
복습
정형데이터
Linear Regression
종속변수가 연속적인 숫자일 때 사용하는 머신러닝 기법
Logistic Resgression(Binary Classification)
학습데이터의 상태가 변한다.
종속변수가 0/1 과 같이 두 개 분류로 나뉘어지는 경우에 사용하게 되는 머신러닝 기법
Multiple Logistic Resgression(Multinomial Classification)
학습데이터의 상태가 다시 변한다.
종속변수가 다중의 형태로 분류가 이루어지는 경우에 사용하게 되는 머신러닝 기법
| machine learning 기법 | activation | loss function | 종속변수(Target)의 타입 |
|---|---|---|---|
| Linear Regression | linear | mse | 연속된 숫자 |
| Logistic Resgression | sigmoid | binary_crossentropy | 0~1 사이의 확률 값 1개 |
| Multinomial Classification | softmax | categorical_corssentropy | class 별 확률 값 |
비정형데이터
학습데이터의 형태가 비정형 데이터로 변한다.
ANN(Artificail Neural Network) 혹은 NN(신경망)
keras model 을 기본으로 생각해서 좀 더 복잡하게 만들어보자라는 생각에서 출발해 생겨난 방법론이 DNN
DNN(Deep Neural Network) => Deep Learning
: input layer 와 output layer 사이에 hidden layer 를 추가한다.
그리고 hidden layer 내부에 Unit 혹은 node 라 불리우는 것을 원하는 만큼 넣어서 조금 더 복잡하고 상세한 계산을 통해 값을 추출해보자.
Image 는 가로x세로의 2차원의 형태인 픽셀들의 모임으로 이루어져 있다.
학습을 위해서는 여러 이미지의 층을 쌓게 되고, 이는 즉 2차원이 여럿 모이게 되기 때문에 3차원이 된다.
그런데 DNN 은 반드시 2차원의 형태로 나와야 한다. 왜냐하면 행렬곱을 통해 연산을 해야 하기 때문이다.
3차원 이미지 데이터에서 여러 개의 이미지를 포기할 수는 없으니 2차원 픽셀의 모임을 1차원 데이터로 바꾼다. 그렇게 되면 가장 큰 문제는 공간에 대한 정보가 사라지게 된다.
즉, 28x28 의 이미지가 있었다면 원래는 좌표값(공간정보) 가 있었는데 그게 사라지고 그러 784 개의 한 줄(1차원) 짜리 데이터로 남게 된다.
그렇다보니 이미지처리에서 많은 오류/비정확성을 불러오일으키게 된다.
=> 이것을 해결하고자 스탠포드에서 새롭게 등장한 이론이자 알고리즘이 CNN 이다.
| machine learning 기법 | activation | loss function | 종속변수(Target)의 타입 |
|---|---|---|---|
| DNN | softmax, relu(hidden layer) | (sparse_)categorical_crossentropy | 이미지 데이터 |
Image 파일의 특징
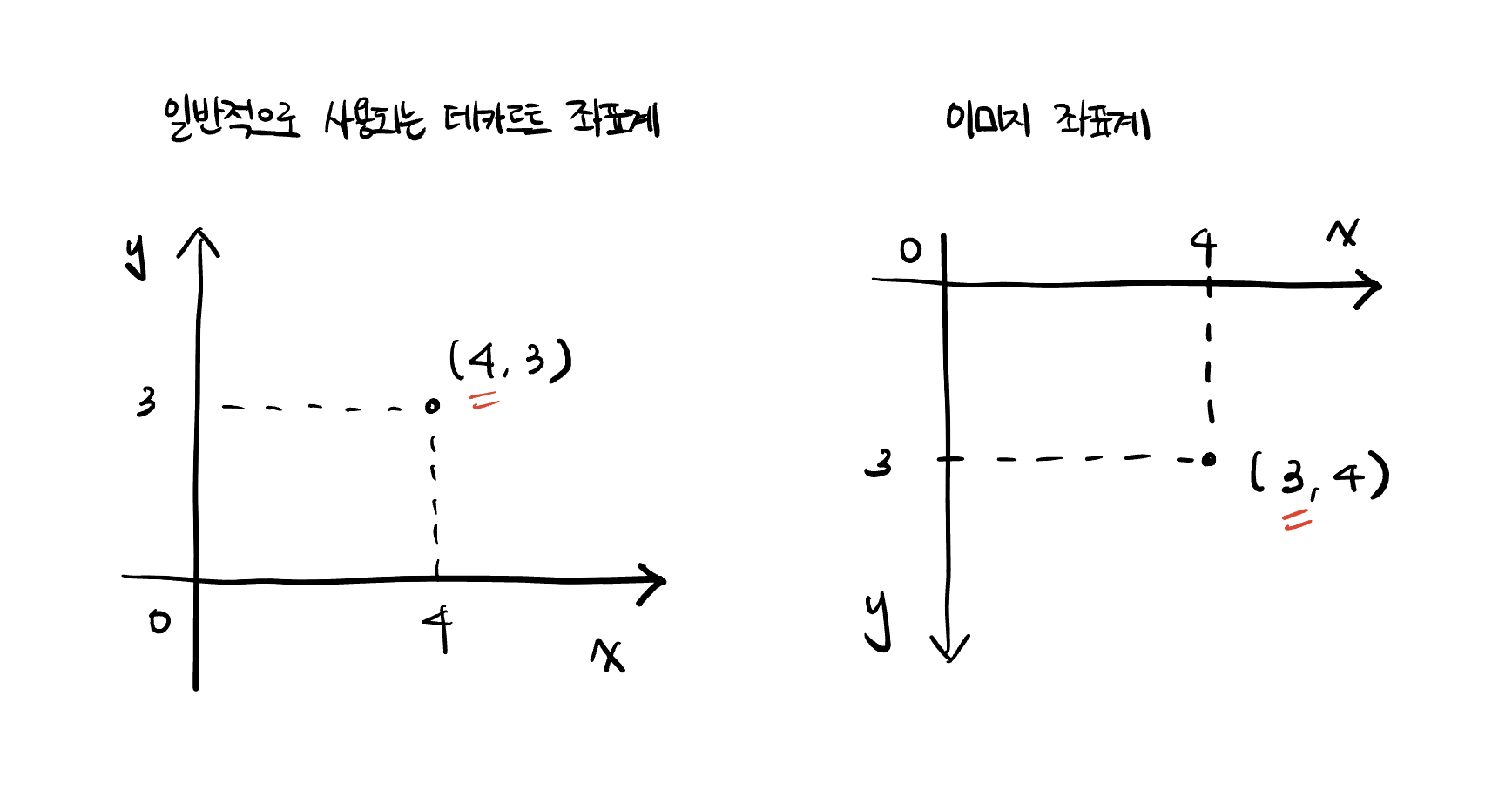
좌표계 : 이미지 좌표계가 별도로 존재한다.(일반적인 데카르트 좌표계를 표시하지 않는다) 이미지의 경우, 최상단의 왼쪽부터 시작해서 오른쪽/아래 방향으로 내려나는 좌표계를 사용한다.
따라서 데카르트 좌표계에서 (x, y) 로 표현했었던 것이 이미지 좌표계에서는 (y, x) 로 표시하게 된다.
이미지가 픽셀데이터로 나오게 되는데, 픽셀데이터 역시 (y, x) 로 표현이 이루어진다.
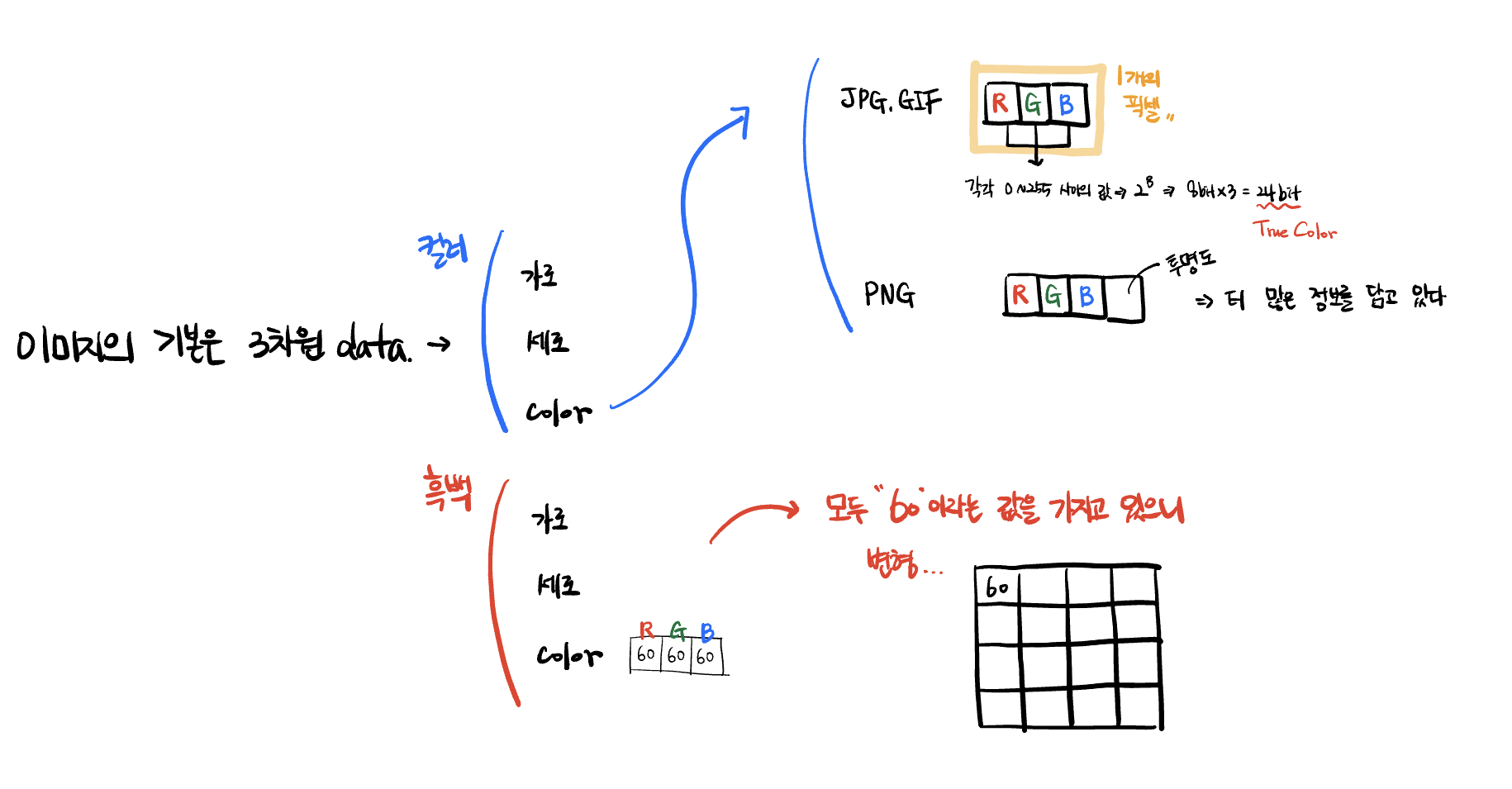
기본적인 이미지의 color 는 RGB 3 개의 색의 값이 합쳐져서 만들어진다.
흑백 이미지의 경우에는 모든 R+G+B/3 의 값이 각각의 R, G, B 에 동일하게 들어가게 된다.
여기서 조금의 편법을 동원해서 흑백 이미지를 2차원으로 변경할 수가 있게 되는데, 어차피 color 의 RGB 가 모두 동일한 값이라면 color 부분을 RGB 를 쓰는 것이 아니라 하나의 스칼라 값(RGB의 평균)을 사용하는 것이다. 이를 통해 오른쪽 아래의 그림과 같이 가로x세로 에 하나의 값을 입력하는 2차원 형태로 만들 수 있게 된다.


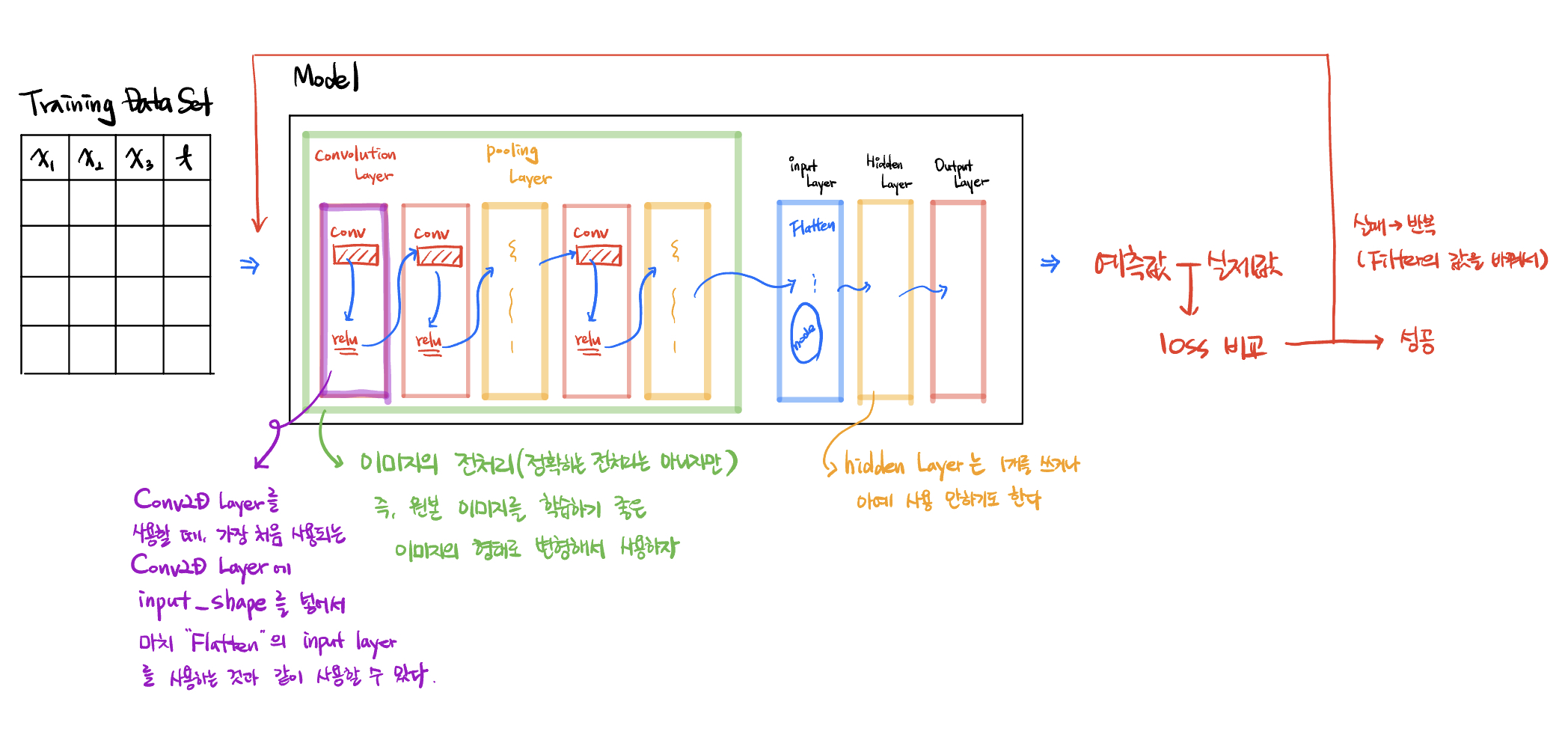
CNN(Convolutional Neural Network)
-> Convolutional Neural Network) -> 합성곱 신경망
-> 줄여서 conunet(컨브넷..)
convulutaion 연산을 줄여서 conv 연산이라고 부르는데, 이는 즉 합성곱 연산을 의미한다.
정의는 f, g 2개의 함수가 있으면 f를 반전, 전이 시켜서 g와 곱한 다음 그 결과를 적분하는 연산.
Convolution 연산(conv 연산)
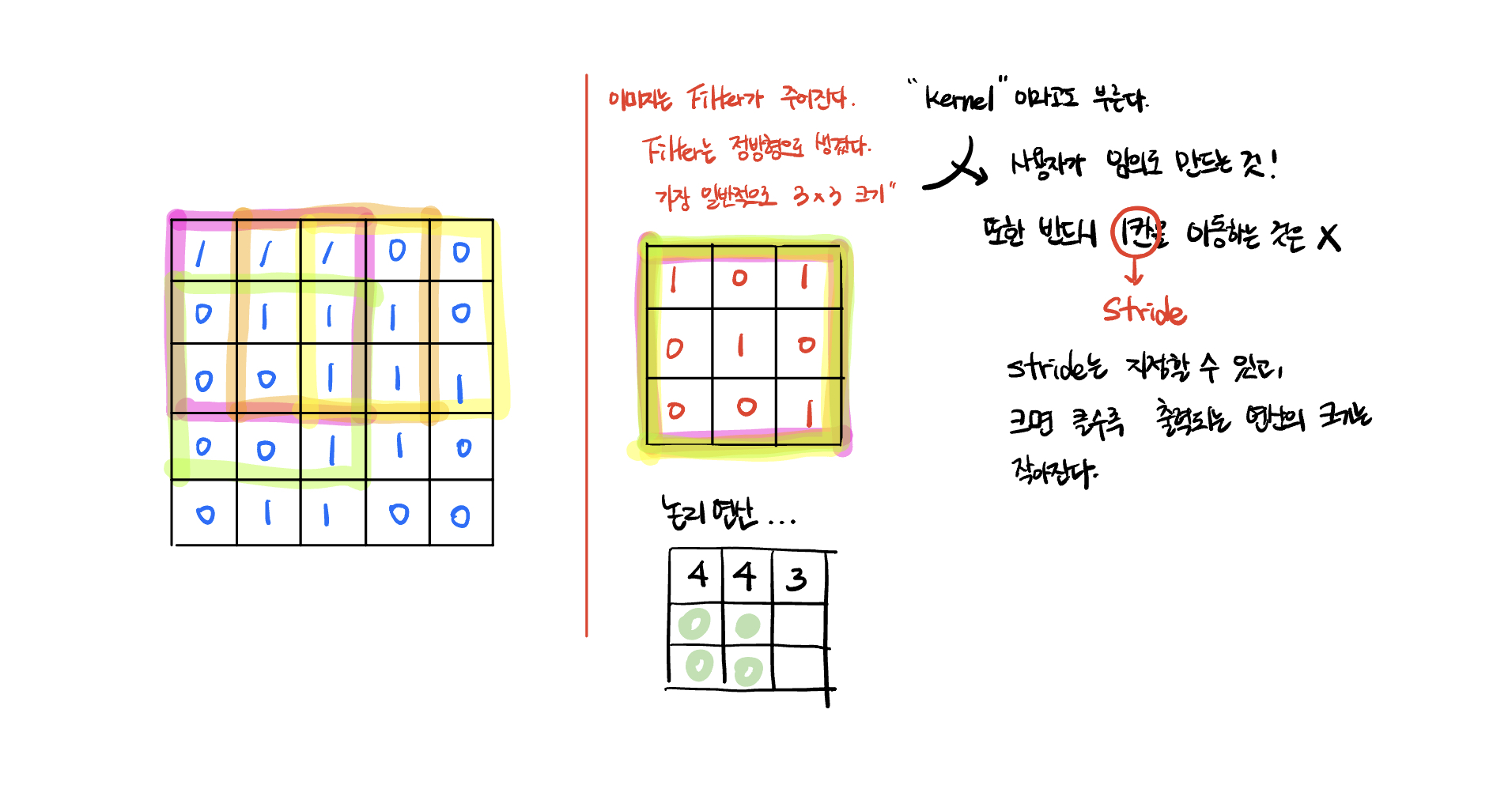
Stride는 지정이 가능하고, 이 값이 크면 클수록 출력되는 연산 값의 크기가 작아진다. 즉, 합성곱 연산을 통해 이미지의 크기가 줄어들게 된다.
이러한 conv 연산을 반복할수록 이미지의 크기가 작아지게 된다.
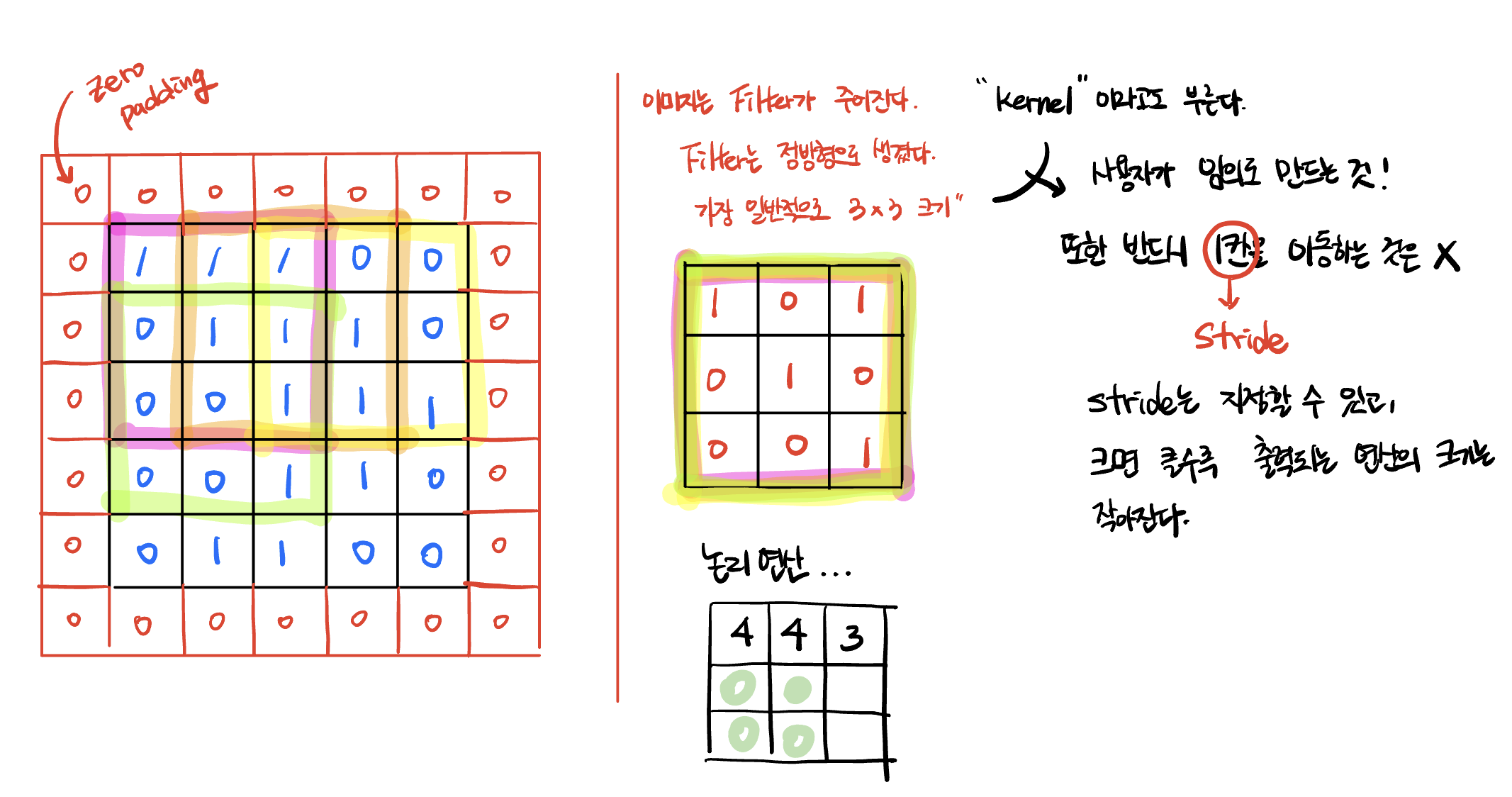
그래서 과도하게 이미지의 크기가 작아져서 이미지데이터의 인식 자체가 불가능하게 되는 현상을 막기 위해서 Padding 을 이용한다.
일반적으로는 zero padding 을 이용한다. 즉 이미지의 외곽부분에 아무 의미 없는 0 값을 가진 이미지 픽셀을 생성한다.
만약 원본 이미지가 5x5 크기였을 때 zero padding 을 부여하게 되면 이미지의 크기는 7x7 크기로 만들어준다.
그 후에 3x3 크기의 Filter(=kernel) 을 가지고 stride 에 1값을 준 채 합성곱 연산을 하게 되면 출력되는 값은 5x5 크기가 된다. 즉 원본과 동일한 크기가 된다.
즉 원래 가지고 있던 이미지가 크기는 그대로인 채, 값이 변하게 된다.
또한, filter(=kernel) 의 값은 어떻게 지정해주어야 하나?
일반적으로 filter 는 여러 개를 이용한다.
즉 각각의 필터를 통해 처리된 결과의 값이 여러 개 나오게 된다.
하나의 이미지를 가지고 여러 개의 필터에 적용시킴으로써 각기 다른 변형된 값이 출력되게 된다.
필터 1) 필터 2) 필터 3)
|1|1|0| |0|0|1| |0|0|1|
|0|0|1| |1|1|0| |0|0|0|
|1|0|0| |1|1|1| |0|1|0|
이렇게 3개의 필터가 존재하게 되면 하나의 이미지를 가지고도 합성곱을 통해 3개의 이미지를 만들 수 있게 된다.
내가 가지고 있는 이미지를 변화시켜서 여러 장을 만드는 것.
그렇게 완성된 여러 장의 이미지를 가지고 학습을 함으로써 학습을 더 잘 할 수 있도록 바꿔주는 것이 CNN 의 가장 큰 골자이다.
합성곱 연산을 실행하면 어떻게 되는가?

여기서 3 의 값에 해당하는 부분을 채널이라고 부른다.
결국 합성곱 연산은 이미지의 특징을 뽑아내서 학습에 좋은 이미지를 만들어내는 과정.
특징을 뽑아내는 역할을 하는 것이 filter/kernel. 따라서 filter의 값이 어떤 값이냐에 따라서 뽑혀져나오는 특징이 달라진다.
1개의 이미지에 대해서 특징만 추출한 이미지 여러 개로 만들어서 학습을 한다.
print('ori_image shape : {}'.format(ori_image.shape))
# 이미지의 형태
# convolution 연산 시에는 4차원의 데이터를 입력받는다.
# (1, 429, 640, 3) => (이미지 개수, height, width, color)
input_image = ori_image.reshape((1,) + ori_image.shape)
# reshape 함수를 통해 기존의 shape 에 1개의 차원을 더해주었다.
input_image = input_image.astype(np.float32)
print('Convolution input image.shape : {}'.format(input_image.shape))
# 입력이미지 channel 변경
# 흑백인데 3채널 까지는 불필요. 따라서 RGB 중 R 하나의 값만 사용하겠다.
# (1, 429, 640, 1) => (이미지 개수, height, width, color)
# slicing을 이용하여 첫번째 R(Red) 값만 이용
channel_1_input_image = input_image[:,:,:,0:1]
print('Channel 변경 input_image.shape : {}'.format(channel_1_input_image.shape))
# filter
# (3,3,1,1) => (filter height, filter width, filter channel, filter 개수)
weight = np.array([[[[-1]],[[0]],[[1]]],
[[[-1]],[[0]],[[1]]],
[[[-1]],[[0]],[[1]]]])
print('적용할 filter shape : {}'.format(weight.shape))
# stride 는 이동 간격
# padding : 'VALID' 는 패딩을 채우지 않겠다는 의미
conv2d = tf.nn.conv2d(channel_1_input_image,
weight,
strides=[1,1,1,1],
padding='VALID').numpy()
print('Convolution 결과 shape : {}'.format(conv2d.shape))
# 원본 (1, 429, 640, 1)
# 필터의 합성곱 결과 (1, 427, 638, 1)
t_img = conv2d[0,:,:,:]
fig = plt.figure(figsize=(10,10)) # 가로세로 크기 inch단위
# 1행2열로 나눈다. 즉 좌/우 로 나누는 것. 좌가 ax1, 우가 ax2
ax1 = fig.add_subplot(1,2,1)
ax2 = fig.add_subplot(1,2,2)
ax1.imshow(ori_image)
ax2.imshow(t_img)
fig.tight_layout()
plt.show()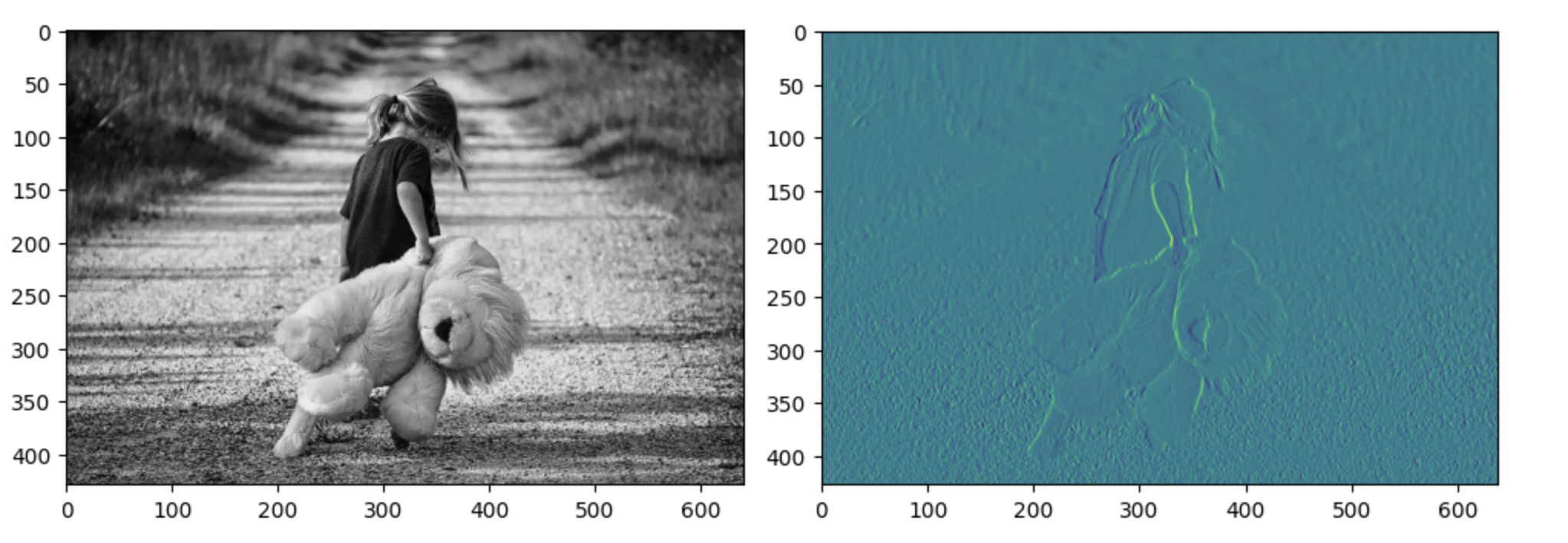
convolution 을 하게 되면 한 개의 이미지의 크기는 줄어들겠지만 여러 개의 이미지가 생성되면서 너무 많은 양의 데이터가 생성된다.
이 문제를 해결하기 위해서 image size 를 줄인다. 이 역할을 하는 것이 Pooling layer 이다.
Pooling
Pooling 에도 여러 가지 방법이 존재하지만, CNN 에서 사용하는 방식은 MAX Pooling 을 사용한다.
Feature map : image 에 filter 를 거쳐서 특징을 뽑아낸 이미지. 다른 말로, 원본 이미지의 특징을 뽑아낸 이미지.
kernel 을 준비한다. 이 때의 사이즈는 2x2
stride 의 값은 kernel 의 y 값!! ( 2x2 에서 앞의 2)
만들어진 kernel 을 Feature map 에 가져대고, 가장 큰 값을 찾아서 출력 값에 담는다.
만약 4x4 의 feature map 이 존재하고, 2x2 의 kernel 을 통해 출력값을 만들내면 최종적으로 2x2 의 이미지가 출력되게 된다.
#import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
import matplotlib.image as img
fig = plt.figure(figsize=(10,10)) # 가로세로 크기 inch단위
ax1 = fig.add_subplot(1,3,1)
ax2 = fig.add_subplot(1,3,2)
ax3 = fig.add_subplot(1,3,3)
ori_image = img.imread('/content/drive/MyDrive/python/image/230405/teddy.jpeg')
ax1.imshow(ori_image)
# 입력이미지의 형태
# (1, 429, 640, 3) => (이미지 개수, height, width, color)
input_image = ori_image.reshape((1,) + ori_image.shape)
input_image = input_image.astype(np.float32)
print('Convolution input image.shape : {}'.format(input_image.shape))
# 입력이미지 channel 변경
# (1, 429, 640, 1) => (이미지 개수, height, width, color)
# slicing을 이용하여 첫번째 R(Red) 값만 이용
channel_1_input_image = input_image[:,:,:,0:1]
print('Channel 변경 input_image.shape : {}'.format(channel_1_input_image.shape))
# filter
# (3,3,1,1) => (filter height, filter width, filter channel, filter 개수)
# weight = np.random.rand(3,3,1,1)
weight = np.array([[[[-1]],[[0]],[[1]]],
[[[-1]],[[0]],[[1]]],
[[[-1]],[[0]],[[1]]]])
print('적용할 filter shape : {}'.format(weight.shape))
# stride : 1 (가로1, 세로1)
# padding = 'VALID'
conv2d = tf.nn.conv2d(channel_1_input_image,
weight,
strides=[1,1,1,1],
padding='VALID').numpy()
# 2번쨰 그림판에 convolution 한 이미지 출력(특징을 뽑아낸 이미지)
t_img = conv2d[0,:,:,:]
ax2.imshow(t_img)
## pooling 처리 ##
# ksize = pooling filter의 크기
#stride = 3x4 => 이미지가 더 작아진다.
pool = tf.nn.max_pool(conv2d,
ksize=[1,3,3,1],
strides=[1,3,3,1],
padding='VALID').numpy()
# 3번쨰 그림판에 pooling 한 이미지 출력(특징을 뽑아낸 이미지)
t_img = pool[0,:,:,:]
ax3.imshow(t_img)
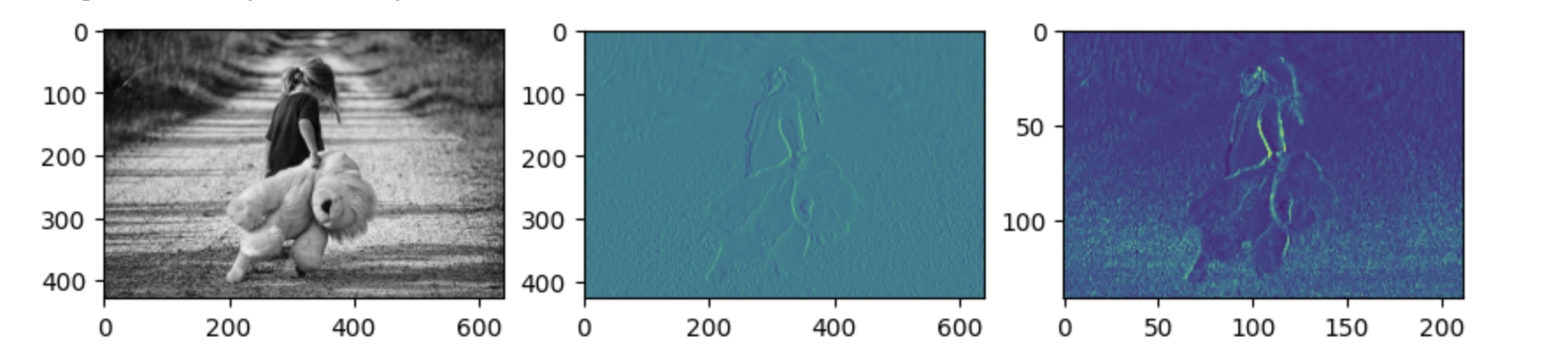
max_pooling 을 하게 되면 이미지의 특징이 더 도드라지게 된다. 즉, pooling 을 통해서 이미지는 더 부각되게 하면서 이미지의 크기는 줄이게 한다.
다음 convulution 시에는 max_pooling 된 이미지를 원본 삼아서 다시 conv 를 하게 된다. 이런 과정을 반복해가면서 특징들을 많이 뽑아내서 사물의 특징을 학습시킨다.
때문에 정확히 말하면 input layer로 들어가기 전까지의 단계를 Feature Extraction, 특징 추출이라고 하고
추출된 자료를 바탕으로 분류기를 통해서 학습을 시킨다.
최종적으로 output 을 통해 넘어온 예측값과 실제값을 비교해서 만약 loss 값이 크다면 다시 학습이 필요하다.
이 때, 기존의 머신 러닝 기법에서는 weight 와 bias 를 수정해서 재학습을 시도했다.
그런데 CNN 은 filter 의 값을 변경해서 재학습을 시도한다. 왜냐하면 filter 의 값에 따라서 이미지의 특징이 뽑혀져 나오는 것이 다르기 때문이다. 즉 반복을 통해서 이미지의 특징을 뽑아내는 filter 의 정확도가 올라가게 된다.
filter 의 값이 좋으면 이미지의 특징을 아주 잘 뽑아낸다.
CNN 을 이용해서 Model 을 학습하면 이미지 학습, 예측에 좋은 결과를 얻을 수 있다.
CNN 은 입력 데이터가 4차원 데이터로 들어가야 한다.
Model 은 keras를 이용해서 만든다.
Model 학습과 평가 역시 keras 를 이용한다.
이미지 파일로부터 pixel 데이터를 뽑아내서, 뽑은 데이터를 4차원 데이터로 변환.
가장 중요한 것은 실사 이미지 파일을 구할 때, 그리고 입력 데이터로 변환할 때에는 반드시 동일한 이미지 사이즈 규격으로 맞춰야 한다.
실습 : MNIST 데이터를 3가지 방법으로 학습 시키기
1. Multinomial Classification
# Multinomial Classification
model_1 = Sequential()
model_1.add(Flatten(input_shape=(784,)))
model_1.add(Dense(10, activation='softmax'))
model_1.compile(optimizer=Adam(learning_rate=1e-4),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
early_stopping = EarlyStopping(monitor='val_loss',
patience=3,
verbose=1,
restore_best_weights=True,
mode='auto')
model_1.fit(x_data_train_norm,
t_data_train,
epochs=2000,
validation_split=0.2,
callbacks=[early_stopping],
verbose=1,
batch_size=100)2. DNN
# DNN
model_2 = Sequential()
model_2.add(Flatten(input_shape=(784,)))
model_2.add(Dense(64, activation='relu'))
model_2.add(Dense(128, activation='relu'))
model_2.add(Dense(32, activation='relu'))
model_2.add(Dense(10, activation='softmax'))
model_2.compile(optimizer=Adam(learning_rate=1e-4),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
early_stopping = EarlyStopping(monitor='val_loss',
patience=3,
verbose=1,
restore_best_weights=True,
mode='auto')
model_2.fit(x_data_train_norm,
t_data_train,
epochs=2000,
validation_split=0.2,
callbacks=[early_stopping],
verbose=1,
batch_size=100)
3. CNN
# CNN
# 1) 특징을 추출하는 것
# 2) 분류기를 통해 분류하는 것
from tensorflow.keras.layers import Conv2D, MaxPooling2D
model_3 = Sequential()
# Feature extraction(Convolution 처리)
# convolution layer 와 pooling layer 를 추가
# Dropout 레이어를 통해서 과적합을 방지하도록 한다.
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dropout
# 일반적으로 input layer 와 conv2d layer 를 하나로 합쳐서 작성한다.
model_3.add(Conv2D(
# filter 를 몇 개 쓸 지
filters=32,
# filter 의 사이즈. 튜플로 명시한다.
kernel_size=(3,3),
activation='relu',
# 첫 번째 conv layer 이기 때문에 input layer 에 쓰이는 input_shape 가 쓰인다.
# input_shape 는 들어가는 이미지 하나의 shape.
input_shape=(28,28,1)
))
# filter 의 사이즈. 즉 kernel의 사이즈
model_3.add(MaxPooling2D(pool_size=(2,2)))
model_3.add(Conv2D(
filters=64,
kernel_size=(3,3),
activation='relu'))
model_3.add(MaxPooling2D(pool_size=(2,2)))
model_3.add(Conv2D(
filters=64,
kernel_size=(3,3),
activation='relu'))
# 이미지의 크기는 줄이고, 특징만 뽑아낸 이
# ㅌFeature Extraciton 을 통해 바뀐 이미지의 node 갯수를 알 수 없기 때문에
# input_shape 를 생략한다.
model_3.add(Flatten())
model_3.add(Dropout(rate=0.25))
model_3.add(Dense(128, activation='relu'))
model_3.add(Dense(10, activation='softmax'))
model_3.compile(optimizer=Adam(learning_rate=1e-4),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
early_stopping = EarlyStopping(monitor='val_loss',
patience=3,
verbose=1,
restore_best_weights=True,
mode='auto')
# x_data_train_norm 은 2차원 데이터. 그런데 CNN 은 4차원 데이터가 필요하다. 그렇기 때문에 변환이 필요하다.
model_3.fit(x_data_train_norm.reshape(-1, 28, 28, 1),
t_data_train,
epochs=2000,
validation_split=0.2,
callbacks=[early_stopping],
verbose=1,
batch_size=100)
# 평가의 결과
# 첫 번 째 모델 => 0.9180
# 두 번 째 모델 => 0.9573
# 세 번 째 모델 => 0.9845
# 세 번 째 + dropout => 0.9867Colab
Colab 의 경우 이미 왠만한 라이브러리가 모두 설치되어 있기 때문에 라이브러리의 버전 충돌 혹은 의존성 문제를 해결할 수 있다.
