
스타벅스와 이디야 매장 분포 분석
스타벅스 : https://www.starbucks.co.kr/store/store_map.do?disp=locale
이디야 : https://ediya.com/contents/find_store.html
데이터 수집을 위한 모듈
- import pandas as pd
- import numpy as np
- import re
- from tqdm import tqdm
- from selenium import webdriver
- from bs4 import BeautifulSoup
- from selenium.webdriver.common.by import By
- from selenium.webdriver.common.keys import Keys
데이터 시각화를 위한 모듈
- import folium
- import googlemaps
- import seaborn as sns
- import matplotlib.pyplot as plt
- from matplotlib import font_manager
f_path = "C:/Windows/Fonts/malgun.ttf"
font_manager.FontProperties(fname=f_path).get_name()
- from matplotlib import rc
rc("font", family = "Malgun Gothic")문제 1).
서울시의 스타벅스 매장의 이름과 주소, 구 이름을 pandas DataFrame 으로 정리
st_url = "https://www.starbucks.co.kr/store/store_map.do?disp=locale"
driver = webdriver.Chrome("driver/chromedriver.exe")
driver.get(url)driver.find_element(By.CSS_SELECTOR, "#container > div > form > fieldset > div > section > article.find_store_cont > article > article:nth-child(4) > div.loca_step1 > div.loca_step1_cont > ul > li:nth-child(1) > a").send_keys(Keys.ENTER)driver.find_element(By.CSS_SELECTOR, "#mCSB_2_container > ul > li:nth-child(1) > a").send_keys(Keys.ENTER)req = driver.page_source
soup = BeautifulSoup(req, "html.parser")
print(soup.prettify())
store = soup.find("div", id = "mCSB_3_container")
stores = store.find_all("li")
stores[0]
stores[0].find("strong").text
stores[0].find("p").text.split()[1]
stores[0].find("p").text
sample = stores[0]
test = []
name = sample.find("strong").text
address = sample.find("p")
gu = sample.find("p").text.split()[1]
test_test = {
"브랜드" : "스타벅스",
"가게명" : name,
"주소" : address,
"구" : gu
}
test.append(test_test)
test
df = pd.DataFrame(test)
df 주소 중 전화번호는 모든 데이터에 똑같이 들어가있어서 뺴줘도 상관없을듯 하다.
주소 중 전화번호는 모든 데이터에 똑같이 들어가있어서 뺴줘도 상관없을듯 하다.
starbucks = []
for list in stores :
name = list.find("strong").text
address = list.find("p").text
address = list.find("p").text.replace("1522-3232", "")
gu = list.find("p").text.split()[1]
starbuck_dic = {
"가게명" : name,
"주소" : address,
"구" : gu
}
starbucks.append(starbuck_dic)
starbucks_df = pd.DataFrame(starbucks)
starbucks_df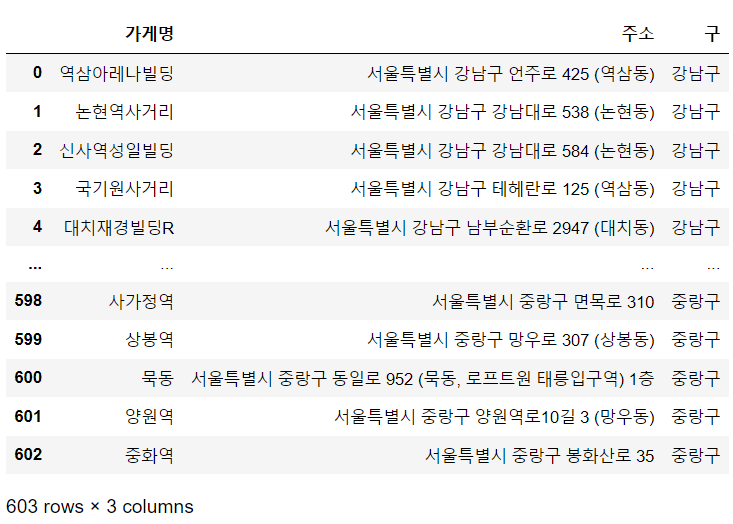
서울에는 총 603개의 스타벅스 매장이 있다 (현시간기준 : 2023.06.09)
문제 2).
서울시의 이디야 매장의 이름과 주소, 구 이름을 pandas DataFrame 으로 정리

 이디야는 스타벅스와는 다르게 주소나 매장명을 입력하는 식으로 검색을 한다. 그러면 아까 스타벅스 주소를 쓸 때 뽑았던 "gu" 데이터를 이용해서 반복문을 실행해서 입력시켜 줄것이다.
이디야는 스타벅스와는 다르게 주소나 매장명을 입력하는 식으로 검색을 한다. 그러면 아까 스타벅스 주소를 쓸 때 뽑았던 "gu" 데이터를 이용해서 반복문을 실행해서 입력시켜 줄것이다.
gu_list = sorted(starbucks_df["구"].unique())
gu_list
driver.find_element(By.CSS_SELECTOR, "#contentWrap > div.contents > div > div.store_search_pop > ul > li:nth-child(2) > a").click()driver.find_element(By.CSS_SELECTOR, "#keyword")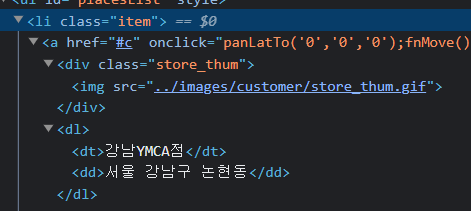 개발자 도구로 보면 dl 라는 태그 안에 매장 정보들이 있는것을 볼 수 있다.
개발자 도구로 보면 dl 라는 태그 안에 매장 정보들이 있는것을 볼 수 있다. 그리고 구별 정보는 ul 이라는 태그가 붙어있는 것을 볼 수 있다.
그리고 구별 정보는 ul 이라는 태그가 붙어있는 것을 볼 수 있다.
ed_list =[]
for gu in gu_list:
driver.find_element_by_css_selector("#keyword")
driver.find_element(By.CSS_SELECTOR, "#keyword").clear()
driver.find_element(By.CSS_SELECTOR, "#keyword").send_keys(f"서울 {gu}")
driver.find_element(By.CSS_SELECTOR, "#keyword_div > form > button").click()
req_ed = driver.page_source
soup = BeautifulSoup(req_ed, "html.parser")
ed_ul = soup.find("ul",id ="placesList")
ed_dl = ed_ul.find_all("dl")
for dl in ed_dl:
name = dl.find("dt").text
address = dl.find("dd").text
gu = address.split()[1]
ed_dic ={
"가계명": name,
"주소" : address,
"구" : gu,
"브랜드" : "이디야"
}
ed_list.append(ed_dic)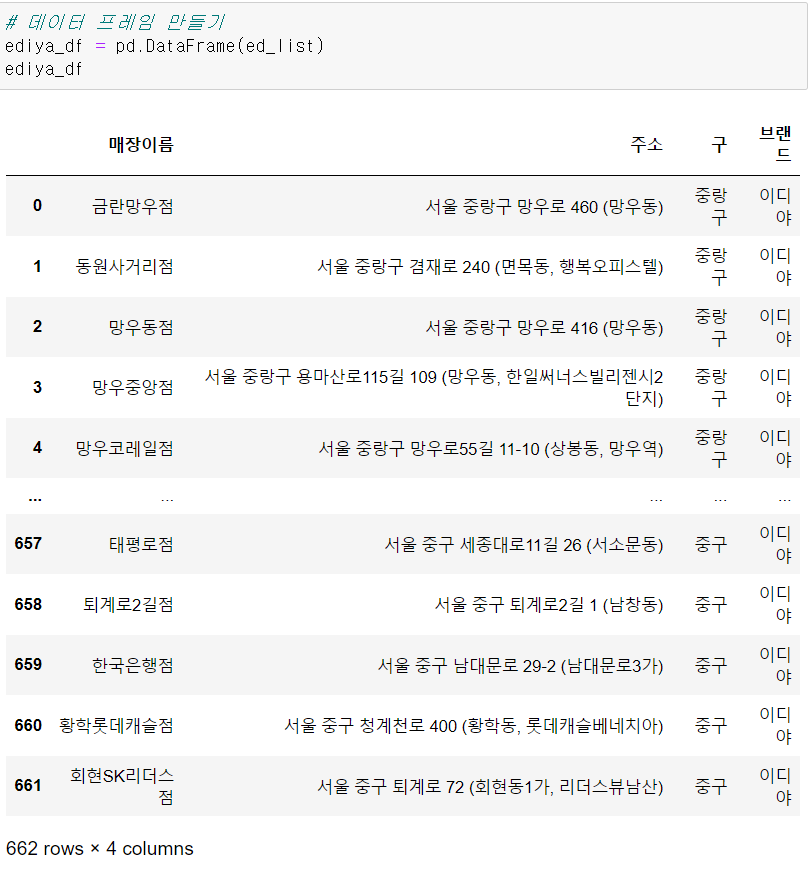 총 662개의 이디야 매장이 있다.
총 662개의 이디야 매장이 있다.
문제 3).
문제 1과 2의 결과를 가지고 이디야 커피가 스타벅스 커피 매장 근처에 있는지 분석
coffee_df = pd.concat([starbucks_df, ediya_df])
coffee_df
coffee_df.reset_index(drop=True, inplace=True)
-깔끔-
import googlemaps
gmaps_key = "AIzaSyBQwxyOv4RtPw4ciz5QhFgGRGhLgNbG3iM"
gmaps = googlemaps.Client(key=gmaps_key)
gmaps
coffee_df["위도"] = np.nan
coffee_df["경도"] = np.nan
coffee_df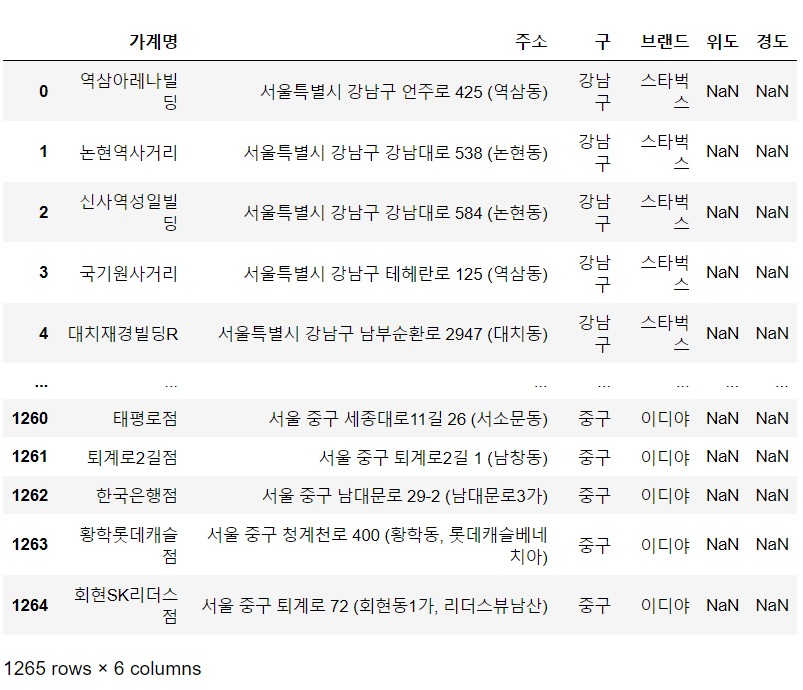 위도와 경도를 googlemap에 검색해서 찾아줄 것이다.
위도와 경도를 googlemap에 검색해서 찾아줄 것이다.
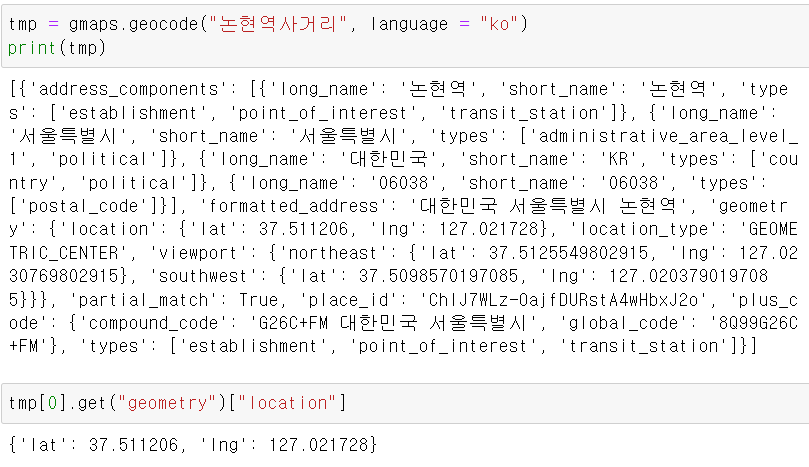 반복문을 돌려서 위도와 경도를 빼줄것이다.
반복문을 돌려서 위도와 경도를 빼줄것이다.
 미리 사전테스트를 하고 나서
미리 사전테스트를 하고 나서
for idx, row in coffee_df.iterrows():
row["주소"]
adr = gmaps.geocode(row["주소"], language="ko")
lat = tmp[0].get("geometry")["location"]["lat"]
lng = tmp[0].get("geometry")["location"]["lng"]
coffee_df.loc[idx, "위도"] = lat
coffee_df.loc[idx, "경도"] = lng
mapping = folium.Map(location = [37.5666612, 126.9783785],zoom_start=11)
# 서울시청 위도 경도
for idx, rows in coffee_df.iterrows():
# 브랜드별 분류
if rows["브랜드"] =="스타벅스":
mk_color="black",
elif rows["브랜드"] == "이디야":
mk_color = "blue"
# 마커 추가
folium.Marker(
location=[rows["위도"],rows["경도"]],
popup=rows["주소"],
tooltip = rows["가계명"],
icon =folium.Icon(
icon ="coffee",
prefix="fa",
color = mk_color)
).add_to(mapping)
mappingplt.figure(figsize=(15, 4))
sns.countplot(data=coffee_df, x = "구", hue = "브랜드")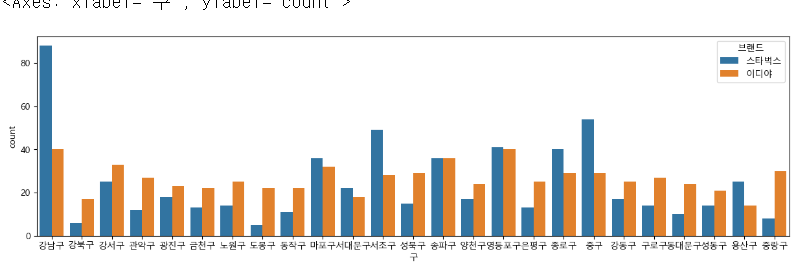
coffee_df_cnt = coffee_df.groupby(["구", "브랜드"]).count()
coffee_df_cnt = coffee_df_cnt.reset_index()
del coffee_df_cnt["주소"]
del coffee_df_cnt["위도"]
del coffee_df_cnt["경도"]
coffee_df_cnt.head()
coffee_df_cnt.columns = ["구", "브랜드", "매장수"]
coffee_df_cnt.head()
coffee_df_cnt = coffee_df_cnt.pivot(index="구",columns="브랜드",values="매장수")
coffee_df_cnt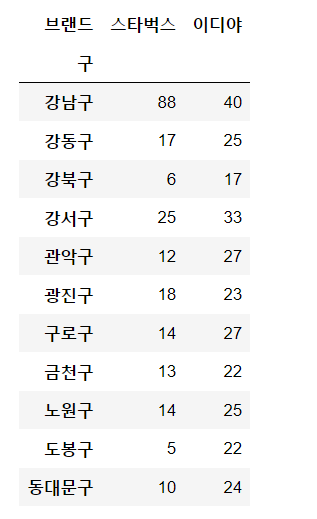
coffee_df_cnt["매장수비교"]=coffee_df_cnt["스타벅스"]>coffee_df_cnt["이디야"]
coffee_df_cnt.head(10)
coffee_df_cnt["매장수비교"] = coffee_df_cnt["매장수비교"].astype(float)
coffee_df_cnt=coffee_df_cnt.reset_index()
coffee_df_cnt.head(10)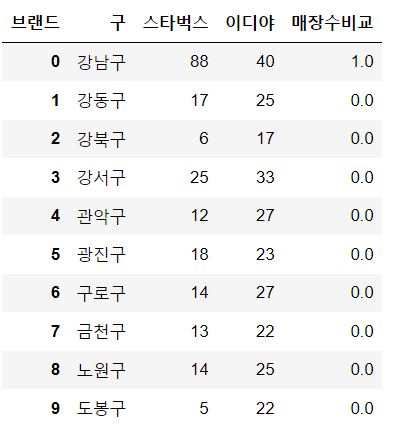
m=folium.Map(location = loc, zoom_start=10) #서울시청
folium.Choropleth(
geo_data=geo_str,
data=coffee_df_cnt,
columns=["구","매장수비교"],
key_on = "feature.properties.name", #색상별로 밀집 현황 확인
fill_color="BuGn", #블루 그린
fill_opacity = 0.7 #투명도
).add_to(m)
m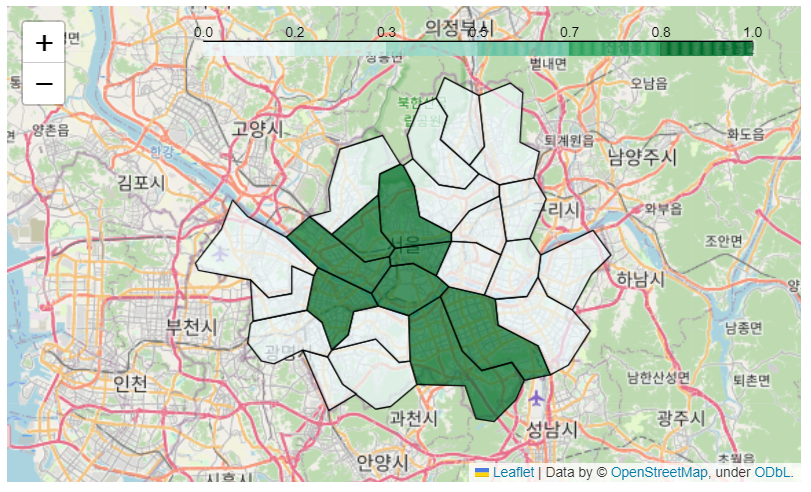
결론
두 데이터를 놓고 봤을때 이디야 매장이 꼭 스타벅스 매장 옆에 있다고는 볼 수 없을거 같다. 서울 중심에 스타벅스가 밀집되어 있는거는 맞지만 서울 외곽으로 나가면 이디야 매장이 많은 곳도 충분히 보인다. 위 countplot에서 보면 강남, 마포, 서초, 영등포, 종로, 중구, 용산을 제외한 나머지 지역에는 이디야 매장의 수도 많고 밀집도도 훨씬 높다. 강남구에 스타벅스가 많은거는 많지만 전체 경향과 비교해 강남구에는 과도하게 스타벅스가 있다고도 볼 수 있다. 반면 이디야는 전 지역에 평균적인 분포를 이루고 있다. 즉 결론, 꼭 이디야가 스타벅스 옆에 있는거만은 아니고 주관적인 입장은 스타벅스가 회사가 몰려있는 큰 구 들을 독점을 하려고 해서 나타난 모습인거 같다.
추가 결론
혼자서 복습할려고 코드를 보다가 위에서 주소를 하나 잘못 찍은것을 발견했다. 위도와 경도를 반복문을 통해서 얻을때, 변수 하나를 잘못 넣어서 모든 데이터가 하나의 위도와 경도를 가지게 되었다. 즉, 경향이나 그래프로 표시할려고 하면 결과가 하나만 나오는 이유가 있었다. 나는 어디서 잘못된지 몰라서 컴퓨터가 안 좋아서 많은 데이터를 못 받쳐주는가하고 했었는데 내 실수였다.
