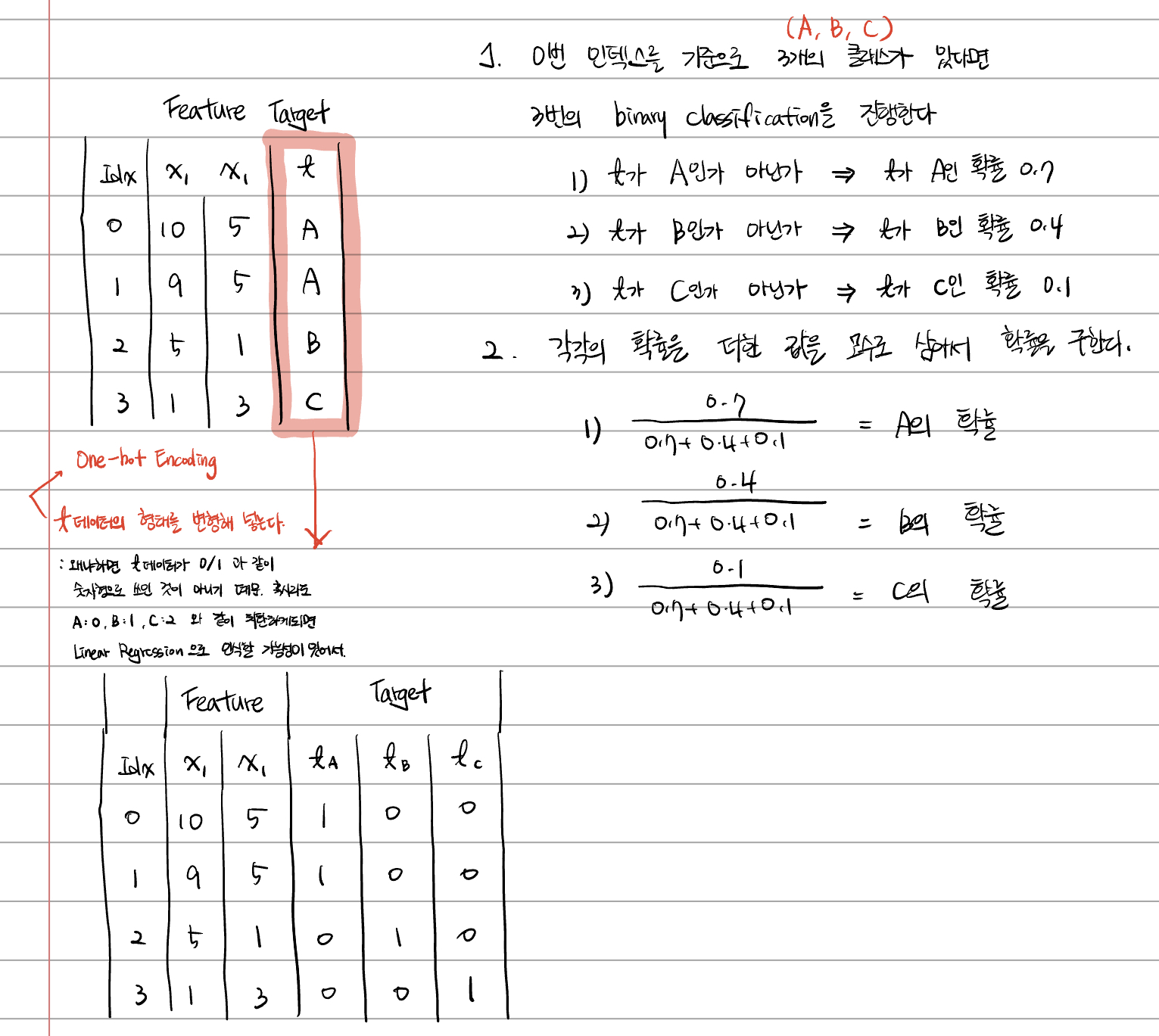
Multinomial Logistic Regression(다중 로지스틱 회귀)
feature(독립변수)에 의해 나오게 되는 결과값인 Target(종속변수)가 0/1 과 같이 binary 형태로 나오는 것이 아니라 A/B/C 과 같이 범주의 결과값으로 나오게 되는 회귀분석을 의미한다.
이러한 다중분류는 관점을 달리하면 여러 개의 binary classification 이라고 볼 수 도 있다.
1) A 또는 A가 아닌 것
2) B 또는 B가 아닌 것
3) C 또는 C가 아닌 것
이런 3가지의 binary classification 의 형태로 나눌 수도 있다는 것이다.
기존의 binary classification 의 경우에는 target 이 0~1 의 확률 값으로 나왔기 때문에 3가지의 이진분류를 통해서
1) A인 확률/B인 확률/C인 확률들을 추출한 뒤
2) 1) 에서 구한 확률들을 모두 더한 모수에 대한 A의 확률/B의 확률/C의 확률울 다시 재가공한다.
그 확률값이 결국 Multinomial Logical Regression 이 된다는 것이다.
즉, 클래스(분류)의 가짓수 만큼의 결과값이 나와야 그 결과값을 전체 모수로 잡아서 재가공이 가능해진다.
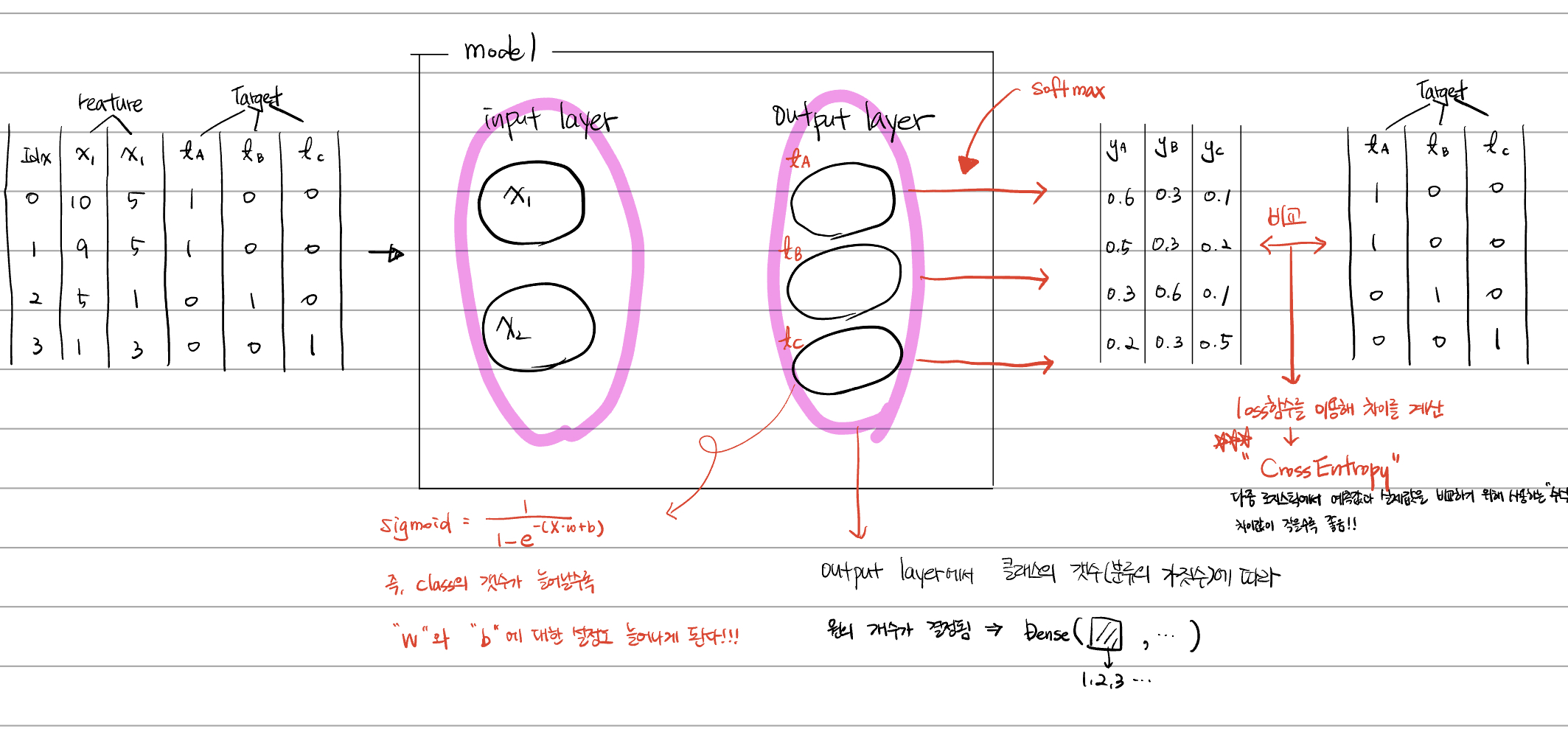
실습 : 키와 몸무게를 바탕으로 bmi 를 분류하기
import numpy as np
import pandas as pd
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense
from tensorflow.keras.optimizers import Adam
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
# 다중분류를 위해서 one-hot encoding 작업이 필요하다.
# 해당 기능을 제공하는 라이브러리인 tensorflow 를 사용한다.
import tensorflow as tf
# 로우 데이터 받아오기
train = pd.read_csv('./data/230404/bmi.csv', skiprows=3)
display(train.head())
# 결측치 처리
# print(train.info())
# 이상치 처리
# 학습데이터와 테스트 데이터를 분리
x_data_train, x_data_test, t_data_train, t_data_test = \
train_test_split(train.drop('label', axis=1, inplace=False).values,
train['label'].values,
test_size=0.3)
print(x_data_train, x_data_train.shape)
# 정규화 처리
scaler = MinMaxScaler()
x_data_train_norm = scaler.fit_transform(x_data_train)
x_data_test_norm = scaler.fit_transform(x_data_test)
# one-hot 처리
# print(t_data_train)
# one-hot 으로 바꾸게 되면 어차피 2차원으로 바뀌기 때문에, 테스트 데이터 분리할 때 굳이 t_data 를 1차원에서 2차원으로 변경하는 reshape 를 진행하지 않았다.
# depth 는 class의 수. 즉 분류의 개수
# print(tf.one_hot(t_data_train, depth=3))
# tf.one_hot() 함수의 결과값은 numpy 가 아니라 Tensor 로 감싸진 값이 나오게 된다.
# 따라서, Tensor 에서 numpy 값을 추출해야 한다.
t_data_train_onehot = tf.one_hot(t_data_train, depth=3).numpy()
t_data_test_onehot = tf.one_hot(t_data_test, depth=3).numpy()
# model 만들기
model = Sequential()
# 레이어 추가
model.add(Flatten( input_shape=(2,)))
model.add(Dense(3, activation='softmax'))
# 환경설정
model.compile(optimizer=Adam(learning_rate=1e-3),
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_data_train_norm,
t_data_train_onehot,
epochs=500,
validation_split=0.3,
verbose=1)
# model 의 마지막 평가 => evaluation
model.evaluate(x_data_test_norm, t_data_test vonehot) model 를 학습시킬 때(model.fit) 중요하게 봐야 할 것은 val_loss 와 val_accuracy. 이 두 개의 값이 실시간으로 중간평가를 하면서 loss 값과 정확도를 측정하는 값이기 때문이다.
또한 위의 예제와 같이 t_data 를 one-hot 으로 별도로 처리하지 않더라도 model 의 환경설정 시에 사용하는 loss 함수에서 sparse_categorical_crossentropy 로 입력하게 되면.
즉 기존의 categorical_crossentropy 에서 sparse 를 추가하게 되면 함수 내부적으로 인자로 받은 t_data 를 one-hot 처리를 시켜 값을 출력한다.
# model 만들기
model = Sequential()
# 레이어 추가
model.add(Flatten( input_shape=(2,)))
model.add(Dense(3, activation='softmax'))
# 환경설정
model.compile(optimizer=Adam(learning_rate=1e-3),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# loss 함수 이름으로 `sparse` 를 추가하게 되면 별도로 one-hot 으로 구분하지 않아도 정상적으로 코드 실행이 진행된다.
model.fit(x_data_train_norm,
t_data_train,
epochs=500,
validation_split=0.3,
verbose=1)이미지 처리
-> 비정형 데이터의 처리
MNIST
: 이미지 데이터셋을 이용한 다중 분류 문제
여기서 이미지 데이터셋은 사람이 손글씨로 숫자를 쓴 이미지를 의미한다.
Color 이미지의 경우, RGB 를 통해 3개의 값을 가지고 색을 표현한다.
이 Color 이미지를 데이터셋으로 변경할 경우 3차원 데이터로 표현이 된다.
흑백 이미지의 경우, 0/1 중 한 개의 값을 가지고 표현할 수는 있지만 많이 사용하지는 않는다!
반면에 한 개의 값을 사용하되 범위를 0~255 로 잡아서 표현할 수도 있다. 그 때 나오게 되는 것이 gray scale 이다.
머신러닝의 첫 번째는 형태를 파악한다.
이미지가 사람인지, 자동차인지, 고양이인지, 강아지인지.
이 때는 굳이 컬러 데이터가 아니어도 흑백 데이터를 가지고도 구분할 수 있기 때문에 흑백 데이터를 사용한다.
머신러닝은 행렬곱을 사용해야 하기 때문에 반드시 2차원 데이터가 필요했다.
[[
[r,g,b],
[r,g,b],
...]]
그런데 이미지의 경우 컬러데이터는 3차원이고, 여러 개의 이미지가 사용되다보니 4차원이 되었다.
그래서 이미지를 흑백 데이터로 바꿔서 2차원으로 했는데 여러 개의 이미지로 층을 쌓다보니 3차원이 되었다.
최종적으로 이미지를 1차원 데이터로 바꾸니 드디어 여러 장의 이미지로 행을 쌓더라도 2차원 데이터로 행렬곱이 사용할 수 있게 되었다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense
from tensorflow.keras.optimizers import Adam
df = pd.read_csv('./data/230404/train.csv')
display(df.head(), df.shape)
# training Data Set
x_data_train, x_data_test, t_data_train, t_data_test = \
train_test_split(df.drop('label', axis=1, inplace=False).values,
df['label'].values,
test_size=0.2)
# 결측치 / 이상치는 존재하지 않음
scaler = MinMaxScaler()
x_data_train_norm = scaler.fit_transform(x_data_train)
x_data_test_norm = scaler.fit_transform(x_data_test)
model = Sequential()
model.add(Flatten(input_shape=(784,)))
model.add(Dense(10, activation='softmax'))
model.compile(optimizer=Adam(learning_rate=1e-4),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_data_train_norm,
t_data_train,
epochs=500,
validation_split=0.2,
verbose=1,
batch_size=100)
# 많은 이미지 데이터의 정보를 한 번에 받을 수가 없다. 42000개의 데이터 행이 있다면 100개를 input_layer 에 넣어서 처리하고 다시 100개를 input_layer에 넣는...
# 그렇게 해서 100개의 데이터를 읽는 과정을 420번 반복하면 1번의 epochs 가 종료된다.
# 이러한 처리 방식을 batch
print(model.evaluate(x_data_test_norm, t_data_test))과적합(Overfitting)
epochs, 즉 반복의 횟수가 많아질수록 기준을 잡게 되는 구분선이 너무 과도하게 정밀해진다. 그러면 기준선을 기준으로 0/1 이라는 binary 구분을 해야 하는데 학습된 값을 기준으로 구분을 하게 되어 버린다.
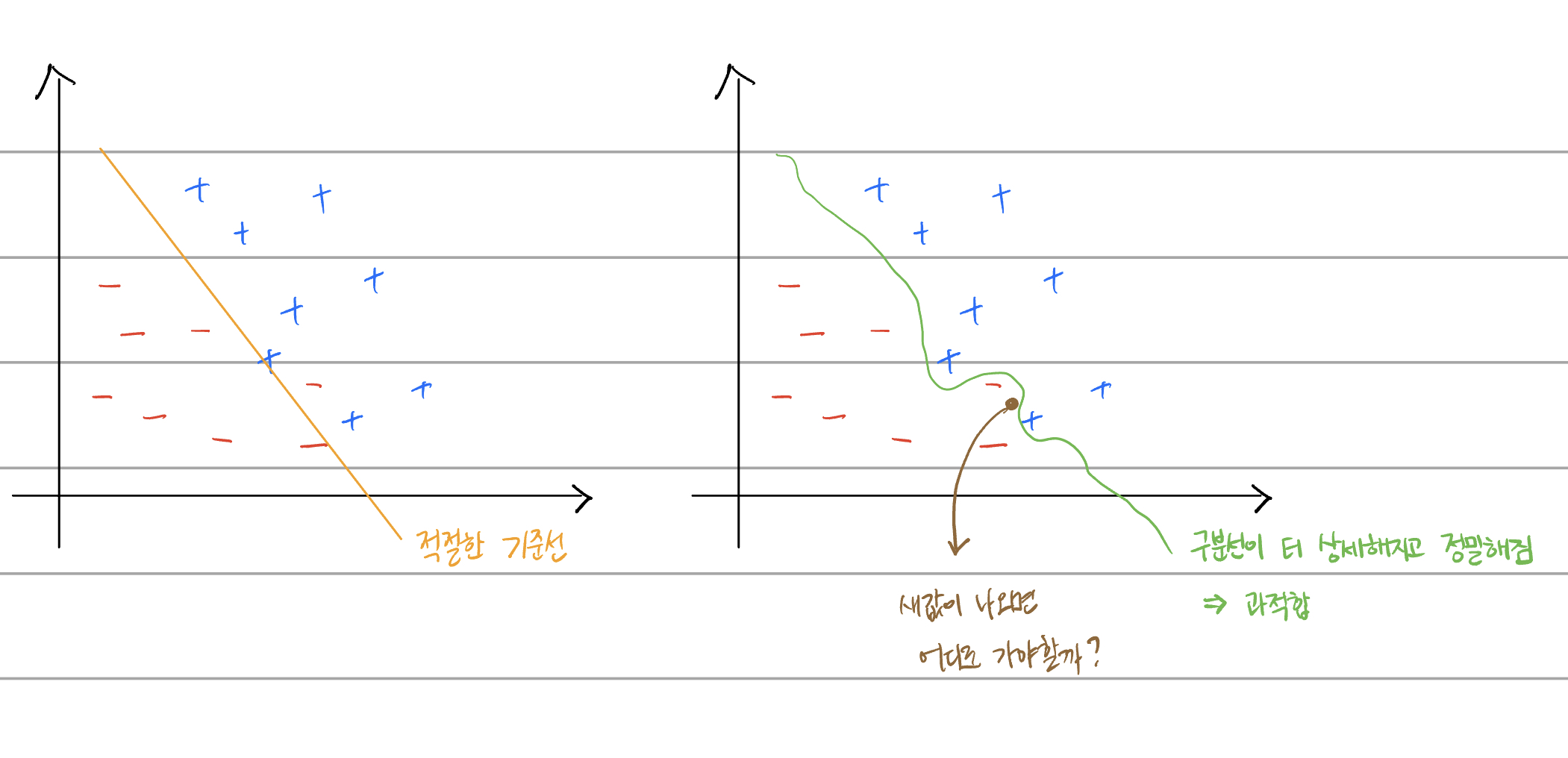
결론적으로 비정형 데이터는 일반 머신러닝 기법을 이용하면 학습에 효율(정확도)이 많이 떨어진다.
이를 해결할 방법이 뭐가 있을지 찾다가 발견한 것이 NN
Hidden Layer
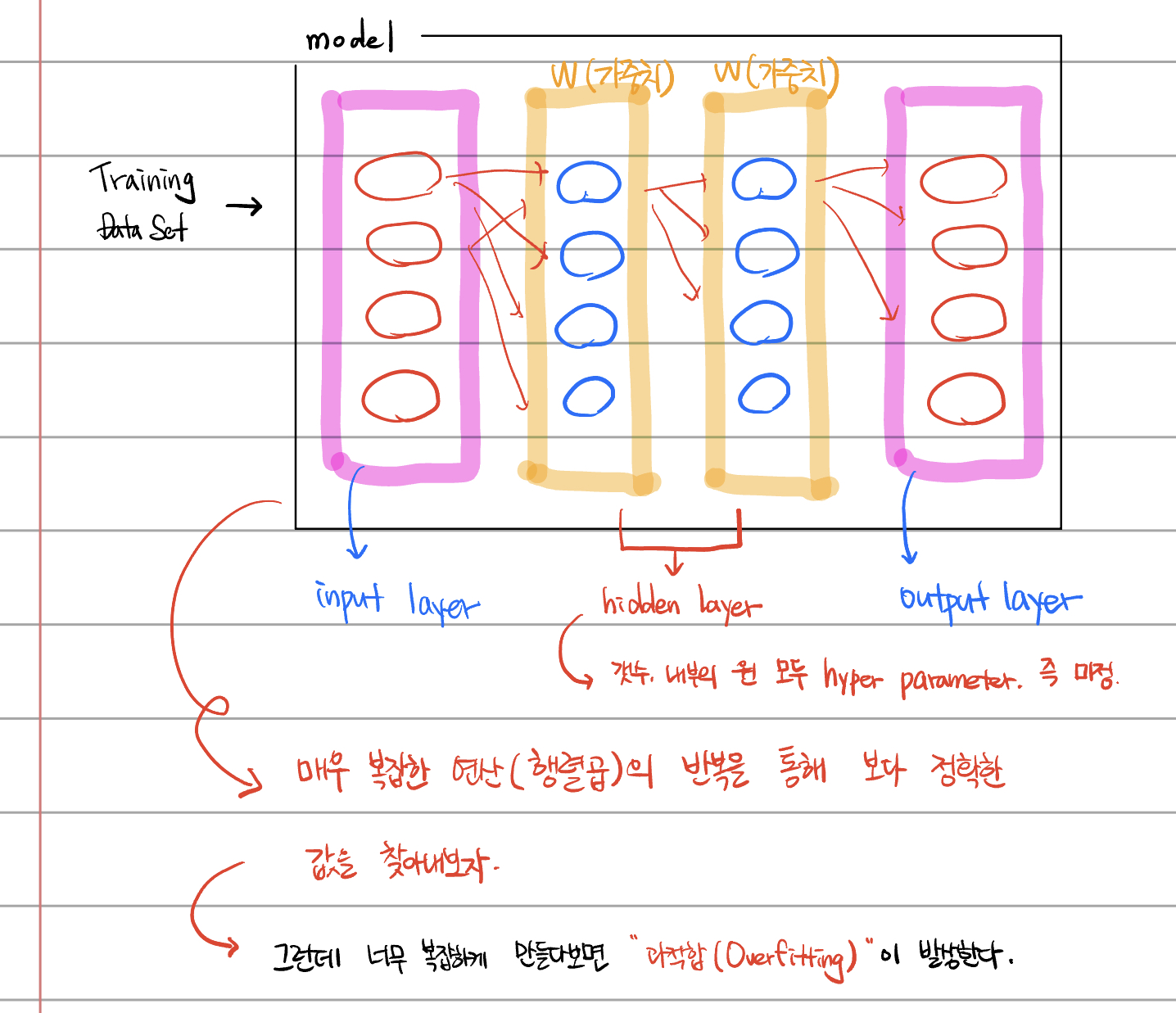
hidden layer 는 1개가 들어갔을 때 효율이 가장 좋다.
2개가 들어갈 경우, 1개 넣었을 때보다 0.7배 만큼 더 정확해진다고 한다.
# input layer
model.add(Flatten(input_shape=(784,)))
#hidden layer
model.add(Dense(256, activation='relu'))
model.add(Dense(128, activation='relu'))
model.add(Dense(64, activation='relu'))
# output layer
model.add(Dense(10, activation='softmax'))hidden layer 는 Dense layer 를 사용한다.
Dropout Layer
from tensorflow.keras.layers import Dropout
# Dropout
model.add(Dropout(rate=0.25))과적합을 방지하기 위해 새로운 layer 를 추가
dropout 이라는 방법을 통해서 연산을 할 때 모든 레이어의 연산을 하는 것이 아니라,
일부의 연산을 제거하여 과적합을 방지하도록 진행한 것.
model.summary()
내 전체 모델의 형태를 요약해서 보여준다.
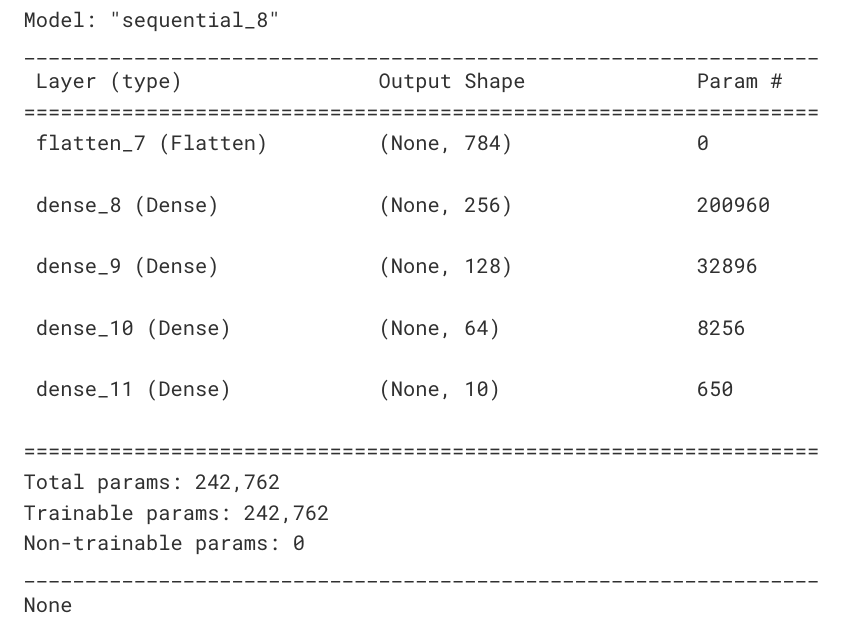
param의 갯수는 즉 w와 b. param 1개 당 한 번의 편미분을 하게 되기 때문에 약 24만 개의 param 에 대한 편미분을 진행하게 된다.
때문에 너무나 많은 param 값이 나온다면, 그것을 조절해주어야 한다.
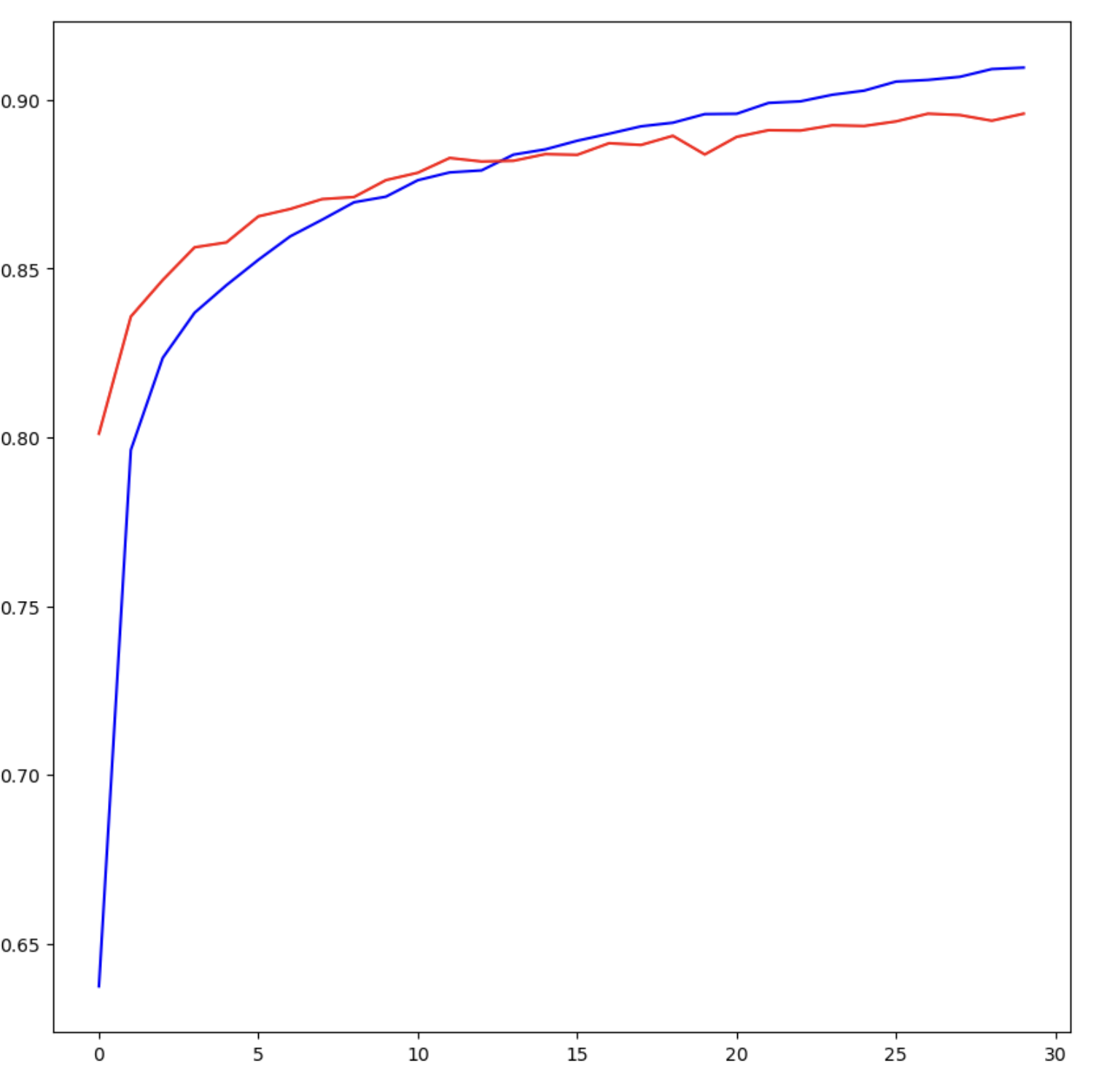
model 의 학습 과정을 그래프로 확인하는 방법
# 학습된 결과를 그래프로 확인해보자
# figsize 는 가로/세로 의 길이를 의미
fig = plt.figure(figsize=(10, 10))
# fig 안에 그림을 그리려면 subplot 를 포함시켜야 한다.
# subplot 은 그림을 그리는 영역을 의미한다.
# 만약 1, 2, 1 이라고 쓰면 1행의 2열/ 즉 2개로 나누어서 그림을 그리겠다는 의미.
fig_acc = fig.add_subplot(1,1,1)
# history(변수. 학습된 모델명).history(모델에는 history 라는 함수가 있다.)
# epochs 가 즐가할 때 마다 나오는 accuracy 와 val_accuracy 를 그래프로 그리겠다.
fig_acc.plot(history.history['accuracy'], color='b')
fig_acc.plot(history.history['val_accuracy'], color='r')
fig.show()
# 파란 선은 학습데이터로 학습을 한 다음 그 학습 데이터로 평가한 것
# 빨간 선은 학습데이터로 학습을 한 다음 별도로 분리한 validation 데이터로 평가한 것
# 때문에 blue 선 보다 red 선의 정확도가 떨어질 수 밖에 없다.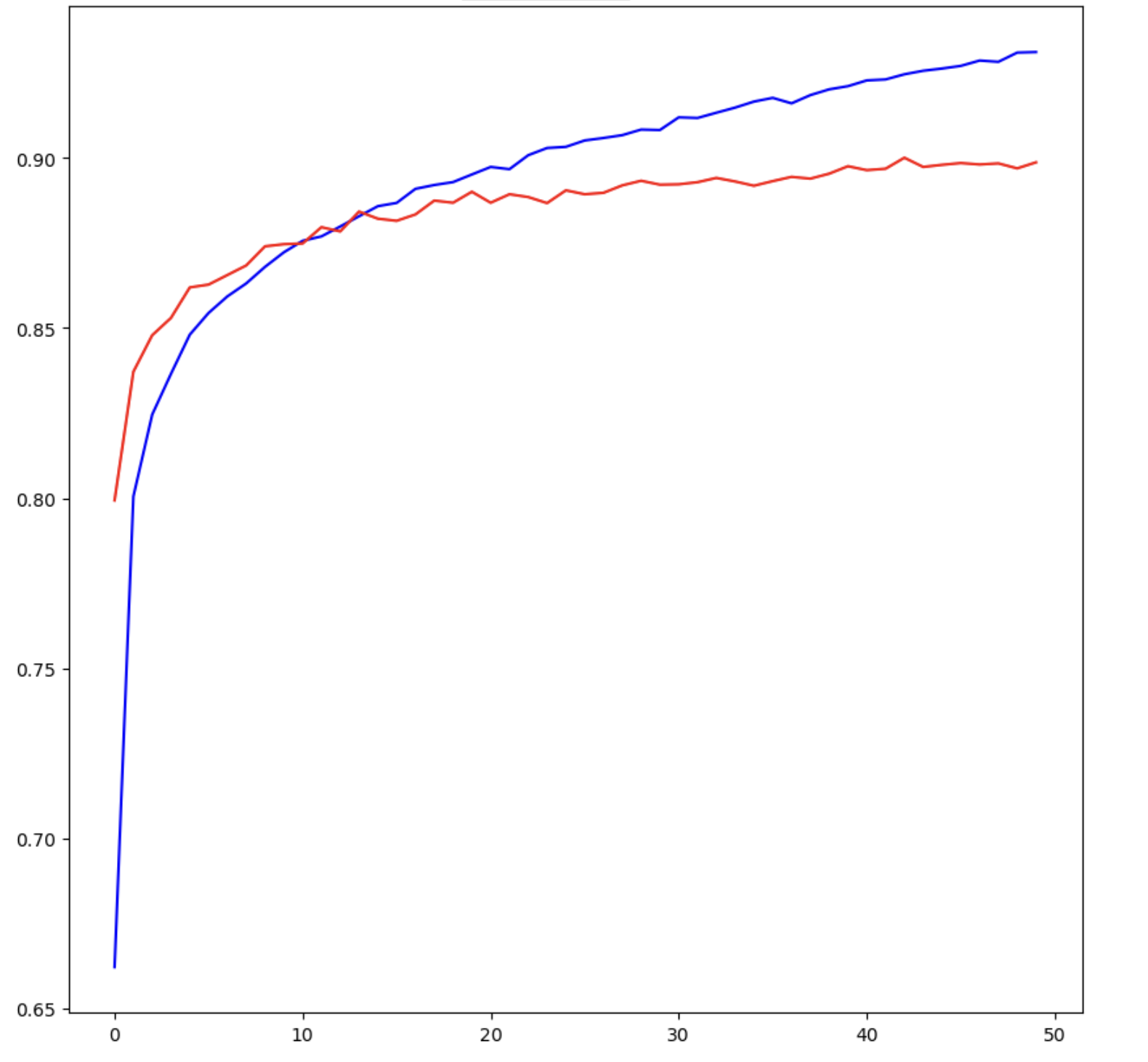
중요하게 봐야할 것은 빨간색 선이다.
서서히 증가하는 과정에서 선이 수평으로 가까워질수록 Overfitting 이 발생한다고 보면 된다.
가장 이상적인 것은 accuracy 와 val_accuracy 가 동시에 서서히 상승해가는 것이 이상적이다.
그렇기 때문에 해당 그래프를 기준으로 본다면 epochs가 20~30회를 넘어가면 과적합이 발생한다고 볼 수 있다.
이를 다른 관점에서 보면 모델을 만들어가는 과정에서 몇 번의 epochs 가 적절할 지, 그 숫자가 몇일지 결정하는 것이 너무 어렵다.
그냥 경험적으로 혹은 여러 번 돌려보면서 테스트를 해야할까? -> 만약 데이터가 미친 듯이 많으면 학습에 시간이 과도하게 소모된다. 이런 경우 수작업은 당연히 불가능해진다.
개인이 반복의 숫자를 정하는 것이 아니라, 일정 기준을 달성하면 epochs(반복)이 멈추게 되는 로직이 필요해진다.
그래서 등장한 기능이 Early Stopping 기능이다. 이 기능 역시 keras 가 제공해준다.
Early Stopping
from tensorflow.keras.callbacks import EarlyStopping
# loss 는 epochs 가 증가할수록 값이 떨어져야 한다.
# 근데 반복을 돌고 있는데도 loss 값이 떨어지지 않는다면
# 결국 반복의 의미가 없다. 즉 멈춰야 한다.
# patience 는 monitor 를 하고 있는 값이 변화하지 않았을 때 몇 번동안 기다릴것인지.
# restore_best_weights weights 값이 가장 좋았던 값을 복원하는 것. 즉 반복을 도는 과정에서 loss 값이 가장 낮은 값을
# 기억했다가 다시 사용하는 것.
my_early_stopping = EarlyStopping(monitor='val_loss',
patience=3,
mode='auto',
restore_best_weights=True,
verbose=1)
history = model.fit(x_data_train_norm,
t_data_train,
epochs=50,
validation_split=0.2,
verbose=1,
callbacks=[my_early_stopping],
batch_size=100)Epoch 1/50
384/384 [==============================] - 1s 3ms/step - loss: 1.0507 - accuracy: 0.6374 - val_loss: 0.6056 - val_accuracy: 0.8010
Epoch 2/50
384/384 [==============================] - 1s 3ms/step - loss: 0.5901 - accuracy: 0.7962 - val_loss: 0.4900 - val_accuracy: 0.8357
Epoch 3/50
384/384 [==============================] - 1s 3ms/step - loss: 0.5092 - accuracy: 0.8235 - val_loss: 0.4461 - val_accuracy: 0.8466
...
Epoch 27/50
384/384 [==============================] - 1s 3ms/step - loss: 0.2595 - accuracy: 0.9058 - val_loss: 0.2952 - val_accuracy: 0.8958
Epoch 28/50
384/384 [==============================] - 1s 3ms/step - loss: 0.2541 - accuracy: 0.9067 - val_loss: 0.2971 - val_accuracy: 0.8954
Epoch 29/50
384/384 [==============================] - 1s 3ms/step - loss: 0.2523 - accuracy: 0.9090 - val_loss: 0.3037 - val_accuracy: 0.8938
Epoch 30/50
383/384 [============================>.] - ETA: 0s - loss: 0.2489 - accuracy: 0.9095Restoring model weights from the end of the best epoch: 27.
384/384 [==============================] - 1s 3ms/step - loss: 0.2492 - accuracy: 0.9095 - val_loss: 0.2960 - val_accuracy: 0.8958
Epoch 30: early stopping
학습이 들어가기 전에 Early Stopping 객체를 만든다. 그 후에 내가 만든 모델이 학습할 때(fit) callbacks=[내가 만든 early stopping 객체] 를 추가해준다.