♣ (2021.07.31 최종본) 17번 노드의 후반 차원 축소 부분 추가하여 완성되었습니다!
Fundamental 17. 비지도학습(Unsupervised Learning)
17.1 학습 목표 탐색
- 지도학습은 정답 데이터(Y)를 통해 X가 무엇인지를 분류하는 방법이다.
- 그렇다면, 정답 데이터가 라벨로 달려있지 않은 수많은 데이터를 다루는 방법이 있을까?
- 그리고 그 데이터들로부터 어떤 정보를 얻을 수 있을까?
→ 정답 : 비지도학습(Unsupervised Learning)일 것이다! - 비지도학습의 개념과 지도학습과의 차이, 비지도학습 관련 알고리즘에 대해 학습하고자 한다.
17.2 비지도학습의 개요
-
지도학습과 달리 훈련(train) 데이터로 정답(label)이 없는 학습 데이터가 주어진다.
-
정답을 알려주지 않은 상태로 오직 데이터셋의 특징과 패턴을 기반으로 모델 스스로가 판단하게 한다.
-
비지도학습과 같은 방법론이 제시된 배경
- 라벨링이 된 데이터셋을 마련하는 데에는 적지 않은 인적 자원을 소모한다.
- 모든 데이터셋에 각각에 대한 정보가 명시되어 있지 않는 경우가 대부분이다.
- 라벨링되어 있지 않은 데이터들 내에서 비슷한 특징이나 패턴을 가진 데이터들끼리 군집화하고 새로운 데이터가 어떤 군집에 속하는지를 추론하는 방법론이 제시되었다.
17.3 클러스터링 : K-means
- 군집화(클러스터링) : 명확한 분류 기준이 없는 데이터를 분석하여 유사한 것들끼리 묶어주는 과정이다.
- 개별적인 데이터들을 몇 개의 그룹으로 추상화하여 새로운 의미를 발견해낼 수 있다.
- K-means Algorithm : 값 k가 주어졌을 때 주어진 데이터들을 k개의 클러스터로 묶는 알고리즘이다.
- K-means에서는 k개의 중심점이 새로운 label 역할을 한다. (실행결과 맨 아랫줄)
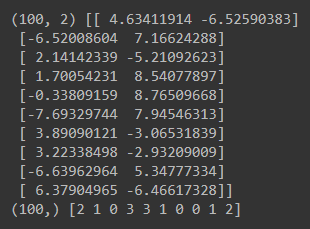
- Scikit-learn의 make_blob()를 활용하면 아래와 같이 중심점이 5개인 무작위의 점 데이터 100개를 생성할 수 있다. 아래 데이터들은 총 5개의 군집을 이루고 있다.
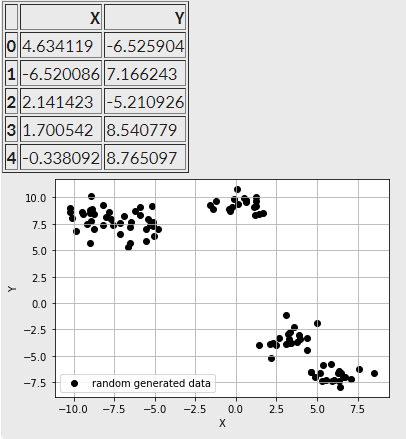
- 위와 같이 현재 100개의 점 데이터는 모두 좌표평면 위에 있다. 좌표평면 위에 존재하는 데이터들 사이의 거리를 계산하는 방법으로, 피타고라스 정리를 응용하여 계산한 두 점 사이의 직선거리를 L2 Distance 혹은 Eucledian Distance라고 한다. (출처)

- K-mean 알고리즘의 해결 순서
Step1. 설정하고자 하는 클러스터의 수 k를 결정한다.
Step2. 설정한 클러스터의 수와 같은 k개의 중심점을 무작위로 선정한다. 이들이 각각의 클러스터를 대표한다.
Step3. 나머지 점들과 모든 중심점 간의 유클리드 거리를 계산한 후 가장 가까운 거리를 가지는 중심점의 클러스터에 속하게 한다.
Step4. 각 k개의 클러스터의 중심점을 재조정한다. 여기서 특정 클러스터에 속하는 모든 점들의 평균값이 해당 클러스터 다음 iteration의 중심점이 된다.
Step5. 재조정된 중심점을 바탕으로 모든 점들과 새로 조정된 중심점 간의 유클리드 거리를 다시 계산한 후 가장 가까운 거리를 가지는 클러스터에 해당 점을 다시 배정한다.
Step6. 특정 iteration 이상이 되어 수렴할 때까지 Step4~Step5의 과정을 반복한다. 여기서 수렴이란 중심점이 더 이상 바뀌지 않는 상태를 의미한다. - K-means 결과를 시각화한 결과는 다음과 같다. ('5.' 내용과 묶어보기)
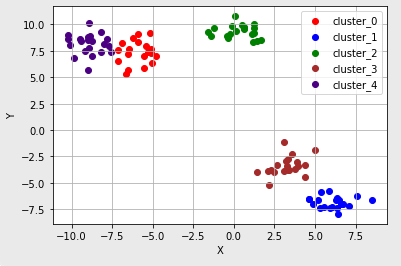
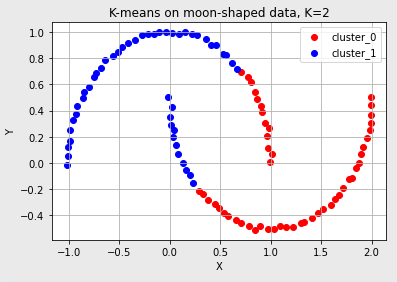
- K-means Algorithm은 군집의 수만 주어진다면 데이터를 군집화할 수 있다. 하지만 데이터의 분포에 따라 의도하지 않은 결과를 초래할 수도 있어 K-means가 항상 해결책이 되지는 못한다.
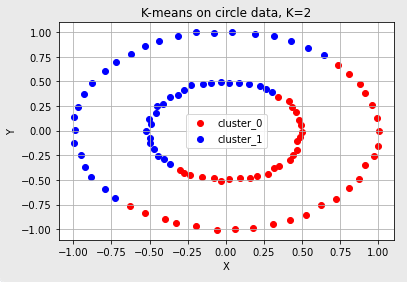
- 대표적으로 아래의 분포를 갖는 데이터는 K-means Algorithm을 적용해도 군집화가 잘 되지 않는다.
- 원형으로 분포한 데이터 (마치 케잌을 자르듯이 반으로 사삭~)
- 초승달 모양으로 분포한 데이터 (역시나.. 사삭~ 느낌으로 2개의 군집을..)
- 3개의 대각선 방향으로 나열된 데이터

- K-means 사용이 적합하지 않은 상황
- K-means에서는 군집의 개수(k)를 미리 지정한다. 따라서 이를 알거나 예측하는 것이 어렵다면 적합하지 않다.
- 유클리드 거리가 가까운 데이터끼리 군집이 형성되므로 데이터 분포에 따라 유클리드 거리가 멀면서 밀접하게 연관되어 있는 데이터들의 군집화를 성공적으로 해내지 못할 수도 있다.
Next Spoiler >>> '10.'에서 설명한 데이터처럼 군집의 개수를 명시하지 않으면서 밀도 기반으로 군집을 예측하는 방법이 있을지 고민해보자.
17.4 클러스터링 : DBSCAN
- 스포했듯이(!) DBSCAN 알고리즘은 밀도(density) 기반의 군집 알고리즘으로, K-means로는 해결하기 어려웠던 문제를 해결하는 데 도움이 된다.
- DBSCAN은 K-means와 달리 군집의 개수를 미리 지정할 필요가 없다.
- DBSCAN은 K-means와 달리 조밀하게 몰려있는 클러스터를 군집화하는 방식을 사용한다. 따라서 원 모양의 군집이 아닌 불특정한 형태의 군집도 찾을 수 있다.
- 클러스터 중심점을 지정하지 않을 때, 어떤 방식으로 클러스터링하는가? 예시
- 클러스터가 최초의 임의의 점 하나로부터 점점 퍼져나가는 것을 알 수 있다.
- 퍼져나가는 기준은 일정 반경 안의 데이터의 개수 즉, 데이터의 밀도를 나타낸다.
- (★★) DBSCAN에서 주로 사용되는 변수와 용어

- DBSCAN에서는 point를 잡아 군집을 표현하려면 epsilon, minPts 변수는 미리 지정해 주어야 한다.
- DBSCAN 알고리즘의 해결 순서

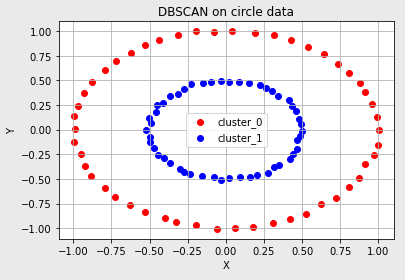
- 17.3절 '10.'에서 언급한 데이터를 DBSCAN으로 해결하기
- 원형 모양의 데이터
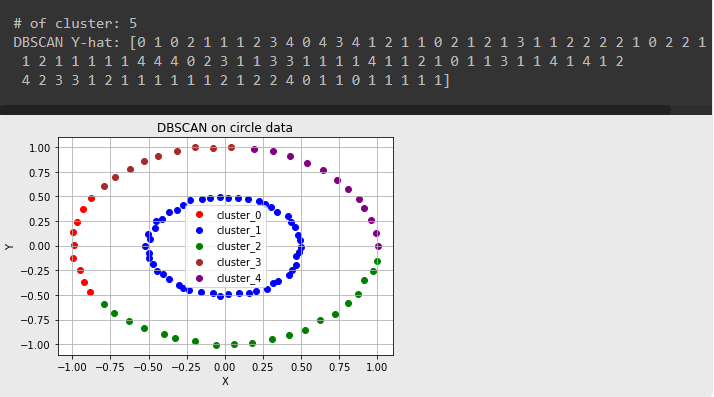
※ 모든 색깔의 cluster가 나타나도록 epsilon, minPts 값을 0.1475, 1로 조정했더니..
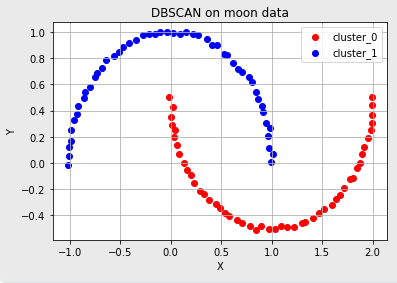
- 초승달 모양으로 분포한 데이터
- 3개의 대각선 방향으로 나열된 데이터
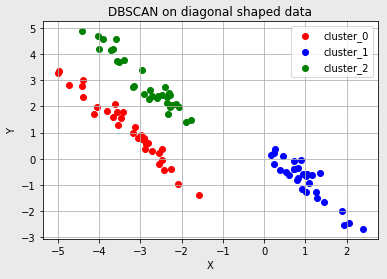
- DBSCAN y-hat 결과값이 -1인 경우 : noise point로 존재한다.
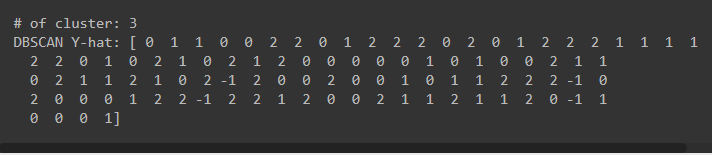
- 이와 같이 데이터 분포에 적합한 epsilon, minPts 변수를 잘 조정하면 클러스터의 수를 명시하지 않았어도 적절한 클러스터의 개수를 설정하여 군집화를 할 수 있다.
- K-means는 클러스터의 개수를 미리 지정해야 하고 데이터의 분포도 신경써야 하는 부분이 있는 바, DBSCAN 알고리즘은 유연하게 사용이 가능한 장점이 있다.
- DBSCAN의 단점은?
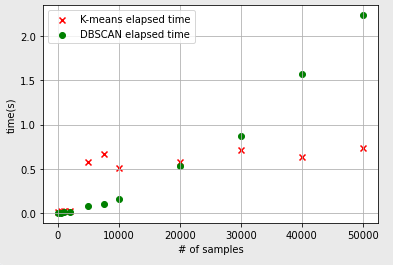
- 위 그림 상 sample 개수가 20,000개 이하에서는 수행시간이 K-means에 비해 적게 걸렸으나 그 이상에서는 DBSCAN 알고리즘의 수행시간이 더 오래 걸렸다고 해석할 수 있다.
- 군집화할 sample의 수가 많아질수록 DBSCAN의 알고리즘 수행시간이 급격히 늘어나는 단점이 발생한다.
17.5 차원 축소 : PCA
- 비지도학습에서는 데이터를 나타내는 여러 특징들 중에서 어떤 특징이 가장 그 데이터를 잘 표현해내는지 알게 해주는 특징 추출(feature extraction) 의 용도로 PCA를 사용한다.
- PCA는 데이터 분포의 주성분을 찾아주는 방법이다.
- 주성분 : 데이터의 분산이 가장 큰 쪽의 방향벡터
- 데이터의 분산을 최대로 보존하면서 서로 직교(orthogonal)하는 기저(basis, 주성분의 축)들을 찾아서 고차원 공간을 저차원으로 사영(projection)한다.
- PCA는 기존의 특징들 중 중요한 것을 선택하는 방식이 아닌 기존의 특징을 선형결합하는 방식을 지향하고 있다.
- 차원 축소 : 차원의 수를 최대로 줄이면서도 데이터 분포의 분산을 유지시키는 기법
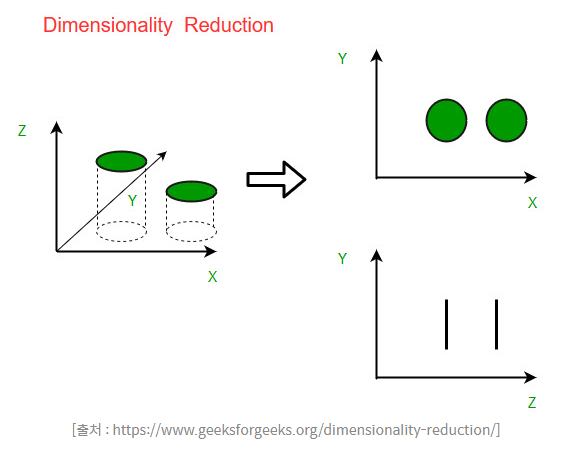
- PCA는 데이터가 가진 고유한 물리적 정보량을 보존하는 데 주력한다.
- PCA는 주로 선형적인 데이터의 분포(키, 몸무게 등)를 가지고 있을 때 정보를 잘 보존할 수 있다.
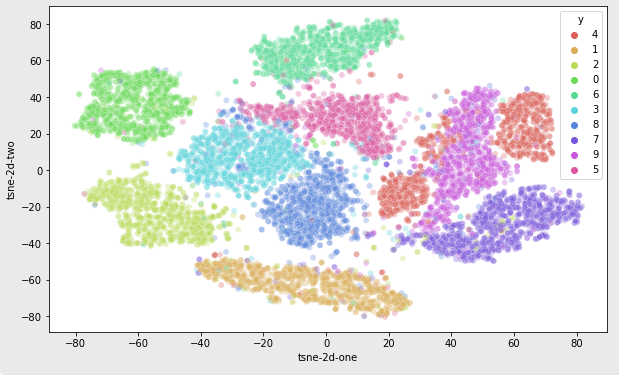
17.6 차원 축소 : T-SNE
- T-SNE는 시각화에 많이 사용되어지는 알고리즘이다.
- 데이터들 간의 상대적인 거리를 보존하는 데 주력한다.
- 정보 손실량에 주목하지 않으며, 시각화에만 유리하다.
17.7 정리


날개를 달고 날아오르자!