Fundamental 15. 딥러닝 들여다보기
♣ 오늘은 TF Master 발표준비 관계로 오전에 15.4절까지만 살펴본 후 포스팅하겠습니다.
♣ 급작스러운 Exploration 제출 관련 문제로 오늘은 15.4절까지만 포스팅하겠습니다.
잔여 부분은 주말을 이용하여 다루도록 하겠습니다.
★15.2~15.4절★
- 우리 뇌에 있는 약 1000억 개에 가까운 신경계 뉴런들이 서로 복잡하게 얽혀있고, 나아가 하나의 거대한 그물망과 같은 형태를 이루고 있는데, 이를 신경망(Neural Network) 이라고 한다.
- 우리 뇌 속의 신경망 구조에 착안한 퍼셉트론(Perceptron) 형태를 제안하며 이를 연결한 형태를 인공신경망(Artificial Neural Network)이라고 부른다.
- 머신러닝의 대표적인 데이터셋인 MNIST를 딥러닝 프레임워크의 코드 몇 줄 정도로 99% 이상의 정확도로 분류할 수 있는 분류기를 만들 수도 있다.
<4~6> 아래 그림은 다층 퍼셉트론의 도식이다.
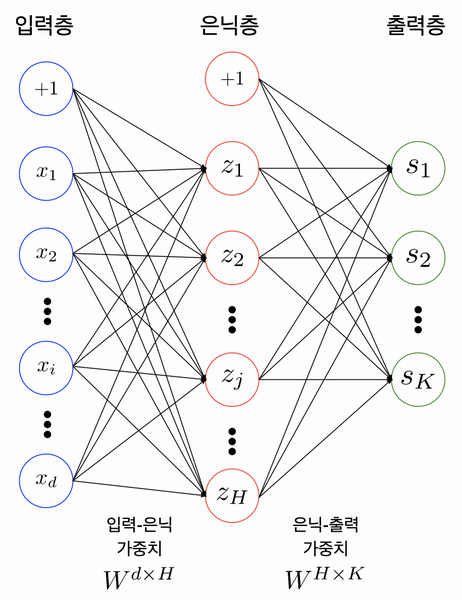
4. 위와 같은 다층 퍼셉트론은 실제로 총 2개의 레이어를 가지고 있다(2층 퍼셉트론). 레이어 개수를 셀 때는 노드와 노드 사이에 연결하는 부분이 몇 개인지를 파악하면 된다.
5. 위의 도식과 같이 입력값이 있는 입력층, 최종 출력값이 있는 출력층을 제외하고 사이에 존재하는 모든 층은 은닉층이라고 칭한다.
6. 입력층과 출력층 사이에 속하는 은닉층의 개수가 많아질수록 인공신경망이 'Deep' 해졌다고 간주할 수 있다.
7. 딥러닝은 충분히 깊은 인공신경망을 활용하여 DNN(Deep Neural Network)라고도 한다.
8. Fully-Connected Neural Network : 서로 다른 층에 위치한 노드 간에는 연결관계가 존재하지 않고 인접층에 위치한 노드들 간의 연결만 존재한다는 의미
9. 입력층-은닉층, 은닉층-출력층 사이에는 각각의 행렬이 존재한다. 이러한 행렬들을 Parameter 또는 Weight라고 한다.
10. Weight=W, Bias=b라고 할 때, 인접한 레이어 사이에는 y=Wx+b의 관계를 이룬다.
11. 시그모이드(Sigmoid) 함수식과 그래프
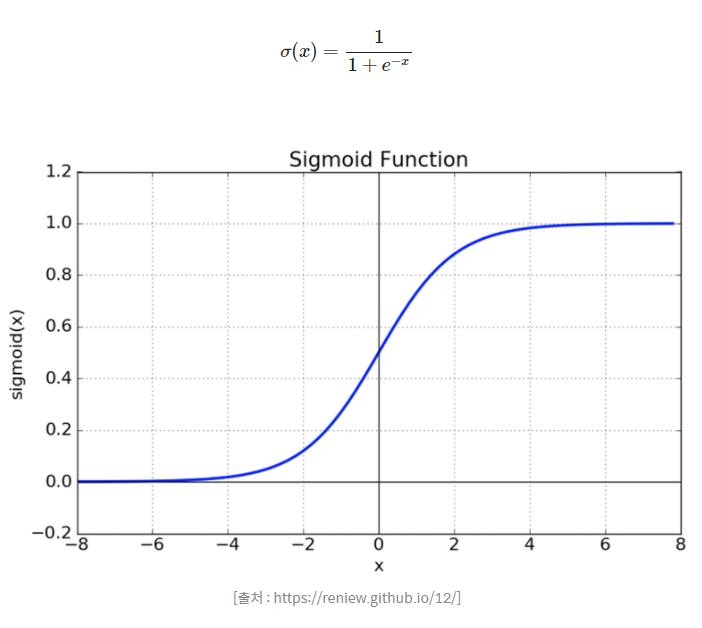
12. 사실 시그모이드 함수보다는 ReLU 함수를 더 많이 사용하는데, 그 이유는
- exp(지수) 함수 사용 시 드는 비용이 크다.
- Vanishing Gradient(기울기 소실) 현상이 발생한다.
- tanh (하이퍼탄젠트 함수) 식과 그래프
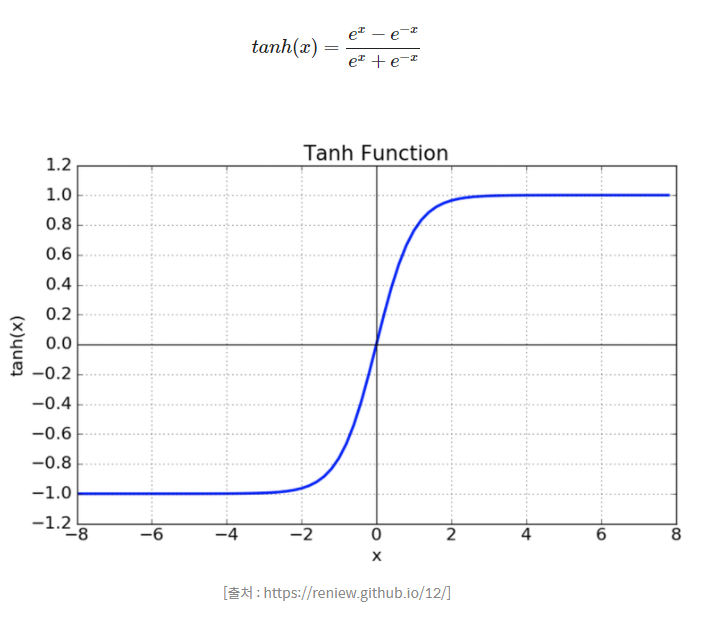
- 함수의 중심값을 0으로 옮겨서 시그모이드 함수의 최적화 과정이 느려지는 문제를 해결하기 위한 함수이다.
- Vanishing Gradient로 인한 문제가 발생한다.
- ReLU 함수식과 그래프
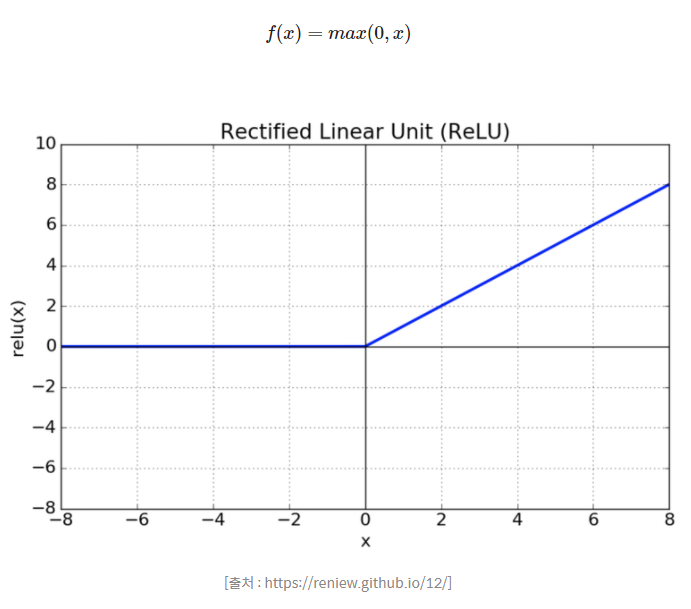
- 함수에서 x의 값이 0보다 작거나 같으면 함숫값은 0이다.
- 함수에서 x의 값이 0보다 크면 해당 x값이 함숫값이다.
- 연산 비용이 저렴하고 구현이 간단하여 복잡한 sigmoid, tanh 함수에 비해 빠른 학습이 가능하다.
- 딥러닝의 전체적인 학습 흐름
- 비선형 활성화 함수를 거친 여러 개의 은닉층을 거친 신호 정보들이 출력층으로 전달된다.
- 이 과정에서 우리가 원하는 정답과 전달된 신호 정보들 간의 차이를 계산하고, 그 차이를 줄이기 위해 필요한 파라미터를 조정한다.
- 이러한 차이를 계산하기 위해 사용되는 함수를 손실함수 또는 비용함수라고 한다.
- 교차 엔트로피(Cross Entropy) : 두 확률분포 사이의 유사도가 커질수록 작아지는 값이다.
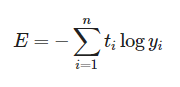
- 평균제곱오차(MSE) : 참고자료
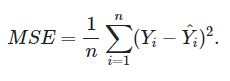
- 경사하강법(Gradient Descent)
- 마치 산꼭대기에서 시작해서 얼른 이 산을 내려가기 위한 최적의 방법을 찾는 것이라고 생각하면 될 듯..?
- 각 단계에서의 기울기를 구한 후, 해당 기울기가 가리키는 방향으로 이동하는 방법이다.
- 하지만 경사하강법이 항상 산 맨 아래에 잘 도착할 수 있을지에 대해서는 문제가 있다.
- 이를 보완하기 위해 도입되는 개념은 학습률(learning rate) 이다.
- 구한 기울기 값과 학습률을 곱한 만큼 발걸음을 딛는다고 생각하면 된다. 이는 과도하게 크게 발걸음을 딛게 된다면 산 아래로 내려가지 못하게 될 수 있기 때문이다.
