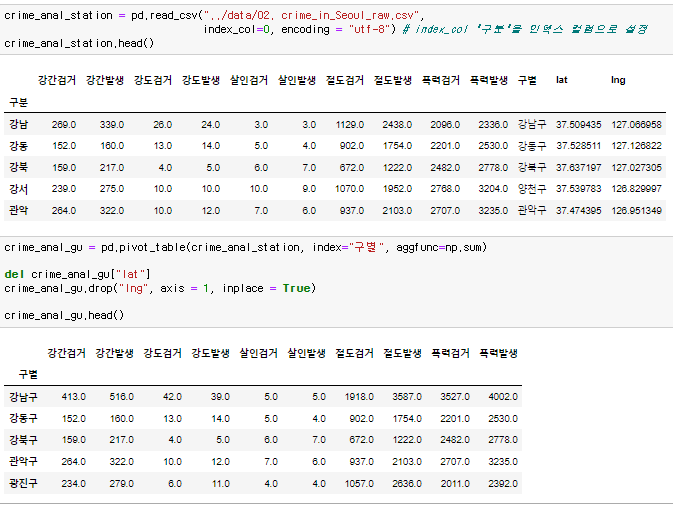 index_col을 이용해 원하는 "구별" 이라는 항목을 인덱스로 쓰고 한국어로 데이터를 다루니까 encoding = "utf-8"을 써준다. 그리고 pivot_table()을 이용해 crime_anal_station, index = "구별", 모두 더하는 기능을 쓰고 위도와 경도는 지워준다.
index_col을 이용해 원하는 "구별" 이라는 항목을 인덱스로 쓰고 한국어로 데이터를 다루니까 encoding = "utf-8"을 써준다. 그리고 pivot_table()을 이용해 crime_anal_station, index = "구별", 모두 더하는 기능을 쓰고 위도와 경도는 지워준다.
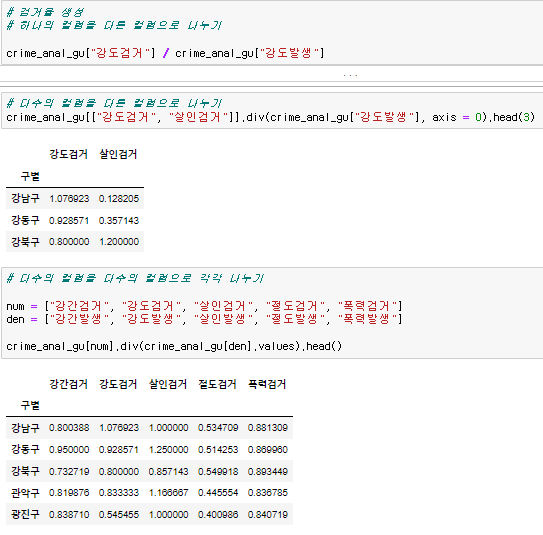 검거율 생성을 위해 사건발생 / 사건검거 를 계산한다.
검거율 생성을 위해 사건발생 / 사건검거 를 계산한다. 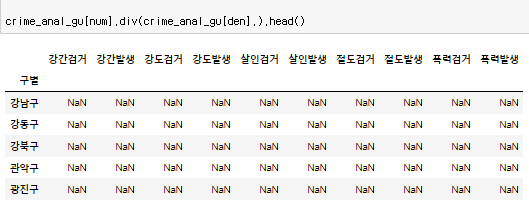 계산을 할 때 values를 빼먹으면 NaN으로 처리가 되니 주의
계산을 할 때 values를 빼먹으면 NaN으로 처리가 되니 주의
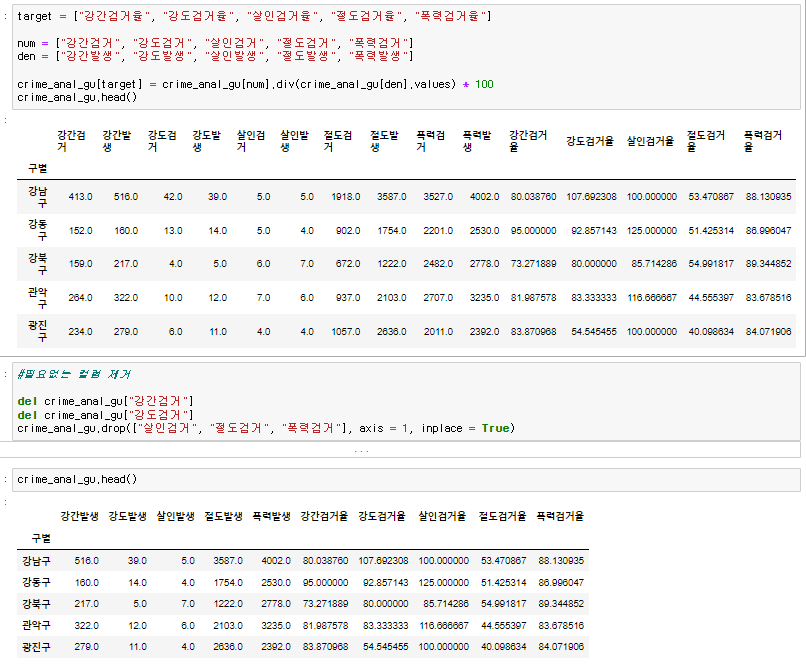 검거율이라는 새로운 columns를 넣어주고 필요없는 발생 columns를 지워준다.
검거율이라는 새로운 columns를 넣어주고 필요없는 발생 columns를 지워준다.
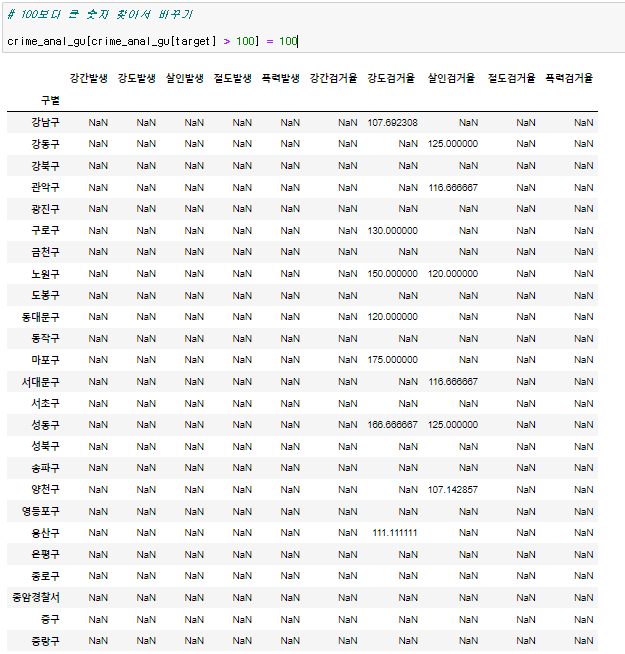 검거율은 확률이다. 확률이 100을 넘으면 안되니까 target에서 100이 넘는 애들을 찾아 다시 마스킹을 해주면 결과가 나온다. 마스킹해서 나온 데이터들을 100으로 변경시켜주면 된다.
검거율은 확률이다. 확률이 100을 넘으면 안되니까 target에서 100이 넘는 애들을 찾아 다시 마스킹을 해주면 결과가 나온다. 마스킹해서 나온 데이터들을 100으로 변경시켜주면 된다.
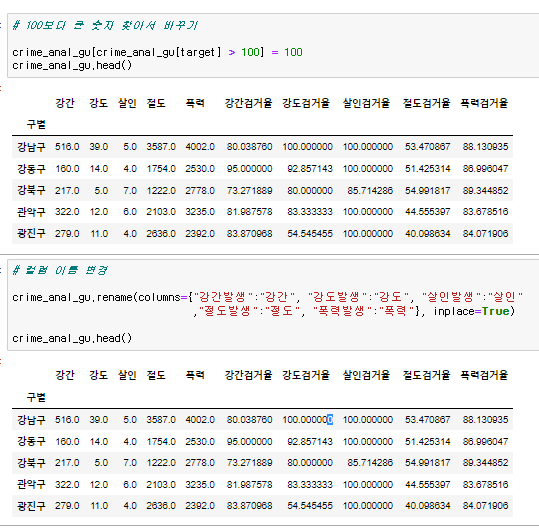 그리고 발생 단어를 빼주고 보기 쉽게 단어를 바꿔준다.
그리고 발생 단어를 빼주고 보기 쉽게 단어를 바꿔준다.
♟️데이터 정리
♟️정규화
최고값은 1, 최소값은 0. 최대값으로 모든 인수들을 나누어 0과 1사이의 숫자로 표현한다.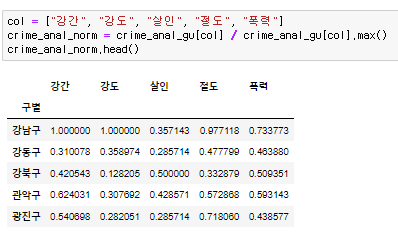
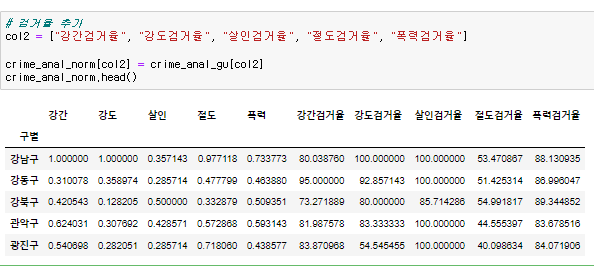 그 상태에서 검거율을 추가한다.
그 상태에서 검거율을 추가한다.
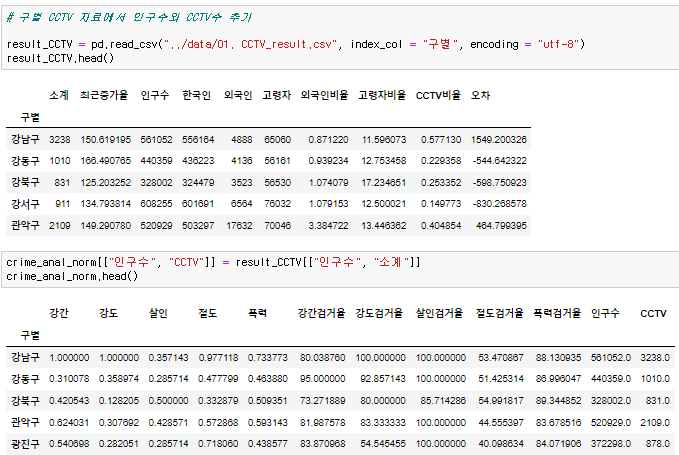 지난번에 만들었던 CCTV 결과를 불러와서 columns를 추가해준다.
지난번에 만들었던 CCTV 결과를 불러와서 columns를 추가해준다.
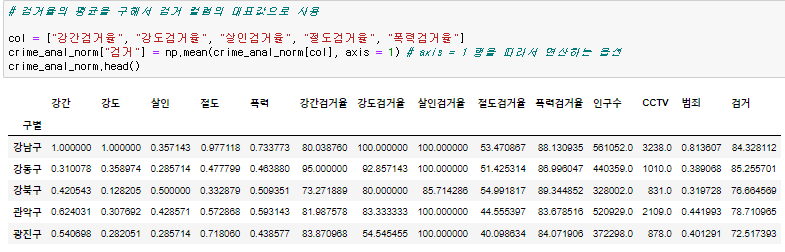 마찬가지로 각 지역별 검거율의 평균을 구한 검거라는 columns 을 만들어준다.
마찬가지로 각 지역별 검거율의 평균을 구한 검거라는 columns 을 만들어준다.
♟️Seaborn
!conda install -y seaborn 을 이용해 seaborn 다운로드
pandas, numpy, 한글, matplotlib 전부 import 해준다
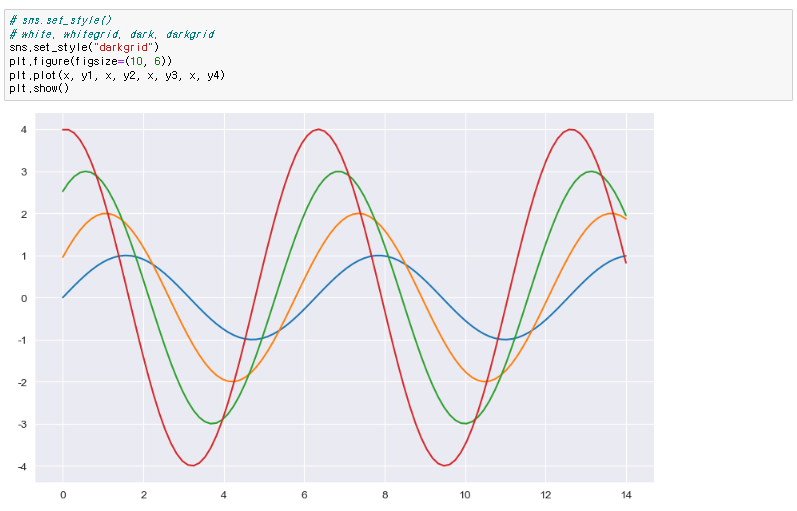
♟️seaborn data
-
boxplot
-
swarmplot
-
lmplot
-
hearmap
-
pairplot
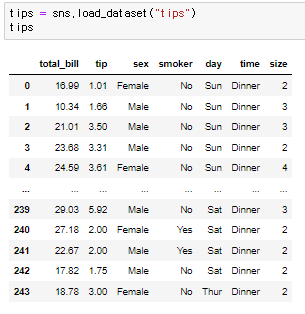
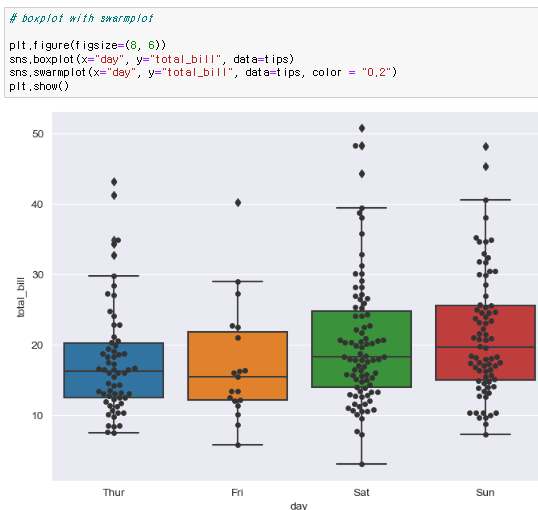
boxplot
swarmplot
lmplot 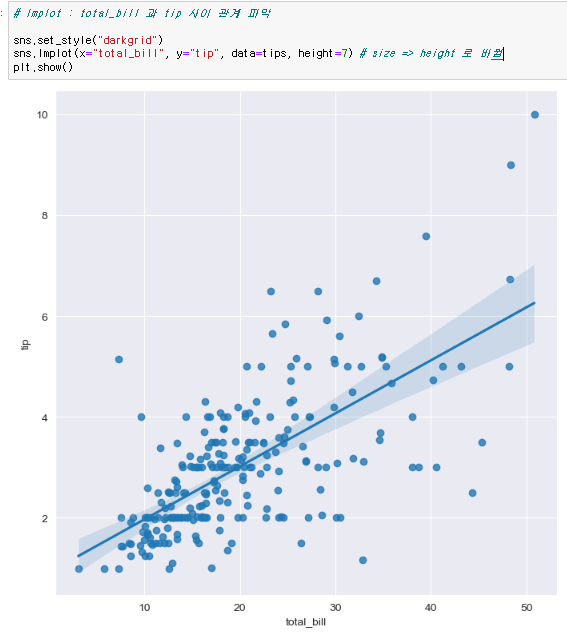
lmplot은 float형 데이터에 쓸수있다.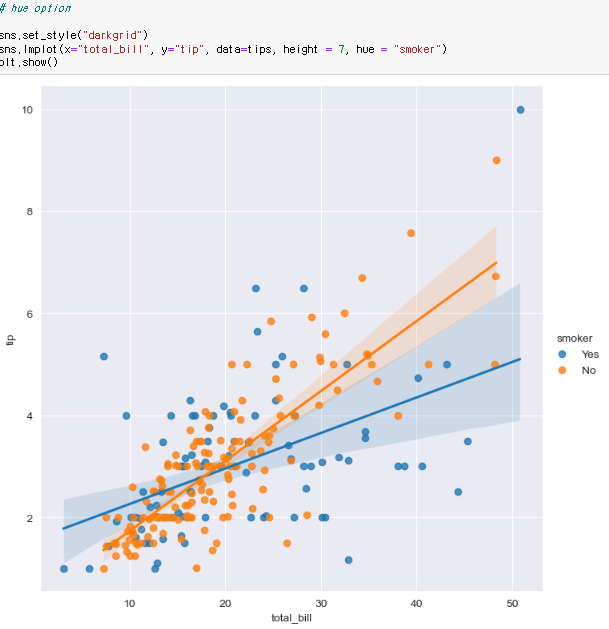 hue option을 이용한 카테고리도 lmplot에 사용할 수 있다.
hue option을 이용한 카테고리도 lmplot에 사용할 수 있다.
heatmap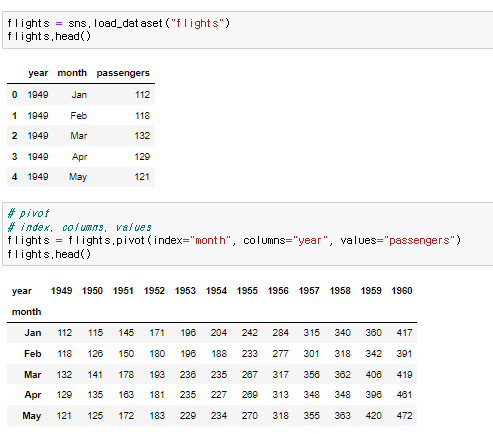 데이터를 불러와준 다음에 pivot을 이용해서 데이터 프레임 형태로 만든다. 그러고 sns.heatmap()을 이용한다. heatmap에 필요한 요소는 data, annot, fmt이다. data는 무슨 데이터를 쓸건지, annot은 숫자를 데이터에 표기할지말지 fmt는 format이고 d는 python에서 배운 정수형이다.
데이터를 불러와준 다음에 pivot을 이용해서 데이터 프레임 형태로 만든다. 그러고 sns.heatmap()을 이용한다. heatmap에 필요한 요소는 data, annot, fmt이다. data는 무슨 데이터를 쓸건지, annot은 숫자를 데이터에 표기할지말지 fmt는 format이고 d는 python에서 배운 정수형이다.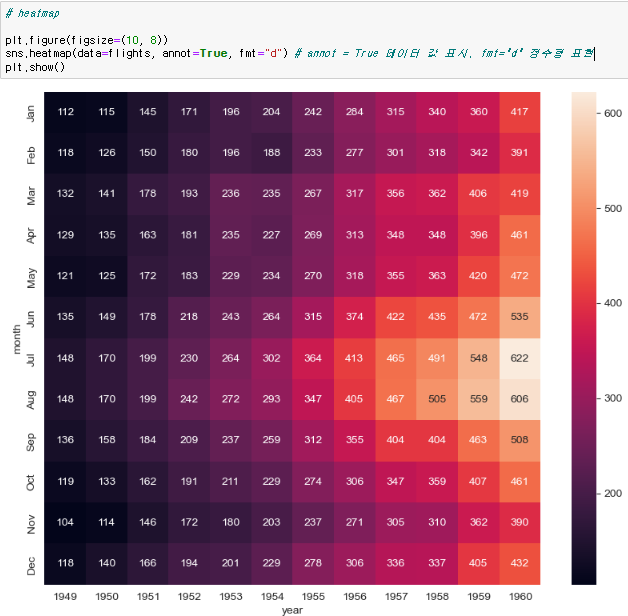
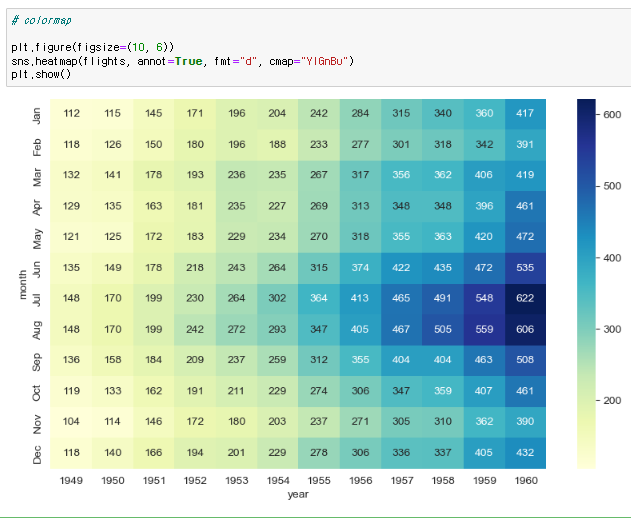 colormap을 이용해 색을 바꿀수도 있다.
colormap을 이용해 색을 바꿀수도 있다.
pairplot
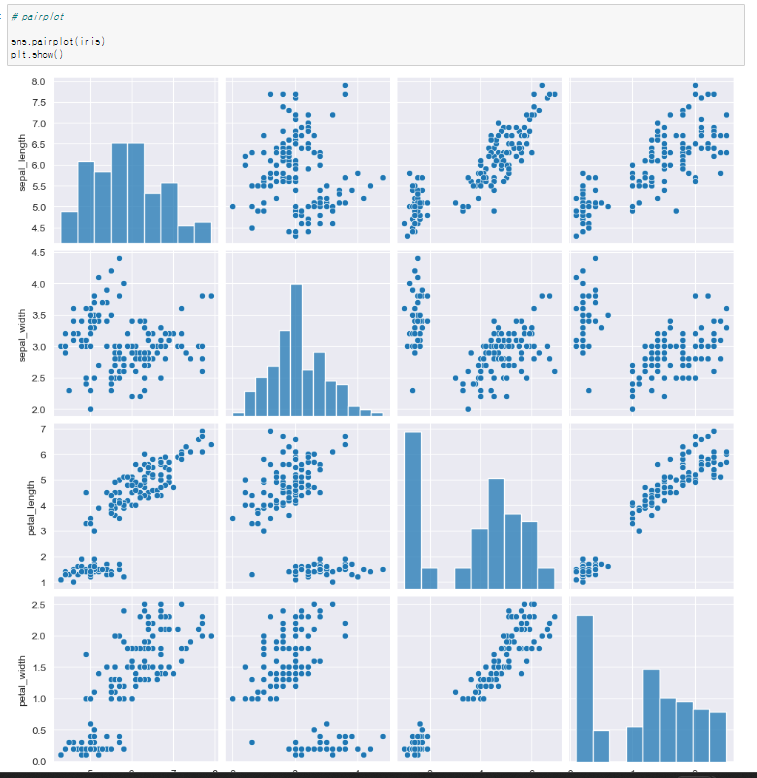
iris는 모든 경우의 수를 보여준다.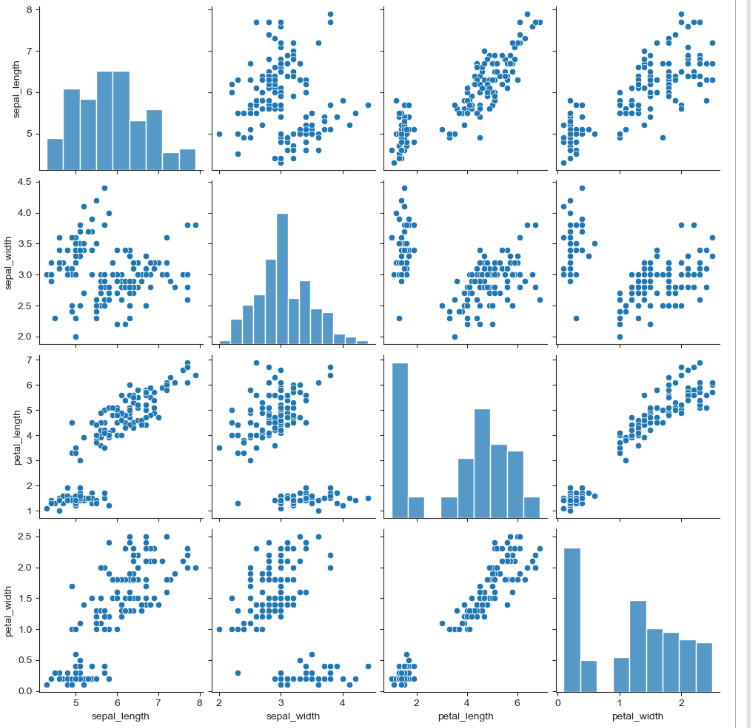 sns.set_style()에 ticks를 넣으면 형태가 또 다르게 된다.
sns.set_style()에 ticks를 넣으면 형태가 또 다르게 된다.
 iris["species"].unique를 써주면 세가지 종류가 나오는데 pairplot에 hue option으로 species를 걸어주면
iris["species"].unique를 써주면 세가지 종류가 나오는데 pairplot에 hue option으로 species를 걸어주면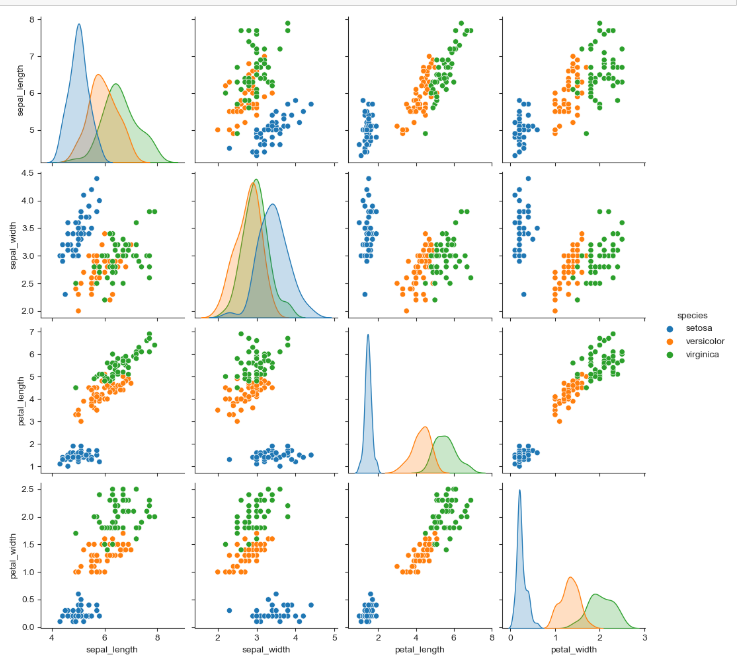 각각의 그래프가 무엇을 나타내는지 알 수 있다.
각각의 그래프가 무엇을 나타내는지 알 수 있다.
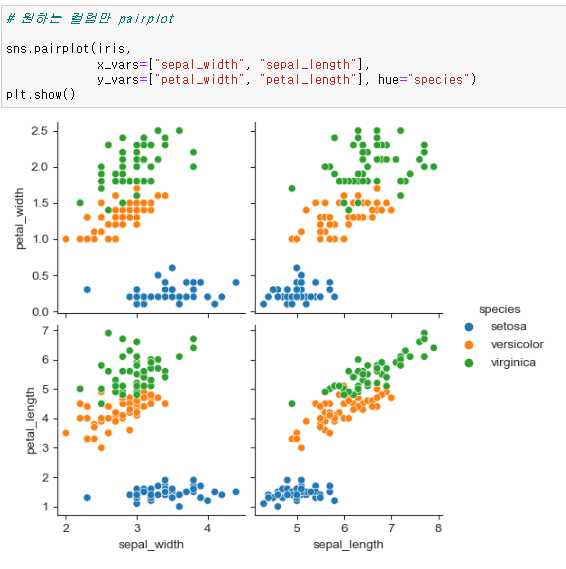
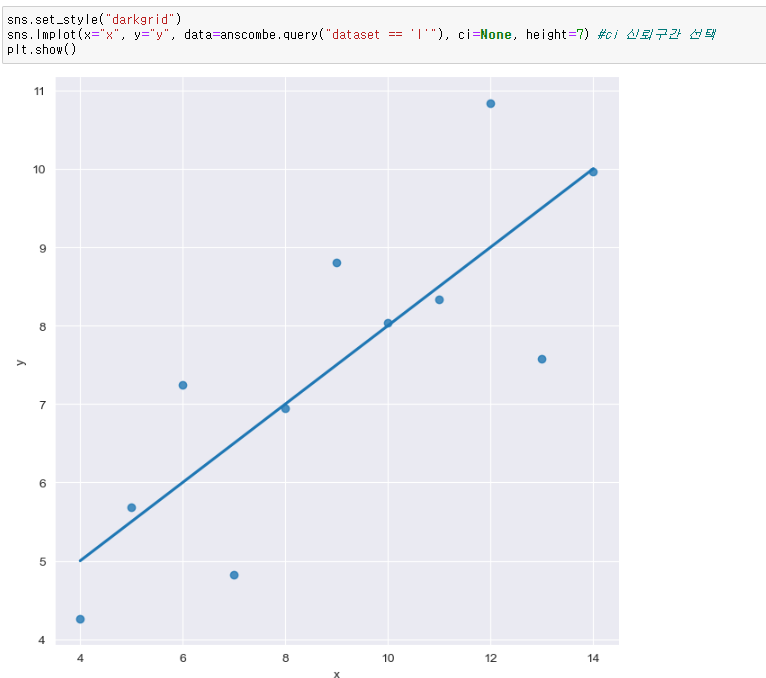
scatter_kws option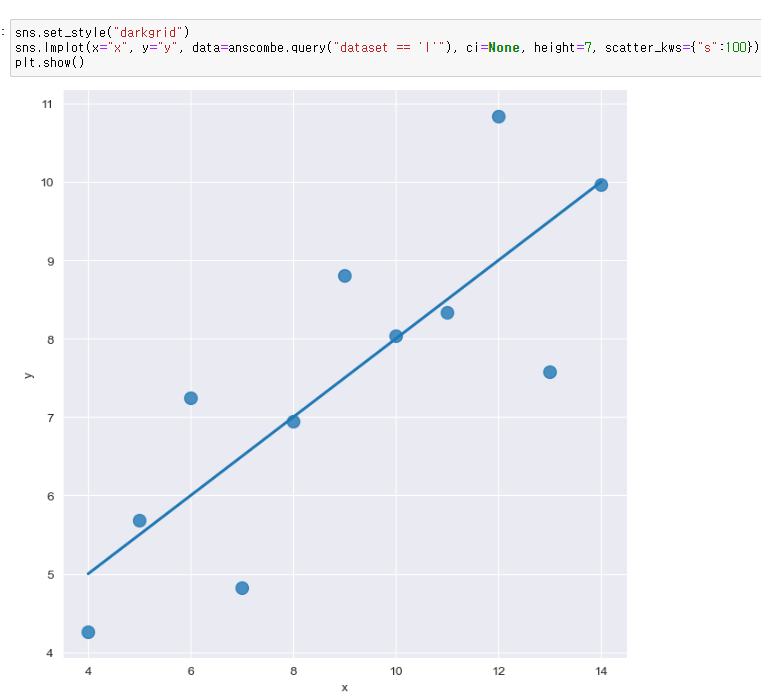
order option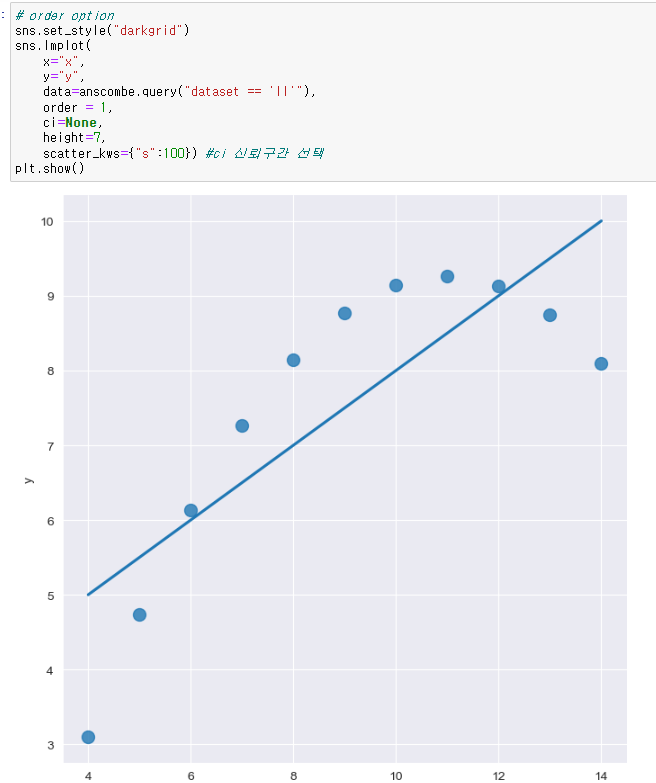
robust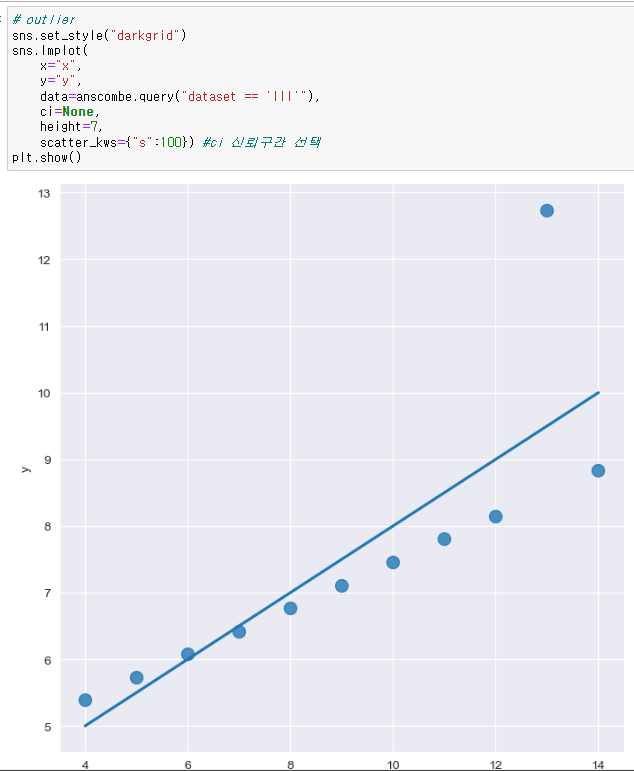
혼자 동떨어져있는 데이터 때문에 전체 경향 직선이 들려있는 경우가 있다. 그때 robust = True 로 해주면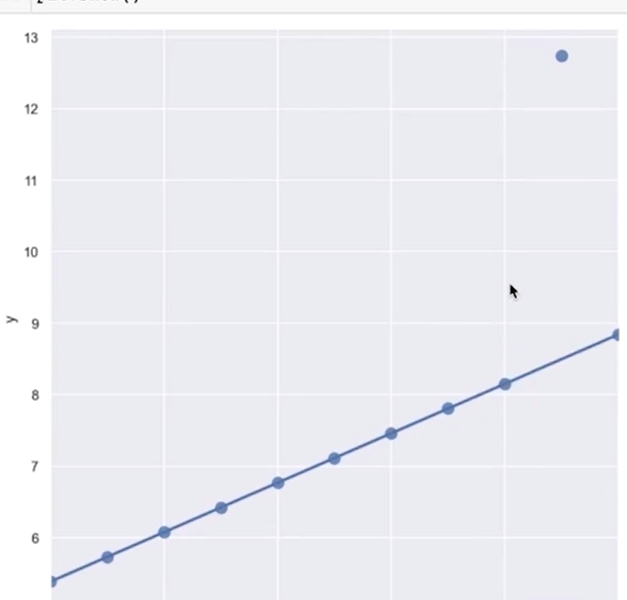
선이 이어져있다.
