
● 오늘의 공부
- selenium
♟️selenium 설치
 conda에서 jupyter notebook 을 활성화시키고 conda install selenium이라고 한다.
conda에서 jupyter notebook 을 활성화시키고 conda install selenium이라고 한다.
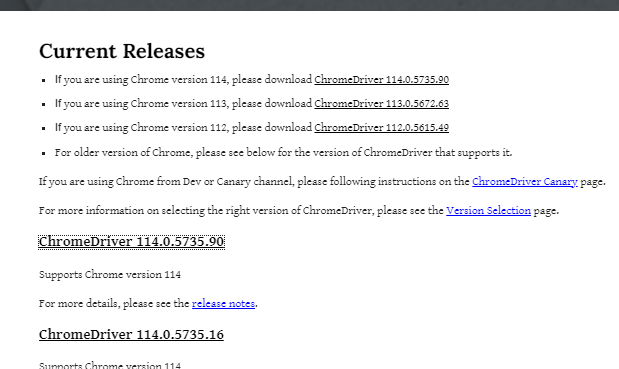
내 컴퓨터에 맞는 Chrome driver를 다운받은 후에 공부하는 폴더로 옮겨주고
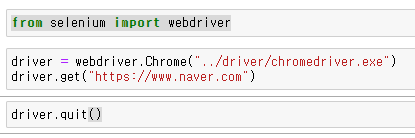
selenium에서 webdriver를 import 한 후에 get()에다 네이버 페이지를 입력하면 네이버 두두등장. selenium 설치 성공
네이버 두두등장. selenium 설치 성공
♟️selenium 세팅
♟️selenium을 쓰는 이유
-
Beautiful Soup 만으로 해결할 수 없을 때
- 접근할 웹 주소를 알 수 없을 때
- 자바스크립트를 사용하는 웹페이지의 경우
- 웹 브라우저로 접근하지 않으면 안될 때 -
웹 브라우저를 원격 조작하는도구
-
자동으로 URL을 열고 클릭 등이 가능
-
스크롤, 문자의 입력, 화면 캡처 등등
♟️selenium webdriver 사용
 selenium에서 webdriver를 import => 변수 선언 => get(URL)로 시작 => 종료할 때는 quit()
selenium에서 webdriver를 import => 변수 선언 => get(URL)로 시작 => 종료할 때는 quit()
♟️webdriver의 기초 기능

webdriver로 켜진 화면을 최대 크기와 최소 크기로 세팅해준다. 그리고 set_window_size()를 이용하면 지정된 사이즈로 맞춰진다.
지정된 사이즈로 맞춰진다.
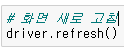 driver.refresh()를 이용하면 화면이 새로 고침된다.
driver.refresh()를 이용하면 화면이 새로 고침된다.
 뒤로가기와 앞으로 가기 이다.
뒤로가기와 앞으로 가기 이다.

데이터 찾기 기능을 쓰기 위해서는 selenium.webdriver.common.by 에서 By 라는 모듈을 import 해주어야 한다.
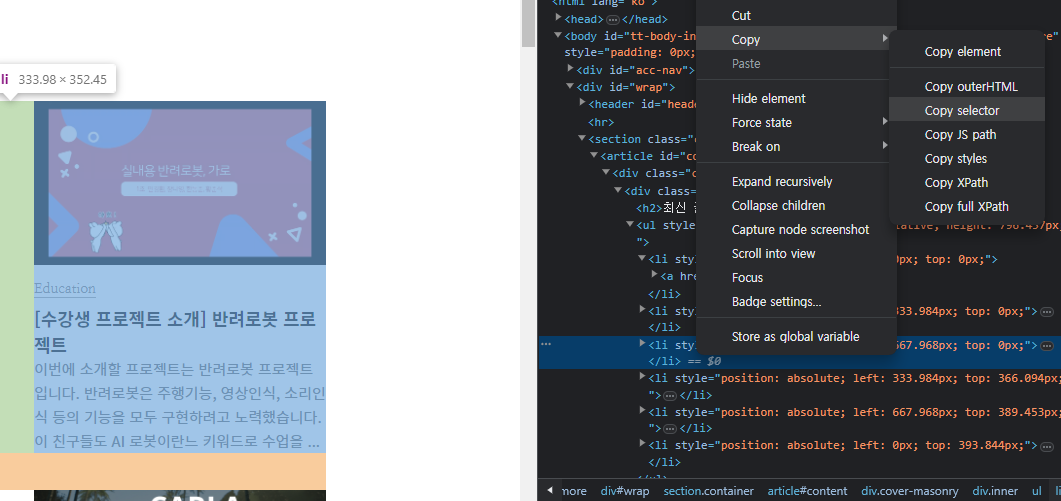
그리고 개발자 모드에서 원하는 html을 복사해서 driver.find_element()에 넣어준다. By 모듈을 import 했기 때문에 By.CSS_SELECTOR, 그리고 복사한 html 주소를 입력하면 원하는 html에서 기능을 사용할 수 있다. 그리고 .click()을 하면 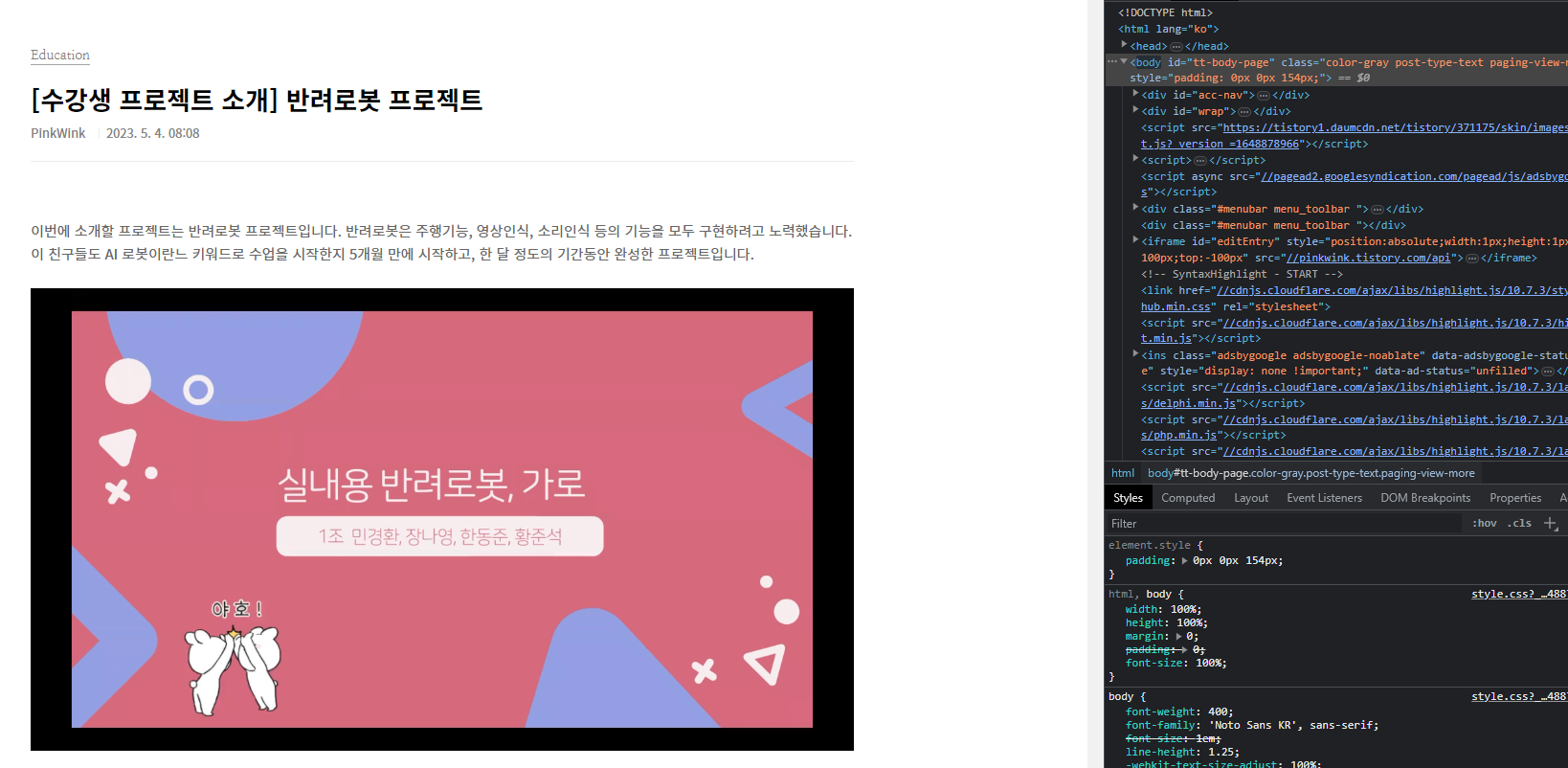 페이지가 넘어와지는걸 볼 수 있다.
페이지가 넘어와지는걸 볼 수 있다.
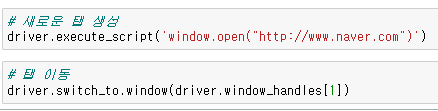 새로운 탭은 driver.execute_script('window.open("))으로 괄호 안에 원하는 주소를 입력하고 driver.switch_to.window(driver.window_handles[])안에 인덱스를 넣어 원하는 탭으로 이동할 수 있다.
새로운 탭은 driver.execute_script('window.open("))으로 괄호 안에 원하는 주소를 입력하고 driver.switch_to.window(driver.window_handles[])안에 인덱스를 넣어 원하는 탭으로 이동할 수 있다.
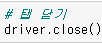 driver.close()를 통해 탭을 닫을 수 있다.
driver.close()를 통해 탭을 닫을 수 있다.
♟️검색어 입력
CSS.SELECTOR검색어 입력을 위해서는 마찬가지로 webdriver를 이용해서 홈페이지를 켠 다음 개발자 도구에서 selector를 이용해서 검색창을 보면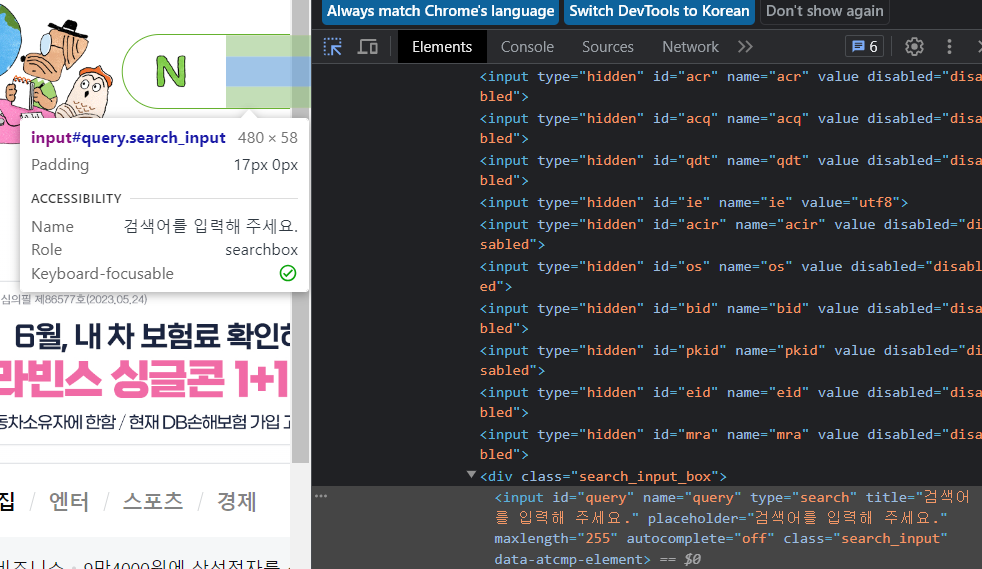 이라고 뜬다. 여기서 copy selector를 이용해 복사해서 붙이면
이라고 뜬다. 여기서 copy selector를 이용해 복사해서 붙이면 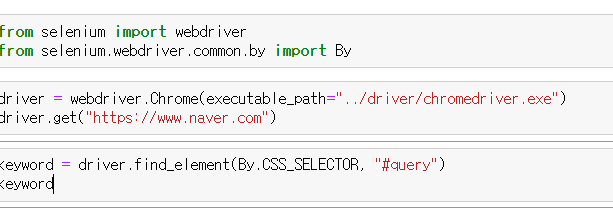 고유 아이디인 #query만 붙여넣기가 된 걸 볼 수 있다. 이거를 keyword라는 변수에 할당해주고 keyword.send.keys("파이썬)이라고 하면 검색창에 자동으로 "파이썬" 이라는 글자가 입력이 된다. 여기서 그치는게 아니라 검색버튼도 눌러줘야 하니깐
고유 아이디인 #query만 붙여넣기가 된 걸 볼 수 있다. 이거를 keyword라는 변수에 할당해주고 keyword.send.keys("파이썬)이라고 하면 검색창에 자동으로 "파이썬" 이라는 글자가 입력이 된다. 여기서 그치는게 아니라 검색버튼도 눌러줘야 하니깐
 마찬가지로 고유 아이디인 #search_btn만 복사가 되고 .click()을 실행하면 자동으로 검색이 된다. 여기서 새로운 단어를 검색하고 싶을때 새로운 단어를 그대로 추가하게 되면 원래 있던 단어상태에서 중첩이 되서 쌓여서 검색이 되기 때문에
마찬가지로 고유 아이디인 #search_btn만 복사가 되고 .click()을 실행하면 자동으로 검색이 된다. 여기서 새로운 단어를 검색하고 싶을때 새로운 단어를 그대로 추가하게 되면 원래 있던 단어상태에서 중첩이 되서 쌓여서 검색이 되기 때문에
 keyword.clear()를 이용해서 검색창을 비워준 후 다시 검색이 되도록 한다.
keyword.clear()를 이용해서 검색창을 비워준 후 다시 검색이 되도록 한다.
XPATHCSS.SELECTOR 와 완전히 방법은 동일하다. 개발자 도구에서 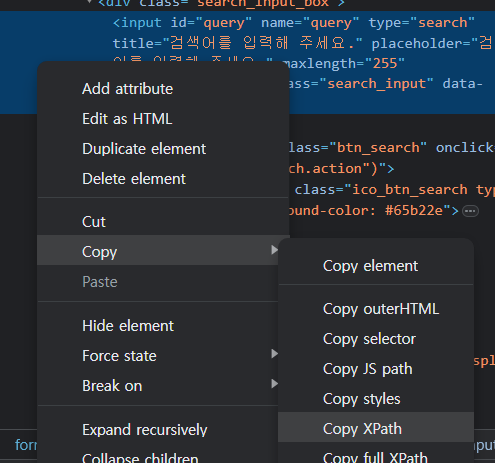 XPATH 복사를 누르고
XPATH 복사를 누르고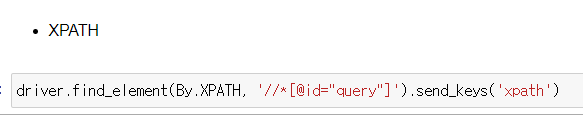
 똑같이 driver.find_element(By.XPATH, '복사한 XPATH').send_keys('단어')를 해주면 검색창에 입력이 된다.
똑같이 driver.find_element(By.XPATH, '복사한 XPATH').send_keys('단어')를 해주면 검색창에 입력이 된다.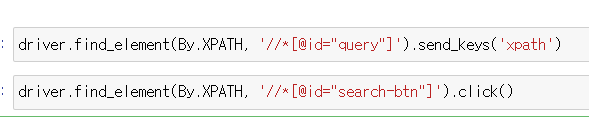 그리고 CSS.SELECTOR 에서 한거처럼 .click()을 하면 검색이 된다.
그리고 CSS.SELECTOR 에서 한거처럼 .click()을 하면 검색이 된다.
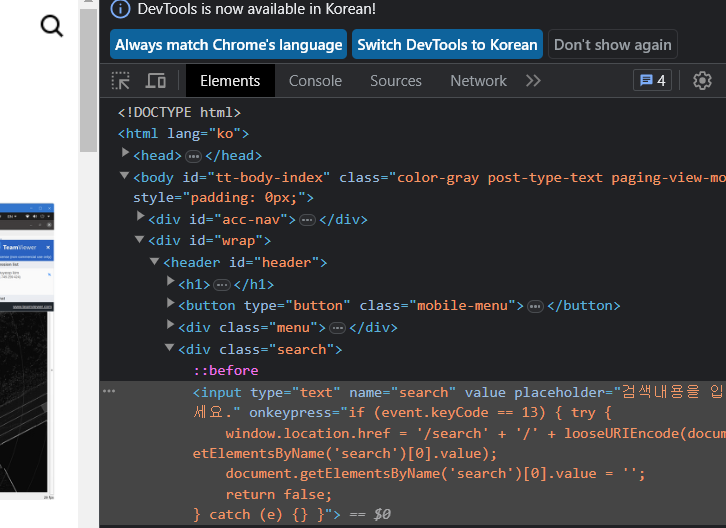
돋보기를 클릭해서 원하는 검색어를 검색하고 싶을때의 절차는 이렇게 세단계이다. 그래서 XPATH든 CSS_SELECTOR든 send_keys()를 이용해도 오류가 뜬다.
이렇게 세단계이다. 그래서 XPATH든 CSS_SELECTOR든 send_keys()를 이용해도 오류가 뜬다.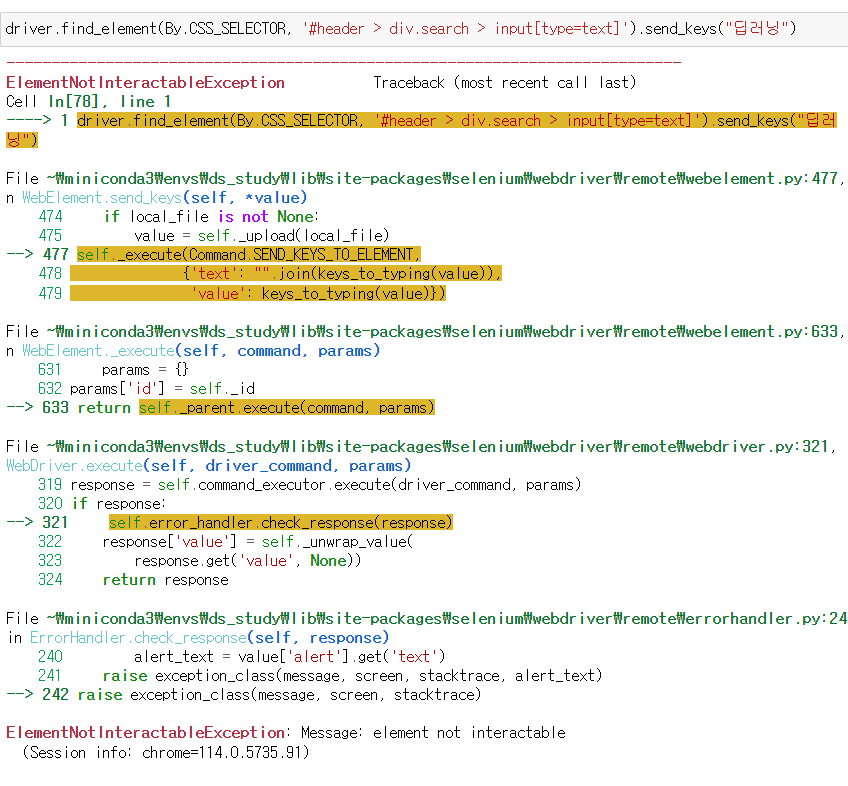 근데 여기서 돋보기 버튼을 눌러 검색창을 활성화 시키고
근데 여기서 돋보기 버튼을 눌러 검색창을 활성화 시키고 다시 코드를 실행하면
다시 코드를 실행하면  실행이 되는 모습이다. 즉 방금 실행한 코드는 검색 절차중 두번째 단계인 2. 검색어를 입력 부분이다.
실행이 되는 모습이다. 즉 방금 실행한 코드는 검색 절차중 두번째 단계인 2. 검색어를 입력 부분이다. 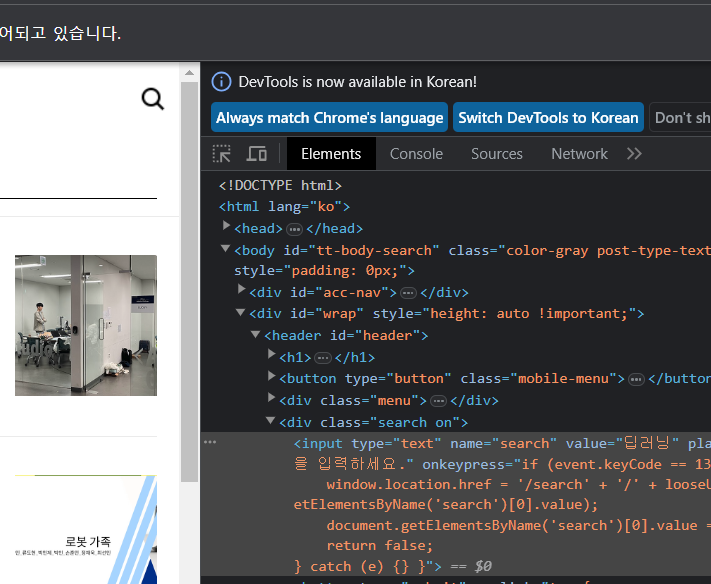
해답은 돋보기를 누르기전의 html 코드와 돋보기를 누르고 나서의 html 코드가 서로 다르다는 것이다. 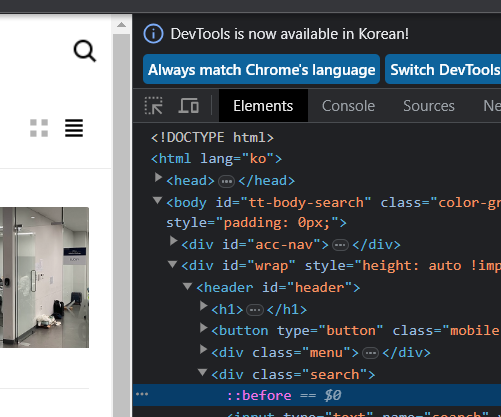
그럴때 selenium.webdriver 에서 ActionChains 모듈을 import 한다. 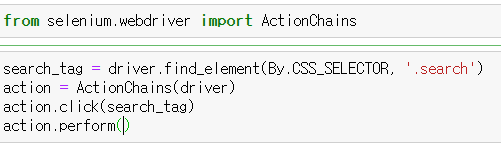 이때 action이라는 변수에 ActionChains(driver)를 놓고 동작을 실시할 변수와 실행시킬 action.perform()을 입력하면
이때 action이라는 변수에 ActionChains(driver)를 놓고 동작을 실시할 변수와 실행시킬 action.perform()을 입력하면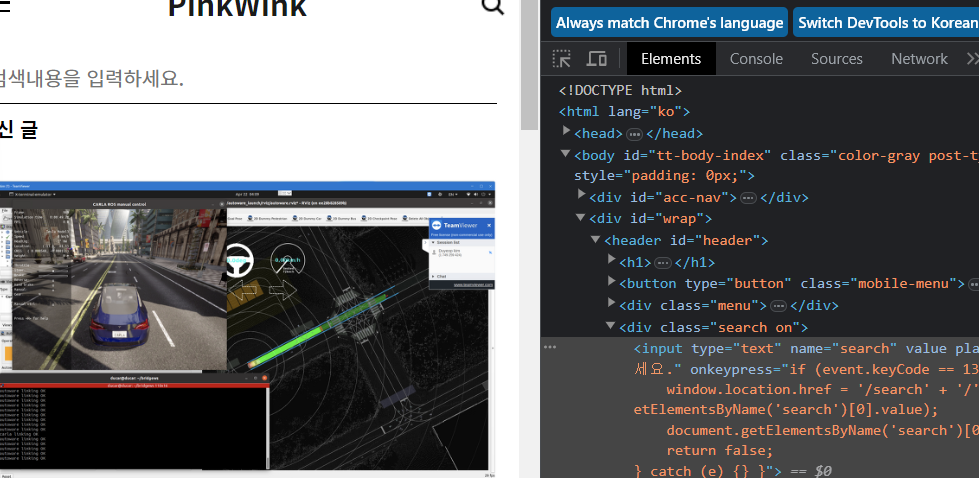 원하는 기능이 실행된다.
원하는 기능이 실행된다. 이제 하나하나 풀어서 다시 연습하는 습관도 가져야겠다. 결론적으로
이제 하나하나 풀어서 다시 연습하는 습관도 가져야겠다. 결론적으로 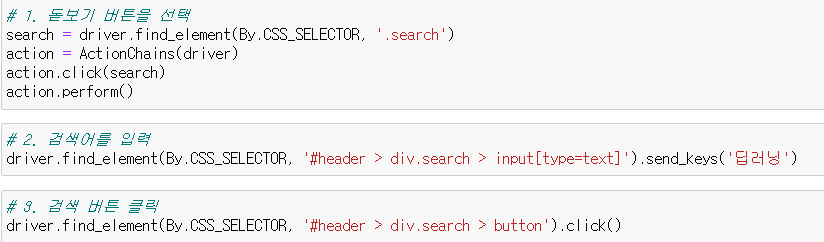 이런 순서대로 동작을 한다.
이런 순서대로 동작을 한다.
♟️selenium + beautifulsoup
driver.page_source 라는 명령어를 통해서 현재 페이지의 html 코드를 불러올 수 있다. 이 명령어를 req 라는 변수에 선언한 다음 soup = BeautifulSoup(req, 'html.parser') 이라고 soup이라는 변수를 또 담아준다. 그러면 webdriver에 열려있는 페이지에 대한 제어가 가능하다.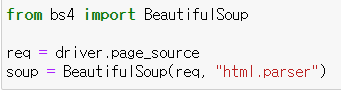
그리고 개발자 도구를 다시 보면 열려있는 포스트에 html 주소중 포스트의 클래스가 post-item 인것을 볼 수 있다. 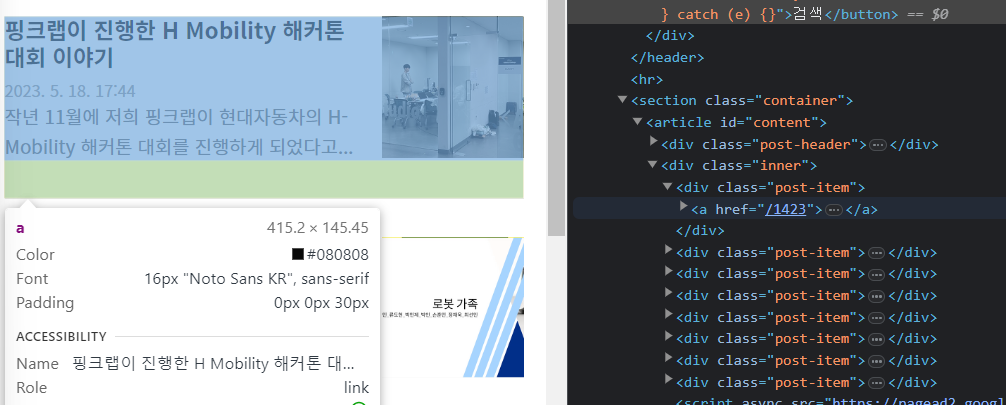
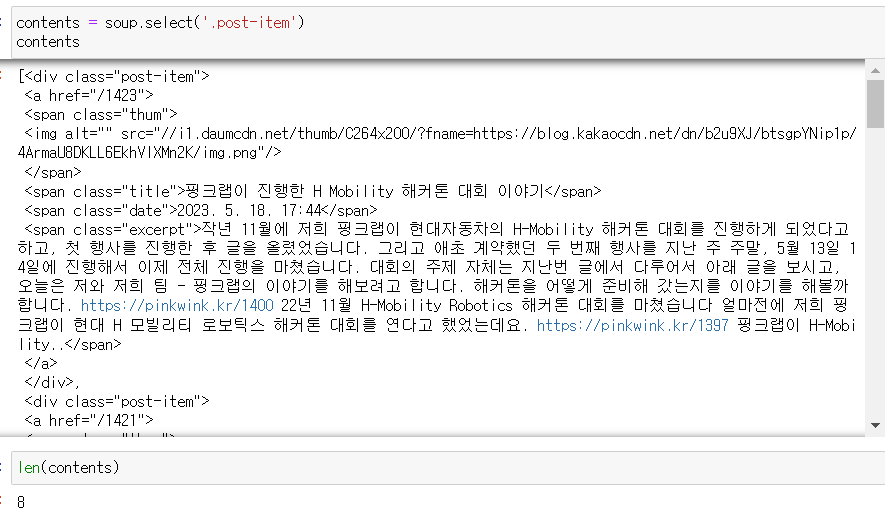 또한 soup.select('.post-item') 를 통해 찾아본 결과, len(contents) = 8, 즉 한 페이지에 8개의 포스트가 올라온다는 것을 알 수 있다.
또한 soup.select('.post-item') 를 통해 찾아본 결과, len(contents) = 8, 즉 한 페이지에 8개의 포스트가 올라온다는 것을 알 수 있다.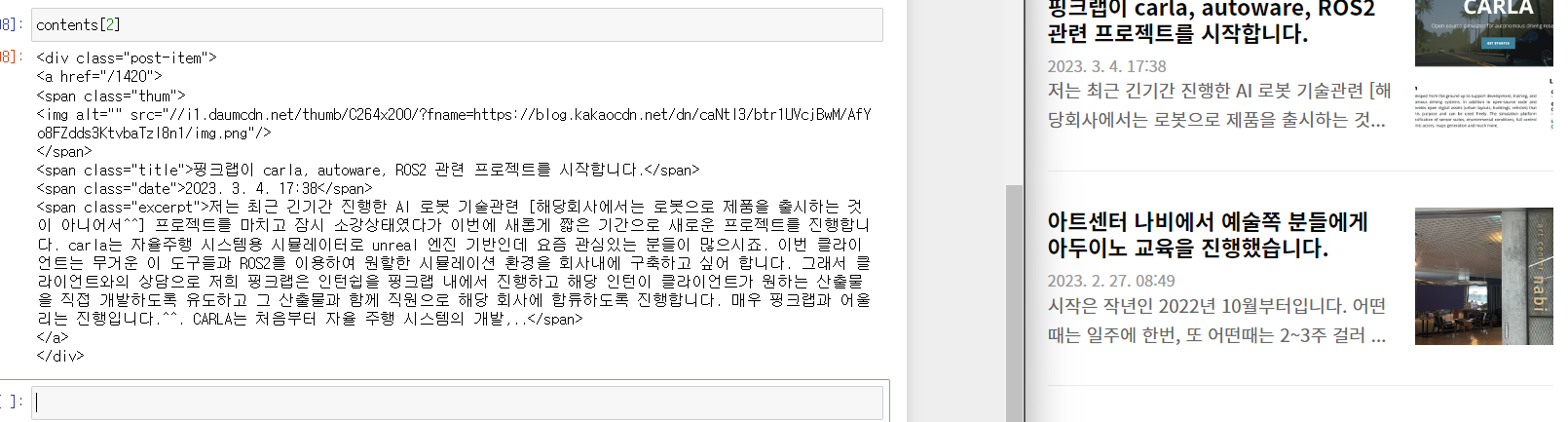 또한 인덱스를 통하여 슬라이싱도 가능하다
또한 인덱스를 통하여 슬라이싱도 가능하다
