
글또 활동하는데 이번 회차에서는 할만한 얘기도, 새로운걸 찾을 시간도 모잘랐어서...이전에 조사했던 내용들을 재구성해 작성해 보도록 하겠다. 글의 주제는 제목에서 알 수 있다시피 RabbitMQ이고, RabbitMQ에 대한 관심(사용해본 적 없는)이 있는 사람들을 위한 글이다.
서론
보통 백엔드 개발을 공부하기 시작하면, 가장 기초적인 MVC 부터 시작하고, 여기에 CRUD를 연습, 그리고 RESTful API에 대한 이야기를 하면서 진행된다. 여기에 영속성을 위한 데이터베이스의 개념이 여러가지 첨부되면, 가장 기본적인 웹 서비스 하나를 만들기 위한 준비가 끝난다. 하지만 이후 요구사항과 사용자에게 제공되는 기능이 더 복잡해지면, 하나의 서버에서 처리를 하는데 문제가 발생하기도 한다.
예를들면 백준 온라인 저지와 같은 알고리즘 문제풀이 사이트들. 이런것들도 전부 한 서버 에플리케이션에서 처리하는게 불가능하지 않다. 어떤 식으로든 사용자의 코드를 전달받고, 그 코드를 서버에서 실행하면 되니까. 하지만 문제는 이 과정을 본래의 방식으로 구현하면, 몇명의 사용자만 동시에 요청하더라도 금세 서버의 응답시간이 증가하는 것을 경험할 수 있을 것이다. 사용자의 요청을 처리하는 과정 사이에, 코드를 컴파일, 실행, 결과 비교, 기록이라는 길고 복잡한 작업이 같이 진행되기 때문이다.
이러한 문제상황을 가장 간단하게 해소하는 방법은 비동기로 처리하는 것이다. 즉, 사용자가 실행할 코드를 전송하면, 해당하는 코드가 들어왔다는 사실을 비동기로 처리하자고 기록한 다음, 사용자에게는 접수 완료 메시지를 보내는 것이다. 이렇게 되면 사용자는 바로 응답을 받을 수 있고, 서버는 다른 사용자의 요청을 처리해줄 수 있으며, 비동기로 처리하기로 한 코드 실행 작업은 다른 프로세스나 스레드에서 처리해줄 수 있다.
BOJ에서도 제출하자 마자 체점이 끝나는 것이 아니라, 먼저 사용자를 제출 창으로 이동시킨 다음, 놀고있는 자원이 있을 때 순서대로 처리하게 된다.
Spring 처럼 프레임워크나 언어 차원에서 자체적으로 비동기 처리를 지원하는 경우도 있겠지만, 이 경우 결국 애플리케이션이 실행 중인 서버의 자원을 활용한다는 한계가 존재한다. 또한 Micro Service Architecture의 발전과 유행은 여러 작은 서비스로 나눠서 기능을 만드는 것을 권장하게 되었다. 그러면서 서비스 간에 비동기 통신을 위해, 여러가지 미들웨어(Middleware), 그중에서도 프로세스 간 메시지를 주고받기 위해 큐를 사용하는 Message Queue들을 사용하게 되었다.
개인적으로 아쉬운점은, 어느 시점부터인가 한국에서는 거의 대부분의 개발자들이 Kafka만 이야기하는 것 같은 느낌이 들기 시작한다는 것이다. 대부분의 커리큘럼도 세일즈포인트가 Kafka에 맞춰져 있고 다른 도구들은 거의 언급도 되지 않는것 같은 기분이다. Message Queue에 초점을 맞춰보면, 오히려 용도 자체는 다른 쪽으로 더 많이 활용하는 Redis의 기능을 활용해서 Message Queue를 사용하는 케이스를 더 찾기 쉬운 느낌이다. 그리고 반대로 즐겁게 사용해 왔던 RabbitMQ에 대한 이야기는 거의 쏙 들어갔다.
물론 Kafka가 같은 목적으로 사용되는 미들웨어 중 성능적으로 가장 뛰어난건 부정하기 어렵지만, 솔직히 작은 프로젝트에서 사용하기에는 초기 설정부터 실제 기능 구현까지 지나치게 복잡성이 높은 느낌이 강했다. 해외에서는 Kafka냐 RabbitMQ냐라는 주제에서, "Kafka의 성능이 짱이다!" 보다는 "Kafka와 RabbitMQ의 Use Case는 다르다"의 측면에서 접근하는 경향도 많이 있다. 특히 Kafka를 다루는 매체들을 보면, Kafka는 메시지를 전달하는 것 보다는 메시지를 안정적으로 기록하고, 다시 실행(replay)하는 것에 측면을 많이 맞춘다고 생각된다.
둘의 첫인상을 한마디로 비교하면,
- Kafka는 메시지를 어떤 방식으로 보관하고 들을지
- RabbitMQ는 메시지를 어떻게 누구에게 보낼지
에 초점이 맞춰진것 같다고 느꼈다.
어쨋든 나는 RabbitMQ를 즐겨 사용해 왔었고, 솔직히 Kafka에 비하면 배우기도 쉽고 구성해 보는것도 간단하다고 생각한다. 또한 비동기로 요청을 처리하기 위해 프로세스간 메시지를 주고받게 해주는 미들웨어로서의 역할에 제일 충실한 미들웨어라고 생각한다. 그래서 옛 기억을 떠올리며 RabbitMQ를 입문하는데 이해를 돕기 위한 이 글을 작성해보고자 한다. 기술적인 부분(어떤 언어로 만들었다, 성능은 어느정도다)보다는 추상적으로, 그냥 한번 사용해볼 때 알아둘 만한 것들에 초점을 맞추고자 한다.
4.0이 나왔지만, 글은 3.X를 사용한다.
RabbitMQ 기본 개념
RabbitMQ는 AMQP 통신을 기반으로 여러 소프트웨어간 메시지를 주고받게 해주는 메시지 브로커(Message Broker)의 일종이다. 프로세스간 비동기 통신을 하고 싶을 때 대표적으로 사용하며, 이를 통해 오래 걸리는 작업을 여러 프로세스에 분배하여 처리할 수 있게 해준다.
컴퓨터에 Docker가 설치되어 있다면, 매우 간단하게 설치하고 사용해볼 수 있다.
docker run -it --rm --name rabbitmq -p 5672:5672 -p 15672:15672 rabbitmq:3.13-management이렇게 설치된 RabbitMQ의 경우 메시지를 주고받는 RabbitMQ 본체와 함께 RabbitMQ를 관리하기 위한 관리자 콘솔을 같이 제공해준다. 실행 후 http://localhost:15672로 가보면 확인할 수 있다. 기본 아이디 비밀번호는 3.13 기준 guest, guest이다. 이 경우 외부 서버에서는 접근이 불가하다.
Producer & Consumer
우리가 HTTP 서버를 만드는 프레임워크를 배우면 알게되는 Client-Server 관계의 메시지 브로커 버전이다. RabbitMQ도 메시지 브로커이기 때문에, Producer와 Consumer를 연결해주는 역할을 한다고 할 수 있다.
Producer는 Client-Server 구조의 Client 역할을 한다고 볼 수 있다. 비동기로 처리해야할 일, 또는 언젠가는 확인해야 할 작업 또는 메시지를 만들고(Produce), 브로커에 적재하는 역할을 한다.
Consumer는 Client-Server 구조의 Server 역할을 한다고 볼 수 있다. 메시지 브로커에 메시지가 들어오면, 해당 메시지를 기다리고 있던 Consumer가 메시지를 소모(Consume)하고, 메시지 브로커에 알린다.

Client-Server와 다른 점은, 메시지 브로커가 있고, 메시지 브로커가 메시지를 보관해 주기 때문에, 메시지가 만들어지는 시점과 메시지가 소모되는 시점이 동시에 일어날 필요가 없다는 것이다. 즉 비동기로 메시지를 전송할 수 있다는 의미. 전화와 문자로 비교를 하자면, 전화 통화를 위해선 발신자와 수신자가 둘다 전화기에 가까이 있어야 하지만 문자는 보냈다고 바로 확인할 필요가 없다는 것과 비슷하다.
RabbitMQ는 특히 Producer가 생성한 메시지를 어떤 Consumer에게 전달할지를 결정하는 방법을 다양하게 제공한다. 여러 Consumer 중 하나에게만 메시지를 전달할 수도, 모든 Consumer에게 같은 메시지를 전달할 수도 있다.
Queue와 Exchange
RabbitMQ는 Producer가 만든 메시지를 특정 Consumer에게 보내기 위해 Queue와 Exchange라는 개념을 사용한다.
Queue는 RabbitMQ에서 메시지를 저장하는 공간으로, 동명의 자료구조 처럼 선입선출(First In First Out)의 형태로 동작한다. 즉 Queue에 쌓인 메시지는, Queue에 쌓인 순서데로 소모된다.
Queue에 메시지를 전달하는 역할을 하는게 Exchange이다. Queue를 생성하면 어떤 Exchange와 관계를 맺을지를 결정할 수 있고, 이를 Binding이라고 부른다. Producer는 Queue가 아니라 Exchange에 메시지를 작성하고, Exchange는 메시지에 따라 어떤 Queue로 메시지를 적재할지를 결정하게 된다.
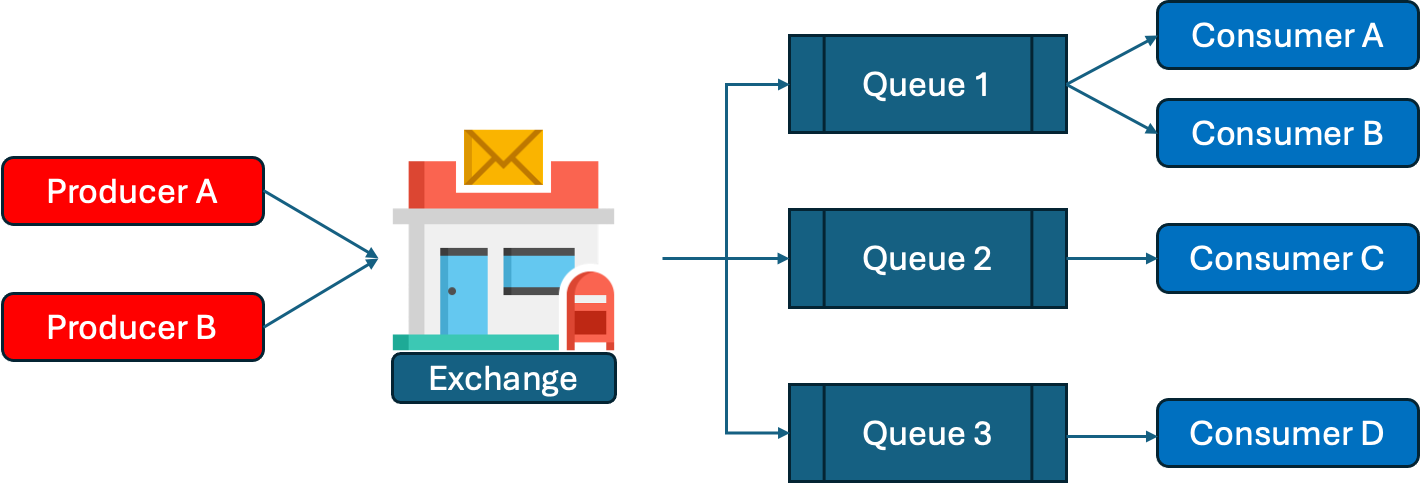
Exchange와 Queue의 관계는 말하자면 우체국과 우체통의 관계와 비슷하다고 생각할 수 있다. 우리가 편지나 택배를 보내고 싶다면 우체국에 가지, 우체통을 찾아가지 않는다. 큰 잡지 회사라면 직접 기사를 고용해 잡지를 배달할 수도 있겠지만, 우체국 같은 운송 사업자를 통해 보내는게 더 일반적일 것이다. 즉, RabbitMQ를 사용하는 우리는 Exchange라는 우체국에 메시지를 보내고, Exchange는 메시지를 살펴보고 적당한 우체통인 Queue들에 보내는 것이다. 하지만 우리는 우체통의 편지를 순서대로 확인하지는 않는다.
Exchange와 Queue는 처음 RabbitMQ를 접할 때 가장 햇갈렸던 부분이다. 특히 RabbitMQ는 Message Queue이기 때문에, RabbitMQ는 하나의 Queue를 가지고 있다고 착각했었다. 하지만 실제로는 RabbitMQ는 Message Queue로 분류되는 소프트웨어(미들웨어)의 일종이고, 그 안에서 메시지를 보내는 방식을 정의하기 위해 Queue라고 하는 개념을 가지고 있었던 것이다.
이 부분을 이해하면 상대적으로 RabbitMQ의 나머지 기능들이 좀더 쉽게 이해된다고 생각한다. 다만 역으로 아직 기능도 살펴보기 전에 불필요한 개념을 익히는 부분도 없지 않다는게....아마 공식 튜토리얼에서는 처음에 설명하지 않은 것이라 생각된다.
Exchange의 개념은 오롯이 RabbitMQ의 것이 아닌 AMQP 프로토콜의 일부분이다.
다음은 Queue와 Exchange에 대한 몇가지 이야기.
- Queue와 Exchange, 그리고 그 관계인 Binding은 관리자 콘솔에서 만들 수 있지만, 대부분의 라이브러리들이 만드는 기능을 포함한다.
- Producer는 일반적으로 Queue에 직접 메시지를 전하지 않는다.
- 하나의 Queue에 여러 Consumer가 연결될 수 있다.
- Exchange와 Queue의 Binding은 N:M 관계로 연결된다.
- Queue를 만들고 Exchange와 연결하지 않아도 Default Exchange와 기본적으로 Binding이 만들어진다.
RabbitMQ 활용법
RabbitMQ는 Queue와 Exchange의 개념을 활용해 굉장히 복잡한 형태로 메시지를 전달하는 것을 가능하게 한다. 이 글에서는 가장 간단한 두 형태인 Competing Consumers Pattern과 Publish Subscribe Pattern만 살펴보자. 또한 복잡한 설정들은 이 글에서는 다루지 않는다.
Python pika 라이브러리를 활용한 예시를 사용한다.
Competing Consumer Pattern
제목에 쓰인 용어 자체는 Enterprise Integration Patterns에 소개된 말을 기반으로 사용했고, 일반적으로는 같은 형태의 구조를 Task Queue, Job Queue, Worker Queue 등 다양한 명칭으로 불리는 것 같다. (책 내용)
Competing Consumer Pattern은 아마도 가장 기본적으로 비동기 처리를 찾는 이유일 것이라고 본다. 사용자의 요청(메시지)가 서버가 처리를 할 수 있는 속도보다 빠르게 만들어진다면, 메시지를 여러 경쟁하는 소비자들에게 위임하는 메시징 패턴의 일종이다.
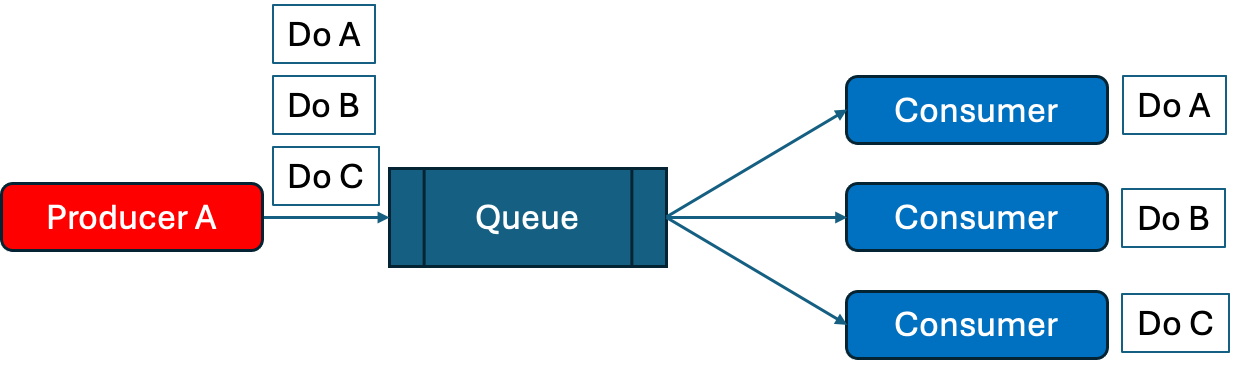
RabbitMQ에서는 이를 다음과 같은 과정을 통해 진행한다.
- 메시지를 균등하게 보낼 Queue의 이름을 정해서 생성한다.
- 해당 Queue의 메시지를 들을 Consumer역할의 프로세스를 여러개 실행한다.
- Producer는 Queue의 이름을 지정해서 메시지를 보낸다.
Competing Consumer는 Consumer를 구분하지 않고 하나의 Queue에서 여러 같은 역할의 Consumer가 경쟁적으로 메시지를 가져가야 한다. 그래서 Exchange의 역할이 크게 필요 없기 때문에 Default Exchange로 진행할 수 있다.
Producer
먼저 Producer 코드를 살펴보자. 작성하면서 Queue의 생성을 같이 할 것이다. Queue의 생성은 Producer도 Consumer도 할 수 있는데, 기본적으로 멱등성을 가지기 때문에 누가 먼저 하던 하나의 Queue만 만들어진다.
# pika 라이브러리를 사용한다.
import pika
# 기본 설정으로 연결한다.
connection = pika.BlockingConnection(pika.ConnectionParameters("localhost"))
channel = connection.channel()
# 사용할 큐를 선언한다.
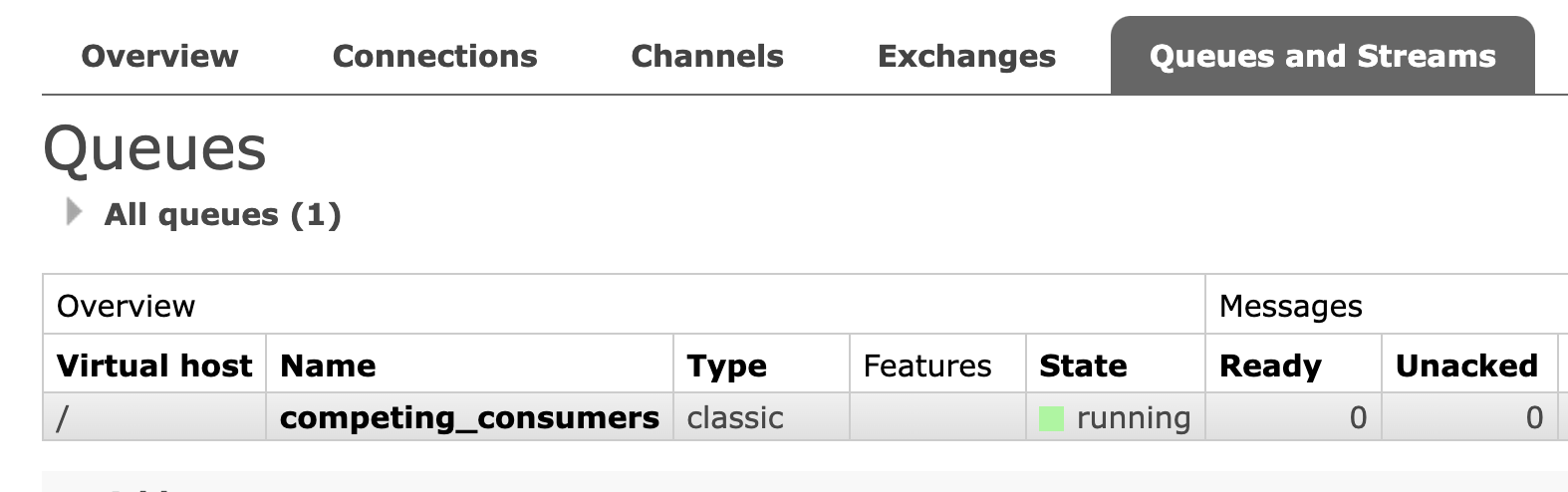
channel.queue_declare(queue="competing_consumers")만들어진 Queue는 "Queues and Streams" 탭에서 확인 가능.
이후 우리가 원하는데로 메시지를 보내기 위한 간단한 반복문으로 메시지를 보내는 부분을 감싸주자. 메시지를 보낼 때는 앞에서 만든 channel의 메서드를 활용한다.
print("enter message (or 'quit' to exit)")
while True:
# 입력을 받는다.
message = input("message: ")
if message == "quit":
break
# 위에서 만든 channel의 basic_publish메서드로 메시지를 보낸다.
channel.basic_publish(
# Default Exchange는 지정하지 않아도 된다.
exchange="",
# 지금은 어떤 Queue에 메시지를 보낼지를 의미한다고 생각하면 된다.
routing_key="competing_consumers",
# 보내는 메시지 부분이다.
body=message,
)
print("Goodbye")RabbitMQ를 기본 설정으로 실행했다면, 정상적으로 실행되고 메시지를 보낼 수 있다.
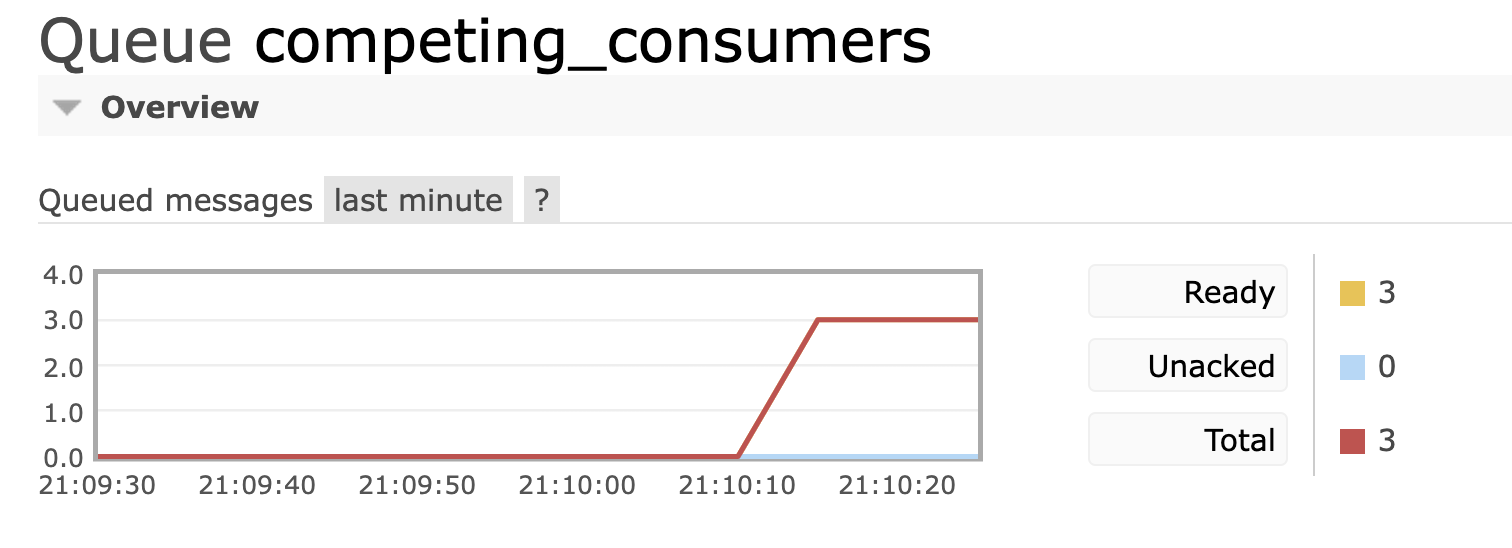
그리고 관리자 콘솔 확인하면 메시지가 적재되어 있음을 볼 수 있다.
Consumer
이제 Consumer를 본다. 연결하는 부분, Queue를 만드는 부분은 동일한데, main으로 감싸주고 정상 종료를 위해 KeyboardInterrupt를 잡아주도록 하였따. Consumer는 사용자가 종료하거나 문제가 생기기 전까지 종료되지 않기 때문이다.
import sys
import pika
# ...중략...
if __name__ == '__main__':
try:
# Producer와 똑같다.
connection = pika.BlockingConnection(pika.ConnectionParameters("localhost"))
channel = connection.channel()
channel.queue_declare(queue="competing_consumers")
# 정상 종료를 위해 사용자 종료 입력을 잡아준다.
except KeyboardInterrupt:
print("Goodbye")
sys.exit(0)이후 except 줄 이전에 Producer가 보낸 메시지를 받는 부분을 만들건데, 이를 위해서 Callback 함수를 만들어야 한다.
# ...중략...
def callback(ch, method, properties, body):
# 다른건 지금 신경쓰지 말고,
# body(네번쩨 매개변수)에 메시지가 들어오는 것만 알아두자.
print(f"received: {body}")
# ...중략...그러면 Producer와 마찬가지로 channel의 메서드를 이용해 메시지를 듣기위해 대기할 수 있다.
# ...중략...
if __name__ == '__main__':
try:
connection = pika.BlockingConnection(pika.ConnectionParameters("localhost"))
channel = connection.channel()
channel.queue_declare(queue="competing_consumers")
# channel의 basic_consume 메서드다.
channel.basic_consume(
# 지금은 어떤 Queue의 메시지를 들을지를 의미한다고 생각하면 된다.
queue="competing_consumers",
# 메시지가 왔을 때 어떤 동작을 할것인지.
on_message_callback=callback,
# 메시지를 잘 받았다고 RabbitMQ에 알린다.
auto_ack=True
)
print("Waiting for messages...")
# 이제부터 메시지를 듣기 시작한다.
channel.start_consuming()
except KeyboardInterrupt:
print("Goodbye")
sys.exit(0)이후 실행해보자. 아까 메시지를 보내두었다면 실행하자 마자 메시지를 받을 것이다.
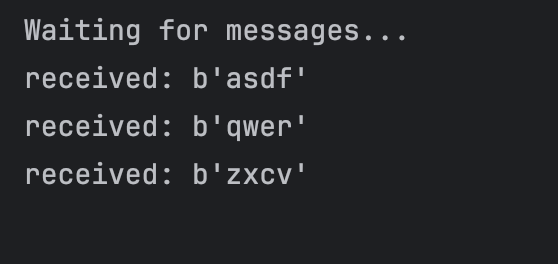
여기서 알 수 있는것이, Producer가 메시지를 보내는 것은 Consumer의 유무랑 상관 없다는 것이다. Producer는 메시지를 RabbitMQ에 전달하면, RabbitMQ는 메시지를 들고 있다가 그 메시지를 처리할 Consumer가 생기면 전달만 하면 되는 것이다. 비동기 통신의 한 모습을 확인하는 것이다.
여러개의 Consumer 실행해보기
Competing Consumer는 여러개의 Consumer가 실행중이라면, 유휴한 Consumer가 먼저 Queue의 메시지를 가져간다. 한번 여러개의 Consumer를 실행해서 테스트 해보자.
필자는 Pycharm CE를 사용중이다. Run Configuration을 활용하면 하나의 Python 스크립트를 동시에 실행할 수 있다.
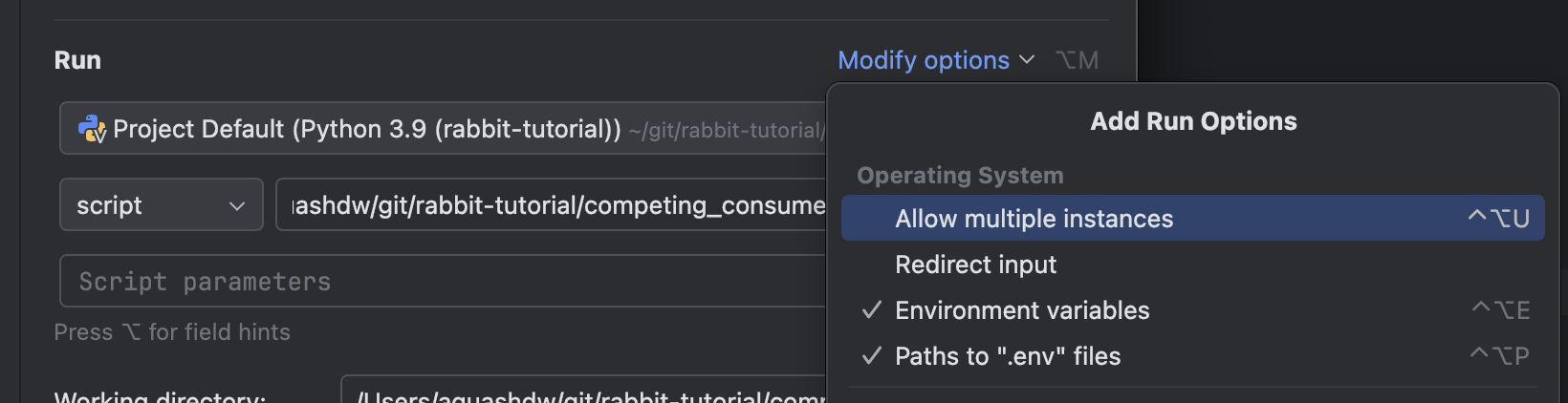
이후 Producer에서 여러 메시지를 순서대로 보내보면,
서로 다른 Consumer가 하나씩 가져가는걸 볼 수 있다!
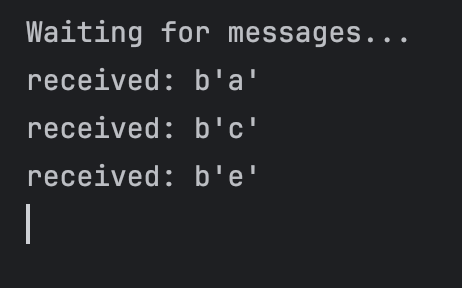
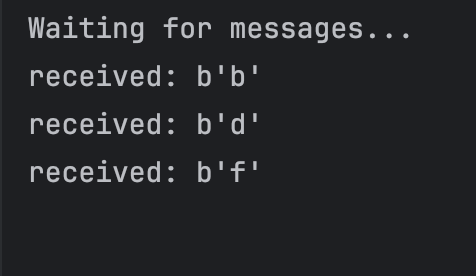
매우매우 간단한 형태의 Competing Consumer라고 볼 수 있겠다. 이제 Consumer 쪽은 오래 걸리는 작업을 처리하는 코드를 작성하면, 서버의 부하를 여러 Consumer에게 배분하는 간단한 분산 처리가 가능할 것이다.
가장 기본 설정으로 진행하는 경우 기본적으로 Round Robin 알고리즘을 활용하게 된다. 만약 다른 형태로 메시지를 배분하고 싶다면 공식 문서와 튜토리얼을 확인해보자.
Publish Subscribe Pattern
Publish Subscribe Pattern(이하 Pub-Sub 패턴이라고도 부른다)은 Competing Consumers Pattern과 다르게 많은 Consumer가 같은 메시지를 들어야 하는 상황에서 활용할 수 있다. 구독 취소, 로그아웃 등 여러 서비스에 영향을 미치는 사건이 발생할 경우, 그 모든 서비스에 사건을 전파하는게 목적이라 할 수 있다.
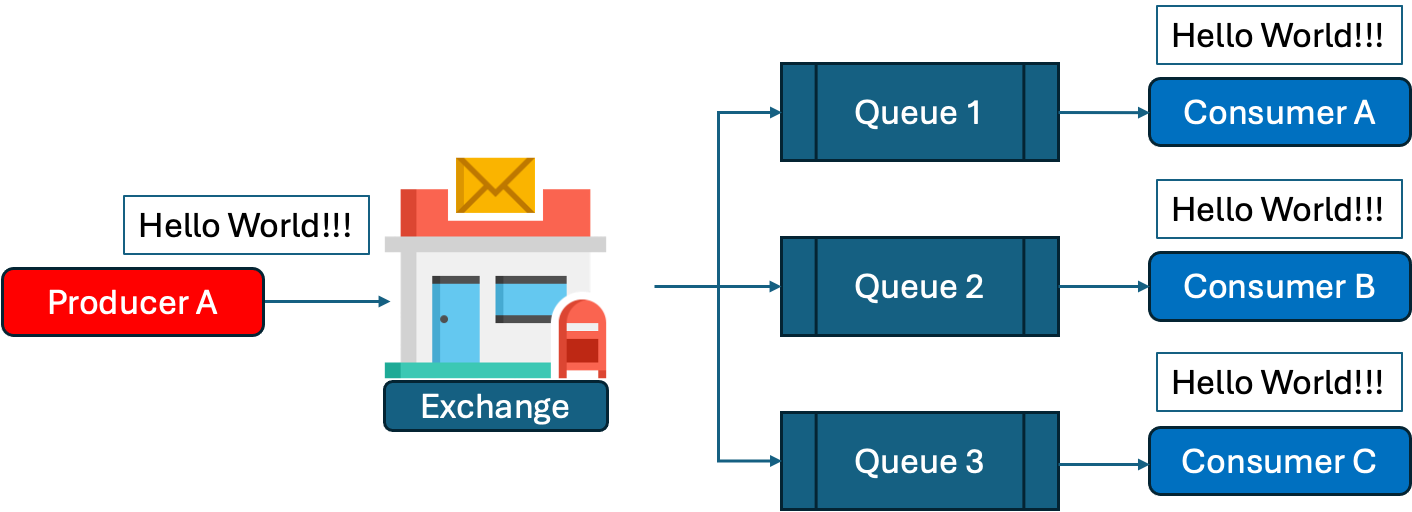
이 경우 Producer를 Publisher, Consumer를 Subscriber라고 하기도 하는데, 굳이 분류를 해보면 RabbitMQ의 기술적인 관점에서는 여전히 Producer / Consumer, Pub-Sub 패턴의 논리적인 관점에서는 Publisher / Subscriber라고 하는게 맞으니....결국 둘다 맞는말?!
사실 RabbitMQ는 Exchange의 종류가 다양하게 있는데, 이를 이용해 매우 복잡한 Pub-Sub을 구현할 수도 있다. 하지만 지금은 그냥 맛보기를 위해 가장 단순한 Fanout Exchange를 사용하기로 한다. Fanout Exchange는 생성된 메시지를, Binding된 모든 Queue에 차별 없이 동일하게 전송하는 Exchange이다. 이를 이용해 Pub-Sub 패턴을 구현한다면,
- 사용할 Fanout Exchange를 만든다.
- Consumer가 실행되면서, 각각 Fanout Exchange와 Binding한 Queue를 생성한다.
- Producer는 Fanout Exchange에 메시지를 보낸다.
이렇게 진행할 경우 Producer의 메시지는 Fanout Exchange에 연결된 모든 Queue에 복사되어 전달될 것이고, 그 결과 모든 Consumer가 메시지를 들을 수 있을 것이다. 이런 구조라면 Producer는 Publisher이고, Consumer는 Subscriber라고 부를만 하겠다.
Publisher
앞서 Competing Consumers의 Producer를 만드는것과 유사한데, 이번에는 Queue가 아닌 Exchange를 선언한다.
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters("localhost"))
channel = connection.channel()
# queue 대신 exchange이다.
channel.exchange_declare(
# 이름
exchange="notice",
# 종류
exchange_type="fanout"
)메시지를 보낼 때도 비슷하지만 인자가 조금 다른데, Queue를 지정하는 대신 Exchange를 지정하고, 그에 따라 routing_key가 사라진다.
print("enter message (or 'quit' to exit)")
while True:
message = input("message: ")
if message == "quit":
break
# 사용하는 메서드는 동일하다.
channel.basic_publish(
# 어떤 Exchange에 보낼지 (이전엔 공백)
exchange="notice",
# 원래 여기 Queue 이름이 있었다.
routing_key="",
body=message,
)
print("Goodbye")routing_key는 다른 Exchange에서 사용하는데, Fanout 같은 경우는 연결된 Queue에 차별없이 메시지를 보내기 때문에 지금은 채워주지 않는다.
마찬가지로 실행 후 관리자 콘솔을 확인해보자. "Exchanges" 탭에서 확인할 수 있다. 그 외에 기본으로 만들어지는 다양한 Exchange도 볼 수 있다.
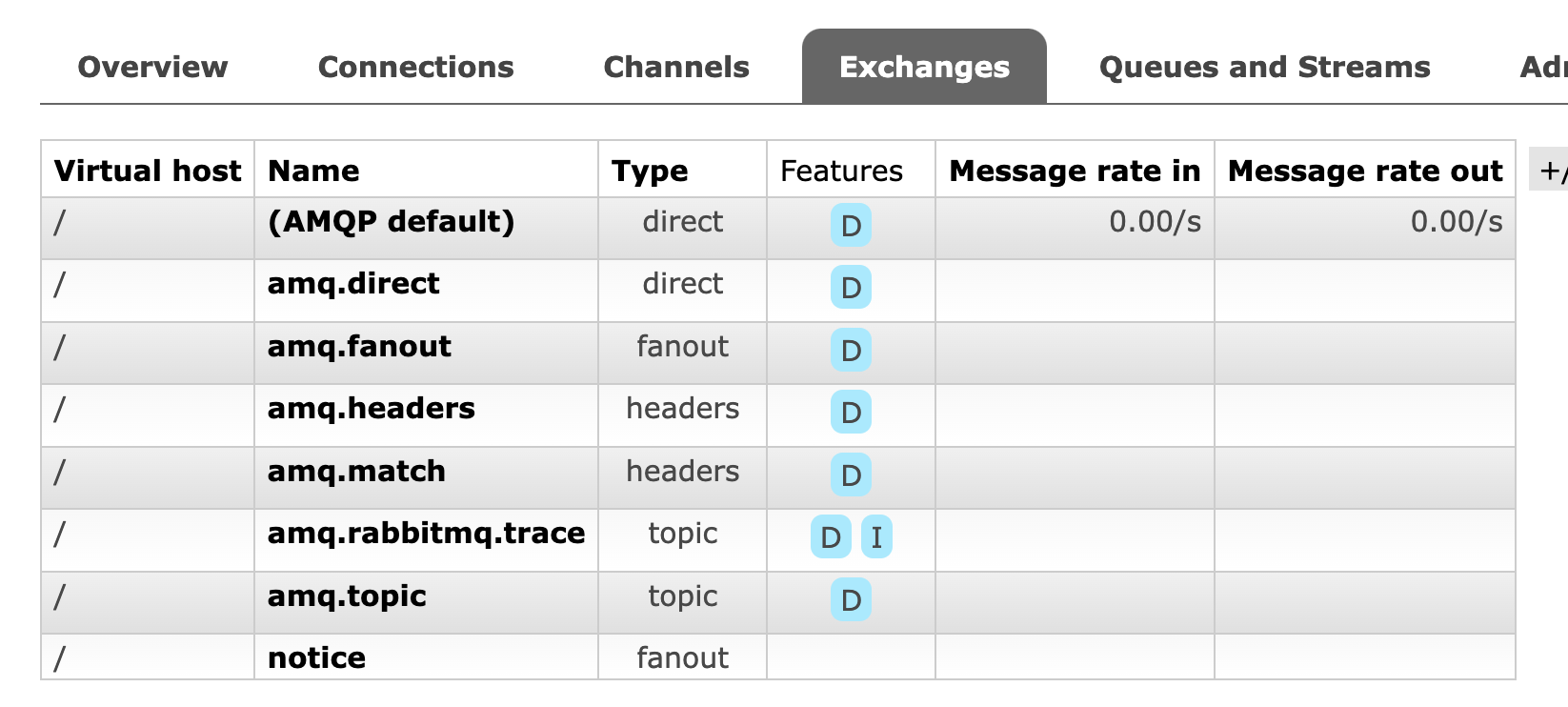
메시지도 잘 보내질 것이지만...차이점이 존재한다. 이는 Subscriber를 만들면 확인할 수 있다.
Subscriber
이것도 마찬가지로 이전의 Consumer와 비슷하게 시작하는데, Callback까지 포함하면 channel을 만드는 과정은 이전과 동일하다.
# 전과 같은 코드다!
import sys
import pika
def callback(ch, method, properties, body):
print(f"received: {body}")
if __name__ == '__main__':
try:
connection = pika.BlockingConnection(pika.ConnectionParameters("localhost"))
channel = connection.channel()
# 여기에 새로운게 들어갈거다.
except KeyboardInterrupt:
print("Goodbye")
sys.exit(0)그 다음은 Publisher와 똑같이 Exchange를 만드는 부분이다. 마찬가지로 멱등성을 가지기 때문에 신경쓸 필요 없다.
# ...중략...
if __name__ == '__main__':
try:
connection = pika.BlockingConnection(pika.ConnectionParameters("localhost"))
channel = connection.channel()
# ...이것도 거의 똑같다. Queue만 Exchange가 되었다.
channel.exchange_declare(
exchange="notice",
exchange_type="fanout",
)
except KeyboardInterrupt:
print("Goodbye")
sys.exit(0)그 다음, 이번에는 Queue를 만들되 Queue의 이름을 우리가 직접 지정하지 않을 것이다. Pub-Sub 패턴에서 Subscriber는 매우 많이 존재할 수 있고, RabbitMQ를 쓴다면 그 Subscriber마다 Queue를 만들어야 함으로 이름 수기로 정했다가는 무슨일이 벌어질 지 모른다!
# ...중략...
if __name__ == '__main__':
try:
connection = pika.BlockingConnection(pika.ConnectionParameters("localhost"))
channel = connection.channel()
channel.exchange_declare(
exchange="notice",
exchange_type="fanout",
)
# 그래서 exclusive=True를 사용해준다.
result = channel.queue_declare(queue="", exclusive=True)
# 그러면 반환된 값에 만들어진 Queue의 이름이 담겨있다.
queue_name = result.method.queue
# 그리고 그 Queue를 Exchange에 Binding 해준다.
channel.queue_bind(exchange="notice", queue=queue_name, )
except KeyboardInterrupt:
print("Goodbye")
sys.exit(0)메시지를 듣는 부분은 똑같다. 만들어진 Queue의 메시지를 듣겠다고 basic_consume을 써주면 된다. Queue 이름 부분만 반환받은 그 이름을 사용해준다.
# ...중략...
if __name__ == '__main__':
try:
connection = pika.BlockingConnection(pika.ConnectionParameters("localhost"))
channel = connection.channel()
channel.exchange_declare(
exchange="notice",
exchange_type="fanout",
)
result = channel.queue_declare(queue="", exclusive=True)
queue_name = result.method.queue
channel.queue_bind(exchange="notice", queue=queue_name, )
# 그 모든 일을 겪고 나서도, 여전히 너다.
channel.basic_consume(
queue=queue_name,
on_message_callback=callback,
auto_ack=True
)
print("Waiting for messages...")
channel.start_consuming()
except KeyboardInterrupt:
print("Goodbye")
sys.exit(0)얘도 한번 실행해보자.
재밌는건 Competing Consumer와 다르게, Publisher를 만들고 메시지를 보내도 Subscriber는 조용하다. Subscriber가 실행되기 전이라면 Exchange에 연결된 Queue가 없고, 연결된 Queue가 없으므로 메시지를 보낼 곳이 없었으므로 메시지가 버려지는 것이다!
여러개의 Subscriber 실행해보기
이제 앞에서 Consumer를 여러개 실행했듯 Subscriber도 여러개 실행해보자.
그리고 Publisher에서 메시지를 만들면...
실행중인 모든 Subscriber가 그 메시지를 들을 수 있을 것이다!
서로 다른 탭에서 확인했음에도 같은 메시지가 있는걸 확인해보자.
아주 간단하게 Publish Subscribe를 구현해 보았다. 앞서 이야기한 것처럼 여러 서비스에서 공통되게 알아야 하는 이야기를 전달하기에 적절한 형태의 메시징 패턴이다. 여기서 RabbitMQ가 제공하는 다양한 Exchange를 활용하면, 특정 메시지만 취사 선택하는 것도 가능하다. 궁금하면 문서를 살펴보자.
마무리
오랜만에 RabbitMQ를 다시 살펴보았다. 오랜만이라고는 하지만 지금 하고 있는 사이드 프로젝트에서도 사용하고 있고, 여전히 많은 Use Case가 있다고 본다. 특히 RabbitMQ의 단순함은 Kafka는 쉽게 도달하기 어렵다고 생각된다. 물론 Kafka의 성능이 뛰어날 수도 있지만, 그만큼 고성능과 일관성이 없어도 된다, 단순 요청-응답 수준의 메시지 전송 체계가 필요하다 하면 큰 고민 없이 도입해볼 수 있는 미들웨어라고 여전히 생각한다. 오래 걸릴것도, 깊게 파야할 것도 아니니 심심한 어느 하루 내 언어와 프레임워크가 지원하는 RabbitMQ 클라이언트를 찾아보자.
