- ILP를 위한 컴파일러 테크닉
- 컴파일러 방식과 하드웨어 방식
- 동적으로 instruction을 스케줄링하는 방식
이번 포스팅에서는 ILP를 위한 컴파일러 테크닉에 대해 정리한다.
Pipeline 잠깐 복습하기
Ideal pipeline CPI는 1이다. 하지만 각종 hazard(structural/data/control) 때문에 사실상 ideal CPI를 얻기는 힘들다. 따라서 이 각종 hazard들을 다 더해서 Pipeline CPI를 얻는다.
Pipeline CPI = Ideal CPI + Structural Stalls + Data Stalls + Control Stalls
ILP (Instruction-Level Parallelism)
개념
보통 instruction는 sequential하게 나열되어 있다. 하지만 이 instructions를 순서대로 하나씩 실행시키려면 오버헤드가 커진다.
서로 independent한 instructions를 찾아서 parallel하게 실행시킬 수 있다면 이러한 오버헤드를 줄일 수 있다. 또는, 완전히 중첩시키지는 않더라고 pipeline과 같이 stage를 약간씩 중첩시켜서 실행시킬 수 있다. 이러한 방식을 ILP 방식이라고 한다. 즉, ILP 방식은 서로 독립적인 명령어들을 최대한 찾고, 이들을 오버랩해서 실행함으로써 성능을 높이는 방식이라고 할 수 있다.
ILP 극대화시키는 방법 2가지
1. static한 방법(Software 기법-compiler)
프로그램이 구동되기 전에 compiler 가 "어떻게 하는게 좋겠다!"라고 결정을 내린 뒤 그대로 실행하는 방법이다. (컴파일러에 의존)
ex) Itanium - 하드웨어는 단순하지만 컴파일러가 굉장히 복잡
2. dynamic한 방법(Hardware 기법)
프로그램일 실행시키는 도중에 hazard같은 애들을 하드웨어 가 동적으로 해결해주는 방법이다. (하드웨어에 의존)
ex) Pentium - 하드웨어적으로 굉장히 복잡
Loop-Level Parallelism
용어 정리
- Loop-level Parallelism : loop 내부에서 parallel하게 명령어를 돌리는 것
- Basic Block : Branch해서 들어오는 부분 ~ Branch 끝나고 나가는 부분 (Loop로 감싸진 영역)
loop에서의 어려움(문제점)
명령어를 실행시킬 때, 일반적으로 loop을 돌리는데 대부분의 시간이 걸린다. 따라서 컴파일러는 이 loop에서 걸리는 시간을 줄이기 위해 중간중간에 생기는 stall을 없애려 하고, 이 과정에서 basic block 내부의 명령어들을 rescheduling하려고 한다. 따라서 컴파일러 입장에서는 basic block의 size가 너무 작아버리면 rescheduling을 하기가 힘들어진다. (애초에 재배치할 명령어들의 수가 적어지므로 rescheduling을 할 것도 별로 없고, 그러므로 speed up도 거의 되지 않는다.) 문제는, typical한 프로그램들은 대부분 basic block size가 작아서 Loop-Level Parallelism을 실현하기가 쉽지 않다는 것이다.
아래와 같이 2가지 방법을 활용하여 loop의 성능을 높여볼 수 있다.
1. static via loop unrolling by compiler
2. dynamic via branch prediction
Loop-Level Parallelism을 위한 software 기법 - static via loop unrolling by compiler
1. Re-schedule to solve the dependences(hazards)
컴파일러가 re-scheduling을 할 때 문제가 될 수 있는 요소들로는 각종 hazard(dependence)들이 있다.
여기서는 Data Hazard의 여러 dependency 문제에 대해 잠시 얘기한다.
- True dependence(RAW)
- Anti dependence(WAR)
- Output dependence(WAW)
True dependence같은 경우는 register가 서로 dependent하기 때문에 re-scheduling을 하더라도 해당 명령어들은 순서를 유지해주어야 한다.
Anti나 Output dependenc와 같은 name dependence들은 명령어가 서로 독립적이긴 하지만 register의 개수가 부족해서, 이전 명령어에 사용되었던 register를 가져다 쓰기 때문에 발생하는 문제이다. 따라서 컴파일러가 re-scheduling을 해주면 해결된다. (이 부분은 사실상 register의 개수를 늘려주거나 register renaming 등의 방법을 사용해도 해결되는 부분이기 때문에 fundamental한 이슈는 아님!)
2. Double instructions 사이에 발생하는 stall 분석
Loop-level에서도 pipeline 아키텍처에서와 마찬가지로 data hazard, control hazard등을 해결하여 어떻게 하면 loop-level parallelism을 잘 실현시킬 수 있을까에 대해 고민해야 한다.
loop 내부에서는 아래 그림과 같은 연산들이 이루어질 수 있다. 아래 그림과 같은 명령어들 사이에서 발생하는 stall의 수를 분석해보자.
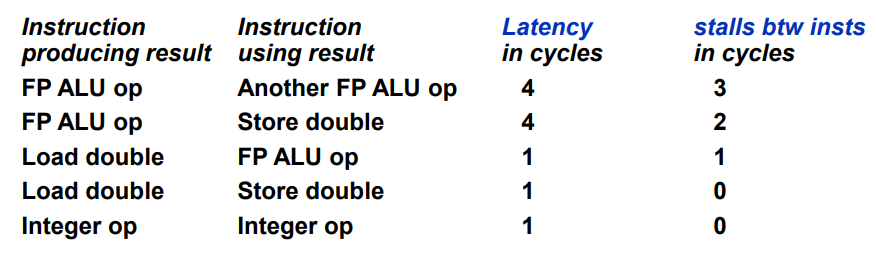
2-1) FP ALU op - Another FP ALU op
add.d f4, f2, f0
sub.d f6, f4, f0- 여기서 add.d의 f4와 sub.d의 f4는 서로 dependent하다. add.d에서 f4의 결과가 생성되므로 add.d가 instruction producing result이고, sub.d가 instruction using result이다.
- 위 예시에 등장하는 add.d와 sub.d는 둘 다 ALU 연산을 수행하고 있다.
- Latency의 경우 instruction producing result의 Execution stage의 길이를 의미한다. double ALU 연산은 Execution이 총 4단계로 이루어지고, 따라서 add.d 명령어의 Execution은 총 4cycles(EX1, EX2, EX3, EX4)가 걸리므로 latency 역시 4 cycles이다.
위 그림에서는 두 명령어 사이의 stall이 3cycles 나온다고 되어있는데, 이유는 다음과 같다.
cycle 0 1 2 3 4 5 6 7 8 9
add.d IF ID EX1 EX2 EX3 EX4 MEM WB
sub.d IF ID EX1 EX2 EX3 EX4 MEM WB- 앞서 언급한 바와 같이 double ALU 연산은 Execution 단계가 총 4cycles이다. 따라서 double ALU 연산을 하는 명령어들 사이에는 3 stalls가 발생한다.
2-2) FP ALU op - Store Double
- 이 경우는 add가 instruction producing result이고, sw가 instruction using result이다.
- 여기서 instruction producing result은 add.d이고, add는 double ALU 연산을 수행중이므로 latency는 역시 4 cycles이다.
위 그림에서는 이들 명령어 사이의 stall이 2cycles 나온다고 되어있는데, 이유는 다음과 같다.
cycle 0 1 2 3 4 5 6 7 8 9
add.d IF ID EX1 EX2 EX3 EX4 MEM WB
sw.d IF ID EX MEM WB- sw나 lw 연산은 EX가 1cycle이다. 따라서 위와 같이 pipeline이 그려질 수 있다. double ALU 연산과 store double 연산을 수행하는 명령어들 사이에는 2 stalls가 발생한다.
sw, lw 연산은 EX가 1cycle로만 이루어져있다.
2-3) Load Double - FP ALU op
- 이 경우는 load가 instruction producing result이고, add가 instruction using result이다.
- 여기서 instruction producing result은 load이고, load의 EX는 1 stage이므로 latency는 역시 1 cycle이다.
cycle 0 1 2 3 4 5 6 7 8 9
lw.d IF ID EX MEM WB
add.d IF ID EX1 EX2 EX3 EX4 MEM WB- Load Double 연산과 double ALU 연산을 하는 명령어 사이에는 1 stall이 발생한다.
2-4) Load Double - Store Double
- 이 경우는 load가 instruction producing result이고, store가 instruction using result이다.
- 여기서 instruction producing result은 load이고, load의 EX는 1 stage이므로 latency는 역시 1 cycle이다.
cycle 0 1 2 3 4 5
lw.d IF ID EX MEM WB
sw.d IF ID EX MEM WB- Load Double 연산과 store Double 연산을 하는 명령어 사이에는 0 stall이 발생한다. (둘 다 MEM 단계에서 작업을 수행하기 때문에 dependency가 발생해도 forwarding으로 해결할 수 있다.)
2-5) Integer op - Integer op
add f4, f2, f0
sub f6, f4, f0- 이 경우는 add가 instruction producing result이고, sub가 instruction using result이다.
- 여기서 instruction producing result은 add이고, Integer ALU op의 EX는 1 stage이므로 latency는 역시 1 cycle이다.
cycle 0 1 2 3 4 5
add IF ID EX MEM WB
sub IF ID EX MEM WB- add 연산과 sub 연산을 하는 명령어 사이에는 0 stall이 발생한다. (add의 EX 단계 직후에서 sub의 EX 단계 직전으로 forwarding해주면 dependency 해결이 가능하다.)
3. FP Loop Example
for (i=1000; i>0; i=i-1){
x[i] = x[i] + s;
}이 코드를 assembly 코드로 바꾸면 아래 그림과 같다.

각 명령어 뒤에 D가 붙은건 double 연산이라는 의미이며, double 연산은 8bytes를 사용한다. 보통 Integer 연산은 4 bytes의 주소공간을 차지하는데, 위의 경우 double 연산이므로 L.D F0, 0(R1) 명령어에서는 F0에 값이 저장될 경우 F0~F1 만큼의 공간을 다 차지한다고 생각하면 된다. (F0, F1 각각은 4 bytes)
+) DADDUI : add. Decrement Add Unsigned integer
+) FP : floating point.
각 instructions 사이에 발생하는 stall까지 적용하면 아래와 같이 나열해볼 수 있다.

stall은 앞서 "2. Double 명령어들 사이에서 발생하는 stall 분석" 부분에서 살펴본 바를 그대로 적용한 것이다.
-
L.D와 ADD.D는 Load Double - Double ALU op이므로 이들 사이에는 1 stall이 발생한다.
-
ADD.D와 S.D는 Double ALU op - Store Double이므로 이들 사이에는 2 stall이 발생한다.
-
S.D와 DADDUI 사이에는 dependency가 존재하지 않으므로 0 stall이 발생한다.
-
BNEZ는 ID stage에서 R1이 0인지 아닌지 test하게 된다.
cycle 0 1 2 3 4 5 6
DADDUI IF ID EX MEM WB
BNEZ IF ID EX MEM WB 따라서 DADDUI와 BNEZ 사이에는 1 stall이 발생한다.총 9 cycles가 발생하였다. compiler의 rescheduling을 통해 cycle을 줄여보도록 하자.

위 그림에서는 S.D와 BNEZ 사이에 있던 DADDUI 명령어를 L.D 바로 뒤로 올린 것을 볼 수 있다. (참고로 DADDUI 연산은 loop example에서 i = i-1 부분에 해당한다.)
DADDUI가 관여하는 register는 R1인데, R1은 S.D와 BNEZ에서 역시 사용된다. 이 때 S.D는 원래 DADDUI 앞에 나오던 명령어이기 때문에 DADDUI에서 변화시킨 부분(-8한 부분)을 고려해주어야 한다(S.D에서 원래 0(R1) 주소를 타겟팅하던 것을 8(R1)으로 다시 타겟팅 해줌). BNEZ 명령어는 원래 DADDUI 뒤에 나오던 명령어이기 때문에 그대로 적용해도 상관없다.

여전히 7 cycles가 걸린다. 조금 더 줄일 수 있는 방법은 없을까? Loop을 펼쳐주자!
4. Unroll Loop
3번 예시를 계속해서 보도록 한다. loop을 한 번 돌 때 위와 같이 명령어들을 늘어놓았었다. 하지만 여전히 stall로 인해 오버헤드가 발생한다. 이를 해결하기 위해 loop이 n번 도는 경우를 한 묶음으로 생각하고 명령어들을 늘어놓도록 한다(straightforward way). 즉, loop을 unrolling한다.
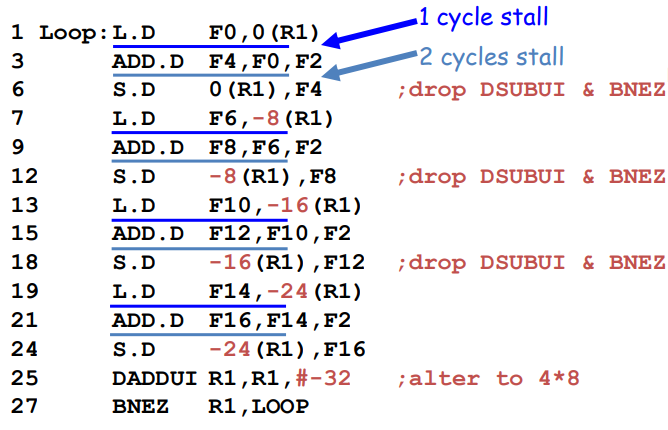
위 그림에서는 3번 예시에 나온 loop이 4번 도는 경우를 한 묶음으로 생각하고 명령어를 늘어놓았다. (Unroll Loop 4 times)
L.D / ADD.D / S.D와 같이 유의미한 명령어들을 우선 4번씩 실행시킨 뒤, Loop 명령어들인 DADDUI와 BNEZ를 가장 마지막에 1번만 실행시킨다. 단, R1의 경우 원래는 DADDUI의 영향을 받아 한 루프 당 -8bytes씩 감소해야 하는데, 이 부분을 하드코딩하여 직접 -8씩 연산한 인덱스를 넣어주었다. 그리고 마지막에 DADDUI에서 한 번에 R1을 -32bytes 해준다.
이는 4 loop를 펼쳐 27 clock cycles가 걸린 것이므로, 1 loop 당 27/4=6.75 만큼의 clock cycles가 걸렸다고 할 수 있다.
앞서 본 7 cycles보다는 줄었지만, 여전히 stall 때문에 오버헤드가 남아있다. 위의 경우는 단순히 loop를 unrolling만 했을 뿐, hazard를 줄이기 위한 optimization을 아무것도 적용하지 않은 상태이다. Optimize를 하여 cycle을 좀 더 줄여보자.

Loop Unrolling을 한 상태에서 명령어를 re-scheduling해보면 위와 같이 코드를 재구성할 수 있다. L.D와 ADD.D와 S.D 간의 dependency를 고려하여 명령어를 재배치했더니 완전히 stall cycles가 제거되었다. 4 times loop가 14 cycles만에 끝났고, 이는 1 loop 당 14/4=3.5 만큼의 clock cycles가 걸렸다고 할 수 있다.
처음에 9 cycles로 시작하여 3.5 cycles까지 줄였다!
- 장점: execution time이 굉장히 많이 줄어든다!
- 단점: 코드 사이즈가 늘어나고, 레지스터가 많이 필요할 수 있다.
Q. 만약 loop 개수가 unrolling하는 개수로 나누어 떨어지지 못한다면 어떻게 해야하는가? 예를 들어, 4 times로 unrolling했는데, 총 loop의 개수가 997 이런식으로 되어있다면 나머지가 생기는데, 이러한 경우를 어떻게 해결할 수 있는가?
A. Loop을 두 부분으로 나눈다. 전체 loop의 개수를 n이라고 하고, unroll하는 loop의 개수를 k라고 하자.
- 우선 나머지(n mod k)에 해당하는 부분을 계산해준다.
- 이후 unrolled body(n/k)에 해당하는 부분을 계산해준다.
요즘은 loop이 어마무시하게 크기 때문에(n의 사이즈가 큼) 나머지(n mod k)에 해당하는 부분은 거의 성능에 영향을 주지 않는다. 따라서 unrolling을 하는 것은 매우 효율적이다.
5. loop unrollilng 할 때 중요하게 고려할 이슈
한 명령어와 다른 명령어 사이에 어떤 dependence가 존재하며, 이를 해결하기 위해 어떤식으로 명령어들을 재배치할 수 있는지를 생각해야 한다. 이 때 함께 고려할 수 있는 부분은 다음과 같다.
-
loop iterations끼리 서로 independent하다면 loop unrolling이 성능을 높이는데 매우 효율적이다. (따라서 미리 loop이 independent한지 검증하도록 한다!)
-
서로 다른 연산을 하는데 괜히 같은 register를 사용하여 불필요한 constraints가 발생하는 상황을 방지해야 한다. 예를 들어, name dependence의 경우 같은 register를 사용함으로써 문제가 발생하는데, register renaming을 해주면 name dependence로 인해 발생하는 문제점을 예방할 수 있다.
-
Eliminate the extra test and branch instruction and adjust the loop termination and iteration code
-
서로 다른 iterations에 있는 load와 store 명령어가 서로 independent하다면, unrolled loop에서 load와 store 명령어의 순서를 바꿀 수 있다. 단, 이 경우 각 load와 store가 접근하는 메모리의 주소를 분석할 필요가 있다.
예를 들어, sw $3 60($4)와 lw $1 100($2)는 서로 independent하기 때문에 컴파일러는 이 둘이 아무런 관련이 없을거라고 여긴다. 하지만 loop가 계속 돌다보면 60($4)가 가리키는 메모리 주소와 100($2)가 가리키는 메모리 주소가 같아질 수 있다. 이러한 경우, 이 둘 사이에는 메모리를 통해서 dependence가 생기지만, 컴파일러는 이를 tracking하기 힘들다. 이를 해결하기 위해 memory disambiguation 이라는 컴파일러 기술을 적용한다. (명령어 사이에 메모리 dependence가 발견되면 컴파일러는 re-scheduling을 적용하지 않는 방향으로 작동할 수도 있다. 이러면 loop을 unroll시켰지만 코드의 optimization은 적용되지 않아 성능이 그닥 향상되지 않는 경우가 발생할 수 있다.) -
코드를 re-schdule할 때는 원래의 코드와 같은 결과가 나오게 해주어야 한다.
6. loop unrolling의 한계
-
무조건 unrolling하면 안된다! 예를 들어, 1000 iterations가 있는 loop에서 4 iterations를 unroll했을 때 3.5 cycles가 나오고 8 iterations를 unroll했을 때 3.2 cycles가 나오는 경우를 생각해볼 수 있다. 약간의 speed-up이 되었지만 코드의 길이가 길어지고, 레지스터를 많이 사용해야하는 등의 문제가 발생하게 되는데, 과연 이만큼 speed-up을 한 것을 무조건 좋다고 할 수 있는지를 고민해봐야한다. (Amdahl's law)
-
코드 사이즈 증가
-
register pressure - 원래는 컴파일러가 메모리에 있는 데이터들을 레지스터에 올려서 연산을 수행한다. 하지만 레지스터를 더 사용하지 못하는 경우가 발생해버리면 계속해서 메모리에 값을 쓰고 읽는 작업을 반복해주어야 하기 때문에 메모리 액세스로 인한 오버헤드가 커진다. (성능이 더 나빠진다)
[Summary]
- 대부분의 code에는 loop이 많이 등장하고, 전체 코드를 실행시키는 시간 중 대부분이 loop 실행시간에 해당한다. 즉, loop에서 소모되는 시간을 줄이면 전체 코드의 성능을 향상시킬 수 있다.
- Loop을 돌릴 때 걸리는 전체 시간을 줄이기 위해 loop-level parallelism을 수행한다.
- Loop 내부에도 여전히 data hazard, control hazard 등이 존재하고, 이러한 hazards는 loop-level parallelism을 방해한다. 컴파일러는 이를 해결하기 위해 Loop Unrolling 방식을 이용한다.
- Loop Unrolling + Code Rescheduling을 통해 Data hazard와 Control hazard 문제를 해결한다. 이를 통해 data hazard의 여러 dependences나 control hazard로 인해 발생하는 stall instructions의 수를 줄이거나 제거할 수 있다.
(사실상 Control hazard는 branch가 존재하는 한 완전히 해결되기는 힘들다. 따라서 여기서는 Control hazard 문제를 해결했다고 보기는 힘들고, 다만 control hazard의 빈도수를 줄였다고 할 수는 있다. 원래라면 1000 iterations만큼 도는 loop이 있을 때, 1000번의 branch가 있으므로 1000번의 control hazard가 발생하게 되지만, 4 loops unrolling을 통해 branch의 수를 250번으로 줄임으로써 control hazard의 발생 빈도가 줄어들게 된 것이다.)
