
문제 1
- 수집한 데이터들을 pandas 데이터 프레임으로 정리해주세요.
- 부가 정보 데이터는 셀프 여부와 마찬가지로 Y 또는 N 으로 저장해주세요
- 최종적으로 데이터 프레임에 들어가야할 컬럼은 총 14개로 아래와 같습니다
- 주유소명, 주소, 브랜드, 휘발유 가격, 경유 가격,
- 셀프 여부, 세차장 여부, 충전소 여부, 경정비 여부, 편의점 여부, 24시간 운영 여부, 구, 위도, 경도
유가정보 분석
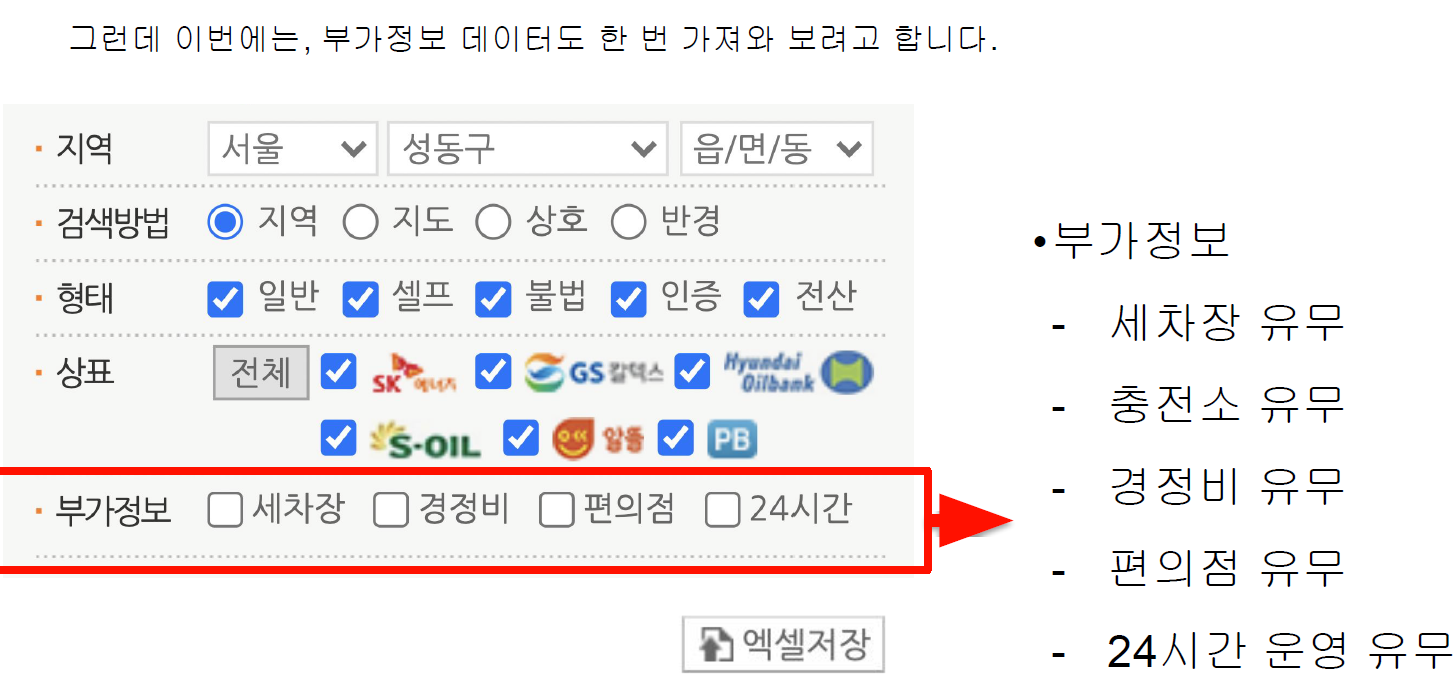
기름값에 추가로 부가정보 불러오기
from selenium import webdriver
from bs4 import BeautifulSoup
import pandas as pd
import numpy as np
import seaborn as sns
import time
from selenium.webdriver.common.by import By
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import font_manager
f_path = "C:/Windows/Fonts/malgun.ttf"
font_manager.FontProperties(fname=f_path).get_name()
from matplotlib import rc
rc("font", family = "Malgun Gothic")국내 주유가격을 알아보는 사이트 : https://www.opinet.co.kr/searRgSelect.do
driver = webdriver.Chrome('./driver/chromedriver.exe')
driver.get(url)나같은 경우는 파일을 다른 폴더 안에 넣었기 때문에 .을 하나만 넣어서 상위폴더로 이동한 후 webdriver를 실행
서울 지역의 주유가격을 알아보기 위해서 서울 지역의 XPATH를 복사후 click()을 넣어주면 자동으로 서울 지역이 선택이 된다.
si_name = driver.find_element(By.XPATH, '//*[@id="SIDO_NM0"]/option[2]')
si_name.click()
첫번째 get_attribute()로 가져온 값은 빈칸이다. 그러면 두번째 인덱스부터 받아온 다음 구 리스트에 다시 넣을것이다.
gu_names = []
for i in range(len(gu_list)) :
gu_names.append(gu_list[i].get_attribute('value'))
gu_names = gu_names[1:]
gu_names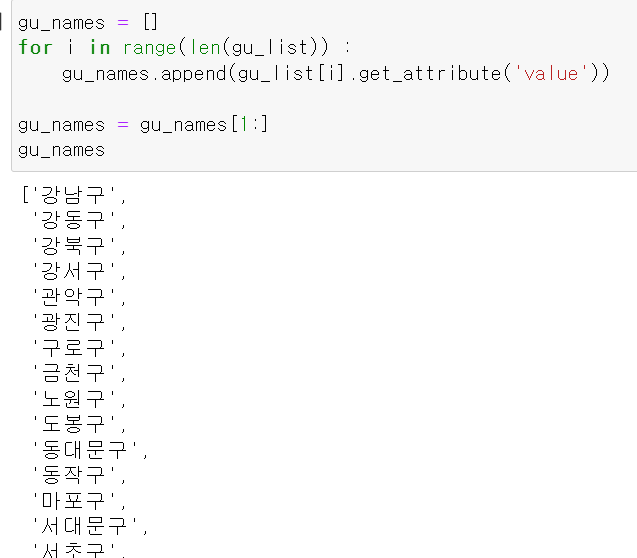
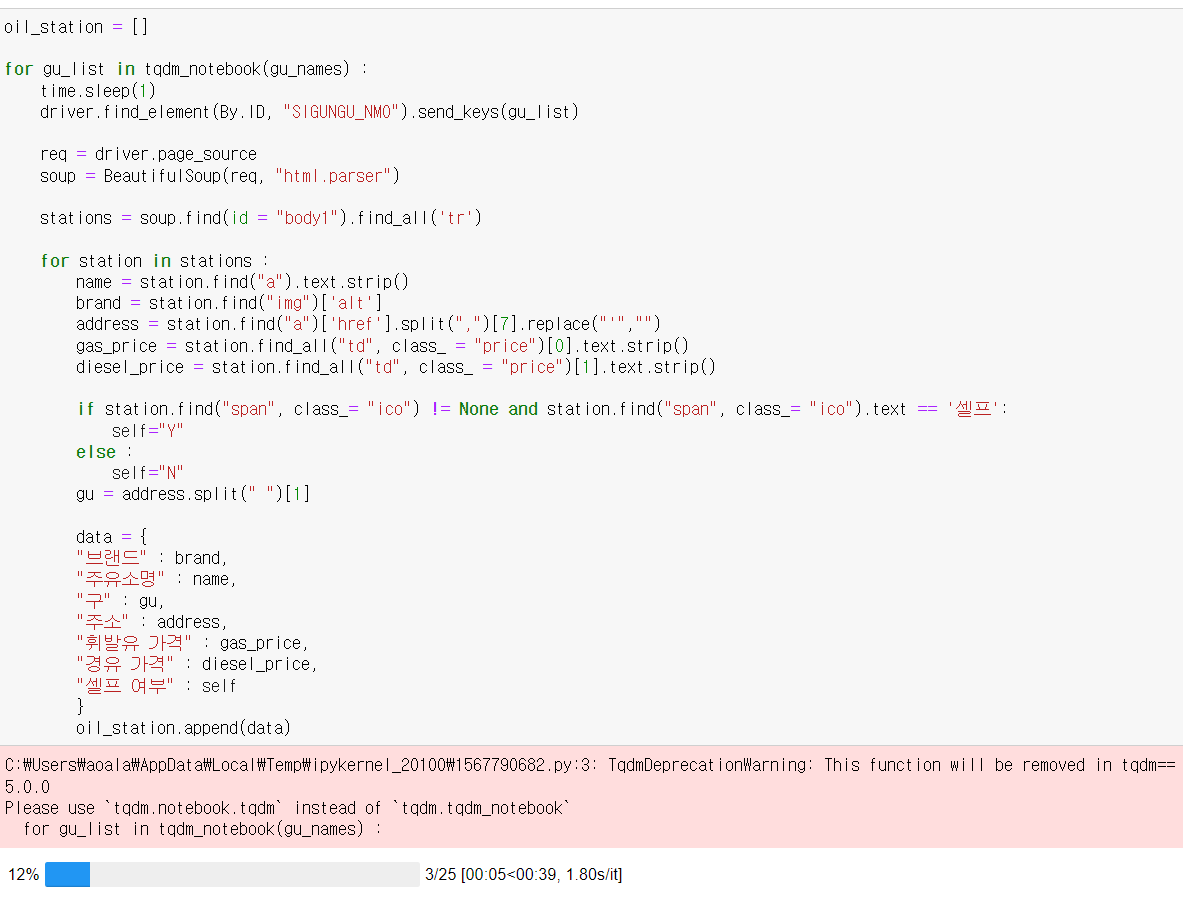
tqdm을 이용해 진행정도를 알수 있다
시군구 선택 부분에 위에서 추출한 구 이름을 넣고 주유소들의 정보를 불러온다. 각 ID와 class에 맞춰서 정보를 추출해준다. 셀프여부 같은 경우는 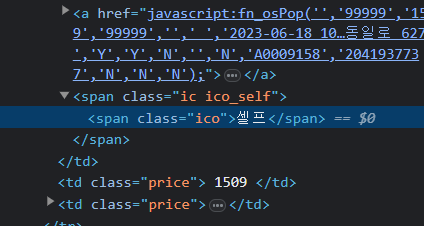 class = ico의 text 값이 셀프라고 되있는 부분이 있어서 바로 추가해주었다.
class = ico의 text 값이 셀프라고 되있는 부분이 있어서 바로 추가해주었다.
주소를 추출할때 뭔가 잘못한건지 계속 현재시간으로 추출이 되서 그냥 리스트 역순으로 슬라이싱해서 다시 해주었다. ㅜㅜ
oil_station = []
for gu_list in tqdm_notebook(gu_names) :
time.sleep(1)
driver.find_element(By.ID, "SIGUNGU_NM0").send_keys(gu_list)
req = driver.page_source
soup = BeautifulSoup(req, "html.parser")
stations = soup.find(id = "body1").find_all('tr')
for station in stations :
name = station.find("a").text.strip()
brand = station.find("img")['alt']
address = station.find("a")['href'].split(",")[-11].replace("'","")
gas_price = station.find_all("td", class_ = "price")[0].text.strip()
diesel_price = station.find_all("td", class_ = "price")[1].text.strip()
if station.find("span", class_= "ico") != None and station.find("span", class_= "ico").text == '셀프':
self="Y"
else :
self="N"
gu = address.split(" ")[1]
data = {
"브랜드" : brand,
"주유소명" : name,
"구" : gu,
"주소" : address,
"휘발유 가격" : gas_price,
"경유 가격" : diesel_price,
"셀프 여부" : self
}
oil_station.append(data)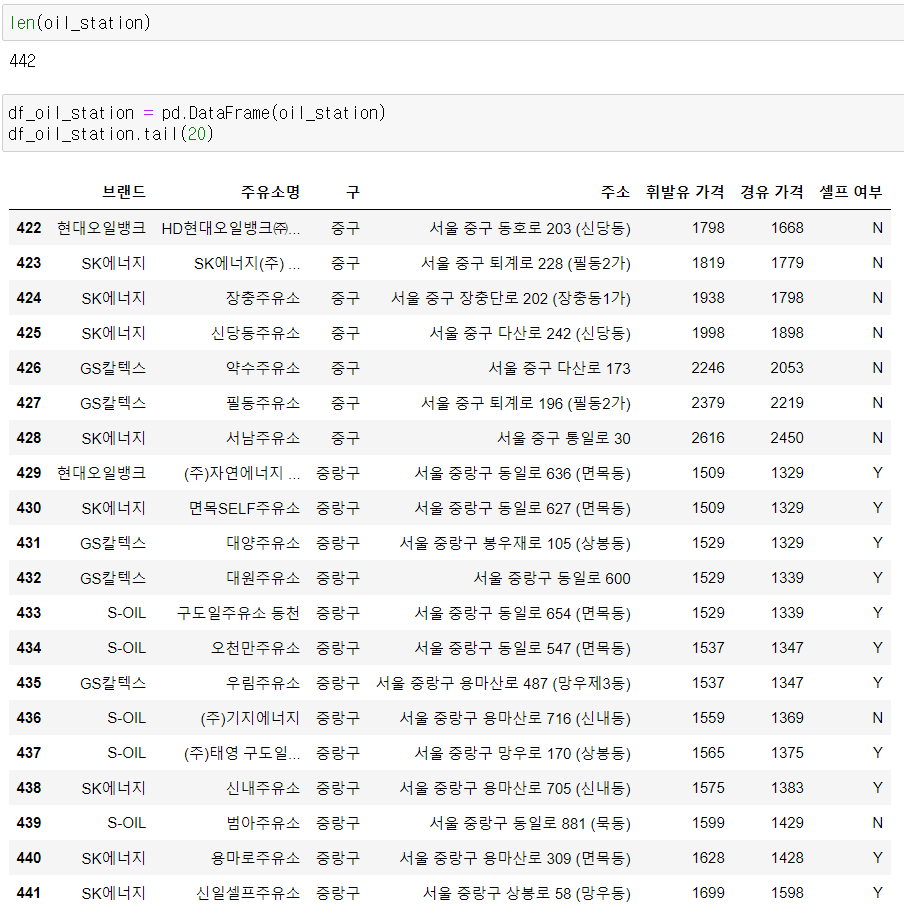 현재 서울에는 총 442개의 주유소가 있다.
현재 서울에는 총 442개의 주유소가 있다.
car_wash = []
driver.find_element(By.XPATH,'//*[@id="CWSH_YN"]').click()
for gu_name in tqdm_notebook(gu_names):
time.sleep(0.5)
driver.find_element(By.ID,"SIGUNGU_NM0").send_keys(gu_name)
req = driver.page_source
soup = BeautifulSoup(req, "html.parser")
stations = soup.select('#body1 > tr')
for station in stations :
address = station.find("a")['href'].split(",")[-11].replace("'","")
wash = 'Y'
car_wash_dic = {
"주소" : address,
"세차장 여부" : wash
}
car_wash.append(car_wash_dic)위 코드를 통해서 세차장 정보를 넣을 리스트를 만든다. 계획하고 있는 것은 세차장 부분을 클릭하도록 하고 클릭되어 나온 세차장들의 주소와 나온 세차장들에 한 해 'Yes' 의 코드인 'Y'를 넣는다. 그리고 원래 데이터 프레임과 merge 코드를 이용해 합치면 비어있는 칸들에 NaN값이 들어가있을건데 NaN 값을 fillna()를 통해 'N'으로 채워주면 세차장이 있는지 없는지가 나올것이다. 해보기전까지 모르는거긴 하지만 해보겠다.
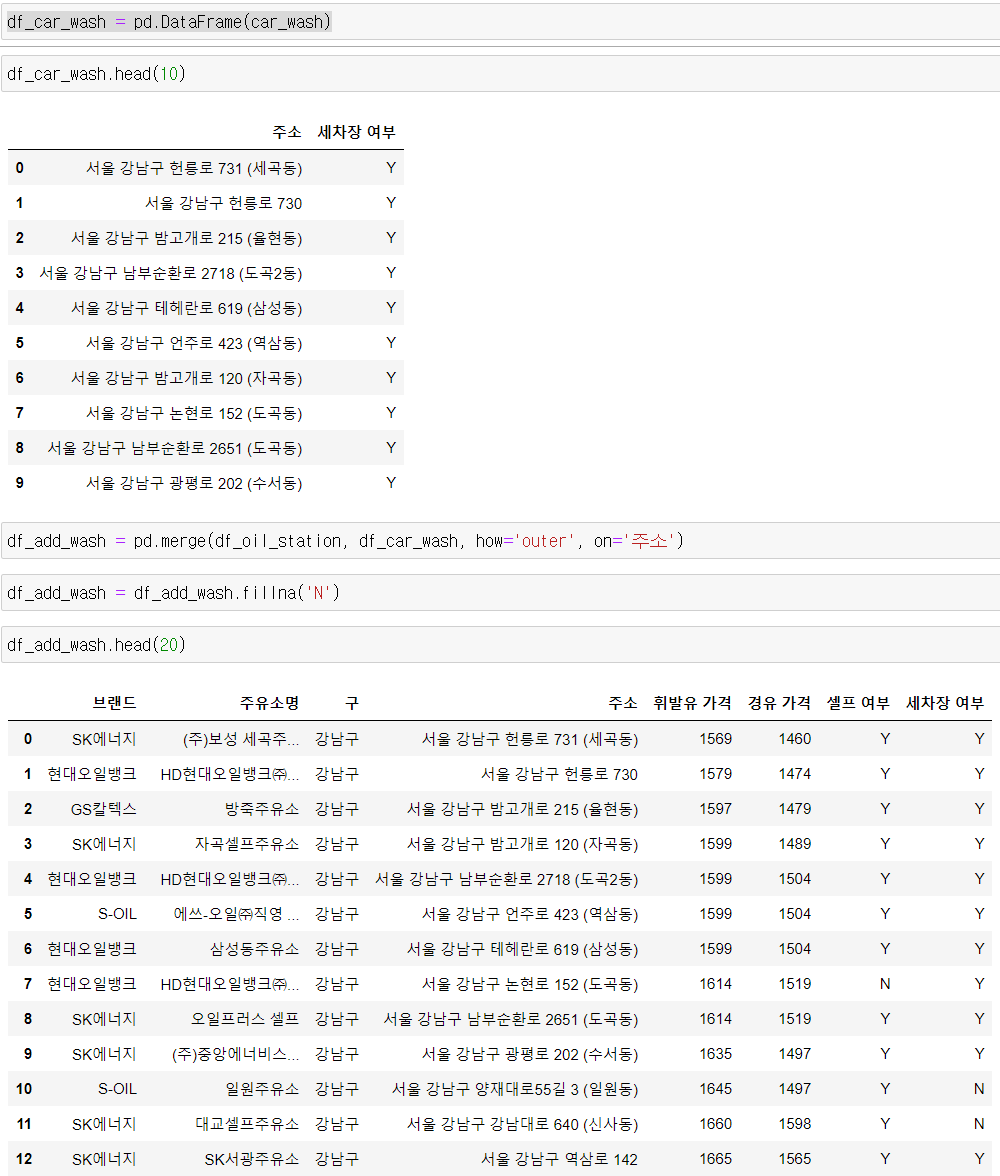 굿!
굿!
같은 방법으로 경정비와 편의점, 24시간을 다 해보겠다
fix_list = []
driver.find_element(By.XPATH,'//*[@id="MAINT_YN"]').click()
for gu_list in tqdm_notebook(gu_names):
time.sleep(1)
driver.find_element(By.ID,"SIGUNGU_NM0").send_keys(gu_list)
req = driver.page_source
soup = BeautifulSoup(req, "html.parser")
res = soup.select('#body1 > tr')
for station in res :
address = station.find("a")['href'].split(",")[-11].replace("'","")
fix = 'Y'
fix_dic = {
"주소" : address,
"경정비 여부" : fix
}
fix_list.append(fix_dic)
df_fix = pd.DataFrame(fix_list)
df_fix.head()
df_fix = pd.DataFrame(fix_list)
df_add_fix = pd.merge(df_add_wash, df_fix, how='outer', on='주소')
df_add_fix = df_add_fix.fillna('N')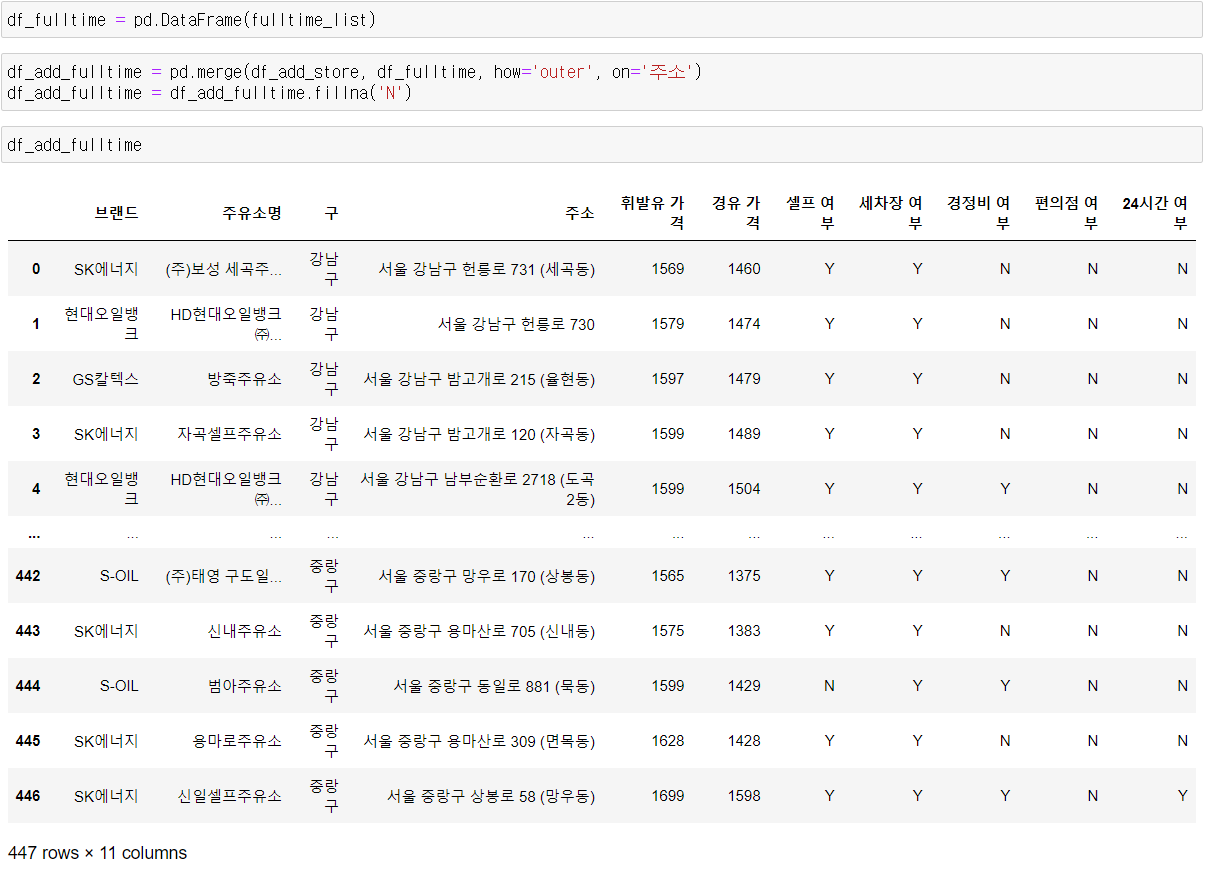 같은 방법으로 24시간 여부까지 추가를 했다.
같은 방법으로 24시간 여부까지 추가를 했다.
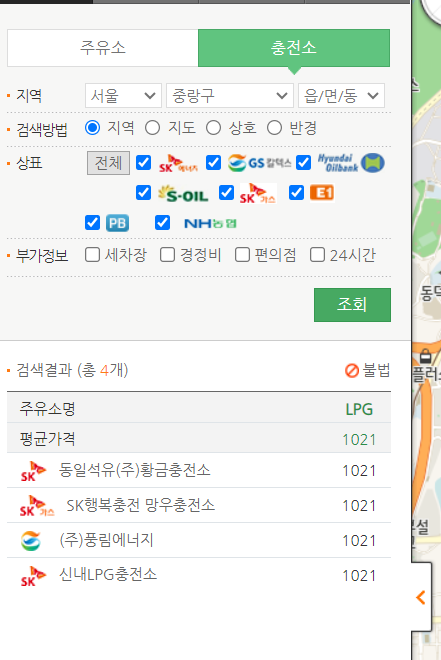 충전소는 따로 충전소를 클릭한다음 서울을 send_keys()하고 다시 반복문을 돌려줄 것이다.
충전소는 따로 충전소를 클릭한다음 서울을 send_keys()하고 다시 반복문을 돌려줄 것이다.
driver.find_element(By.XPATH,'//*[@id="LPG_BTN"]').click()
driver.find_element(By.ID,"SIDO_NM0").send_keys("서울")
lpg_list = []
for gu_list in tqdm_notebook(gu_names):
time.sleep(0.5)
driver.find_element(By.ID,"SIGUNGU_NM0").send_keys(gu_list)
req = driver.page_source
soup = BeautifulSoup(req, "html.parser")
res = soup.select('#body1 > tr')
for station in res :
address = station.find("a")['href'].split(",")[-11].replace("'","")
lpg = "Y"
lpg_dic = {
"주소" : address,
"충전소 여부" : lpg
}
lpg_list.append(lpg_dic)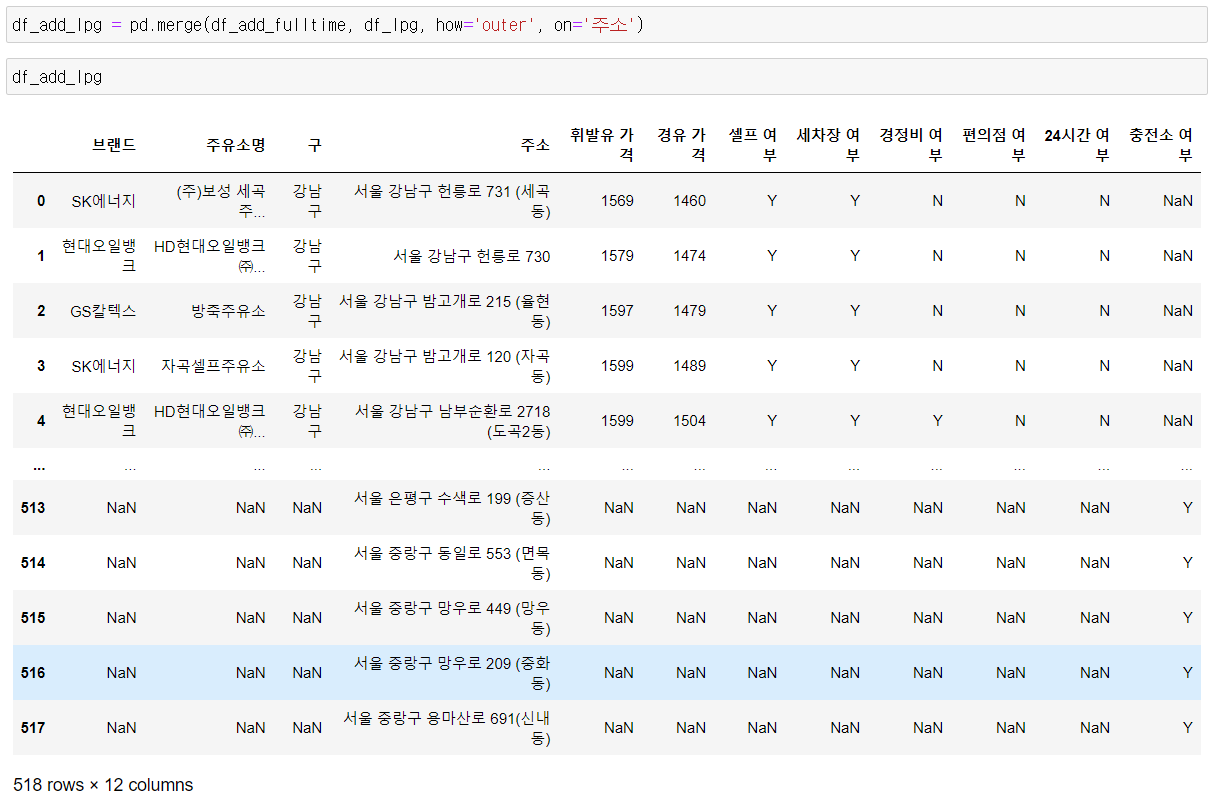 index 갯수가 많이 늘어난걸 확인했다. 아마 독단적으로 LPG 충전소만 있는거 같다. 보면 브랜드, 주유소명, 구에 NaN 값이 들어가 있다. 그러면 다시 위에서 추가했었던 데이터와 주소가 같은 부분을 골라서 추가해 주겠다.
index 갯수가 많이 늘어난걸 확인했다. 아마 독단적으로 LPG 충전소만 있는거 같다. 보면 브랜드, 주유소명, 구에 NaN 값이 들어가 있다. 그러면 다시 위에서 추가했었던 데이터와 주소가 같은 부분을 골라서 추가해 주겠다.
df_lpg = pd.DataFrame(lpg_list)
df_lpg = pd.merge(df_oil_station, df_lpg, on='주소')
df_lpg
del df_lpg ["브랜드"]
del df_lpg ["주유소명"]
del df_lpg ["구"]
del df_lpg ["휘발유 가격"]
del df_lpg ["경유 가격"]
del df_lpg ["셀프 여부"]
df_lpg
df_add_lpg = pd.merge(df_add_fulltime, df_lpg, how='outer', on='주소')
df_add_lpg = df_add_lpg.fillna('N')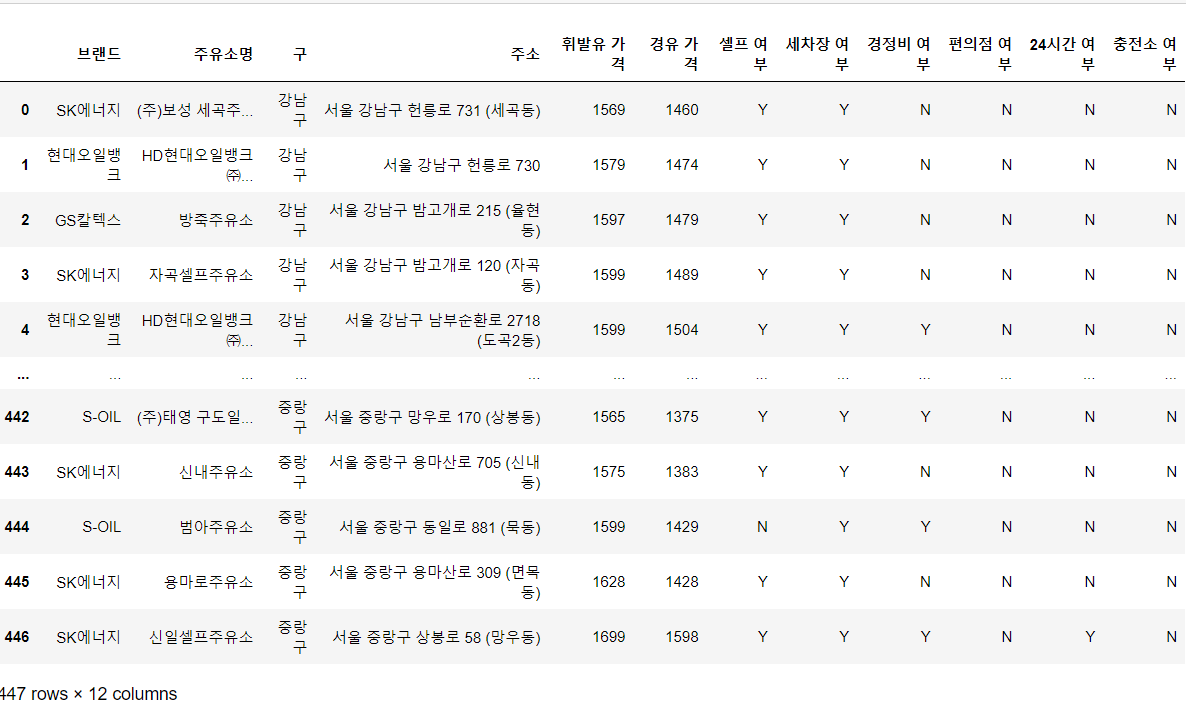
LPG에서 시간을 제일 많이 뺏겼던거 같다. 생각보다 서울에는 LPG와 주유소를 같이 하는 곳이 없다. 생각보다가 아니라 한군데 있었다. LPG만 독단적으로 하는 곳이 있어서 그 데이터를 빼고 다시 추가하려고 했는데 머리로는 이해했지만 코드를 어떻게 잡아야할지 가늠이 안됐다. 처음에 columns을 안 빼고 추가하니까 처음처럼 계속 index가 500몇개까지 들어가서 한참을 해맸다.
import googlemaps
gmaps_key = "AIzaSyBQwxyOv4RtPw4ciz5QhFgGRGhLgNbG3iM"
gmaps = googlemaps.Client(key=gmaps_key)
for idx, rows in df_add_lpg.iterrows():
tmp = gmaps.geocode(df_add_lpg['주소'][idx], language="ko")
lat = tmp[0].get("geometry")["location"]["lat"]
lng = tmp[0].get("geometry")["location"]["lng"]
df_add_lpg.loc[idx, '위도'] = lat
df_add_lpg.loc[idx, '경도'] = lng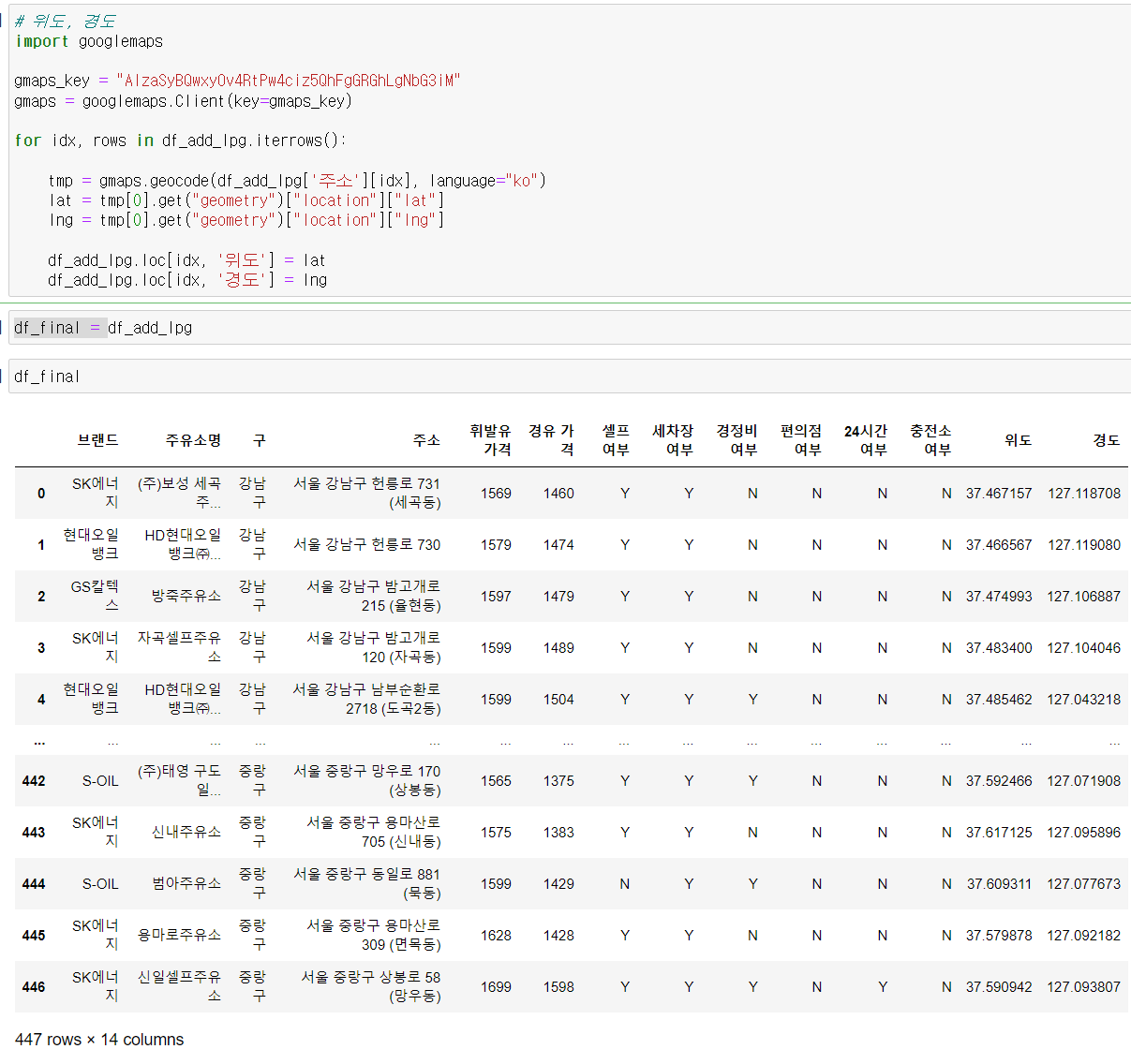 굿!
굿!
사실 원래 하던 방법대로 딕셔너리를 만들어서 추가했는데 갑자기 index가 30개가 늘어나서 iterrow 함수를 썻다.
 휘발유와 경유 가격의 type도 깔끔하게 숫자형으로 바꿔주었다.
휘발유와 경유 가격의 type도 깔끔하게 숫자형으로 바꿔주었다.
문제 2)
- 그리고 다시 한 번, 휘발유와 경유 가격이 셀프 주유소에서 정말 저렴한지 여러분의 분석 결과를 작성해주세요.
- 분석한 결과를 여러분의 jupyter notebook에 markdown 으로 설명해주시면 됩니다.
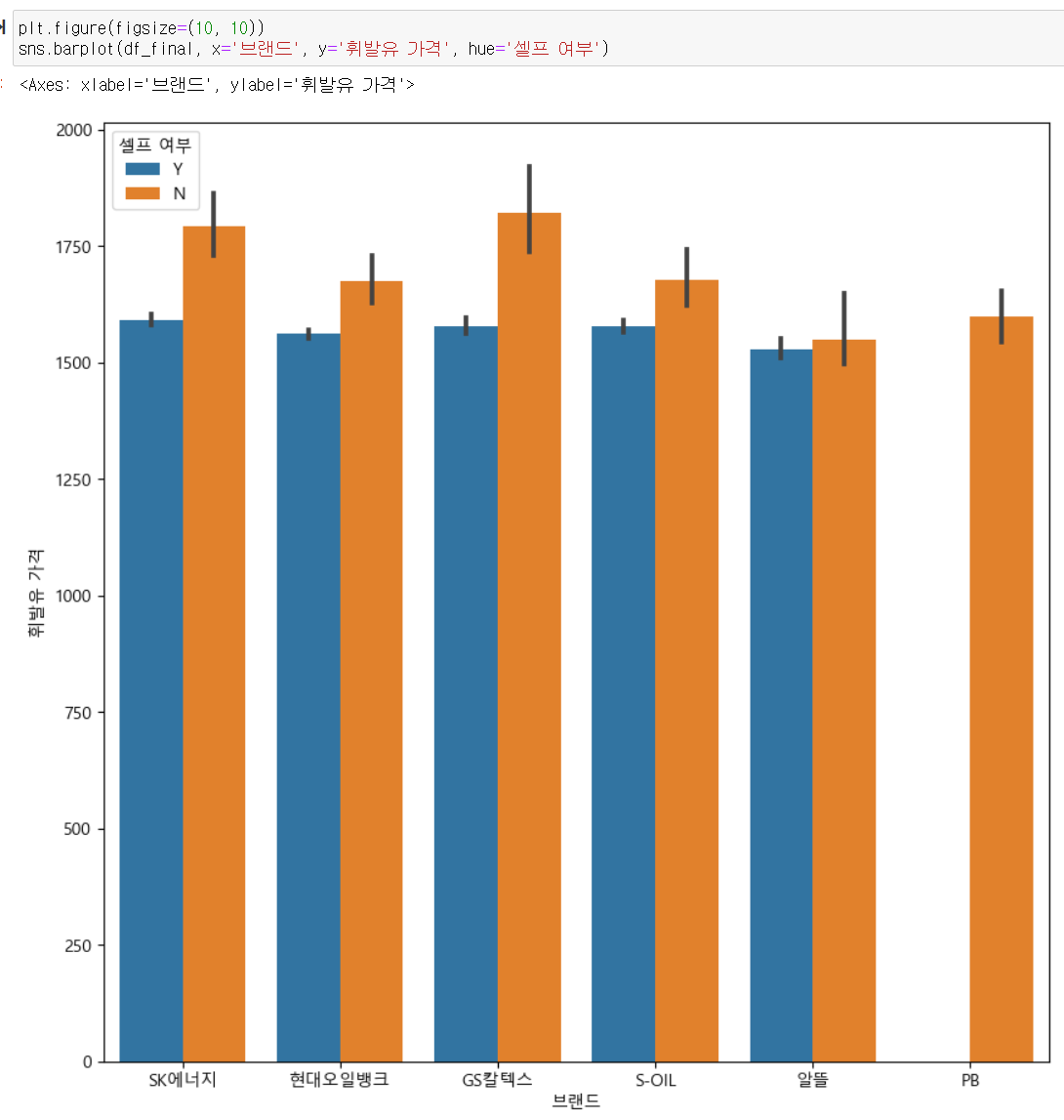
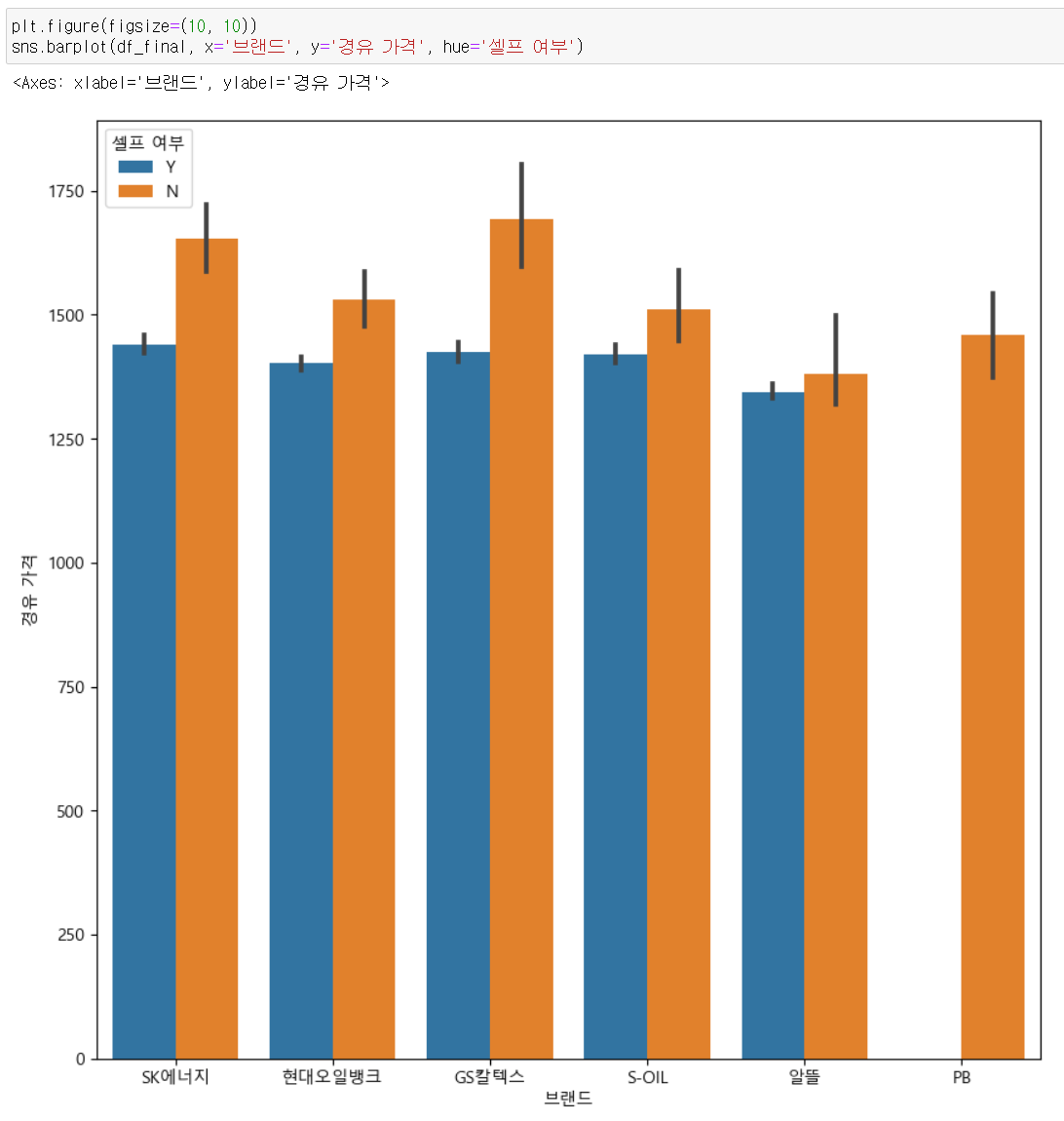
확실히 셀프 주유가 가능한 곳이 휘발유와 경유 가격이 비교적 싼 편이다.
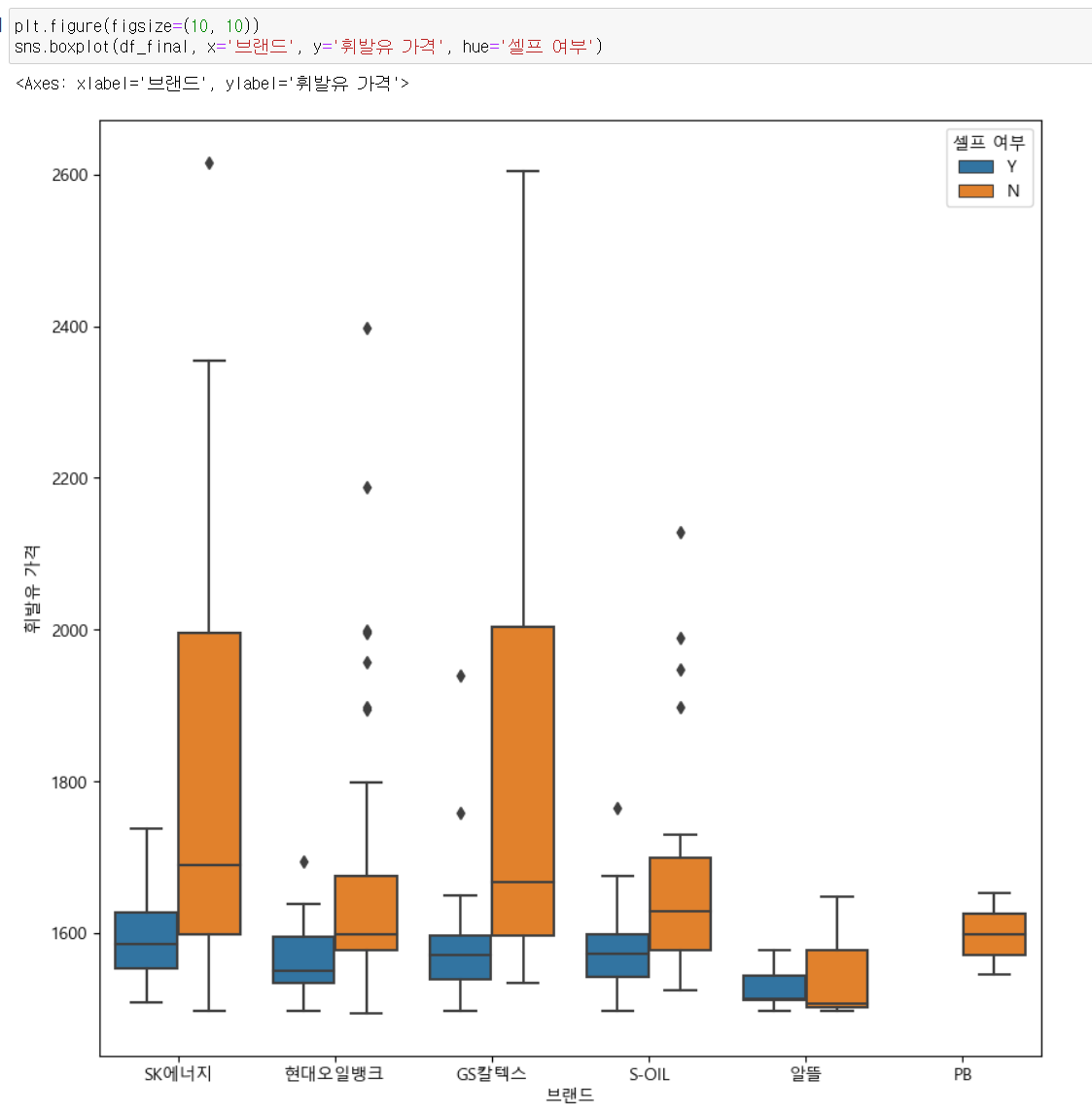
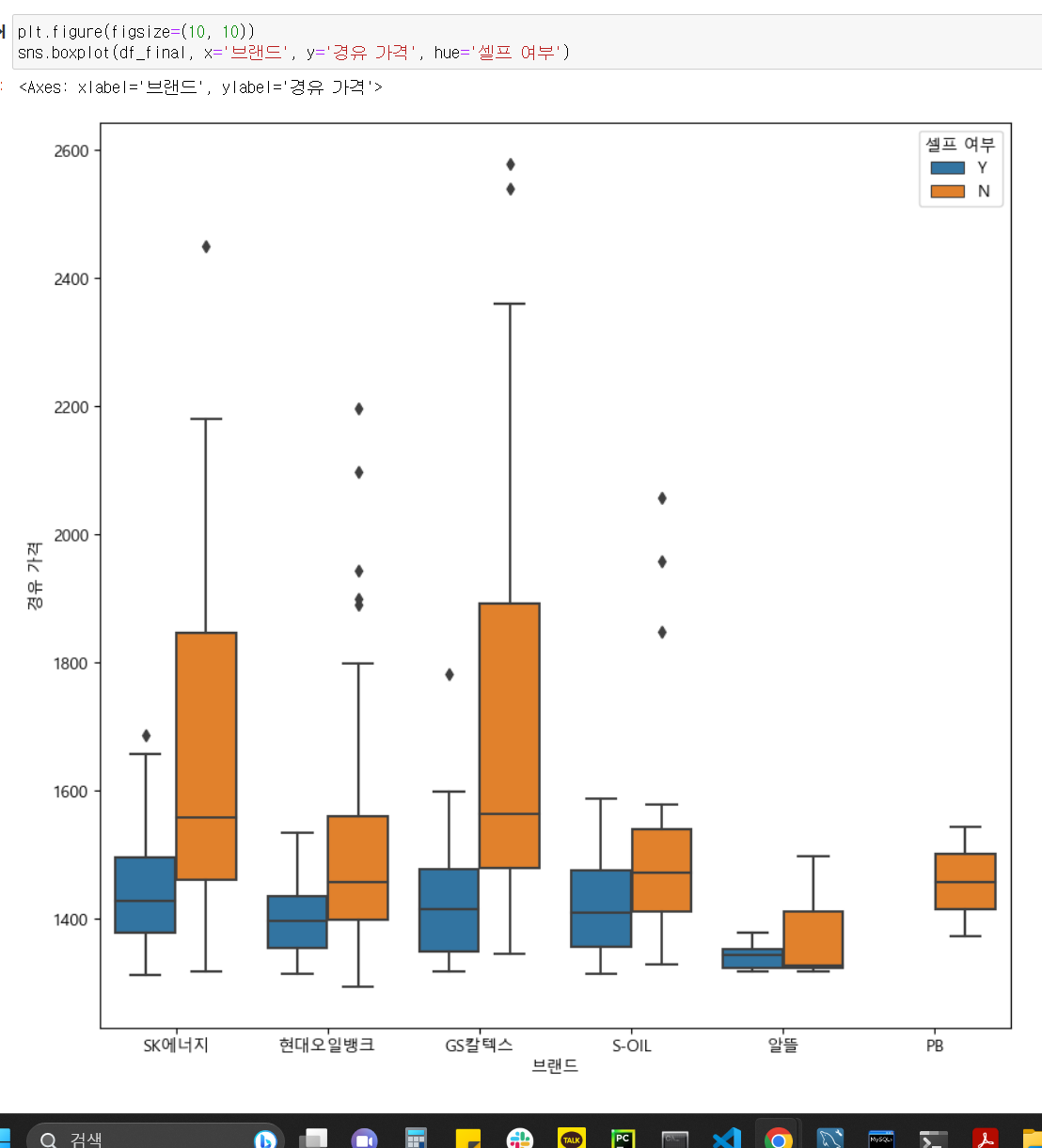
결론
boxplot으로 보았을때 알뜰 브랜드의 데이터가 너무 적어 신뢰도가 떨어진다. 중위값이 셀프 주유가 가능한 곳이 더 높거나, 셀프 주유가 불가능한 곳의 중위 값이 너무 낮게 있다. 주관적인 생각이지만 sk, 현대, gs 같은 대기업의 경우, 최소값부터 25%까지 영역에 비해 75% 부터 최대값까지에 해당하는 영역이 상당히 넓은 것으로 보아 전반적으로 대기업의 주유가격이 훨씬 높은거 같다. 결론은 boxplot 으로 보았을 때 거의 대부분의 주유소중 셀프 주유가 가능한 곳의 주유 가격이 그렇지 않은 곳 보다 저렴하다 라는게 이번 프로젝트의 결론이다.
