- ILP를 위한 컴파일러 테크닉
- 컴파일러 방식과 하드웨어 방식
- 동적으로 instruction을 스케줄링하는 방식
지난 포스팅에서 정리한 Loop Unrolling 방식(Loop-Level Parallelism을 위한 컴파일러 방식)은 사실상 Control hazard를 줄였다기보다는, Control hazard의 발생 빈도를 줄인 것이다. 즉, branch penalty 자체가 줄어든 것이 아니라 branch frequency가 줄어들었다고 볼 수 있다. (이해가 되지 않을 경우 지난 포스팅의 Summary를 참고한다.)
이번 포스팅에서는 branch penalty 자체를 줄이는 방법에 대해 정리한다.
static branch prediction
static branch prediction은 명령어를 수행하기 전에 컴파일러가 미리 branch가 taken될지 not taken될지 예측한 후 이를 적용하는 방법이다. 아래와 같이 3가지 방식으로 예측할 수 있다.
Predict a branch as taken
branch가 무조건 taken된다고 예측한다.
Predict a branch as not taken
branch가 무조건 not takenn된다고 예측한다.
Trace(profile)-based branch prediction
아키텍처 시뮬레이션을 돌려본 후 branch가 몇 번 taken되고 not taken되는지를 통계적으로 분석한 후, 더 높은 쪽으로 결정한다. 예를 들어, 시뮬레이션 결과 branch가 80% taken될 것으로 추정된다면 컴파일러는 branch가 taken 된다고 예측한 상태에서 명령어들을 수행한다.
컴파일러 기술이다!!(하드웨어는 관여할 필요 없음!)
Trace-based branch prediction을 하게 되면 misprediction이 25% 미만으로 확 줄어든다! (Taken, Not taken 등은 거의 50%정도의 misprediction이 나왔었음.)
dynamic branch prediction
dynamic branch prediction은 명령어를 수행하는 와중에 하드웨어가 어떠한 패턴을 분석하여 branch가 미리 taken될지 not taken될지 예측하면서 이를 적용하는 방법이다.
1) Branch History Table (BHT)
과거에 수행된 branch들을 history table에 저장(기록)해두고, 이후에 동일한 branch가 taken될지 not taken될지 예측한다.
< 작동 방법 >
BHT는 PC address의 lower bits를 인덱스로 갖고, 1 bit(0 또는 1) 값을 갖는 테이블이다. 이 1bit 부분이 전에 branch가 taken 되었는지 not taken 되었는지의 이력을 보여준다. (0이면 Not taken, 1이면 Taken되었다는 의미이다.) 과거에 not taken되었으면 지금도 not taken하고, 과거에 taken 되었으면 지금도 taken하는 식으로 예측한다.
예를 들어, 다음과 같은 instructions와 BHT가 있다고 하자.(처음에 BHT의 values는 전부 0으로 초기화)
0xFFFF3450 add
0xFFFF3454 sub
0xFFFF3458 beq
| index | value |
|---|---|
| 0 | 0 (Not taken) |
| 1 | 0 (Not taken) |
| 2 | 0 (Not taken) |
| 3 | 0 (Not taken) |
| 4 | 0 (Not taken) |
| 5 | 0 (Not taken) |
| 6 | 0 (Not taken) |
| 7 | 0 (Not taken) |
현재 beq의 PC address는 0xFFFF3458이고, 여기서 lower bits 3자리를 확인해보면 다음과 같다.
.... 0101 1000 (word는 마지막 2자리를 읽지 않음 / 현재 bht의 index가 0~8까지이므로 lower bits 3자리를 읽어줘야 함 000~111)
PC의 lower bits가 6(110)이므로 6번 index의 value를 확인하면 된다. 현재 6번 index의 value는 0(Not taken)이므로, beq는 not taken될 것이라고 예측할 수 있다.
< 1-bit BHT의 문제점 >
만약 loop에서 BHT를 이용해 branch를 예측할 경우, 2번의 mispredictions가 발생할 수 있다.
- loop 시작 부분: 이전에 등장한 이력이 없는 branch이기 때문에 mispredict할 수 있다.
- loop의 마지막 부분: 이전까지는 loop가 계속 동작중인 상태이기 때문에 branch 역시 계속 taken된다고 예측할 것이다. 하지만 loop을 빠져나가는 마지막 iteration에서는 실제 branch가 not taken되므로 여기서 misprediction이 발생한다.
< 1-bit BHT의 해결책 >
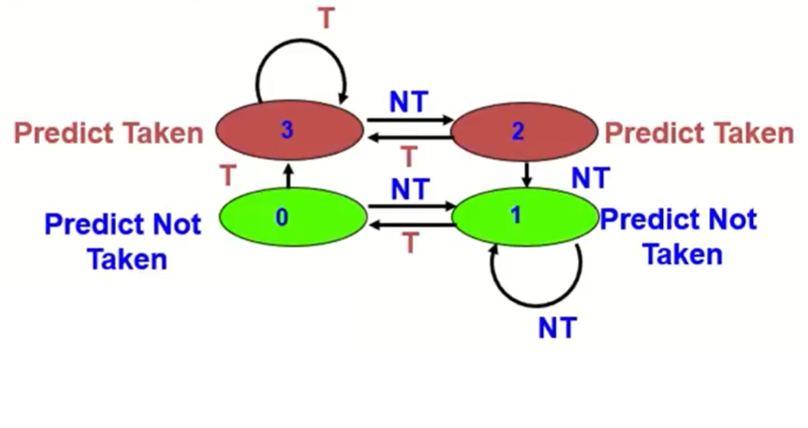
Solution: 2-bit scheme (hysteresis: 바로 바꾸지 않고, 좀 더 delay시킨 뒤 바꿈)
misprediction이 2번 일어났을 경우에 prediction을 바꾼다.
BHT 예시)
| index | value |
|---|---|
| 0 | 00 (Not taken) |
| 1 | 01 (Not taken) |
| 2 | 10 (Taken) |
| 3 | 11 (Taken) |
| 4 | 01 (Not taken) |
| 5 | 10 (Taken) |
| 6 | 11 (Taken) |
| 7 | 01 (Not taken) |
00과 01이면 현재는 not taken으로 예측한다.
10과 11이면 현재는 taken으로 예측한다.
< misprediction이 발생하는 이유 >
-
Prediction is wrong
(ex. BHT는 Not taken이라 되어있어서 Not taken이라고 예측했는데 실제로는 taken되는 경우) -
Hashing conflict - 하나의 entry(index)에 여러개의 서로 다른 branch들이 매핑되는 경우
(ex. 동일한 branch가 아니더라도, PC address의 lower bits가 같으면 무조건 동일한 index에 value가 저장된다. 따라서 BHT에 기록된 branch prediction 값이 현재 branch의 과거 이력이 아니라 다른 branch의 과거 이력이 기록된 것일 수도 있다.)
Branch를 수행하기 위해서는 다음과 같은 정보를 알아야 한다.
Branch를 할 것인지, 하지 않을 것인지 - Branch Prediction
: Global Branch Predictor / Locall Branch PredictorTarget Address가 어디인지 (어디로 jump할 것인지)
: Branch Target Buffer / Return Address Stack
2) Global Branch Predictor
Correlated Branch Prediction과 Global Branch Prediction은 비슷한 개념임! 옛날에는 Correlated Branch Prediction이라고 불렀는데, 요즘에는 Local Branch Prediction과 통일감을 주기 위해 용어를 Global Branch Prediction이라고 부른다고 함.
Correlated Brach Prediction
- 가장 최근에 수행된 m개의 branch 이력을 기록하고, 해당 패턴을 이용하여 적절한 n-bit BTH를 선택한다.
- (m, n) predictor: 가장 최근 m개의 branch들을 기록하고, n-bit을 value로 갖는 2^m history tables들 중에 선택한다.
- global branch history: 최근 m개의 branch의 상태를 유지하는 m-bit shift register이다.
- 전체 entry의 개수는 2^m(BHT 수) * n-bit(BHT의 각 entry의 bit수)이다.
예를 들어, (2, 2) predictor를 생각해본다. 하드웨어가 현재 predict해야하는 branch가 있을 때, 이 branch의 가장 최근 2개의 과거 이력을 확인한다. 이 때 최근 2개의 과거 이력의 경우의 수는 다음과 같이 4가지이다.
| 1번째 | 2번째 | 3번째 | 4번째 |
|---|---|---|---|
| (NT, NT) | (NT, T) | (T, NT) | (T, T) |
만약 실제 과거 이력이 NT, T이라면 하드웨어는 2번째 BHT를 선택하고, 해당 테이블로 접근한다. 2번째 테이블의 몇 번째 index로 접근할지는 Branch Address(PC)를 통해 결정할 수 있다.
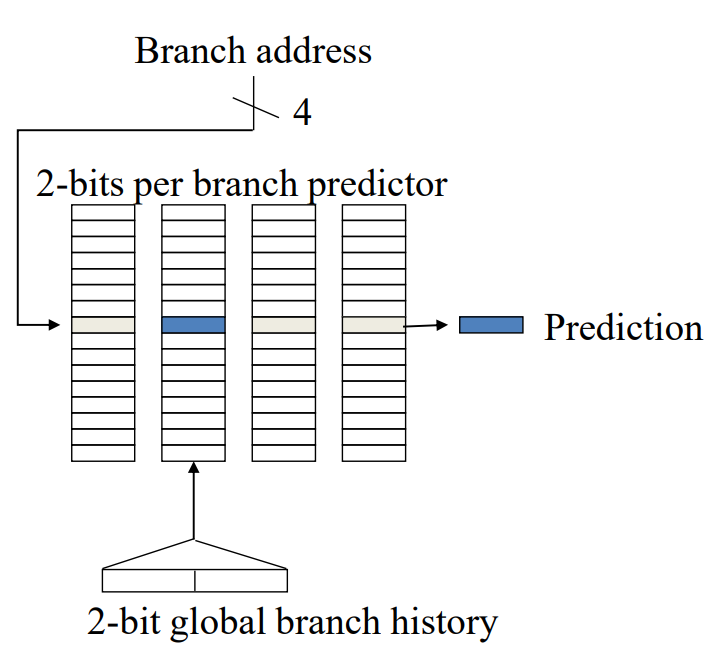
즉, 위와 같은 BHT가 있다고 할 때, 6번째 index에 접근한다는 의미는 Branch Address의 lower bits 4자리가 0110이라는 의미이다. (여기서는 Lower bits를 4자리까지 보는 이유는 각 BHT의 index가 총 16가지이기 때문이다. - 0000~1111 - 또한 word에서는 마지막 2bit을 취급하지 않으므로 Branch Address의 실제 주소값은 .... ..01 10.. 일 것이다.)
현재 선택된 BHT는 2번째 BHT이고, index는 6번째이다. 여기서 만약 해당 index의 value는 01이었다고 가정하자. 이 경우, 하드웨어는 현재 실행될 branch가 NT될 것이라고 예측할 수 있다.
다시 정리해보면 아래와 같다.
| 이력 | 상태 |
|---|---|
| 전전 | NT |
| 전 | T |
| 현재 | NT라고 predict |
현재 branch가 NT이라고 예측했는데, 만약 Taken된다면 위에서 본 2번째 BHT의 6번째 index의 value는 어떻게 변할 것인가? 원래는 01이라는 값이 저장되어 있었다. 위의 Finite State Machine에 따르면 1(01)에서 Taken되었을 때 0(00)으로 상태가 변하므로 6번째 index의 value는 00으로 바뀌게 될 것이다.
동일한 branch를 또 다시 예측할 상황이 발생하면, 이번에는 다음과 같이 볼 수 있다.
| 이력 | 상태 |
|---|---|
| 전전 | T |
| 전 | T |
| 현재 | ??? |
이번에는 4가지 경우의 BHT 중에서 TT인 4번째 BHT를 선택하고, 또다시 Branch Address의 lower bits에 해당하는 6번째 index로 접근한다. 현재 00이 저장되어있으므로 NT라고 예측할 수 있다. 여기서 만약 현재 branch가 Taken된다면 해당 index의 값은 3(11)로 바뀔 것이고, Not Taken된다면 1(01)로 바뀔 것이다. (위의 FSM을 참고)
Global History Branch Predictor
Correlated Branch Prediction을 좀 더 일반화한 것이 Global History Branch Predictor이다. 돌아가는 방식은 둘이 거의 똑같다.
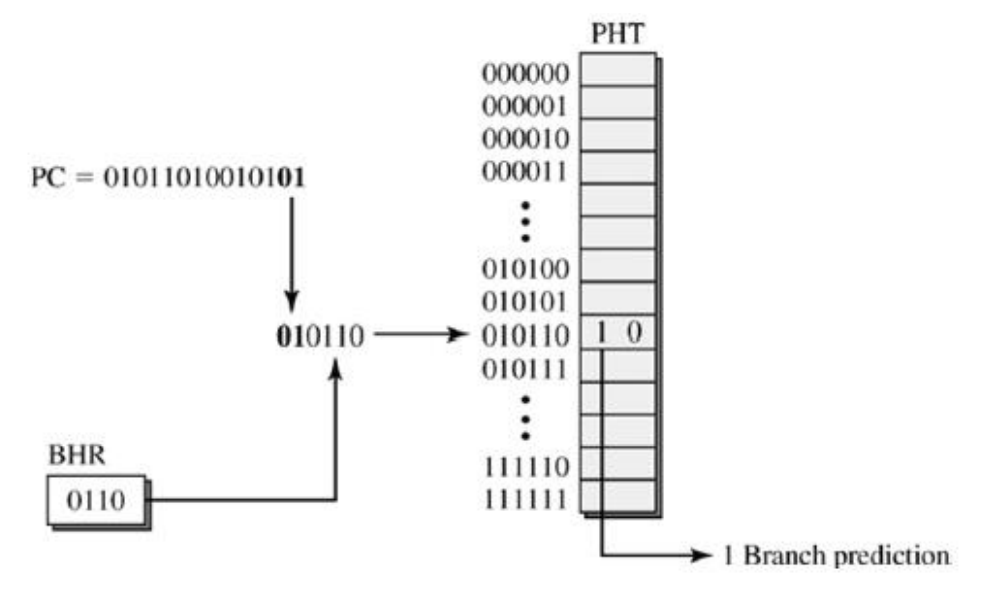
BHR: Branch History Register - global history에 대한 shift register
PHT: Pattern History Table
3) Local Branch Predictor
여러 개의 branch들이 있을 때 각각의 history만 갖고 미래를 예측하겠다!
ex) iteration이 3~4정도 되는 작은 loop이 큰 loop으로 감싸져있는 경우, branch pattern이 1110111011101110...과 같이 반복된다. 이 때 작은 loop의 마지막 iteration이 not taken될 것이라는 것을 어떻게 잘 predict할 수 있는가?
| 앞에 4개 bit | Prediction |
|---|---|
| 0000 | |
| 0001 | |
| 0010 | |
| 0011 | |
| 0100 | |
| 0101 | |
| 0110 | |
| 0111 | 0 (00 - Not Taken) |
| 1000 | |
| 1001 | |
| 1010 | |
| 1011 | 1 (11 - Taken) |
| 1100 | |
| 1101 | 1 (11 - Taken) |
| 1110 | 1 (11 - Taken) |
| 1111 |
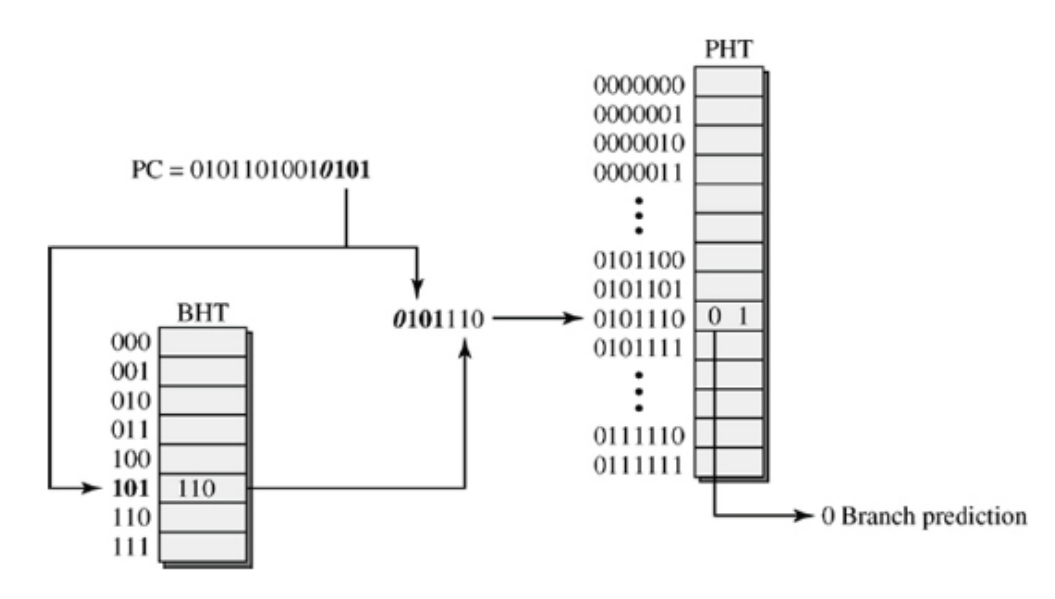
BHT: PC의 lower bits 3자리를 사용 (참고로 위 그림에서 맨 뒤 2bit인 00은 생략된 상태)
4) Branch Target Buffer (BTB)
BTB는 Branch Target Address를 저장하는 버퍼이다.(캐시같은 구조) 과거에 한 번이라도 해당 Branch의 Target Address가 계산된 적이 있다면, 이후에는 그걸 이용하면 된다. (일반적인 경우에는 Branch의 Target Address의 물리적인 값이 잘 바뀌지 않는다. - Target Address가 각 iteration마다 계속 바뀌거나 하지는 않음)
단, 아래와 같은 경우는 Target Address가 바뀔 수 있다. (JAL 명령어)
int main(){
...
foo();
...
foo();
}위 코드에서는 foo() 함수가 서로 다른 위치에서 호출되고 있는데, 이러한 경우 Branch Target Address 값이 바뀔 수 있다.
BTB의 구조는 아래와 같다.
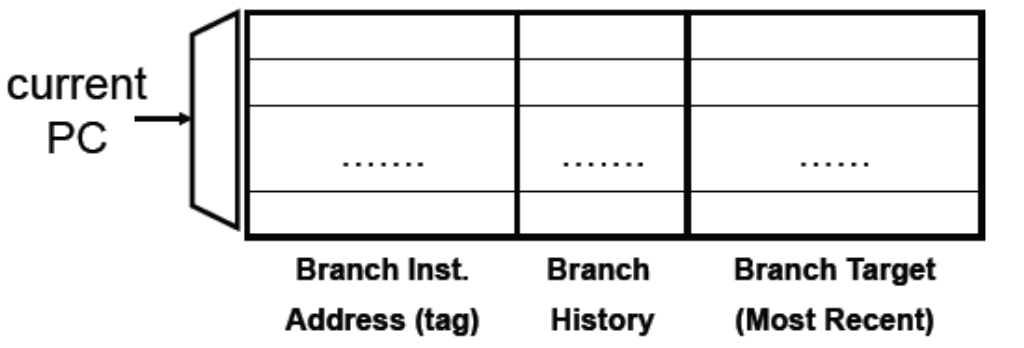
Branch Instruction Address와 같은 태그를 또 저장하는 이유
: Branch Address의 전체를 tag로 저장하는 이유는 hashing conflict를 피하기 위해서이다. 만약 lower bit만 가지고 index를 계산하여 BTB에 접근하게 되면, lower bit은 같지만 서로 다른 branch의 target address를 참조하게 되는 경우가 발생할 수 있다. 이러한 위험을 방지하기 위해 Branch instruction Address를 tag로 달아둔다.
예를 들어, A라는 branch와 B라는 branch의 lower bit은 같고, BTB에는 A라는 branch의 정보가 저장된 상태이다. 만약 tag가 없다면, B라는 branch는 A branch의 target address를 참조하게 될 것이다. 하지만 이렇게 되면 B와 A는 서로 다른 branch이기 때문에 잘못된 target address를 참조하는 것이 된다. 따라서 A와 B를 구분해주기 위해 Branch Instruction Address 역시 tag로 넣어주는 것이 옳다.
※ 참고로 요즘에는 위 구조에서 Branch History column은 뺐다. 현재는 Branch Instruction Address(tag)와 Branch Target column만 포함시킨다.
아래는 BTB 알고리즘의 flow이다.
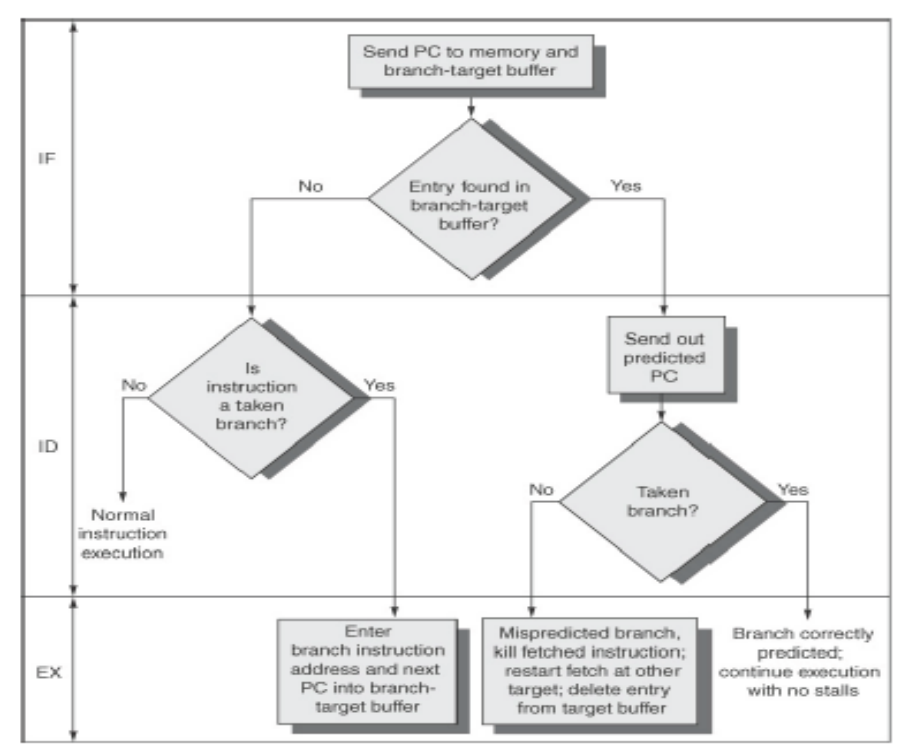
IF: Target Buffer에 기록된 branch인가?
ID: 해당 branch가 Taken되는 branch인가?
EX: 실행단계
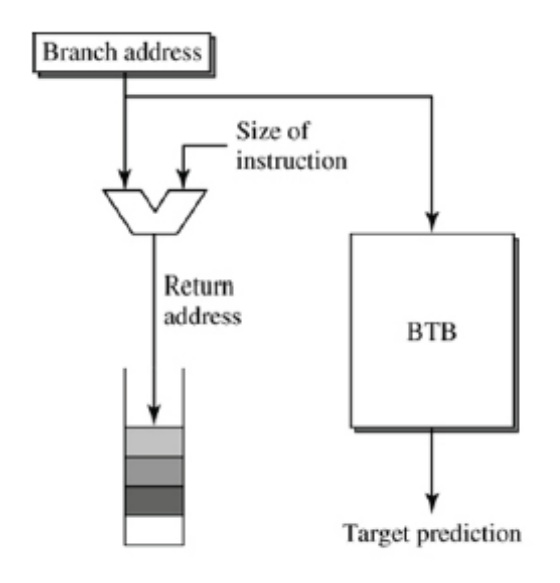
5) Return Address Stack (RAS)
Function 실행을 마친 경우, 해당 function을 호출했던 명령어의 다음 명령어로 return해야 한다. 즉, function을 마치면 어느 위치로 되돌아갈지에 대한 정보가 어딘가에 저장되어 있어야 한다. 이를 저장하는 장소가 Return Address Stack이다.
예를 들어, 만약 main함수에서 A() B() C() D() 함수가 nested로 호출되었다면, RAS에는 아래와 같은 구조로 return address가 보관되어야 한다.
| top |
|---|
| C에서 D를 호출한 명령어의 다음 명령어 주소 |
| B에서 C를 호출한 명령어의 다음 명령어 주소 |
| A에서 B를 호출한 명령어의 다음 명령어 주소 |
| main에서 A를 호출한 명령어의 다음 명령어 주소 |
참고로 stack이므로 위에서부터 pop한다. (LIFO)
BEQ나 J와 같은 명령어들은 동일한 branch에 대해 Target Address가 바뀔 일이 없다. 따라서 BTB만 사용한다. 하지만 JAL은 함수 호출이 끝나면 목적지(Return해야 할 Address)가 매번 바뀔 수 있다. 따라서 JAL 명령어는 BTB와 RAS를 함꼐 사용한다.)