
정렬 알고리즘(Sorting Algorithm)이란
데이터를 특정한 기준에 따라 순서대로 정렬하는 알고리즘입니다. 정렬은 많은 컴퓨터 과학 및 데이터 처리 작업에서 기본적이면서도 중요한 연산 중 하나입니다. 데이터를 정렬하면 검색, 삽입, 삭제 등의 연산이 빠르고 효율적으로 수행될 수 있습니다.
다양한 정렬 알고리즘이 개발되어 왔으며, 이러한 알고리즘들은 정렬 방법, 성능, 메모리 사용량 등의 다양한 측면에서 차이를 보입니다. 주요한 정렬 알고리즘 몇 가지를 간단히 소개하고자 합니다.
버블 정렬(Bubble Sort), 삽입 정렬(Insertion Sort), 선택 정렬(Selection Sort)은 간단하지만 기본적인 정렬 알고리즘 중에 하나로, 배열을 정렬하는 데 사용됩니다. 이들은 각각 다른 방식으로 요소를 비교하고 교환하거나 삽입하여 배열을 정렬합니다.
1. 버블 정렬 (Bubble Sort)
버블 정렬은 인접한 두 요소를 비교하고 조건에 따라 교환을 반복적으로 수행하여 정렬하는 알고리즘입니다. 가장 큰 값이 배열의 끝으로 이동합니다.
배열의 첫 번째 요소부터 시작하여 인접한 두 요소를 비교합니다.
만약 두 요소의 순서가 정상이 아니라면 교환합니다.
배열의 끝까지 이 과정을 반복하며, 가장 큰 요소가 맨 끝으로 이동합니다.
정렬이 완료될 때까지 위의 과정을 반복합니다.
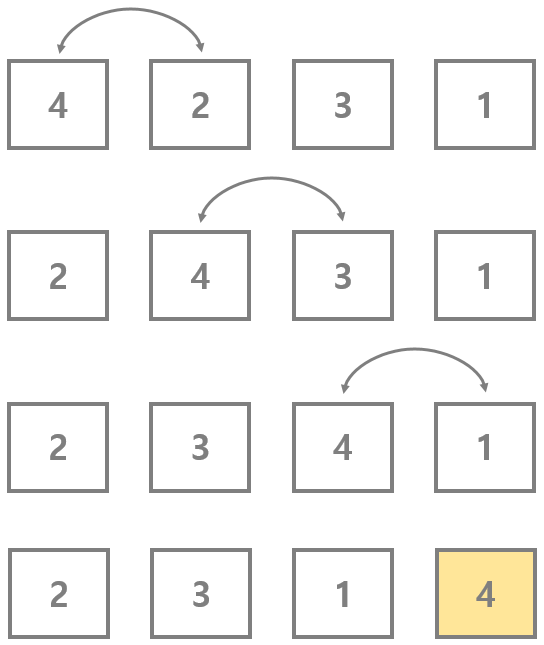
최선의 경우: O(n) - 이미 정렬된 배열에서는 교환이 발생하지 않을 수 있음.
평균 및 최악의 경우: O(n^2)
2. 삽입 정렬 (Insertion Sort)
삽입 정렬은 배열을 순회하면서 각 요소를 적절한 위치에 삽입하여 정렬하는 알고리즘입니다. 이미 정렬된 부분과 새로운 요소를 비교하면서 삽입을 수행합니다.
두 번째 요소부터 시작하여 현재 요소를 이미 정렬된 부분과 비교합니다.
적절한 위치를 찾을 때까지 이전 요소들과 비교하며 삽입합니다.
배열의 끝까지 위의 과정을 반복하여 정렬을 완료합니다.
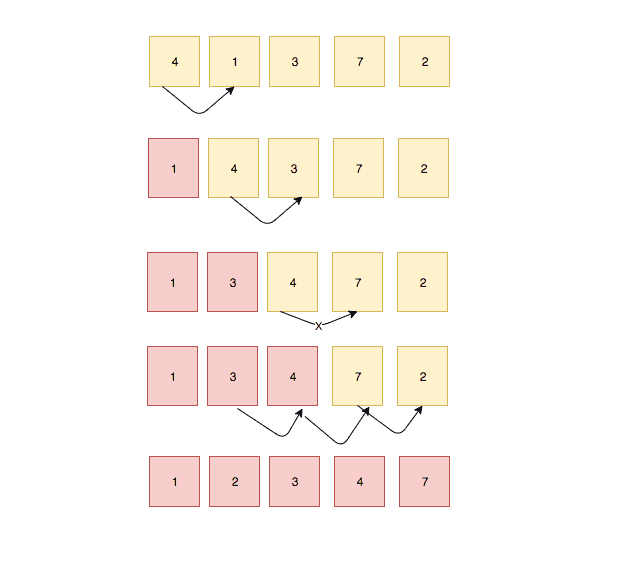
최선의 경우: O(n) - 이미 정렬된 배열일 때.
평균 및 최악의 경우: O(n^2)
3. 선택 정렬 (Selection Sort)
선택 정렬은 배열을 순회하면서 가장 작은 요소를 선택하여 맨 앞으로 이동시키는 과정을 반복하여 정렬하는 알고리즘입니다.
배열에서 가장 작은 요소를 찾아 맨 앞으로 이동시킵니다.
다음으로 작은 요소를 찾아 두 번째 위치로 이동시킵니다.
위의 과정을 반복하여 정렬을 완료합니다.

최선, 평균, 최악의 경우 모두 O(n^2)
이러한 정렬 알고리즘들은 기본적이고 이해하기 쉽지만, 대규모 데이터셋에 대해서는 효율적이지 않을 수 있습니다. 대량의 데이터를 다룰 때에는 효율적인 정렬 알고리즘들을 고려하는 것이 좋습니다.

성장하기위한 나만의 방법을 꾸준히 찾는중! 협동적 & 성실한 Frontend 개발자를 목표로…