
● 오늘의 공부
- 셀프 주유소가 저렴확지 확인
- 셀레니움으로 접근
♟️셀프 주유소가 저렴한지 확인
https://www.opinet.co.kr/searRgSelect.do
에서 원하는 지역을 설정하면 선택한 지역의 주유소들의 정보들이 나온다. 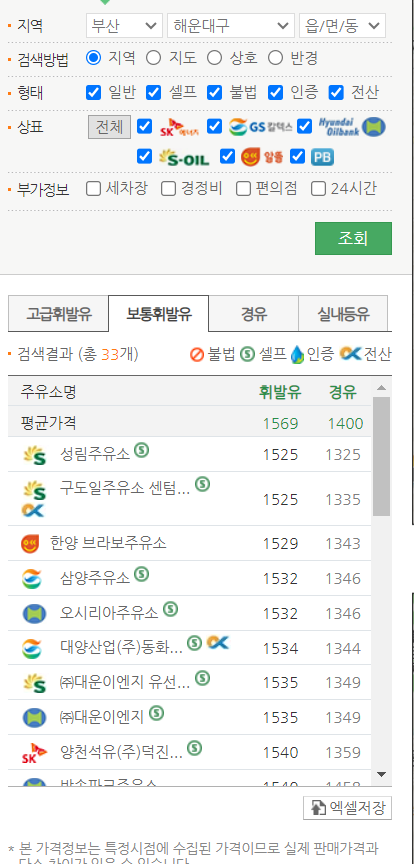 여기서 액셀 저장을 눌러서 다운 받은 액셀을 확인해보면 브랜드, 가격, 셀프 주유 여부, 위치 등이 나온다.
여기서 액셀 저장을 눌러서 다운 받은 액셀을 확인해보면 브랜드, 가격, 셀프 주유 여부, 위치 등이 나온다.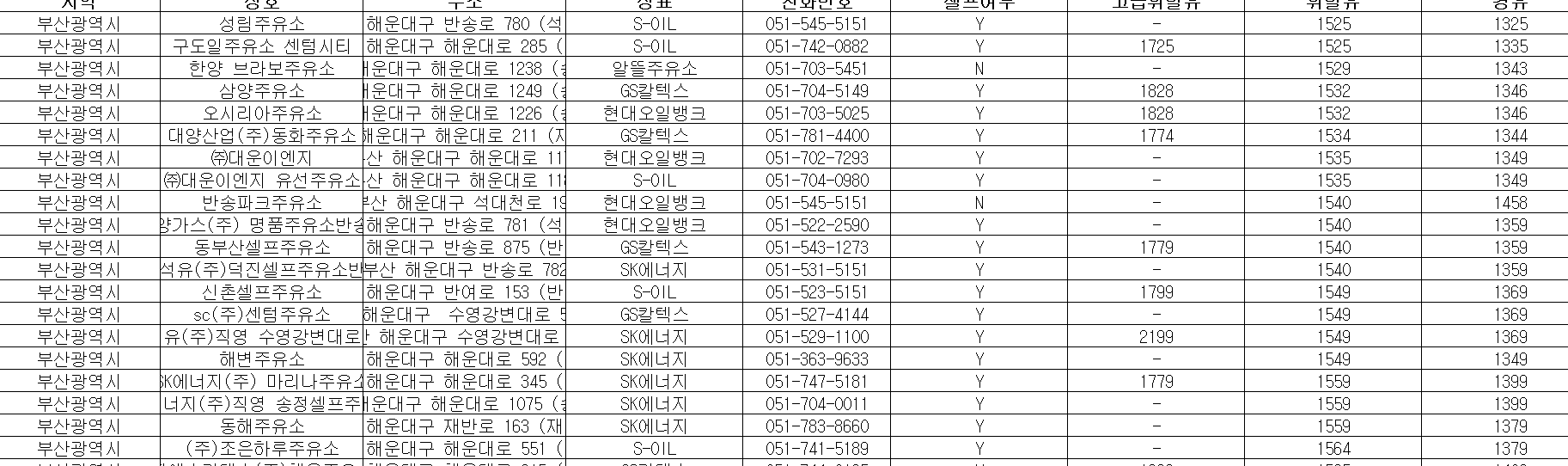
♟️셀레니움으로 접근
♟️페이지 접근
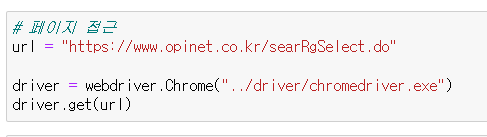 항상 해왔던 방식으로 이번엔 주소를 url이라는 변수에 넣어주고 get()을 써준다. 이때 우리 원하는 주소는 거리별 주유소를 볼 수 있는 그 화면이지만 가끔 메인화면으로 가지면서 팝업창이 열어질때가 있다. 난 그러진 않았지만 혹시나 팝업창이 열어지면서 메인창으로 가지면
항상 해왔던 방식으로 이번엔 주소를 url이라는 변수에 넣어주고 get()을 써준다. 이때 우리 원하는 주소는 거리별 주유소를 볼 수 있는 그 화면이지만 가끔 메인화면으로 가지면서 팝업창이 열어질때가 있다. 난 그러진 않았지만 혹시나 팝업창이 열어지면서 메인창으로 가지면
 이렇게 하면 다시 메인페이지로 돌아오게 된다.
이렇게 하면 다시 메인페이지로 돌아오게 된다.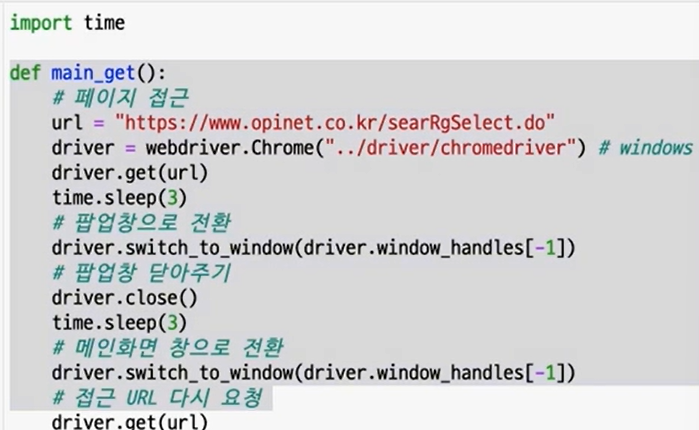 또 위 방식처럼 해줄수 있다. selenium은 driver창을 여는데 처리 시간이 오래 걸린다. 그래서 import time을 이용해서 sleep이라는 모듈로 행동간 3초간의 텀을 주면 편리하게 사용할 수 있다.
또 위 방식처럼 해줄수 있다. selenium은 driver창을 여는데 처리 시간이 오래 걸린다. 그래서 import time을 이용해서 sleep이라는 모듈로 행동간 3초간의 텀을 주면 편리하게 사용할 수 있다.
♟️시 / 도 접근
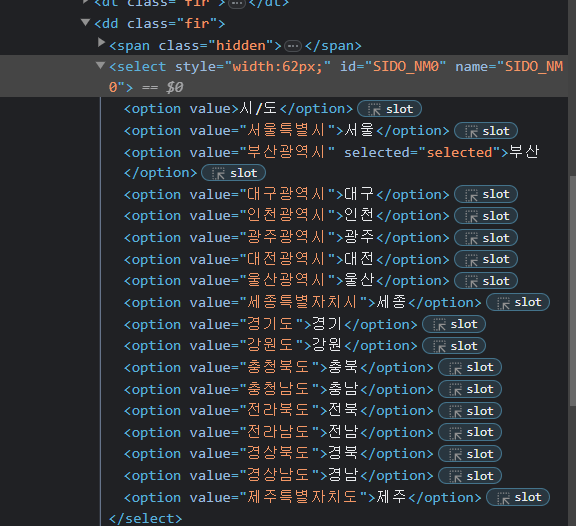 개발자 도구에서 시 부분에 selector를 올리면 ID와 ID 밑에 여러 요소들이 나온다. ID를 복사해서 find_element_by_id()를 이용해 넣어주고 텍스를 이용해 뽑아보면
개발자 도구에서 시 부분에 selector를 올리면 ID와 ID 밑에 여러 요소들이 나온다. ID를 복사해서 find_element_by_id()를 이용해 넣어주고 텍스를 이용해 뽑아보면 이렇게 html 코드가 같이 섞인 모습을 볼 수 있다.
이렇게 html 코드가 같이 섞인 모습을 볼 수 있다.
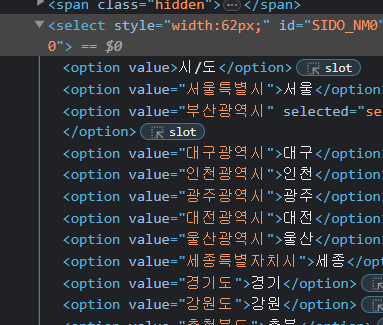 그래서 다시 보면 option 이라는 태그가 붙어있는걸 볼 수 있다. 그래서 다시 find()를 써주는데 우리가 찾는건 하나의 데이터가 아닌 여러개의 데이터니까 find_element에 s를 붙여서 find_elements를 써주어야 한다.
그래서 다시 보면 option 이라는 태그가 붙어있는걸 볼 수 있다. 그래서 다시 find()를 써주는데 우리가 찾는건 하나의 데이터가 아닌 여러개의 데이터니까 find_element에 s를 붙여서 find_elements를 써주어야 한다.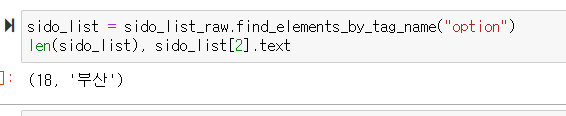
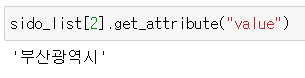 그러면 get_attribute()를 이용해 value 값을 가져오면 풀네임이 나오는것을 볼 수 있다.
그러면 get_attribute()를 이용해 value 값을 가져오면 풀네임이 나오는것을 볼 수 있다.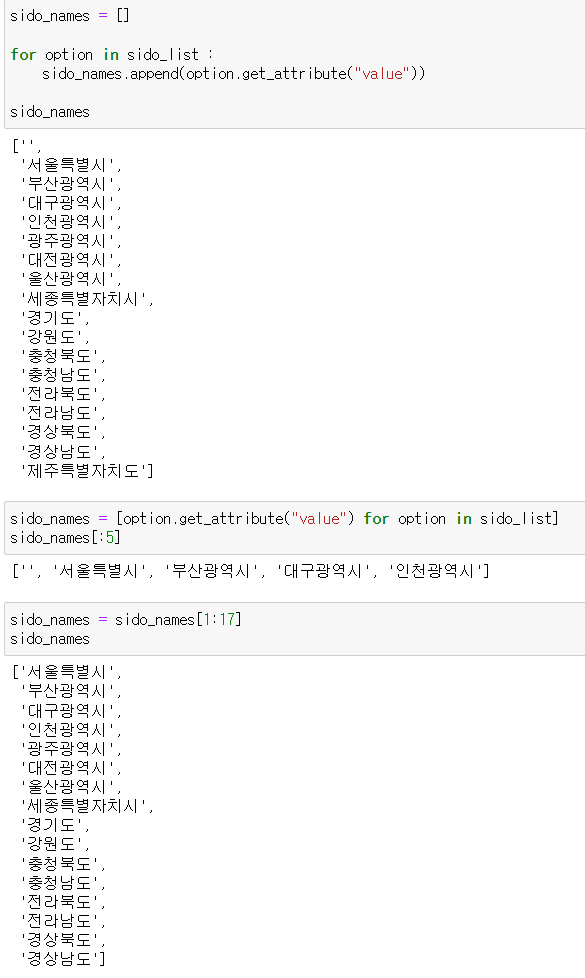
이걸 반복문을 이용해서 모든 지역의 풀네임을 한 리스트에 받아넣을 수 있다. 맨 첫번째 요소인 빈칸은 빼주었다.

 send_keys를 이용해 16번째 인덱스인 제주특별자치도를 넣어주면 제주로 변하는 모습이다.
send_keys를 이용해 16번째 인덱스인 제주특별자치도를 넣어주면 제주로 변하는 모습이다.
♟️구 접근
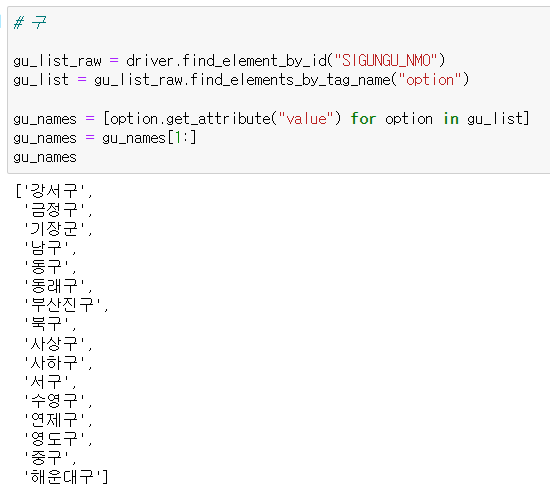
구 접근도 시 / 도 와 완전히 똑같은 방법이다.
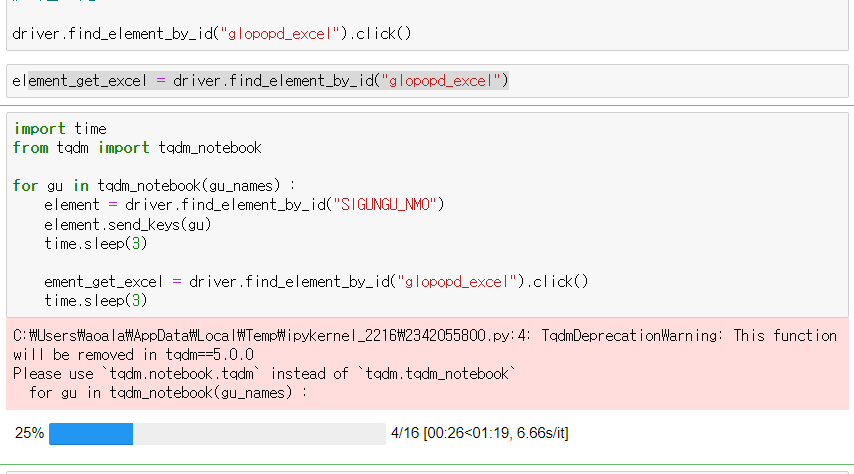 반복문을 이용해서 모든 구의 엑셀들을 다운받아준다.
반복문을 이용해서 모든 구의 엑셀들을 다운받아준다.
♟️데이터 가져오기
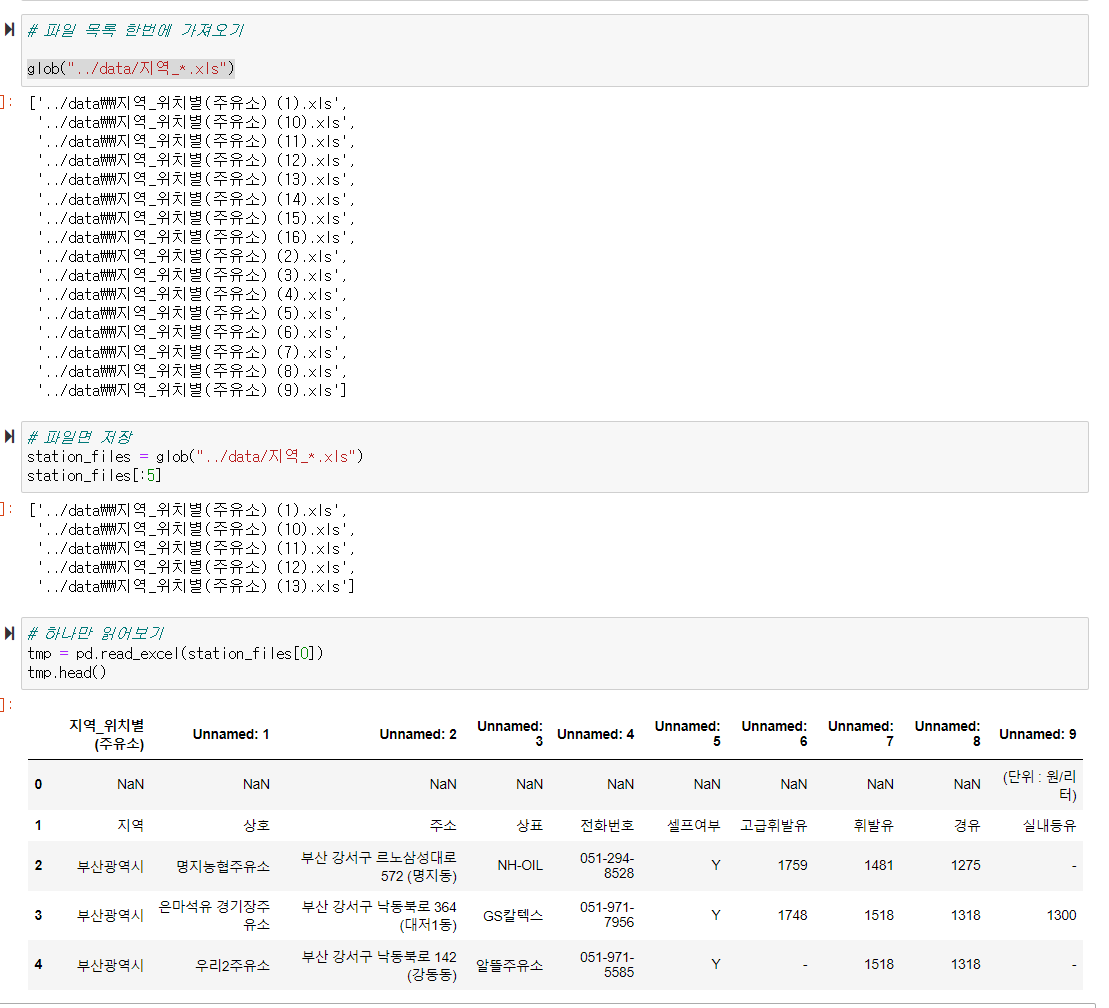
glob 이란 모듈을 이용해서 '지역'이라는 이름이 들어가는 모든 데이터들을 불러온다 => 지역_*
그리고 pandas를 이용해서 데이터를 읽으면 columns도 이상하게 돼있는 상태이고 NaN, 비어있는 부분도 있기 때문에 정리를 해주겠다.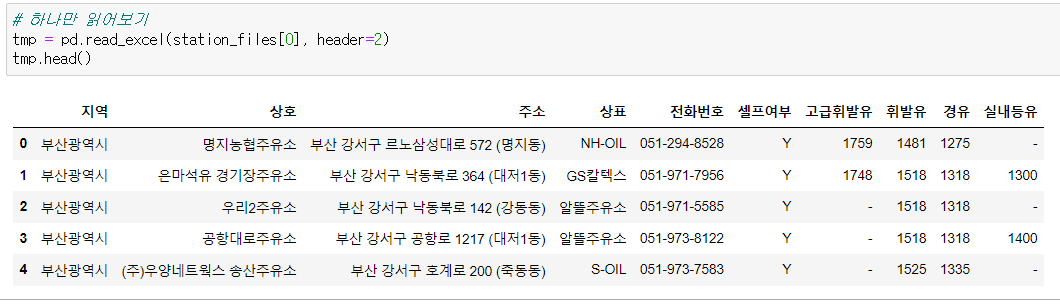 header=2 로 위 두개를 날리니까 column도 원래대로 돌아오고 NaN값도 없어졌다.
header=2 로 위 두개를 날리니까 column도 원래대로 돌아오고 NaN값도 없어졌다.
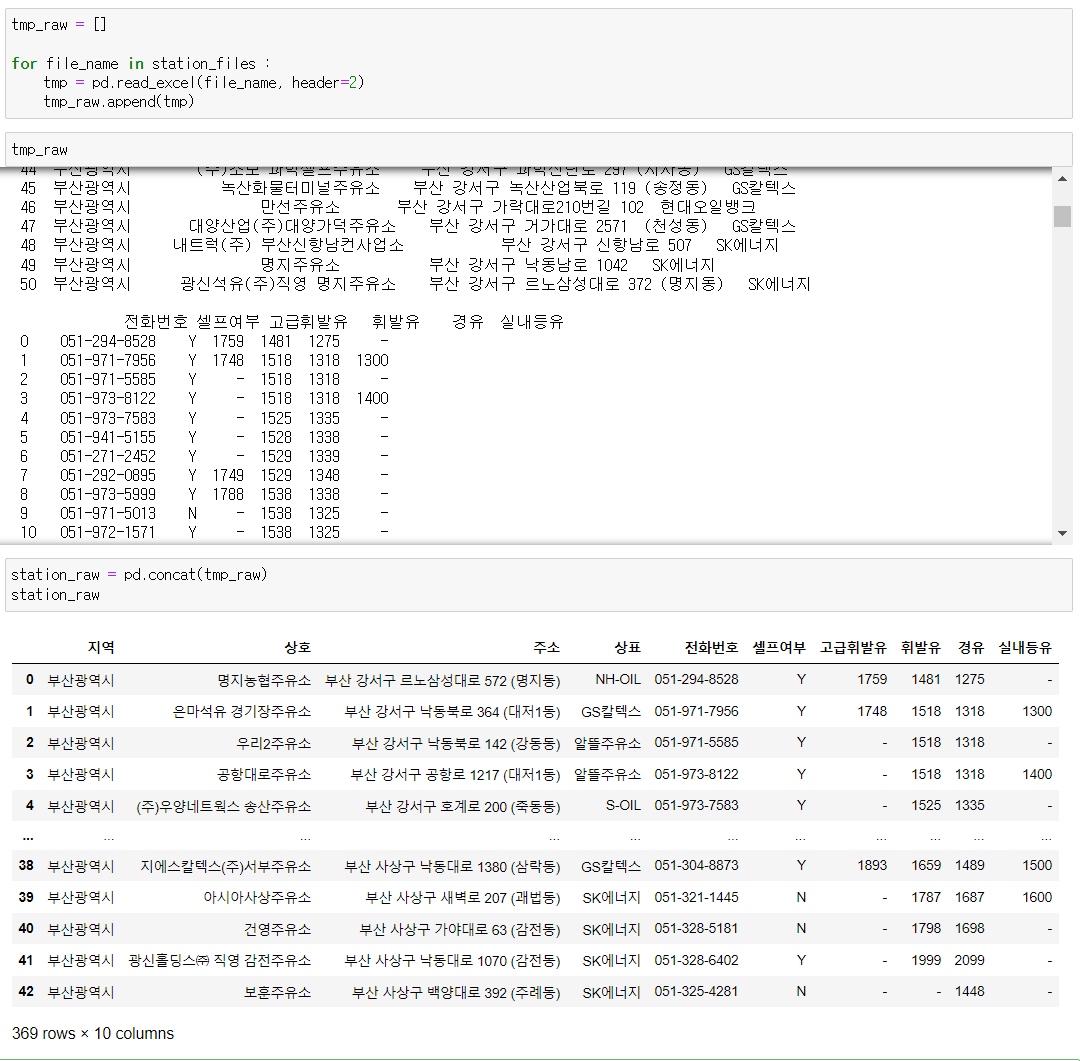 반복문을 이용해서 모든 엑셀들에 대해서 header = 2 를 실행시켜 주고 tmp_raw라는 리스트 안에 넣어주었다. 밑에서 쓰인 pd.concat()은 형식이 동일하고 연달아 이어붙이기만 하면 될 때 쓰는 pandas이다.
반복문을 이용해서 모든 엑셀들에 대해서 header = 2 를 실행시켜 주고 tmp_raw라는 리스트 안에 넣어주었다. 밑에서 쓰인 pd.concat()은 형식이 동일하고 연달아 이어붙이기만 하면 될 때 쓰는 pandas이다.
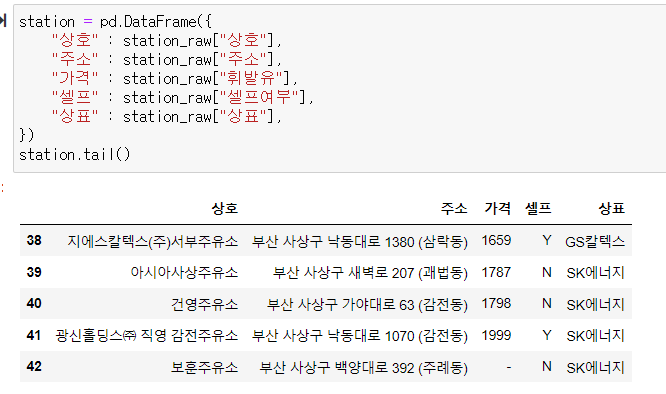 데이터프레임을 만들어준다
데이터프레임을 만들어준다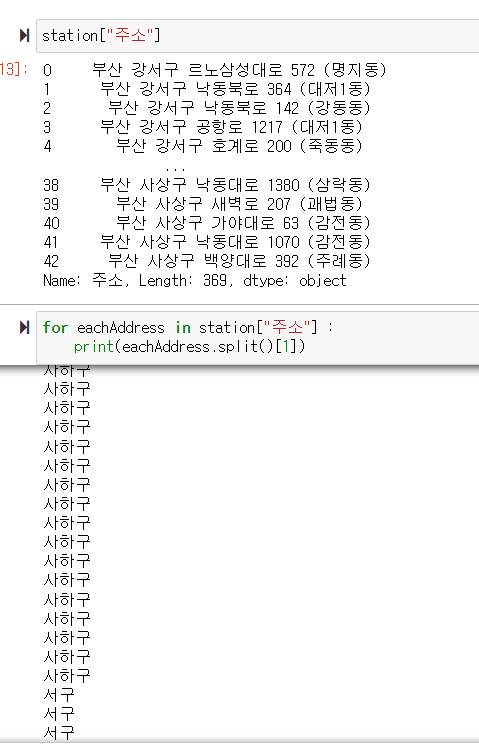
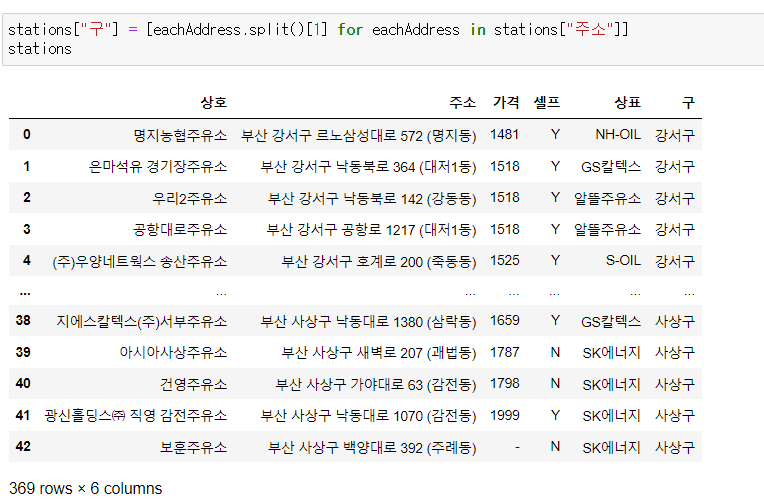 반복문과 split()으로 리스트에 들어있는 글자들을 분리시켜 줄 수 있다. 분리시킨 글자들 중 XX구 부분만 빼서 따로 구 라는 columns를 만들어 준다.
반복문과 split()으로 리스트에 들어있는 글자들을 분리시켜 줄 수 있다. 분리시킨 글자들 중 XX구 부분만 빼서 따로 구 라는 columns를 만들어 준다.
 그리고 아까봤었던 가격이 -인 부분을 마스킹해서 본다.
그리고 아까봤었던 가격이 -인 부분을 마스킹해서 본다.
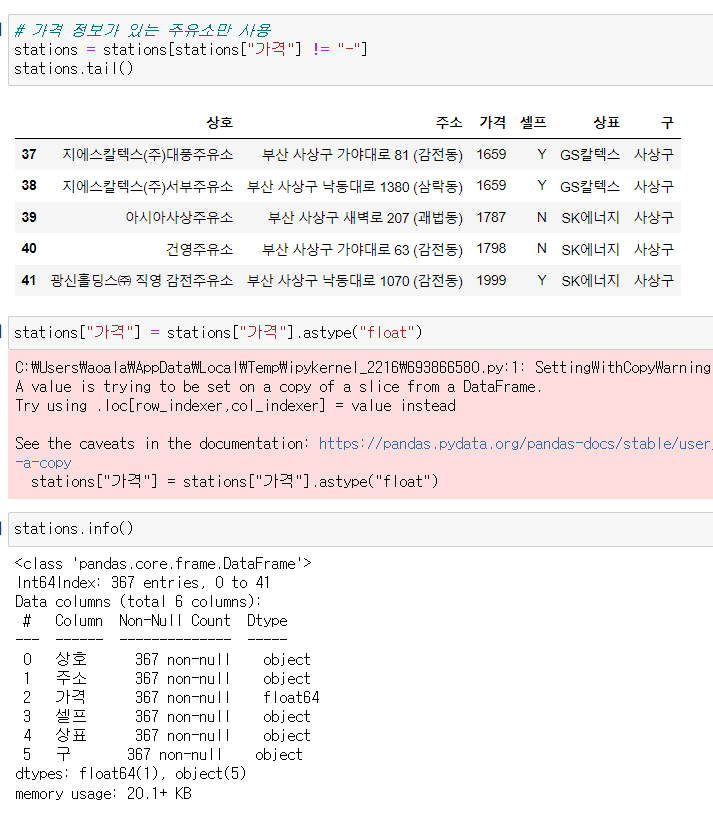 가격 정보 부분이 -가 아닌 부분만 stations라는 변수에 재할당하고나서 stations.info()를 보면 가격부분이 float로 변경되있는거를 볼 수 있다.
가격 정보 부분이 -가 아닌 부분만 stations라는 변수에 재할당하고나서 stations.info()를 보면 가격부분이 float로 변경되있는거를 볼 수 있다.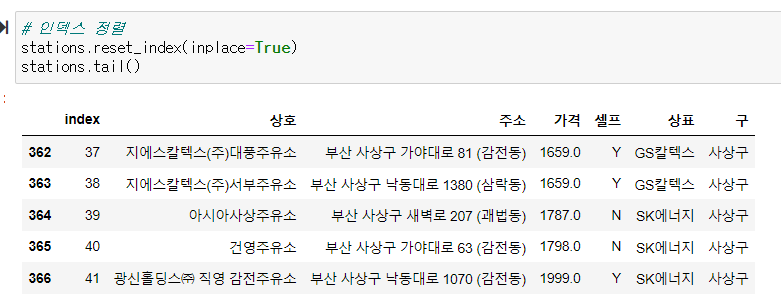 그리고 인덱스를 다시 정렬해준다.
그리고 인덱스를 다시 정렬해준다.
♟️주유 가격 정보 시각화
pandas boxplot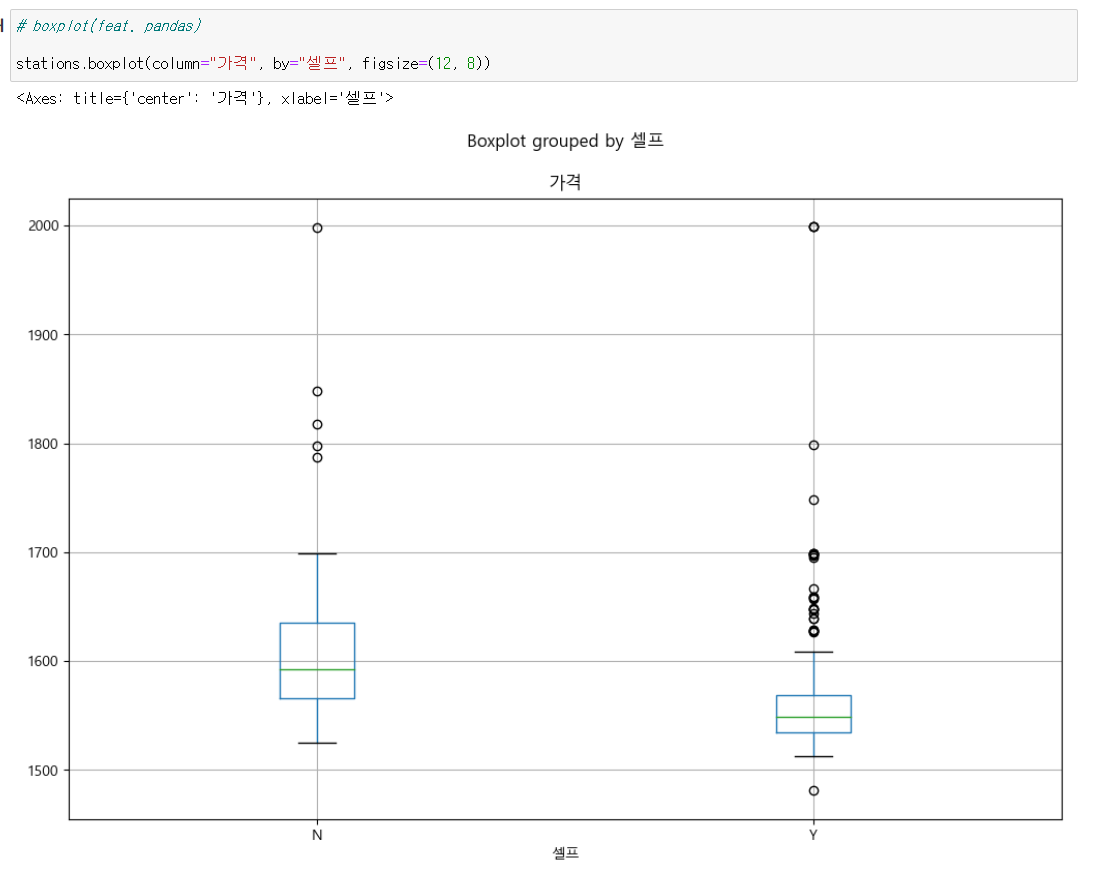
boxplot은 네모 안의 데이터가 총 데이터의 50%를 차지하는거고 50% 데이터의 1.5배를 넘어가면 별도로 표기해준다. 셀프유무와 가격으로만 봤을때 알 수 있는 점은 셀프가 되는 곳이 대체로 저렴하다이다.
seaborn boxplot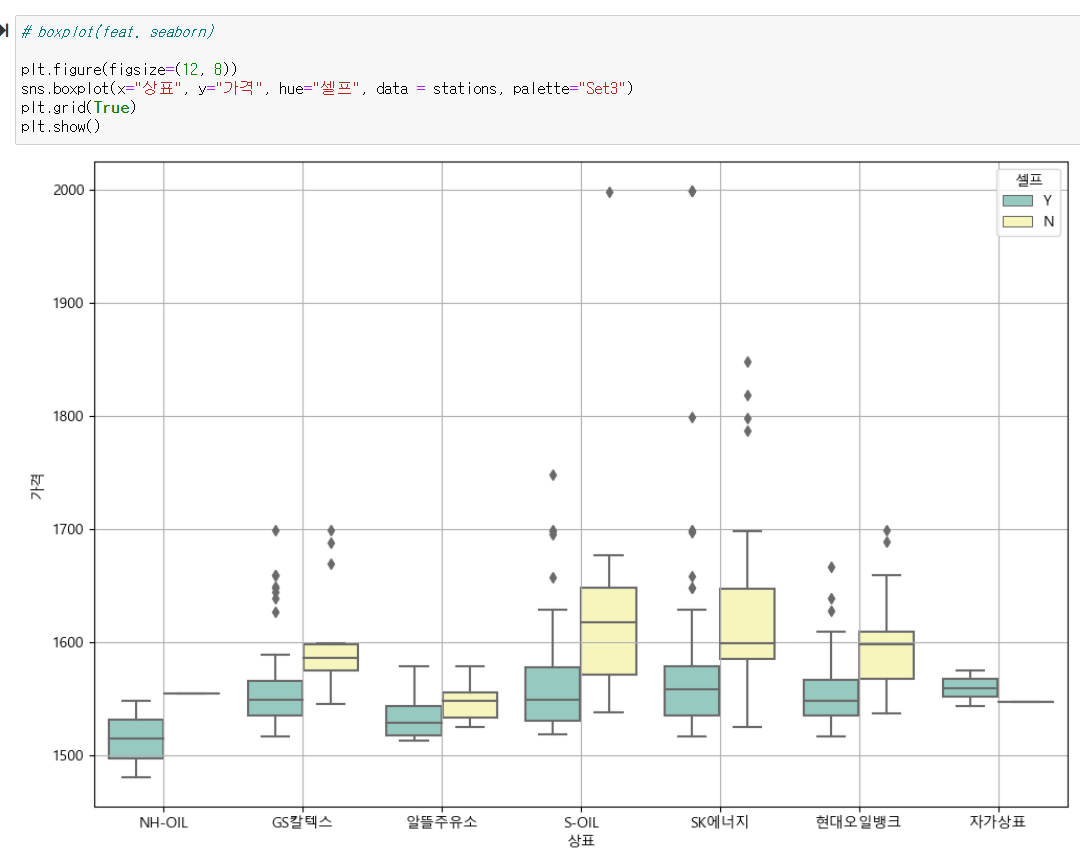 seaborn을 이용한 boxplot 을 이용해서 상표명과 가격별로 알아보았다. 대체적으로 셀프가 되는곳이 저렴하고 비싼 상표를 알 수 있다.
seaborn을 이용한 boxplot 을 이용해서 상표명과 가격별로 알아보았다. 대체적으로 셀프가 되는곳이 저렴하고 비싼 상표를 알 수 있다.
♟️지도 시각화
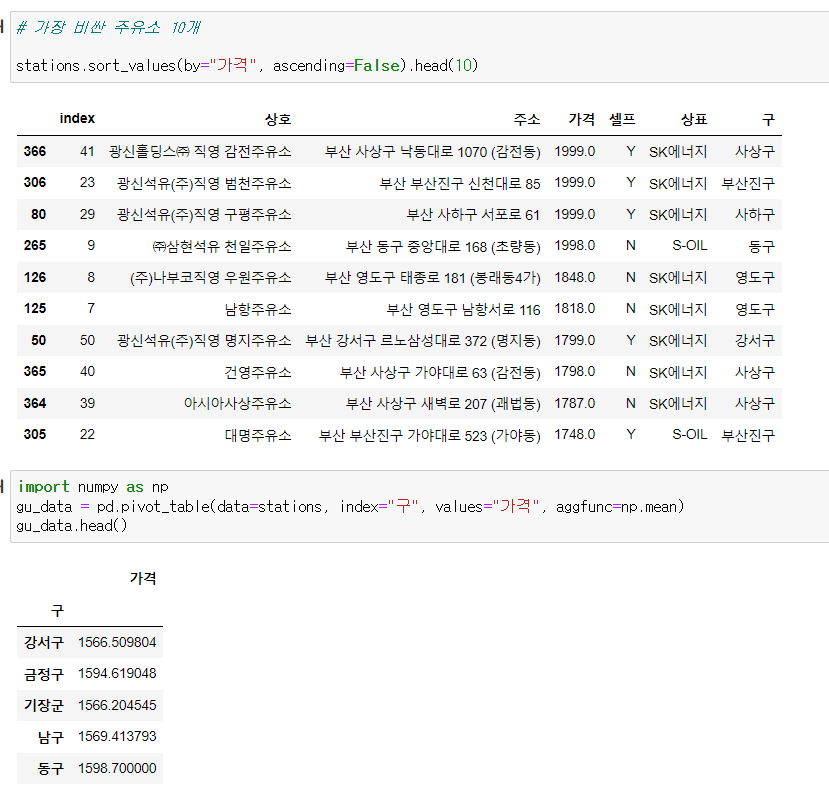 sort_values, ascending=False로 제일 비싼 주유소 10곳을 보았다. 그리고 pivot_table을 이용해 각 구의 주유소의 평균값을 정렬했다.
sort_values, ascending=False로 제일 비싼 주유소 10곳을 보았다. 그리고 pivot_table을 이용해 각 구의 주유소의 평균값을 정렬했다.

그리고 folium을 이용해서 지도를 불러와주고, choropleth를 이용해서 데이터, columns, key_on, 색을 입력해주면 된다.
