[Paper Review]A Self-Supervised Mixture-of-Experts Framework for Multi-behavior Recommendation
Paper Review
Multi-behavior recommendation, Self-supervised learning, Collaborative filtering, Miture of experts
https://github.com/K-Kyungho/MEMBER
e-commerce 환경에서는 사용자가 수많은 상품 중에서 어떤 것을 선택홰야 할지 어려움을 겪는다. 추천시스템은 사용자가 놓칠 수 있는 적합한 상품을 발견하도록 돕는 데 중요한 역할을 한다.
기존의 대부분의 추천 시스템은 사용자의 구매 이력에만 초점을 맞추지만,
Multi-behavior Recommender Systems의 경우 장바구니 추가, 클릭 등과 같은 보조적 사용자 행동도 함께 고려하여 추천을 개선한다.
하지만 이러한 시스템들은 전반적인 성능 향상에도 불구하고, 2가지 항목 유형 (방문한 아이템 vs 방문하지 않은 아이템) 간의 성능 불균형이 존재한다는 한계가 있음.
사용자가 실제로 상호작용한 아이템, 그렇지 않은 아이템을 구분할 때 성능이 달라지는 것임.
-> 해결?
MEMBER (Mixture-of-Experts Framework for Multi-Behavior Recommendation) 제안함.
- 두 가지 아이템 유형에 각각 특화된 전문가 모델들을 결합한 (Mixture-of-Experts) 구조 사용.
- 각 전문가 모델은 자기지도학습 (Self-supervised learning) 기반으로 학습
- 서로 다른 설계 목표에 맞게 개별적으로 최적화됨.
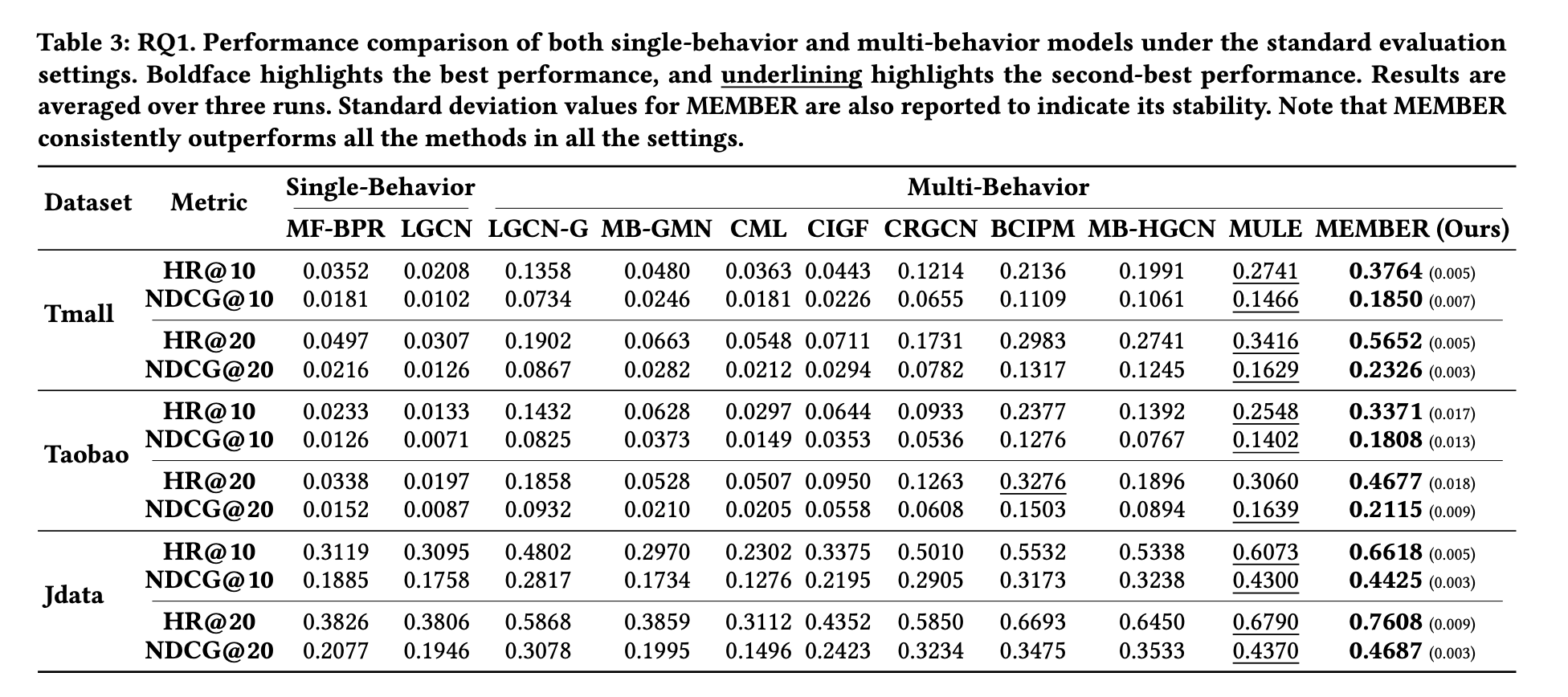
실험 결과, MEMBER 모델은 기존 최신 모델보다 Hit Ratio@20에서 최대 6.45% 성능 향상을 달성함.
-> MEMBER가 다중 행위 추천 문제에서 효과적으로 일반화 + 사용자 경험 향상과 추천 정확도 개선에 모두 기여함.
Introduction
전자상거래 시대에는 소비자가 직면하는 선택지가 너무 많기 때문에 적절한 상품을 찾는 데 어려움을 겪는 경우가 많다. 이러한 상황에서 추천 시스템은 사용자가 적합한 상품을 발견하도록 돕는 중요한 역할을 수행한다.
추천시스템은 개인화된 제안을 제공함으로써, 사용자 경험 향상 + 소매업체의 판매 실적 향상 도움
전통적인 추천시스템 -> 사용자의 구매이력에 기반하여 작동.
but, 실제로는 사용자가 구매 외에도 클릭, 장바구니 추가 등 다양한 보조적 행동을 수행한다.
이러한 행동들은 사용자의 선호와 의도를 이해하는 데 매우 중요한 단서를 제공함.
최근의 Multi-behavior Recommender Systems : 이러한 보조적 행동을 함께 고려함으로써 더 나은 추천 성능을 보여준다.
하지만, 기존의 다중 행위 추천 모델들은 여전히 두 가지 한계를 가진다.
흐름 : 구매이력 기반의 전통적인 추천시스템의 한계를 해결하기 위해서 클릭, 장바구니 추가 등 다양한 보조적 행동에 기반한 multi-behavior 추천시스템 등장 했지만, 여전히 한계가 존재함.
1. 방문한 아이템과 방문하지 않은 아이템 사이의 추천 품질 격차가 크게 나타난다.
ex) 사용자가 클릭하거나 장바구니에 추가한 적이 있는 아이템은 보조적 행동 데이터를 활용할 수 있어 상대적으로 높은 정확도를 보이지만, 그렇지 않은 아이템은 이러한 정보가 부족해 예측 성능이 급격히 떨어진다.
2. 이 두 유형의 아이템을 하나의 모델로 동시에 높은 성능을 내기 어렵다.
동일한 아키텍처에서 두 아이템 유형 모두에 대해 일관된 추천 품질을 확보하는 것은 여전히 도전적인 문제...
제안하고자 하는것 ?
MEMBER (Mixture-of-Experts Framework for Multi-Behavior Recommendation) 이라는 새로운 다중 행위 추천 프레임워크 제안.
- 2개의 전문가 모델로 구성
- 방문한 아이템에 특화된 전문가 (contrastive learning을 통해 보조적 행위와 구매 간의 관계를 학습)
- 방문하지 않은 아이템에 특화된 전문가 (generative self-supervised learning을 통해 보조 정보 없이도 구매 가능성을 추론하도록 훈련)
각 전문가는 서로 다른 학습 전략으로 훈련.
12개의 평가 설정 중 visited items에서는 12개 중 12개, unvisited items에서는 6개 중 4개 설정에서 최고 성능 달성함.
Related Work & Preliminaries (관련 연구 및 기본 개념)
2.1 Related Work - 다중 행위 추천 시스템
Multi-behavior Recommender Systems은 사용자의 다양한 행위를 기반으로 추천 정확도를 높이기 위해 고안된 모델이다.
- 클릭, 장바구니 추가, 구매 등 여러 종류의 보조 행위로부터 신호를 추출하여 모델이 사용자의 선호를 더 정교하게 파악하도록 한다.
- 다양한 연구 (Transformer, attention-based, self-supervised 방식 등)가 이러한 보조 행위를 효과적으로 모델링하기 위해 제안되어 옴.
BUT !!
하지만 지금까지 대부분의 연구는 보조행위가 추천 품질에 미치는 영향을 깊이 분석하지 않았고, 특히 "방문 아이템 vs 비방문 아이템" 간의 성능 차이를 명확히 구분하여 평가하지 않앗음.
따라서, 이 논문에서는 처음으로 두 아이템 그룹을 명시적으로 구분하여 성능을 분석하고, 이 불균형 문제를 해결할 수 있는 혼합전문가 구조를 도입했다.
Mixture-of-Experts (MoE) in Recommender Systems
MoE 아키텍처는 다양한 추천 및 분류 작업에서 폭넓게 활용되어 옴.
- 기본 개념은 여러 개의 전문가 모델을 준비하고, 각 전문가가 특정 도메인 혹은 특정 행동 유형에 특화되어 학습되도록 하는 것.
ex) 한 전문가는 '클릭 예측', 다른 전문가는 '구매 예측'에 특화.
다중 행위 추천에서는 이러한 접근이 매우 유용하다.
'방문된 아이템'과 '비방문 아이템'은 학습해야 하는 신호 구조가 다르기 때문임.
2.2 Notations and Problem Definition
- U: 사용자 집합
- I: 아이템 집합
- M: 행위 집합 (예: 클릭, 장바구니 추가, 구매 등)
-> 각 사용자 u의 행위는 (u, i, m) 의 형태로 표현됨 → “사용자 u가 행위 m을 통해 아이템 i와 상호작용”
모델의 목적 : 다양한 행위 데이터를 사용해 각 사용자에게 미방문 아이템을 추천하는 것임
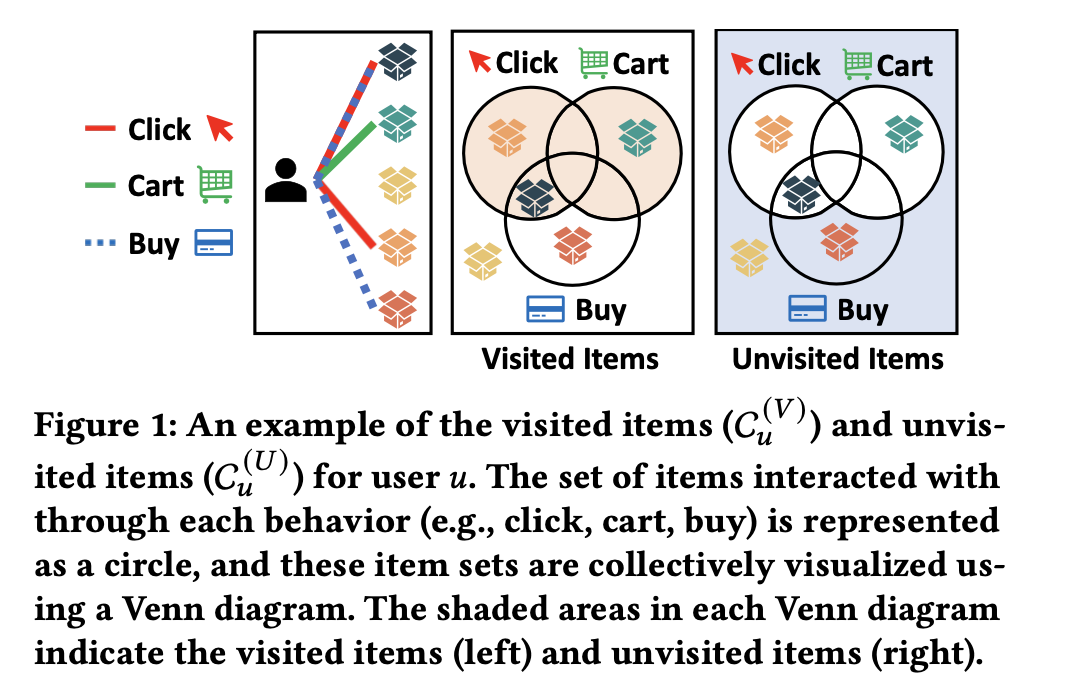
(3). Model training and evaluation
모든 행위 정보를 사용하여 모델을 학습시킨다.
이후, 학습된 모델의 추천 품질을 평가하기 위해 각 사용자 u에 대해 두 가지 항목으로 나누어 성능 측정함.
1. visited items (방문한 아이템)
2. unvisited items (방문하지 않은 아이템)
즉, 테스트 세트에 포함된 사용자의 목표 행동이 주어졌을 때, 해당 행동이 어떤 아이텤에 대한 것인지에 따라 두 가지로 분류한다.
-
- visited-item purchase : 해당 아이템이 사용자의 (이전에 방문했던 아이템 집합) 에 속하는 경우
-
- unvisited-item purchase : 해당 아이템이 사용자의 (이전에 방문하지 않은 아이템 집합) 에 속하는 경우
-
모델의 visited-item 추천 성능은 방문한 아이템을 다른 후보 아이템보다 높은 점수로 예측할 수 있는지로 평가한다.
-
unvisited-item 추천 성능은 방문한 적이 없는 아이템 중에서 실제 구매된 아이템에 높은 점수를 부여할 수 있는 지로 평가함.
-> 이를 정량적으로 측정하기 위해 두 경우 모두에서 Hit-Ratio@10 (HR@10) 지표를 사용하였다.
(추천 상위 10개 항목 중 실제로 구매된 아이템이 포함되어 있는 비율을 평가) -
세 가지 실제 다중 행위 추천 데이터셋
Tmall, Taobao, Jdata
주요 결과는 본문에서 Tmall 데이터셋을 기준으로 보고하며, 추가적인 실험 결과는 부록제시.
3.2 Analysis Results
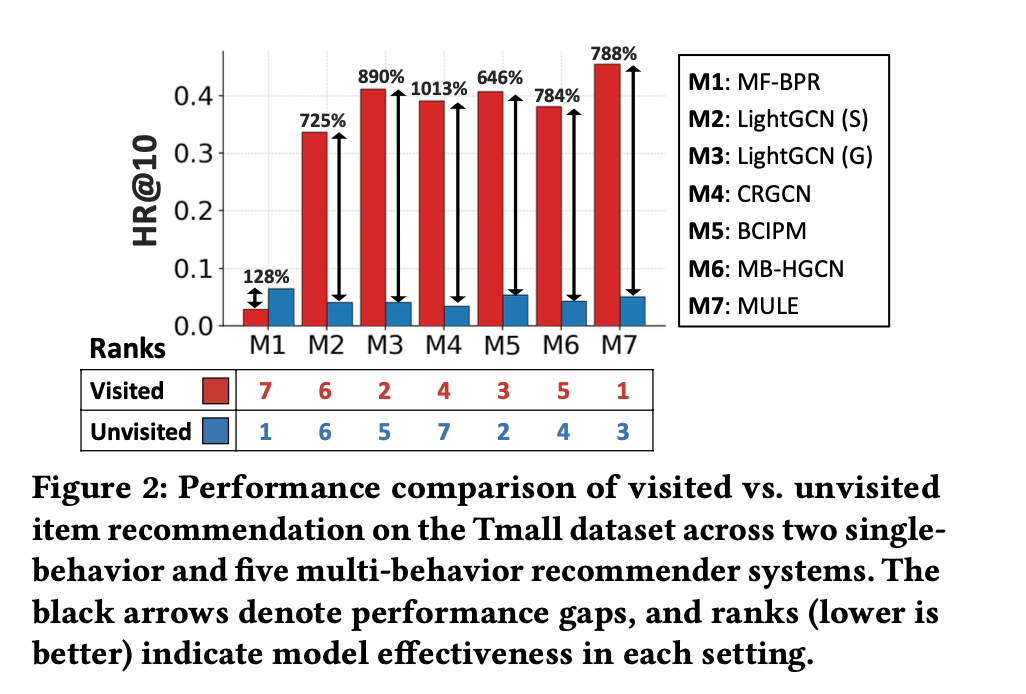
(O1) Performance gap between visited and unvisited items. 방문 아이템과 미방문 아이템 간의 성능 격차
- 모든 방법에서 공통적으로, 미방문 아이템 추천 성능이 방문 아이템보다 크게 하락하는 절대적인 성능 저하 관찰. (모든 multi-behavior 추천 모델에서 방문 아이템 추천 성능은 미방문 아이템 추천 대지 평균 약 824.2% 더 높게 나타났다.)
-> 기존 모델들이 이전에 본 적 없는 아이템에 대한 추천을 매우 어렵게 처리하고 있음
따라서, 미방문 아이템 추천 품질의 개선 필요성 !!!
- 단일 행위만 사용하는 MF-BPR(Matrix Factorization - Bayesian Personalized Ranking) 모델이 오히려 미방문 아이템에 대해서는 가장 높은 성능을 보였다.
->복잡한 다중행위 모델이 항상 모든 경우에 우수하지 않음을 시사한다.
(O2) No one-size-fits-all model. (하나의 모델로는 모든 경우에 최적 성능을 낼 수 없음)
기존 multi-behavior 추천 모델들의 성능 순위를 살펴보면, 방문 아이템 추천에서의 순위와 미방문 아이템 추천에서의 순위가 크게 다름.
- 한 모델이 방문 아이템에서는 잘 작동하더라도, 미방문 아이템에서는 그렇지 않을 수 있다
- 이 불일치는 "단일 모델로 두 종류의 추천을 동시에 잘 수행하는 것은 어렵다는 사실을 보여줌
4. Proposed Method : MEMBER
MEMBER (Mixture-of-Experts for Multi-BEHavior Recommendation) 모델 제안
-> multi behavior 추천 문제를 해결하기 위한 새로운 혼합전문가 기반 아키텍처
핵심 아이디어
1. 각 전문가(Expert)가 각각의 추천 유형에 특화되어 학습 (방문 / 미방문 아이템 추천)
2. 각 전문가가 서로 다른 목표에 따라 독립적으로 파라미터화되어, 데이터 내 서로 다른 패턴 학습
- 하나의 단일 모델이 모든 상황에서 잘 작동하지 않는다는 분석 결과에 기반하여, MEMBER는 전문가 분리 구조를 도입
- 미방문 아이템 추천의 성능 저하 문제를 해결 위해 -> MEMBER은 해당 전문가에 대해 특화된 Self-Supervised Learning Scheme을 적용
[MEMBER architecture]
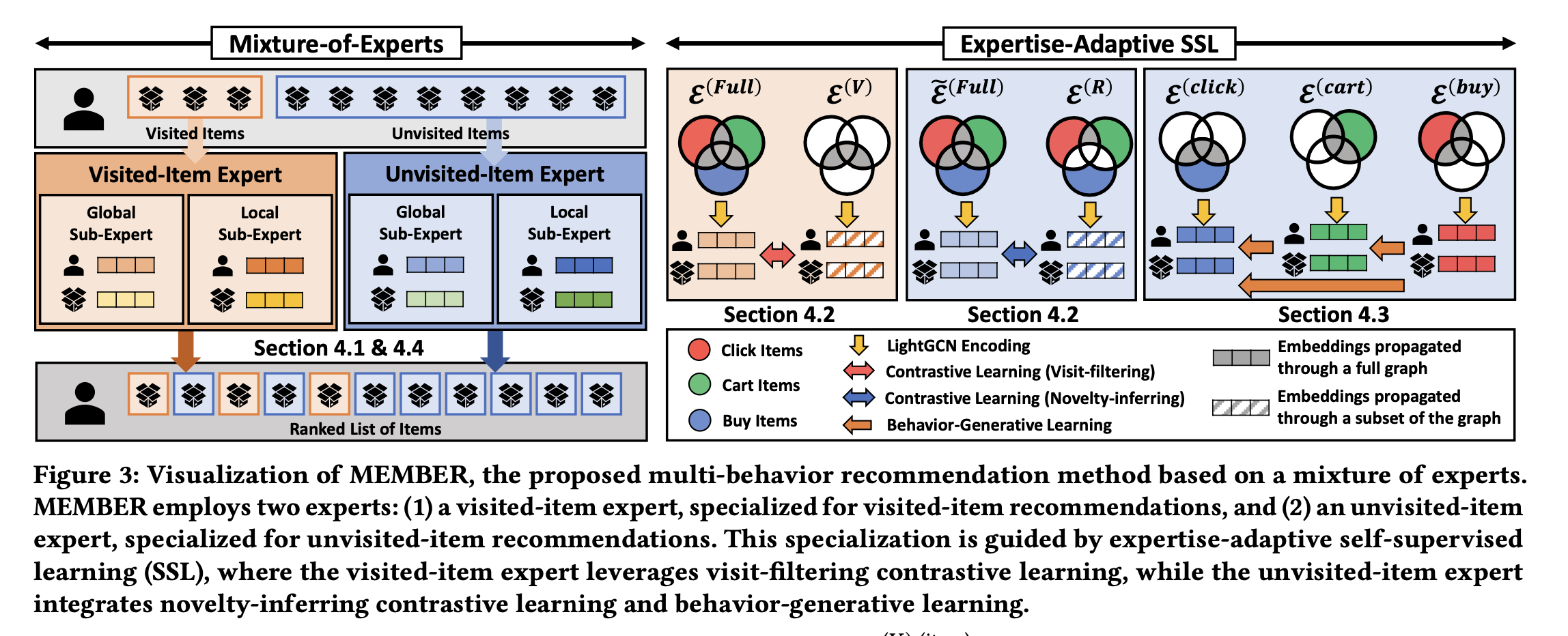
4.1 Architecture of Each Expert
MEMBER에서 사용된 두 가지 서브 모듈
- Global sub-expert
- Local sub-expert
각 sub expert는 그래프 기반의 컨볼루션 함수를 사용해 임베딩을 계산하며, 사용자-아이템 간 관계를 LightGCN 기반으로 학습한다.
Graph convolution function
- 각 Expert의 아키텍처: 각 expert는 LightGCN 기반의 그래프 컨볼루션 함수 를 사용하여 사용자 및 아이템 임베딩을 학습.
그래프 컨볼루션 함수
- LightGCN의 메시지 전달(message passing) 및 임베딩 집계(aggregation) 방식을 따른다. (GNN 스터디에서 배운내용)
- ℓ-번째 레이어에서 사용자 와 아이템 의 임베딩은 다음과 같이 계산됨.
최종 임베딩은 모든 레이어의 임베딩을 평균하여 얻는다.
Input modeling 및 Encoding
-
각 expert는 Global sub-expert와 Local sub-expert를 포함
-
Global sub-expert: 모든 행동 상호작용을 결합한 단일 글로벌 그래프 를 사용하여 글로벌 사용자 및 아이템 임베딩 을 학습
- Local sub-expert: 각 행동 에 해당하는 로컬 그래프 에서 임베딩 을 학습한 후, 이들을 평균하여 최종 로컬 임베딩 을 얻는다.
여기서, 임.
Scoring
- 각 expert는 글로벌 및 로컬 sub-expert의 점수를 가중 평균하여 사용자 와 아이템 에 대한 추천 점수 를 계산
4.2 Expertise-Adaptive SSL: (1) Contrastive Learning
- 각 expert는 자신의 특화된 목표를 달성하기 위해 맞춤형 SSL을 사용함.
-방문 아이템 expert를 위한 Visit-filtering Contrasive Learning (CL): 'visited-purchase set' 에 집중하도록 설계된다. - 이 expert는 로컬 sub-expert에서 얻은 모든 행동 임베딩 뷰
, 와 로부터 파생된 임베딩 뷰 , 를 대조하여 학습함.
사용자 및 아이템에 대한 infoNCE 형태의 CL 손실
- 미방문 아이템 expert를 위한 Novelty-inferring Contrastive Learning (CL)
'unvisited-purchase' (보조 행동 없이 발생한 구매)와 같은 'remaining set' 에 집중하도록 설계 - 이 expert는 글로벌 sub-expert에서 얻은 모든 행동 임베딩 뷰 와 로부터 파생된 임베딩 뷰 를 대조하여 학습
5. Experiments
Research Questions
- RQ1 (Overall performance): MEMBER는 표준 다중 행동 추천 환경에서 얼마나 좋은 성능을 보이는가?
- RQ2 (Item type-specific performance): MEMBER는 visited 아이템과 unvisited 아이템 각각에 대해 얼마나 잘 추천하는가?
- RQ3 (Ablation study): MEMBER의 각 구성 요소가 실제로 성능 향상에 기여하는가?
- RQ4 (Sensitivity): MEMBER는 하이퍼파라미터 설정이 바뀌어도 일관된 성능을 유지하는가?
5.1 Experimental Settings (실험 설정)
📊 Dataset
MEMBER는 3개의 대표적인 e-commerce 다중 행동 추천 데이터셋에서 평가됨.
| Dataset | 설명 |
|---|---|
| Tmall | Alibaba.com의 전자상거래 데이터셋. 행동: 클릭(click), 장바구니(cart), 구매(purchase). |
| Taobao | Taobao.com의 데이터셋. 행동: 클릭(click), 장바구니(cart), 구매(purchase). |
| Jdata | JD.com의 데이터셋. 행동: 클릭(click), 장바구니(cart), 구매(purchase). |
Baseline methods (비교 모델)
1️⃣ 기본(single-behavior) 추천 모델
1. MF-BPR
2. LightGCN
2️⃣ 다중 행동 추천 모델 (Multi-behavior RS)
1. MG-GNN
2. CML
3. CGF
4. CRGCN
5. BCPMF
6. MB-HGCF
7. MULE
⚙️ Evaluation Metrics (평가 지표)
- Hit Ratio@K (HR@K)
- NDCG@K (Normalized Discounted Cumulative Gain)
→ 둘 다 다중 행동 추천 분야에서 표준적으로 사용되는 지표임.