Paper Review
1.[Paper Review] Conditional Density Estimation for Tabular Data Synthesis using Masked Language Modeling
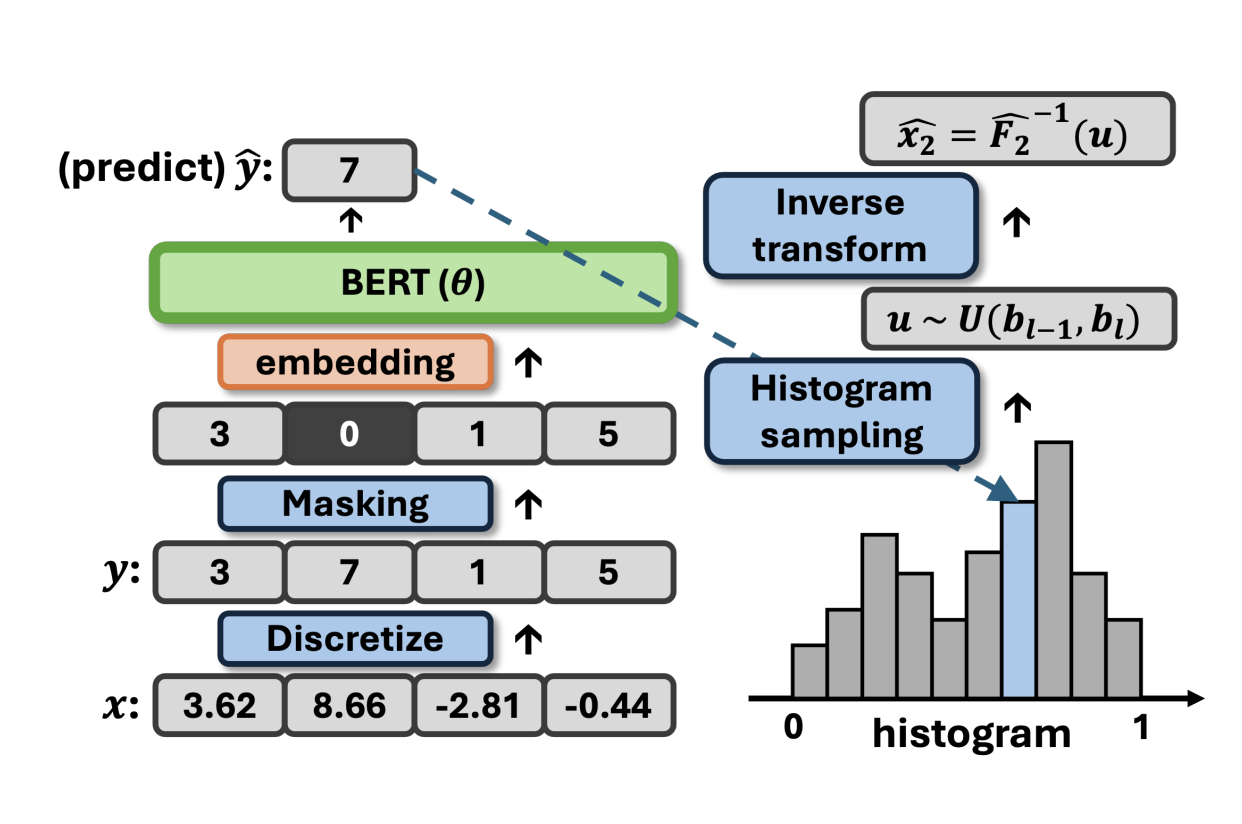
Abstract 본 논문의 목표 : MLu가 높은 이질적인 tabular data set에 대한 합성 데이터를 생성하는 것. MLu의 성능은 조건부 분포를 정확하게 근사하는 것에 달려 있기 때문에, 조건부 분포 추정에 기반한 합성 데이터 생성 방법을 고안하는 데 초점
2.[Paper Review] Deep Learning based Recommender System : A Survey and New Perspectives
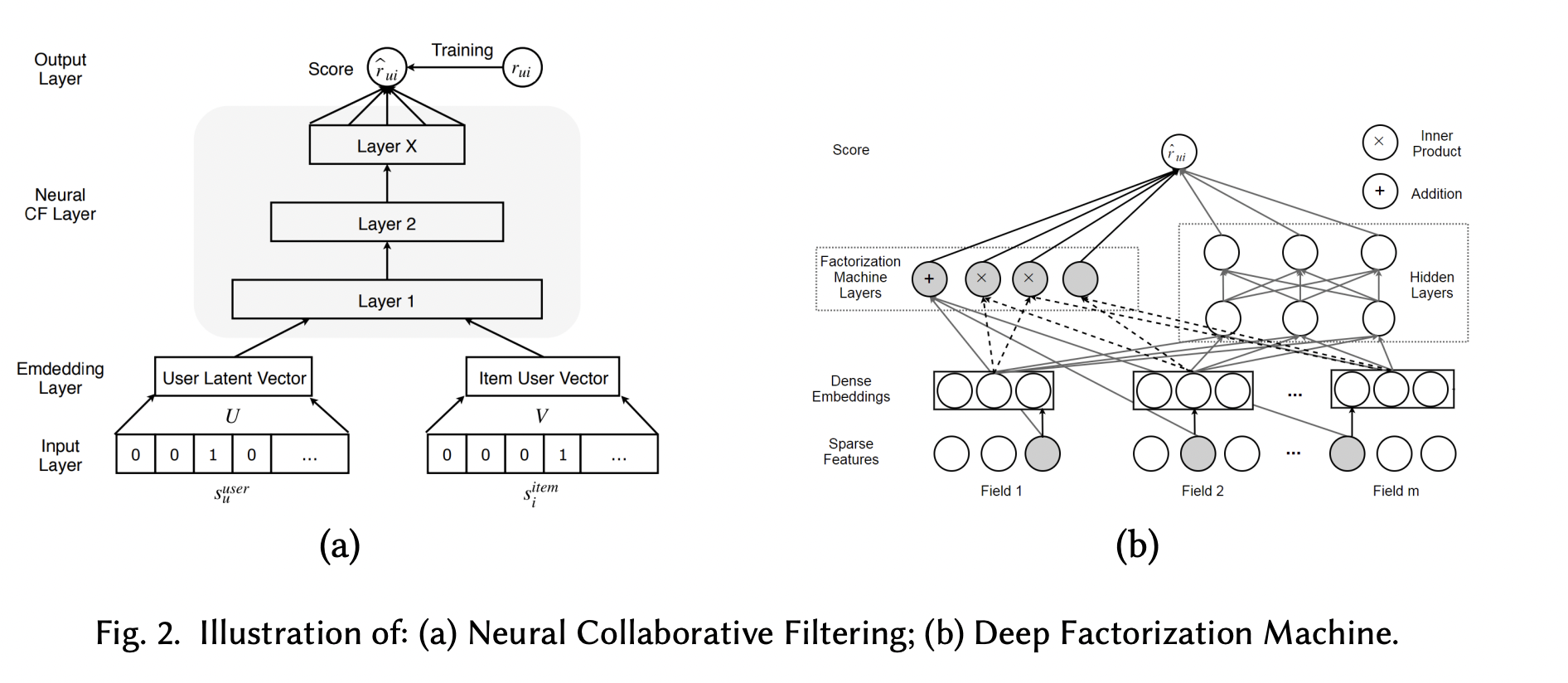
온라인 정보의 양이 폭발적으로 증가함에 따라, 추천 시스템은 정보 과부하를 극복하는 효과적인 전략으로 자리잡아 왔다. 웹 에플리케이션에서 추천 시스템의 유용성은 매우 크며, 특히 과도한 선택지 문제를 완화하는 데 중요한 역할을 한다. 최근 몇 년 동안 딥러닝은 컴퓨터
3.[Paper Review] Unicorn: U-Net for Sea Ice Forecasting with Convolutional Neural Ordinary Differential Equations
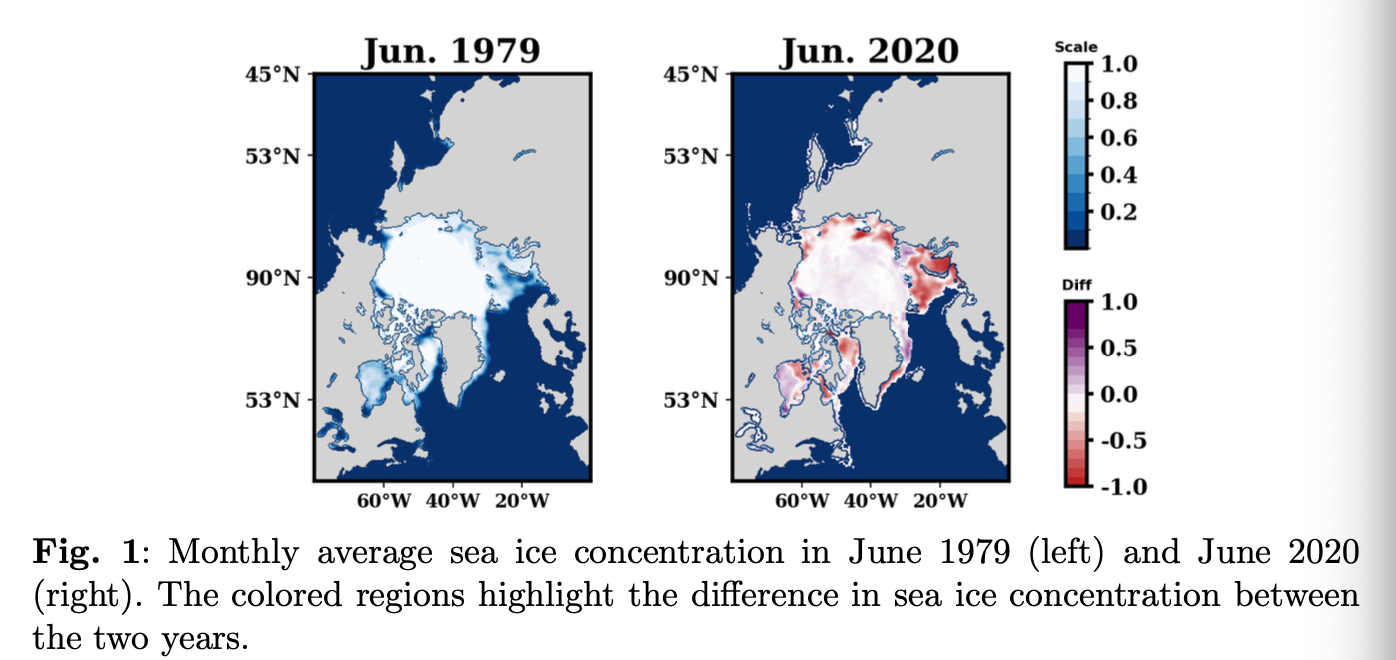
매주 해빙을 예측하기 위해 설계된 새로운 딥러닝 아키텍쳐인 'Unicorn' 소개\-> 예측 성능을 향상시키기 위해 다수의 시계열 이미지들을 아키텍처 내에 통합한다. 또한, U-Net 내에 bottleneck layer를 도입해, 컨볼루션 연산과 결합된 neural o
4.[Paper Review]A Self-Supervised Mixture-of-Experts Framework for Multi-behavior Recommendation

Multi-behavior recommendation, Self-supervised learning, Collaborative filtering, Miture of experts https://github.com/K-Kyungho/MEMBER e-commerce 환경에서는 사용자가 수많은 상품 중에서 어떤 것을 선택홰야 할지 어려움을 겪는다. 추천시스템은...
5.[Paper Review]Causal Discovery in the Presence of Missing Data
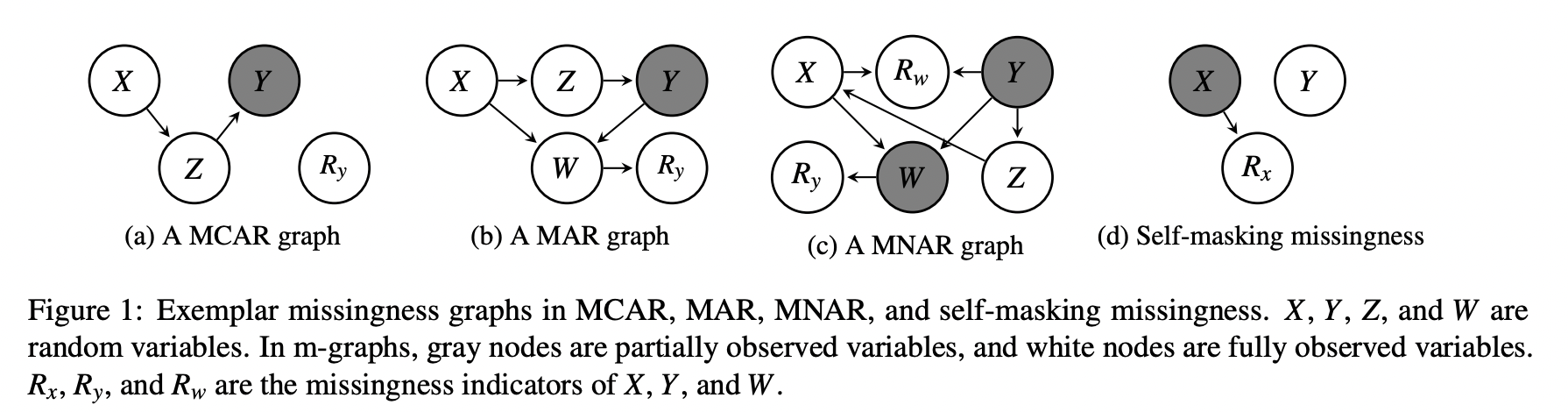
결측자료분석 수업의 논문 발표 과제를 위해 읽은 논문 Causal Discovery in the Presence of Missing DataKTH Royal Institute of Technology, 2Microsoft Research, Cambridge, 3Karo
6.[Paper Review] Target Item-Oriented Conditional Diffusion Differential Transformer for Next-Item Prediction
Abstract 순차적 추천 : 사용자의 과거 상호작용과 동적 선호도를 학습하여 개인하된 다음 아이템을 예측하는 것을 목표로 함. 다중행동 SR : 다양한 유형의 사용자 상호작용을 고려하여 사용자 관심사를 더 풍부하게 포착하고 데이터 희소성 문제를 완화할 수 있음. MBSR 접근 방식의 문제점 : 사용자 관심사와 직접적으로 관련된 target item의 중...