[Paper Review] Target Item-Oriented Conditional Diffusion Differential Transformer for Next-Item Prediction
Paper Review
Abstract
순차적 추천 : 사용자의 과거 상호작용과 동적 선호도를 학습하여 개인하된 다음 아이템을 예측하는 것을 목표로 함.
다중행동 SR : 다양한 유형의 사용자 상호작용을 고려하여 사용자 관심사를 더 풍부하게 포착하고 데이터 희소성 문제를 완화할 수 있음.
MBSR 접근 방식의 문제점 : 사용자 관심사와 직접적으로 관련된 target item의 중요성을 간과함.
-> 사용자의 진짜 선호를 반영하는 타깃 아이템 기반 표혀 능력이 제한적이라는 문제 존재함.
타깃 아이템 지향 조건부 확산 미분 Transformer(ICDDT)
-> Diffusion 모델을 통해 타깃 아이템 정보를 분포 표현으로 주입하여, 훈련 과정에서 사용자 선호를 더 효과적으로 캡처할 수 있게 한다.
- 확산 단계에서 행동 유형 간의 샘플링 분포를 구별 -> 행동 인식 샘플링 달성
- 새로운 상호작용 시퀀스, 목표 행동, 확산 단계를 결합하는 세 가지 유형의 상호작용을 도입
-> 미분 Transformer 기반 근사기의 훈련을 정교하게 유도하며, 사용자 개인화 정보로서의 분포 표현을 학습. - Adaptive Truncation 기법 -> 샘플링 분포를 단순화, 추론과정 가속화
1. Introduction (서론)
- 고정 벡터만을 이용한 제한된 표현 능력
MBSR에서 많은 모델은 아이템을 표현하기 위해 고정 벡터에 의존한다. 그러나 이러한 벡터는 아이템의 잠재 특성이나 사용자 선호의 다양성과 불확실성을 충분히 포착하지 못한다.
-> 분포를 활용하는 대체적 표현 방식이 필요하다.
연구 배경
Diffusion Model
- 확산(diffusion) 모델은 뛰어난 표현력과 생성 능력으로 주목받아옴. -> 사후 붕괴(posterior collapse)를 방지
분포 표현을 도입 -> 확산 모델은 다차원(latent) 잠재 특징과 다양한 사용자 선호를 효과적으로 포착 - 확산 모델은 훈련 과정에서 타깃 아이템을 도입하는 데 유리 -> 추론 단계에서 모든 후보 아이템을 입력으로 보정할 필요 없이 순수한 노이즈에서부터 시작해 학습할 수 있기 때문
- 확산 모델의 마코프 체인 기반 점진적(stepwise) 노이즈 추가/제거 과정은 SR(Task)의 동적 특성과 연관
기존의 연구?
SR 연구들 중 일부는 diffusion모델과 distribution 표현을 활용해서 훈련과정에서 타깃 아이템 정보를 효과적으로 사용하는 데 성공
but, 사용자 행동들은 서로 다른 의도와 선호 수준을 내포 -> 확산 기반 SR 모델을 그대로 MBSR에 적용하면 최적 성능에 도달하지 못할 위험
MBSR : 행동 간 이질성이 크므로, 확산 단계에서의 노이즈 주입과 역과정에서의 복원 과정 모두에서 행동별 특수 처리 필요함.
ex) MISD : 현재까지 유일한 확상 기반 MBSR 모델 -> 다중 관심사(multi-interest) 모델링에 초점
행동 특화 모델링 측면 -> MISD는 단순히 과거 시퀀스에 행동 임베딩을 넣고,확산 모델 자체는 행동 유형을 고려하지 않는 행동-불가지론적(behavior-agnostic) 방식
그 결과, 행동 유형에서 기인하는 풍부한 정보를 충분히 활용하지 못함
- 단순한 통합 방식은 MBSR 작업에서 확산 모델의 효과를 제한 + 이질적 행동들 아래에서의 사용자 선호의 다양성과 복잡성을 온전히 포착하기 어렵
- 타깃 상호작용 데이터의 비활용 문제
- 고정 벡터만을 사용했을 때의 표현력 제한 문제
-> 타깃 아이템 지향 조건부 확산 미분 Transformer(ICDDT)를 MBSR용으로 제안
타깃 아이템 지향 조건부 확산 미분 Transformer(ICDDT)
타깃 아이템 임베딩을 diffuse , 역방향 복원 단계에서 노이즈 제거된 표현을 재구성
-> 타깃 아이템 기반 사용자 관심사 학습(target item-guided user interest learning)
1. Diffusion Phase
높은 신뢰도(high-confidence) 행동 : 구매처럼 사용자의 강하고 확신 있는 관심
낮은 신뢰도(low-confidence) 행동 : view, add-to-cart와 같이 사용자의 선호에 다소 불확실성이 있는 행동
-> 모델은 행동별로 더 적절한 확산 단계를 선택하게 되고, 다양한 행동 아래에서 사용자의 잠재적 선호를 더 효과적으로 포착가능
2. Reverse phase
세 가지 조건 (상호작용 시퀀스, 타깃 행동, 확산 단계)를 도입해, 조건부 미분 Transformer 기반 근사기가 노이즈 제거된 타깃 아이템 표현을 재구성하도록 유도함. -> 재구성된 표현 - 사용자의 실제 선호와 개인화된 관심 반영 가능
3. Inference step 수 설정
추론속도 가속화
확산 단계 샘플링 분포가 전체 확산 단계보다 더 적은 스텝을 사용하는 비균일 감소 분포와 일치함. (non-uniform decreasing sep sampling distribution)
주요 기여
(1) 새로운 확산 기반 이중 타깃 인식 프레임워크(ICDDT) 제안
벡터 기반 표현의 한계를 극복하기 위해 분포 표현(distribution representations)을 도입하고,
타깃 아이템과 타깃 행동 정보를 모두 활용하여 사용자의 실제 선호를 포착한다.
(2) 확산 단계에서 행동 인식 베타 분포 설계
고신뢰도 행동과 저신뢰도 행동 각각에 적절한 확산 단계를 샘플링할 수 있어
개인화 수준(personalization)을 행동마다 다르게 유지할 수 있다.
(3) 역확산 단계에서 세 조건을 기반으로 한 근사기 설계
상호작용 시퀀스 + 타깃 행동 + 확산 단계의 세 가지 조건을 이용하여
노이즈 제거된(de-noised) 타깃 아이템 표현을 정교하게 재구성한다.
(4) 추론 가속을 위한 스텝 (truncation) 기법 도입
확산 단계 샘플링 분포와 일치하도록 추론 단계를 줄여
추론 속도를 향상시킨다.
확산 모델은 원래 수백 수천 스텝을 거쳐야 하는데 추천 시스템은 실시간성을 필요로 하기 때문에 샘플링 분포를 분석해서 실제로 중요한 것은 소수의 스텝임을 확인
(5) 두 개의 실제 데이터셋에서 실험
ICDD T는 최신 SOTA 모델들보다 유의미한 성능 향상을 보여주었다.
Related Work
2.1 Sequential Recommendation
순차적 추천(Sequential Recommendation, SR) : 사용자의 과거 상호작용 속에서 나타나는 아이템 전이 패턴을 포착하기 위해 제안
-> RNN, GRU, Attention 등 딥러닝 기반 방법을 활용해 시퀀스를 모델링함.
SASRec : 스택된 self-attention 블록을 활용하여 장기 의존성(long-term dependency)을 포착한, 선구적인 연구 중 하나
최근에는 확산 모델(diffusion models) 이 더 일반화된 분포 표현(distribution representation)을 생성할 수 있는 능력 덕분에 큰 관심
현재 확산 기반 SR 연구
1. 아이템 시퀀스를 확산의 입력 주제로 사용하는 방식 (item sequences as diffusion subjects)
주로 확산 모델을 데이터 증강 관점에서 사용하는 방향
예: PDRce[19], DiffuASR[17]
2. 타깃 아이템 확산을 위한 가이드로 시퀀스 인코딩을 사용하는 방식
아이템 시퀀스를 시퀀스 인코더로 먼저 인코딩한 후, 그 표현이 역확산(reverse) 과정을 가이드하는 데 사용된다.
예: DreamRec[37], SdiRec[33], DimeRec[14]
3. 아이템 임베딩을 타깃 아이템 확산 가이던스로 사용하는 방식
Transformer와 같은 시퀀스 인코더를 사용해 타깃 아이템의 표현을 재구성하는 근사기를 만든다.
예: DiffuRec[15], DiQDiff[20]
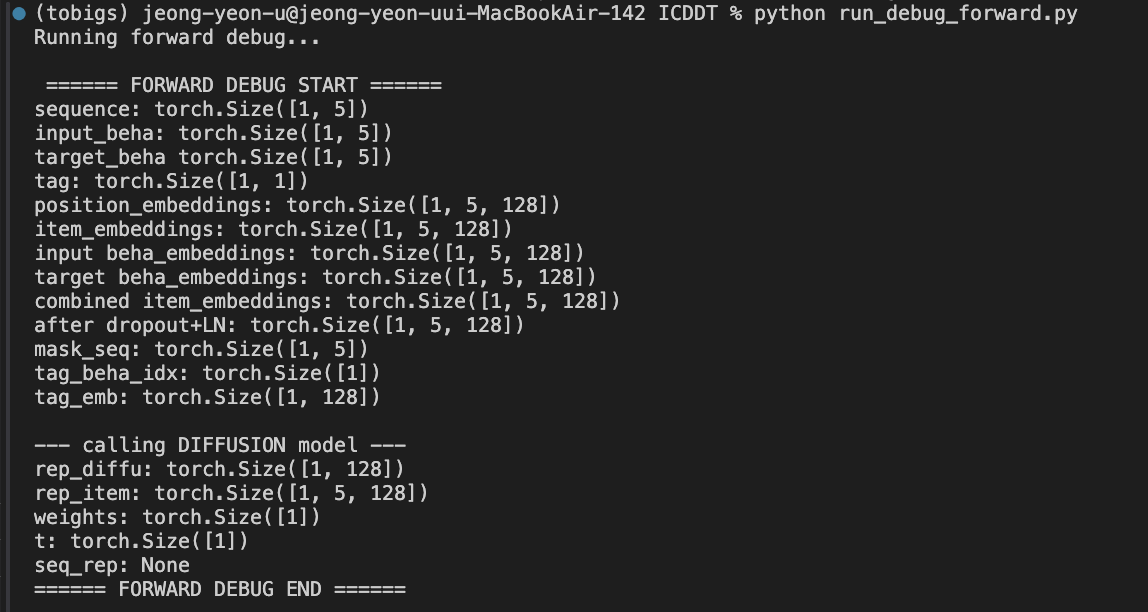
3.2 Framework Overview
(i) 타깃 아이템 기반 사용자 관심사 학습(Target item–guided user interest learning)
타깃 아이템 임베딩을 확산시키고,
역확산(reverse) 단계에서 노이즈 제거된 타깃 아이템 표현을 재구성함으로써
사용자의 잠재적 관심사(latent behavioral interests)를 행동 aware 방식으로 더 잘 포착한다.
기존 MBSR 모델들과 달리,
우리 모델은 타깃 정보의 분포 표현(distribution representation)을 도입해
타깃 아이템을 더 효과적으로 활용한다.
(ii) 행동-aware 확산 단계 선택 (Behavior-aware step selection)
확산 단계의 Beta 샘플링 분포를 행동별로 다르게 설계하고, 사용자의 행동 유형(조회/장바구니/구매 등)에 따라 적절한 확산 단계를 선택한다.
이는 단순히 전체 확산 단계를 모두 사용하는 기존 SR 방식과 달리, 각 행동 유형의 잠재적 선호 차이를 더 정확히 포착하게 해준다.
(iii) 조건 기반 역확산 (Multi-condition guidance)
역확산 단계에서는 사용자 시퀀스, 타깃 행동, 확산 단계 이 세가지 조건을 모두 활용해 타깃 아이템의 노이즈 제거 표현을 조건부로 재구성
-> 기존 SR보다 훨씬 정교한 개인화 표현 생성 가능
(iv) 추론 단계 단축 (Step truncation)
확산 단계 샘플링 분포를 분석해, 실제로 필요한 단계 수만 남기고 불필요한 단계를 제거하여 추론 속도 크게 개선.
-> 뭐가 필요하고 뭐가 불필요한지는 어떤 기준으로 선정하는지?
코드 구현

class AddLayerNorm(nn.Module):
def __init__(self, hidden_size, args):
super(AddLayerNorm, self).__init__()
self.hidden_size = hidden_size
self.dropout = nn.Dropout(args.dropout)
self.norm_seq = LayerNorm(self.hidden_size)
self.linear = nn.Linear(self.hidden_size*2, 2) # 0 for scale, 1 for shift
def forward(self, x, target_beha_rep, t_emb):
# t_emb = t_emb.unsqueeze(1).repeat(target_beha_rep.shape)
target_beha_rep = target_beha_rep[:, -1, :] # 마지막 행동 스텝만 사용함.
c = self.linear(th.cat([target_beha_rep, t_emb], dim=-1))
output = self.norm_seq(self.dropout(x))
# print(c.shape)
# print(output.shape)
output = c[:, 0].unsqueeze(1).unsqueeze(2) * output + c[:, 1].unsqueeze(1).unsqueeze(2)
return output # [B, D]
두 개의 attention(Q1K1, Q2K2)을 계산하고, 그 차이(att1 - λ·att2)를 사용하면
시계열/행동 데이터의 노이즈 부분이 제거된다.
- att1 = "signal + noise 포함"
- att2 = "noise 패턴을 더 많이 반영"
- att = att1 - lambda * att2 = 노이즈를 제거한 attention score
-> 더 선명한 representation을 얻을 수 있음.
# Multi-head Differential Attention
class MultiHeadDiffAttention(nn.Module):
def __init__(self, heads, hidden_size, dropout, layer_idx):
super().__init__()
assert hidden_size % heads == 0
self.heads = heads
self.head_size = hidden_size // heads
self.lambda_init = lambda_init(layer_idx) # 람다 초기값이 layer맏 다름 -> 논문에서 제안한 시간 기반 weighting
# split qkv
self.q1_proj = nn.Linear(hidden_size, hidden_size)
self.q2_proj = nn.Linear(hidden_size, hidden_size)
self.k1_proj = nn.Linear(hidden_size, hidden_size)
self.k2_proj = nn.Linear(hidden_size, hidden_size)
self.v_proj = nn.Linear(hidden_size, 2 * hidden_size) # V projects to 2 * hidden_size
self.c_proj = nn.Linear(2 * hidden_size, hidden_size)
self.attn_dropout = nn.Dropout(dropout)
self.resid_dropout = nn.Dropout(dropout)
# self.subln = nn.LayerNorm(2 * self.head_size, elementwise_affine=False)
self.subln = LayerNorm(2 * self.head_size)
# Init λ across heads
self.lambda_q1 = nn.Parameter(torch.randn(heads, self.head_size) * 0.1)
self.lambda_k1 = nn.Parameter(torch.randn(heads, self.head_size) * 0.1)
self.lambda_q2 = nn.Parameter(torch.randn(heads, self.head_size) * 0.1)
self.lambda_k2 = nn.Parameter(torch.randn(heads, self.head_size) * 0.1)
self.initializer_range = 0.02
self.apply(self._init_weights)
def _init_weights(self, module):
"""Initialize the weights"""
if isinstance(module, (nn.Linear, nn.Embedding)):
# Slightly different from the TF version which uses truncated_normal for initialization
# cf https://github.com/pytorch/pytorch/pull/5617
module.weight.data.normal_(mean=0.0, std=self.initializer_range)
elif isinstance(module, LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
if isinstance(module, nn.Linear) and module.bias is not None:
module.bias.data.zero_()
def forward(self, q, k, v, mask=None):
B, T, C = q.shape
# Project x to get q1, q2, k1, k2, v
q1 = self.q1_proj(q).view(B, T, self.heads, self.head_size).transpose(1, 2)
q2 = self.q2_proj(q).view(B, T, self.heads, self.head_size).transpose(1, 2)
k1 = self.k1_proj(k).view(B, T, self.heads, self.head_size).transpose(1, 2)
k2 = self.k2_proj(k).view(B, T, self.heads, self.head_size).transpose(1, 2)
v = self.v_proj(v).view(B, T, self.heads, 2 * self.head_size).transpose(1, 2)
scale = 1.0 / math.sqrt(self.head_size)
att1 = torch.matmul(q1, k1.transpose(-2, -1)) * scale
att2 = torch.matmul(q2, k2.transpose(-2, -1)) * scale
if mask is not None:
mask = mask.unsqueeze(1).repeat([1, att1.shape[1], 1]).unsqueeze(-1).repeat([1,1,1,att1.shape[-1]])
att1 = att1.masked_fill(mask == 0, -1e9) # float('-inf'))
att2 = att2.masked_fill(mask == 0, -1e9) # float('-inf'))
att1 = F.softmax(att1, dim=-1)
att2 = F.softmax(att2, dim=-1)
# Compute λ for each head separately
lambda_1 = torch.exp(torch.sum(self.lambda_q1 * self.lambda_k1, dim=-1)).unsqueeze(-1).unsqueeze(-1)
lambda_2 = torch.exp(torch.sum(self.lambda_q2 * self.lambda_k2, dim=-1)).unsqueeze(-1).unsqueeze(-1)
lambda_full = lambda_1 - lambda_2 + self.lambda_init
att = att1 - lambda_full * att2
att = self.attn_dropout(att)
y = torch.matmul(att, v) # [B, heads, T, 2 * head_size]
y = self.subln(y)
y = y * (1 - self.lambda_init)
y = y.transpose(1, 2).contiguous().view(B, T, 2 * C)
y = self.resid_dropout(self.c_proj(y)) # Value dimension이 2C → 다시 C로 projection
return y


import torch
from model import create_model_diffu, Att_Diffuse_model
import argparse
# 1) dummy args 생성
args = argparse.Namespace(
hidden_size=128,
item_num=100,
beha_num=5,
max_seq_length=10,
emb_dropout=0.1,
dropout=0.1,
initializer_range=0.02,
output_dir='./debug_save/',
dataset='debug',
# Transformer
n_layers=2,
n_heads=2,
# Diffusion
diffusion_steps=4,
gamma=1.0,
aux_alpha=1.0,
tar_alpha=1.0,
aux_beta=1.0,
tar_beta=1.0,
schedule_sampler_name="behaaware",
lambda_uncertainty=0.001,
noise_schedule="trunc_lin",
rescale_timesteps=True,
# other
no=0
)
# 2) diffusion 모델 생성
diffu = create_model_diffu(args)
# 3) 전체 모델 생성
model = Att_Diffuse_model(diffu, args)
# 4) dummy input 만들기
B = 1 # batch
L = 5 # sequence length
sequence = torch.randint(1, 30, (B, L))
input_beha = torch.randint(1, 3, (B, L))
target_beha = torch.randint(1, 3, (B, L))
tag = torch.randint(1, 30, (B, 1))
# 5) forward 디버그
print("Running forward debug...")
model.forward(sequence, input_beha, tag, target_beha, train_flag=True)