안녕하세요. 이번에는 저희 Applied AI Lab.에서 KDD 2019에 출판한 MeLU(Meta-Learned User preference estimator)라는 논문을 소개하려고 합니다.
이 글에서는 파인만 알고리즘에 따라 1) 저희가 푼 문제에 대한 설명, 2) 이런 아이디어를 생각하게 된 사고 과정, 그리고 3) 최종적으로 저희가 문제에 대한 답을 어떻게 써내려갔는지에 대해서 소개드리고자 합니다.
실험 결과에 대해서는 이 글에서 언급하지 않을 예정이니, 논문을 통해 확인 부탁드리겠습니다.
Write down the problem
저희는 추천 시스템을 공부하면서 '사람들마다 각기 다른 생각을 가지고 있는데 왜 추천 시스템은 모두에게 동일한 아이템을 추천할까?' 하는 호기심이 생겼습니다.
예를 들어, 영화 '인터스텔라'를 본 두 사람 A와 B가 있고, A라는 사람은 크리스토퍼 놀란 감독의 연출이 좋아서 이 영화를 본 것이고 B라는 사람은 SF 장르가 좋아서 이 영화를 봤다고 가정을 해봅시다. (물론 한 편의 영화를 바탕으로 이런 추측을 하는 것은 사람에게도 매우 어려운 일입니다.) 이후 A는 추천시스템이 장르는 조금 다르더라도 같은 감독의 영화인 '다크나이트'를 추천해주길 바랄 것이며, B는 같은 장르의 영화인 '아바타'를 추천해주길 기대할 것입니다. 즉, 사용자 A와 B는 아이템을 공통으로 소비했지만 추천시스템이 다른 방식으로 추천해주길 바랄 것입니다.
저희는 바로 이 포인트에 맞춰서 연구를 시작했습니다.
"사용자 개개인에 꼭 맞는 추천시스템을 만들어 주자!"
Think very hard
위의 문제를 풀기위해 저희는 깊이 고민했습니다.
개인에게 맞는 추천시스템을 만들 때 저희가 가장 어려울 것이라고 생각했던 부분은 추천 모델을 학습하는 부분입니다. 딥러닝 기반의 추천 모델이 잘 작동하기 위해서는 모델의 많은 파라미터를 학습할 수 있는 많은 수의 학습 데이터가 필요한데, 개인에게 맞는 추천 시스템을 구축할 때는 많은 데이터를 확보할 수 없기 때문이죠. 이를 극복할 수 있는 방법에 대해서 고민하던 중에 저희 Lab.에서 매주 진행하는 세미나 시간에 접했던 메타러닝(meta-learning)이 생각났습니다.
메타러닝
메타러닝은 Few-shot learning이라고도 부릅니다. 모델의 크기에 비해서 학습 데이터 수가 작은 환경에서도 예측을 잘 수행하는 것을 목표로 하기 때문에 few-shot learning이라고도 부르게 된 것입니다. 특별히, 분류 문제에서는 메타러닝을 N-way K-shot 분류 문제라고도 합니다. 이 때 N-way는 모델이 주어진 입력(input)을 몇 개 중에 하나로 분류할 것인지를 의미합니다. 즉, N-way는 우리가 만드는 분류 모델은 N개의 class를 분류하는 모델이라고 생각하시면 됩니다. K-shot은 각 class 당 몇 개의 학습 데이터(training samples)가 있는지를 의미합니다. 그럼 N-way K-shot에 대한 의미를 풀어쓰면, N개의 class에 대한 분류 모델을 학습하는데 그 때 각 class에 속한 학습 데이터의 수가 K개라는 의미입니다. 즉, N-way K-shot에는 NK개의 학습 데이터가 존재합니다.
독자 분들의 이해를 돕기 위해서 아래와 같은 분류 문제 예시를 소개해드리겠습니다. 아래 그림과 같이 14개의 도형을 분류하는 문제가 있다고 가정할 때, 5-way 2-shot 상황에서의 메타러닝 모델 환경을 구성해보았습니다. 첫 번째 task에서는 평행사변형, 마름모, 직각삼각형, 정삼각형, 그리고 원을 분류하는 경우를 나타냅니다. 이 때 왼쪽 상자 안에는 각 도형에 해당하는 학습 이미지가 두 장씩 있고, 오른쪽 상자에는 테스트를 위한 마름모가 한 장 있습니다. 메타러닝에서는 왼쪽 상자에 해당하는 데이터 셋을 support set, 오른쪽 상자에 해당하는 데이터 셋을 query set이라고 부릅니다. 두 번째 task에 대해서도 직사각형, 화살표, 정오각형, 사다리꼴, 원 이렇게 분류하는 문제이고 이후 support set과 query set은 동일하게 생각하시면 됩니다.
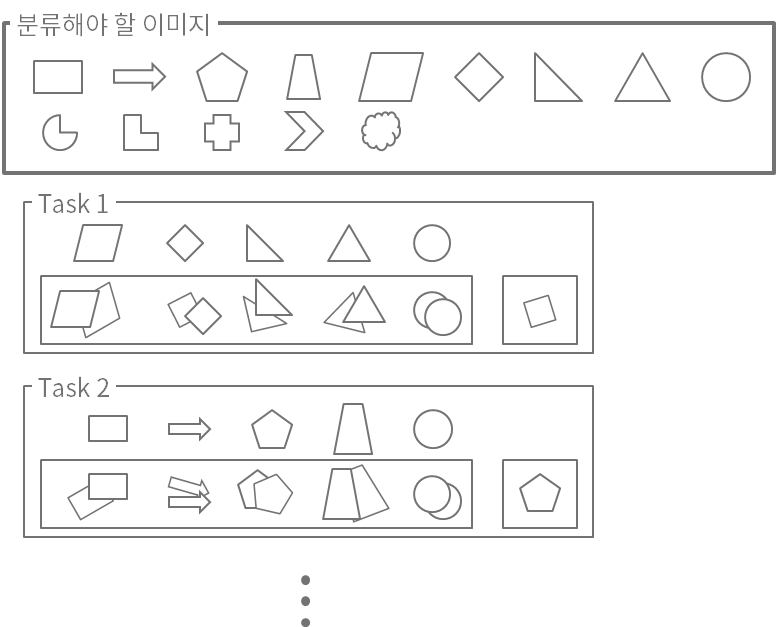 [그림 1] 메타러닝 데이터 셋 구분
[그림 1] 메타러닝 데이터 셋 구분
위와 같이 데이터 셋이 준비되어 있을 때, 최적화(optimization) 기반 메타러닝 모델은 "여러 Tasks에 대해서 빠르게 학습할 수 있는 초기 파라미터를 찾자"는 목표를 가집니다. 아래 그림 2와 같이 저희가 학습하려는 모델 가 있고, 그 모델 의 파라미터를 라고 하겠습니다. 최적화 기반 메타러닝 모델은 이 작을 때 다음의 조건을 만족시키는 초기 파라미터 를 찾고자 합니다.
- Task 1의 support set 속한 데이터 셋을 이용해서 로부터 gradient step만큼 학습했을 때 Task 1의 query set에서 좋은 성능을 보임.
- Task 2의 support set 속한 데이터 셋을 이용해서 로부터 gradient step만큼 학습했을 때 Task 2의 query set에서 좋은 성능을 보임.
- Task 3의 support set 속한 데이터 셋을 이용해서 로부터 gradient step만큼 학습했을 때 Task 3의 query set에서 좋은 성능을 보임.
- ...
이 작을 때 모든 query set에서 좋은 성능을 보인다는 것은 모든 task에 대해서 모델이 빠르게 학습할 수 있는 초기 파라미터 를 찾았다는 것을 의미합니다.
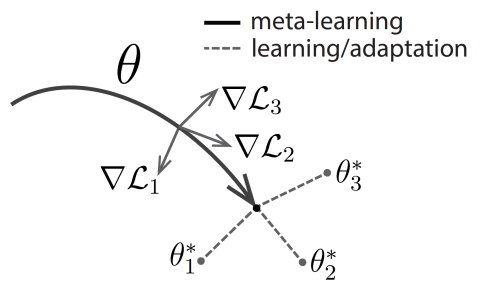 [그림 2] 최적화 기반 메타러닝 모델 학습 과정 (출처: [1])
[그림 2] 최적화 기반 메타러닝 모델 학습 과정 (출처: [1])
그림 1과 그림 2를 연관지어 "평행사변형, 마름모, 직각삼각형, 정삼각형, 그리고 원"을 분류하는 Task 1을 그림 2에서 1번에 매핑된다고 생각하고, "직사각형, 화살표, 정오각형, 사다리꼴, 원"을 분류하는 Task 2를 그림 2에서 2번에 매핑된다고 생각해보겠습니다. Task 1에 해당하는 경우는 평행사변형, 마름모, 직각삼각형, 정삼각형, 그리고 원만 분류를 잘 하면 될 뿐, Task 2에 포함된 정오각형, 사다리꼴, 화살표, 직사각형 등은 분류를 잘 할 필요가 없습니다. 즉, 각 task에서는 서로 다른 문제를 풀기 때문에 모델의 구조가 동일하더라도 Task 1과 2를 수행하는데 꼭 맞는 최적의 파라미터(와 )가 각기 다릅니다. 최적화 기반 메타러닝은 이와 같이 각기 다른 task에 대한 최적의 파라미터를 빠르게 학습할 수 있는 공통의 초기 파라미터 를 찾는 것을 목표로 합니다.
뉴럴 네트워크에서는 분류 문제와 회귀 문제에서의 차이가 크지 않기 때문에 회귀 문제도 위의 예시와 비슷하게 생각할 수 있습니다. 다만, 회귀 문제의 경우에는 분류 해야하는 class가 없기 때문에 N-way는 무의미해지며, 몇 개의 학습 데이터를 나타내는 K-shot만 의미를 갖게 됩니다. 따라서, 회귀 문제에서는 일반적으로 N-way K-shot으로 표현하지 않습니다. 저희는 메타러닝 관점의 회귀 문제와 추천 시스템을 연관지어 생각해보았습니다.
추천 시스템과 메타러닝을 연관짓기 전에 마지막으로 한 가지 부분을 다시 강조드리고자 합니다. 앞선 예시에서 Task 1과 2에 대해서 각각 학습된 모델은 구조만 같고 다른 최적의 파라미터를 갖는 다른 모델이라는 점입니다. 당연한 내용일 수 있지만, 이 특징으로 인해 저희가 처음에 소개한 "사용자 개개인에 꼭 맞는 추천시스템"을 만들 수 있었습니다. 더 나아가서, 메타러닝이 few-shot learning이라고도 불리는 것처럼, 제안하는 추천 모델이 기록이 적은 초기 사용자(user cold-start or new user)경우에 잘 작동할 것이라고 생각했습니다.
메타러닝과 추천 시스템 연결짓기
저희가 풀려는 문제도 '개별 유저마다 소비한 아이템이 적은 상황에서 추천을 잘 하는 모델을 만드는 것'이기 때문에 위에서 설명드린 메타러닝과 같은 맥락의 문제라는 생각이 들었습니다.
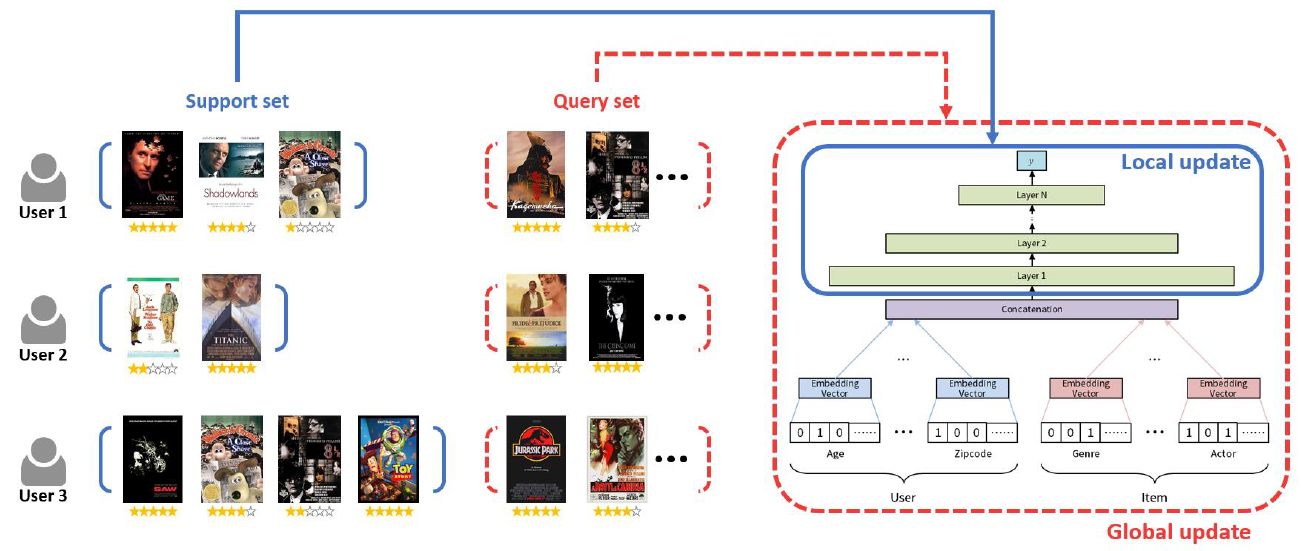
아래 그림과 같이 영화 추천 시스템을 예시로 설명 드리겠습니다. 유저가 소비한 영화는 support set으로 간주하고 유저가 이후 소비할 영화를 query set으로 생각해보겠습니다. 이와 같이 구성된 데이터 셋을 기반으로 메타러닝을 통해 영화 추천 모델을 학습할 경우, 개별 유저에 꼭 맞춰 영화를 추천할 수 있는 모델의 초기 파라미터가 학습될 것이라고 생각했습니다.
 [그림 3] 메타러닝 관점으로 바라본 개별 사용자의 아이템 추천
[그림 3] 메타러닝 관점으로 바라본 개별 사용자의 아이템 추천
최적화 기반 메타러닝 모델로 구성된 추천 모델은 다음의 조건을 만족시키는 추천 모델의 초기 파라미터 를 찾게 됩니다.
- User 1의 support set 속한 영화 rating 정보를 이용해서 로부터 gradient step만큼 학습했을 때 User 1의 query set에 속한 영화 rating을 잘 맞춤.
- User 2의 support set 속한 영화 rating 정보를 이용해서 로부터 gradient step만큼 학습했을 때 User 2의 query set에 속한 영화 rating을 잘 맞춤.
- User 3의 support set 속한 영화 rating 정보를 이용해서 로부터 gradient step만큼 학습했을 때 User 3의 query set에 속한 영화 rating을 잘 맞춤.
- ...
첫 번째 사용자는 세 개의 영화를 보았고, 그 중 두 개의 영화에 대해서는 긍정적으로 생각하고 있고 한 개의 영화는 부정적으로 생각하고 있습니다. 이와 같은 정보를 바탕으로 추천 모델의 파라미터를 학습했을 때, 이후 첫 번째 사용자가 볼 것 같은 영화를 잘 맞출 수 있게 됩니다. 두 번째 그리고 세 번째 사용자에게도 유사하게 생각할 수 있으며, 이를 통해 저희는 개별 사용자가 본 영화를 바탕으로 각 사용자에 맞는 추천 모델을 학습할 수 있다고 확신했습니다.
위와 같은 생각의 과정을 통해, 메타러닝 기반 모델이 저희가 풀고 싶은 "사용자 개개인에 꼭 맞는 추천시스템을 만들어 주자"는 문제에 적합한 모델이라고 생각했습니다.
Write down the solution
저희는 사용자에게 추천을 수행하는 모델을 아래와 같은 구조로 설계했습니다. 아래 그림에서 볼 수 있듯이, 추천 모델은 사용자 정보(좌측)와 아이템 정보(우측)를 입력받아, 해당 유저가 해당 아이템을 좋아할 지 싫어할 지를 예측하도록 구성했습니다.
저희는 추천 모델이 few-shot 환경에서도 잘 작동한다는 점을 강조하기 위해 초기 사용자에게도 모델이 잘 작동하도록 설계하고 싶었습니다. 이 때문에, 저희는 협업 필터링(collaborative filtering; CF) 기반 추천 모델이 베이스 모델에서 널리 사용하는 사용자 임베딩과 아이템 임베딩을 사용하지 않고, 아래 그림과 같이 사용자와 아이템의 features가 임베딩 되도록 모델을 설계했습니다. 저희 모델은 크게 3개의 layer로 구성되어 있습니다. 각각은 사용자와 아이템의 features를 입력받아 임베딩하는 embedding layer, 해당 정보를 합쳐주는 concatenate layer, 그리고 해당 사용자가 해당 아이템에 대해서 어떤 결정을 내리는지 예측하는 decision-making layer입니다.
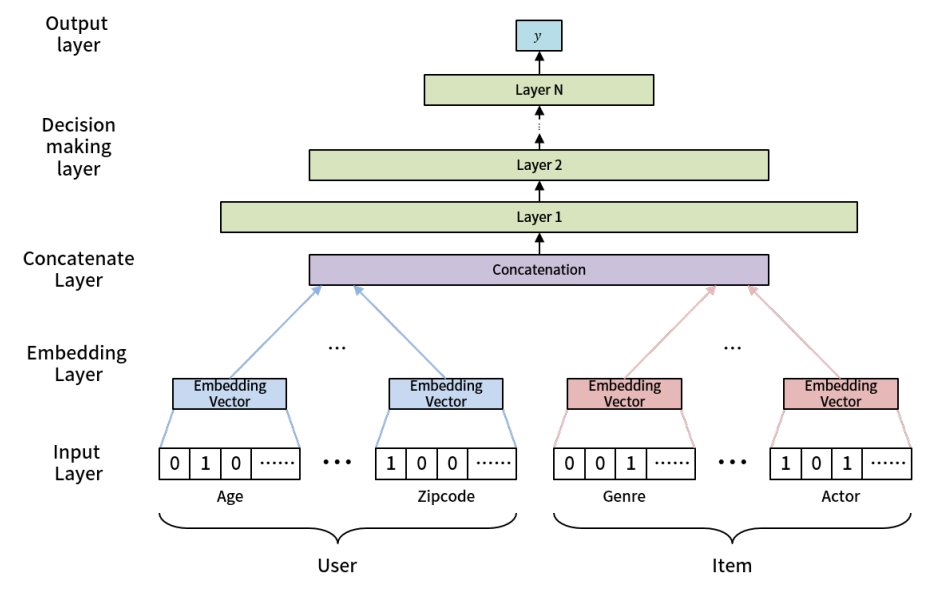 [그림 4] 사용자 추천 모델
[그림 4] 사용자 추천 모델
저희는 메타러닝을 적용하여 위와 같은 기본 모델이 각 사용자에 맞는 모델이 될 수 있도록 아래 그림과 같은 구조로 사용자 추천 모델을 학습 하였습니다. 각 사용자별로 기존에 본 아이템 셋(support set)과 이후에 볼 아이템 셋(query set)을 구분한 뒤, 기존에 본 아이템 셋을 바탕으로 decision-making layer만을 추가로 학습하여 이후에 볼 아이템을 잘 맞출 수 있도록 하였습니다. 조금 더 구체적으로 설명을 하자면, 저희는 사용자들이 기존에 본 아이템 셋을 기반으로 의사 결정을 다르게 한다는 가설로부터 시작했습니다. 앞선 예시에서처럼 '인터스텔라'라는 영화를 보고 감명을 받은 경우를 생각해보겠습니다. 해당 사용자는 이후에 볼 영화를 선택할 때 '인터스텔라'와 무관해지기 어려울 것입니다. 저희는 이게 사용자 또는 아이템의 본질이 바뀌었다기보다는 사람의 생각하는 과정이 변화한 것이라고 생각하고, 기존에 본 아이템 셋이 decision-making layer에만 영향을 주어 학습(local update)하도록 설계했습니다. (이와 같은 일부분만 모델을 업데이트 하는 방법은 이후 연구에서도 다뤄지고 있으며, 결과적으로도 좋은 방법이었던 것 같습니다. [2] 참고.)
모델의 초기 파라미터를 학습하기 위해, 저희는 기존에 본 아이템 셋을 이용하여 decision-making layer를 학습(local update)한 뒤 예측한 결과를 바탕으로 모델의 전체가 학습(global update)되도록 했습니다. 즉, 최적화 기반 메타러닝에서처럼, 저희가 제안하는 추천 시스템은 global update를 통해 추천 모델의 초기 파라미터를 학습하고, local update를 통해 각 사용자에게 맞는 추천 모델이 되도록 했습니다.
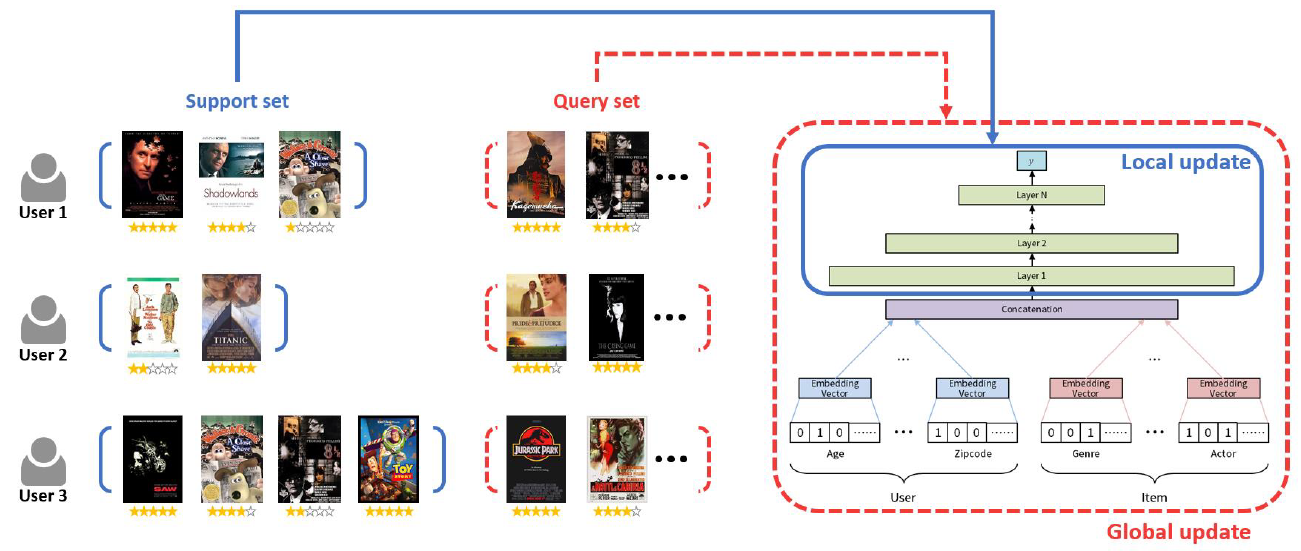 [그림 5] 제안 모델 구조
[그림 5] 제안 모델 구조
One more thing
초기 사용자에게 좋은 성능을 보이는 것에서 더 나아가서, 저희는 제안 모델이 사용자가 어떤 아이템의 선호도 평가를 하는 것이 좋을지에 대해서도 제시해줄 수 있을 것이라고 생각했습니다. 아래 그림과 같이 넷플릭스나 애플 뮤직 등과 같은 많은 추천 시스템에서는 사용자에게 영화와 음악 등을 추천하기에 앞서 사용자들의 선호를 파악하기 위해 몇 가지 아이템을 고르게 합니다. 저희는 아래와 같은 사용자 선호도 파악을 위한 아이템들이 단순하게 유명한 아이템을 제시하고 있다고 생각했고, 과연 이 아이템들이 사용자를 파악하는데 도움이 되는지에 대해서 의구심을 가졌습니다.
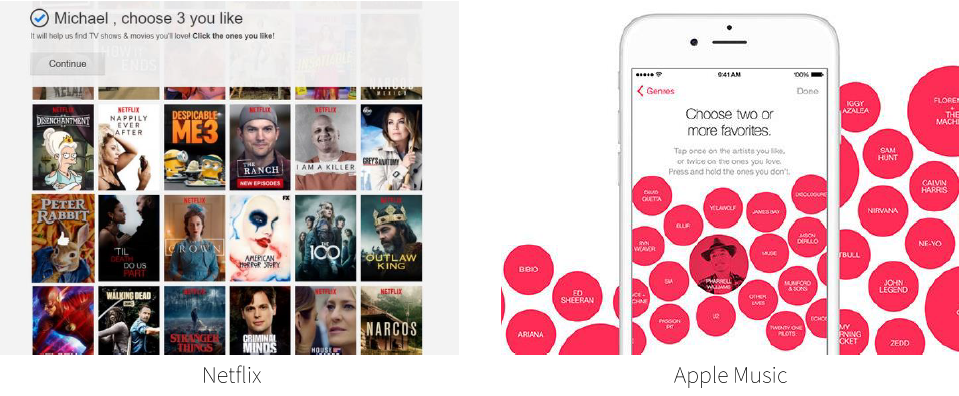 [그림 6] 사용자 추천을 위한 근거 수집 단계
[그림 6] 사용자 추천을 위한 근거 수집 단계
이런 의구심을 해결하기 위해, 저희는 다음과 같은 절차를 통해서 제안 모델을 바탕으로 사용자 선호도를 파악하기 위한 아이템을 선별했습니다.
- 각 아이템에 대해서, local update 시의 평균 Frobenius norm을 계산한다.
- 각 아이템에 대해서, 학습 데이터 셋 내에서의 popularity를 계산한다.
- 1과 2에서 계산한 값을 0과 1사이의 값을 갖도록 정규화(normalization)한다.
- 3에서 계산한 값을 곱하여, 각 아이템의 최종 score로 산출한다.
이와 같이 계산된 score를 바탕으로 값이 높은 20개의 아이템과, 유명한(popularity) 20개의 아이템에 대한 user study를 진행하였고, 저희가 제안한 방법이 사용자의 선호도를 파악하는데 더 도움이 되는 것으로 나타났습니다.
서비스 적용
저희는 이와 같이 개발한 추천 알고리즘을 저희 NC에서 운영중인 버프툰에 베타 서비스로 잠깐 운영했었습니다. 아쉽게도 현재는 해당 서비스를 이용할 수 없지만, 저희는 추천 알고리즘을 라이브 서비스에 적용하면서 새로운 Challenge를 발견하기도 했으며 지속적으로 알고리즘을 개선하기 위한 노력을 이어가고 있습니다.
 [그림 7] 버프툰 서비스로의 MeLU 적용
[그림 7] 버프툰 서비스로의 MeLU 적용
참고문헌
[1] Finn et al., 2017, Model agnostic meta learning for fast adaptation of deep networks, ICML.
[2] Raghu et al. 2020, Rapid Learning or Feature Reuse? Towards Understanding the Effectiveness of MAML, ICLR.
