
Paper Link : https://arxiv.org/abs/1706.03762
※ 본 포스팅은 논문의 가장 중요한 내용에 대한 리뷰를 정리하여 올리기 때문에 다소 축약되거나 의역된 내용이 많습니다. 참고하세요.오늘 리뷰할 논문은 현대 LLM이 나오기까지 가장 큰 출발이라 불리는 Transformer가 소개된 2017년 논문 "Attention is all you need"입니다.
0. Abstract
- 현재 주도적인 Sequence transduction model들은 인코더와 디코더 구조를 포함한 복잡한 RNN 혹은 CNN구조를 기반으로 함.
- 재귀(=recurrent)나 합성곱(=convolution) 방식을 아예 배제하고 Attension Mechanism만을 활용한 Transformer라는 새로운 간단한 네트워크 구조를 제안.
- 2가지 Translation Task를 수행한 실험 결과, 이 모델들은 품질 면에서 우수함을 보였으며 Transformer가 다른 작업에도 잘 일반화됨을 보여주었음.
1. Introduce
- RNN, LSTM과 GRU는 언어 모델링, 기계 번역과 같은 순차 모델링 및 변환 문제에서 최고의 접근 방식으로 확고히 자리잡고 있고 이후에도 많은 연구가 순환 언어 모델과 인코더-디코더 구조의 한계를 뛰어넘기 위해 계속되고 있음.
- 순환 모델은 일반적으로 입력 및 출력 시퀀스의 심볼 위치에 따라 계산을 분할함. 연산 steps의 위치에 따라, 이전 hidden state인 와 position 의 입력을 기능으로 하는 hidden state 가 생성됨.
- 이런 inherently한 sequential 본질은 병렬처리를 못 하게하며, 긴 문장에서는 critical한 문제이고 메모리 제약으로 인해 예제에서 일괄 처리가 제한됨.
- factorization tricks과 conditional computation을 통해 계산 효율성을 크게 향상시켰으며, 후자의 경우 모델 성능도 개선되었지만 여전히 순차적 계산의 근본적인 제약은 남아 있음.
- Attention Mechanism은 다양한 task에서 compelling sequence modeling 및 transduction model의 필수적인 부분이 되었으며, 입력 또는 출력 시퀀스에서의 거리의 제약을 받지 않게 하였음.
- 본 연구에서 우리는 순환을 배제하는 대신 오로지 Attention Mechanism에 의존하여 입출력 간의 전역적 의존성을 파악하는 모델 구조인 Transformer를 제안하고자 함.
- 해당 모델은 훨씬 더 많은 병렬 처리를 가능하게 하며, 8개의 P100 GPU에서 단 12시간 훈련한 후 번역 품질에서 SOTA를 달성할 수 있었음.
2. Background
-
순차적 계산을 줄이려는 목표는 Extended Neural GPU, ByteNet, 그리고 ConvS2S에서도 다루어졌으며, 이 모델들은 모두 CNN을 사용함.
- input, output 거리에서 dependency를 학습하기 어려움.
- Transformer에서는 이것을 Multi-Head Attention을 사용하여 상수시간으로 줄어들었음.
-
Self-attention, 때때로 intra-attention이라고 불리는 이 attention mechanism은 하나의 시퀀스 내 다양한 위치를 서로 연관시켜 시퀀스의 표현을 계산함.
- 독해(=comprehension), 추상적 요약(=abstractive summerization), 텍스트 함축(=textual entailment) 및 task-independent sentnece representation과 같은 다양한 작업에 성공적으로 사용됨.
-
End-to-End Memory Network는 sequence-aligned recurrence 대신 recurrent attention mechanism을 기반으로 하며, 단순 언어 질문 응답 및 언어 모델링 작업에서 좋은 성능을 보인 것으로 나타남.
-
Transformer는 Sequence-aligned RNN이나 CNN을 사용하지 않고, Self-Attention에만 의존하여 입력과 출력의 표현을 계산하는 최초의 transduction 모델입니다.
3. Model Architecture
- 대부분의 경쟁력 있는 신경망 구조의 sequence transduction 모델은 인코더-디코더 구조를 가지고 있습니다.
- 인코더의 입력 시퀀스 를 연속적 표현인 와 같이 매핑하여 표현함.
- 를 바탕으로 디코더는 출력 시퀀스 를 하나씩 생성함.
- 각각의 단계에서 모델은 auto-regressive하며, 다음을 생성할 때 이전에 생성된 symbol들을 추가 입력으로 사용합니다.
- Transformer는 인코더와 디코더에 대해 각각 Figure 1의 왼쪽과 오른쪽 반쪽에서 보여지는 것처럼, Self-Attention과 Point-wise, fully connected layer를 사용하여 구성됨.
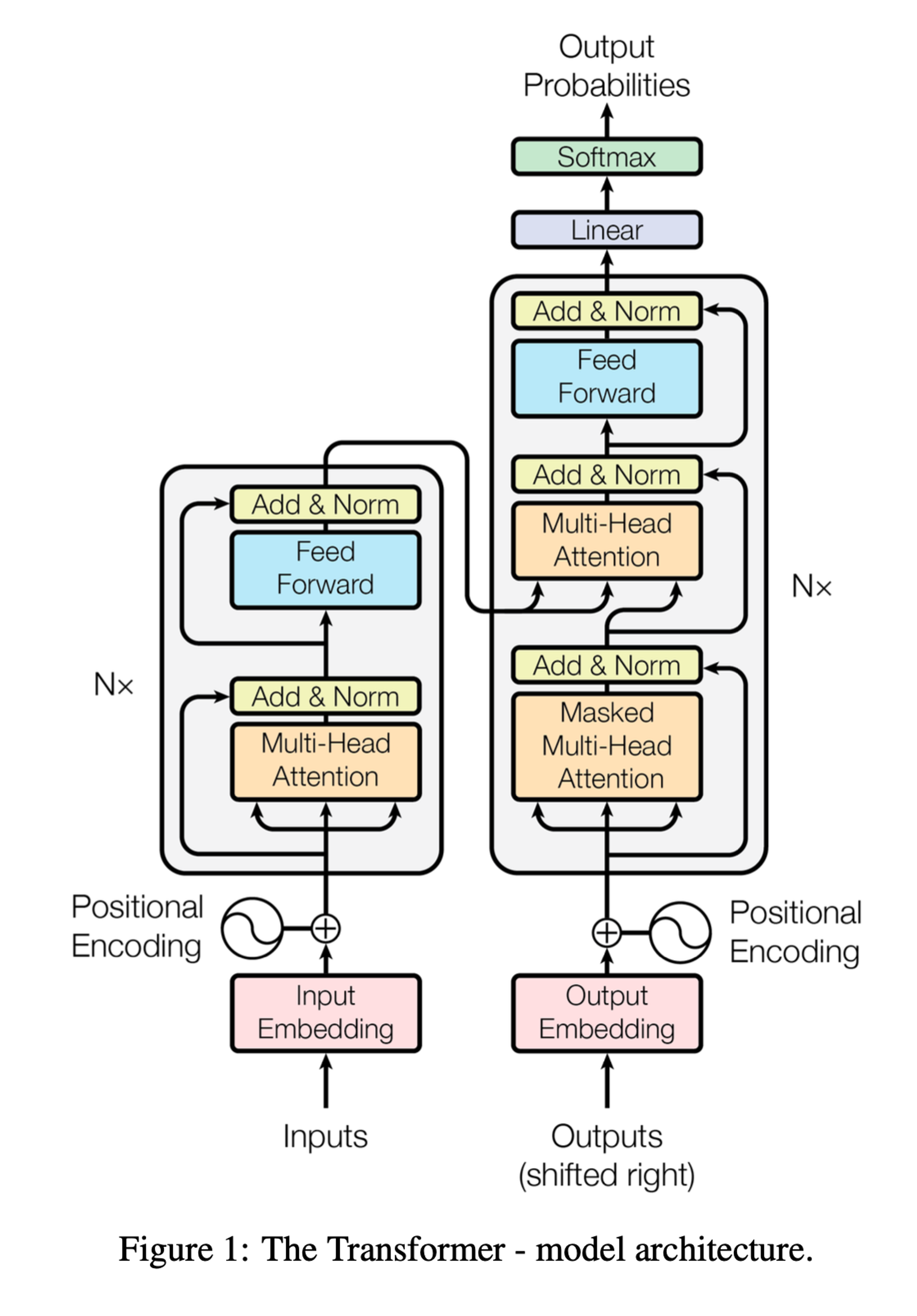
3.1 Encoder and Decoder Stacks
Encoder
- 인코더는 N=6개의 동일한 계층으로 구성됨.
- 각 계층은 2개의 Sub-Layer를 가짐.
- 첫 번째는 Multi-Head Self Attention Mechanism
- 두 번째는 위치별 Fully connected FFN
- 두 Sub-Layer 각각을 둘러싸는 Resiual connection을 사용하고, 그 다음에 정규화를 적용함.
- 각 Sub-Layer의 출력은 인데, 여기서 는 Sub-Layer자체가 구현하는 함수임.
- Residual Connection을 용이하게 하기 위해, 모델의 모든 서브레이어와 임베딩 레이어는 의 차원을 가진 출력을 생성함.
Decoder
- 디코더 또한 N = 6개의 동일한 계층으로 구성됨
- 인코더 계층의 두 서브레이어 외에도, 세 번째 서브레이어를 추가함
- 인코더의 출력에 대해 Multi-Head Attention Mechanism을 수행함
- 각 Sub-Layer 주변에 Residual connection을 사용하고, 그 다음에 레이어 정규화를 적용함.
- 디코더의 self-attention layer를 수정하여 position이 다른 위치로 이동하는 것을 방지하는데 이를 위해 사용되는 방법이 Masking임.
- 어떤 i번째 position에서 예측을 수행할 때, 미래에 올 위치에 접근하는 것이 불가능하고 해당 위치와 그 이전의 위치들에 대해서만 의존하도록 함.
3.2 Attention
- Attention Function은 query, key, value 그리고 output 모두가 벡터인 출력에 대해서 query와 key-value pair를 output에 매핑하는 함수임.
- output은 value들의 가중치 합으로 계산하는데 이때, 각 value에 할당된 가중치는 해당 key를 가진 query와 연관된 함수(=> 종류가 많음! dot-prod, badanau, etc...)에 의해 계산됨.
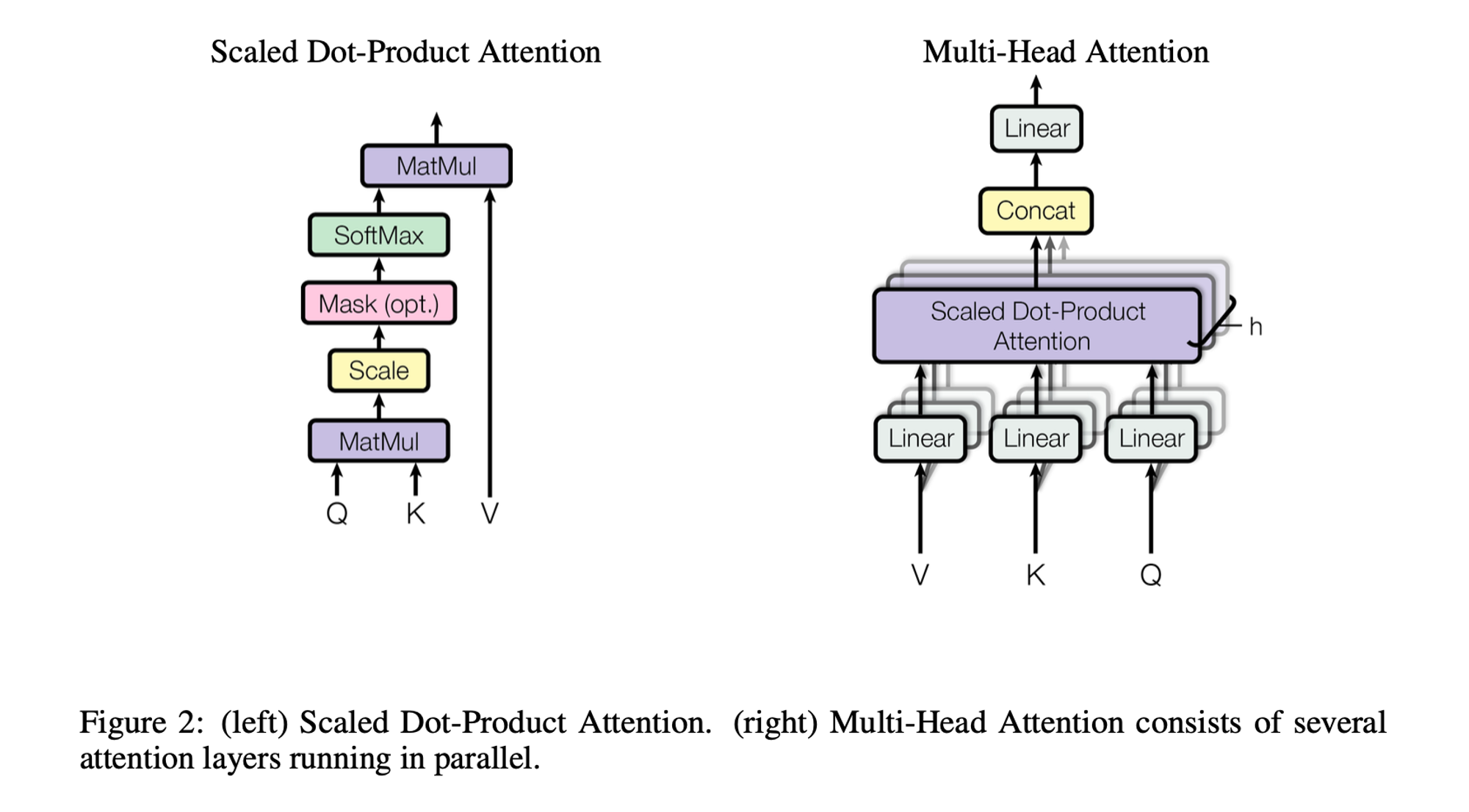
3.2.1 Scaled Dot Product Attention
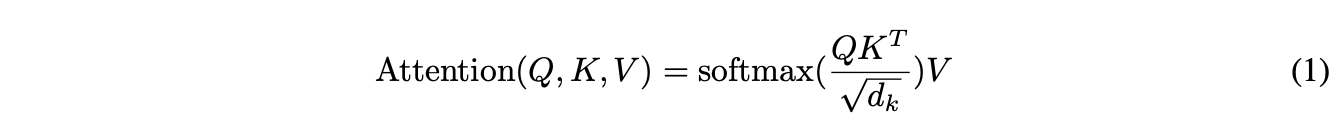
-
Scaled Dot-Product Attention의 입력은 에 대한 query, key와 에 대한 value의 벡터들로 구성됨.
-
모든 key로 dot-product를 계산하고 각각을 로 나눈 다음, Softmax함수를 적용하여 value의 가중치를 얻게됨.
-
가장 일반적으로 사용되는 attention function은 'additive attention'과 'dot-product attention'이고 이중 Dot-product attention의 스케일링 인자인 를 제외하면 본 논문의 알고리즘과 같음.
-
additive attention은 feed-forward network를 이용하여 compatibility function을 계산함.
-
위의 두 가지는 이론적인 복잡성은 유사하지만, dot-product attention이 훨씬 빠르고 공간효율적임.
- 가 작으면 두 방식의 성능은 비슷하지만, 가 큰 경우 additie attention이 더 성능이 좋음.
- 가 크면 dot-product의 경우 gradient vanishing 문제를 해결하기 위해 로 스케일링 함.
3.2.2 Multi-Head Attention
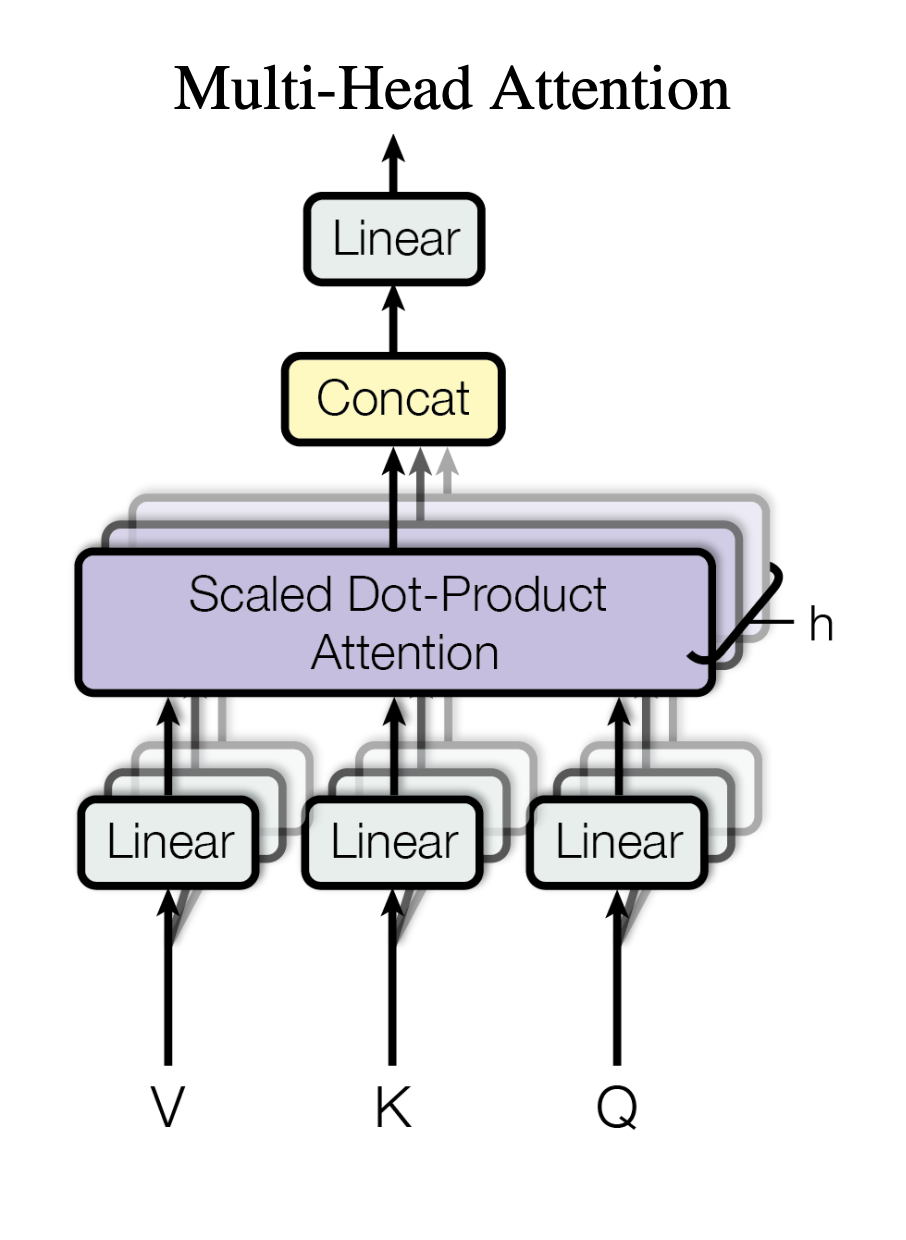
- 의 차원크기를 가지는 key, value, query로 단일 어텐션 기능을 수행하는 대신에 query, key,value을 각각 , , 차원으로 번 linear projection하는 것(=> 서로 다르게 학습)이 더 효과적이라는 것을 발견함.
- 이렇게 projection된 query, key, value에 대해서 attention function을 병렬적으로 수행하여 개의 차원의 결과를 산출함. 이 결과들을 연결시킨 후 linear projection하여 최종적인 결과벡터를 얻게됨.

- 파라미터들
- 본 연구에선 이고 이다. 각 head마다 차원을 줄이기 때문에 전체계산비용이 단일 어텐션과 비슷하다.
3.2.3 Applications of Attention in our Model
- Transformer에서는 Multi-Head Attention을 3가지 방식으로 사용함.
- 인코더-디코더 레이어
- query는 이전 디코더 레이어에서 나옴.
- key와 value는 인코더의 output에서 나옴.
- 디코더의 모든 위치에서 input sequence의 모든 position을 다룰 수 있음.
- 전형적인 Seq2Seq에서의 attention 방식.
- 인코더
- self-attention layer를 포함함.
- query, key, value는 모두 인코더의 이전 layer의 output에서 나옴.
- 인코더의 각 position은 인코더의 이전 layer의 모든 position을 다룰 수 있음.
- 디코더
- 디코더의 각 position은 해당 position까지 모든 position을 다룰 수 있음.
- 디코더의 auto-regressive 성질을 보존하기 위해 leftward의 정보흐름을 막아야함 (= 미래 시점의 단어들을 미리 조회함에 따라 현재단어 결정에 미칠 수 있는 영향을 막음).
- Scaled-dot product attention에서 모든 softmax의 input value 중 illegal connection에 해당하는 값을 로 masking out해서 구현함. (= Softmax를 취했을 때 해당위치의 값이 0이 되게하기 위해서)
3.3 Point wise Feed Forward Network
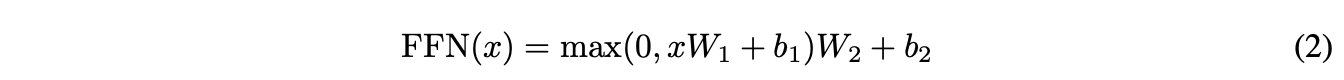
- 인코더 디코더의 각 layer는 fully connected feed-forward network를 가짐.
- 각 position에 따로따로, 동일하게 적용됨.
- ReLu 활성화 함수를 포함한 두 개의 Linear Transformation이 포함됨.
- 선형변환은 position에 대해서는 동일하지만, 각 층마다 다른 파라미터 를 사용함.
- 입출력 차원은 동일하게 .
- FFN 내부 hidden layer의 차원은 .
3.4 Embedding and Softmaxs
- 다른 시퀀스 변환 모델과 유사하게, 학습된 임베딩을 사용함.
- 입력 토큰과 출력 토큰을 차원의 벡터로 변환하기 위함.
- 디코더의 출력을 예측되는 다음 토큰의 확률로 변환하기 위해서 일반적으로 학습된 linear transformation과 softmax함수를 사용함.
- 두 임베딩 레이어와 softmax 이전의 linear transformation에 동일한 가중치 행렬을 공유하도록 함.
- 임베딩 레이어에서는 그 가중치에 을 곱해줌.
3.5 Positional Encoding
-
Transformer는 어떤 recurrence, convolution도 사용하지 않기 때문에, sequence의 순서를 사용하기 위해 position에 대한 정보를 주입해줘야 함.
-
인코더와 디코더 stack 아래의 input 임베딩에 "Positional Encoding"을 추가함.
-
Positional Encoding은 input 임베딩과 마찬가지로, 차원을 가지기 때문에 합칠 수 있음.
-
Positional encoding은 여러가지가 있지만, Transformer는 다른 주기를 가지는 Sine, Cosine function을 사용함.
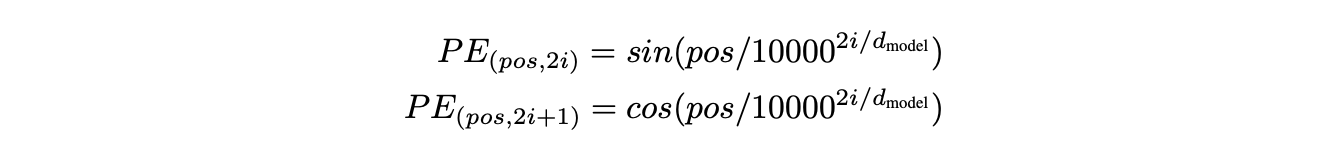
- 파라미터들
- : position을 의미함
- : 차원을 의미함
- positional encoding의 각 차원는 Sine Curve에 대응됨.
- 파장은 에서 까지 기하급수적으로 늘어남.
- 위의 함수를 선택한 이유는 어떤 고정된 오프셋 에 대해,가 의 선형함수로 표현될 것이라는 가설때문. (상대적으로 위치를 쉽게 학습할 것이다!)
- 실험결과 두 버전이 동일한 결과를 산출하였고 결국 Sine Curve를 선택함.
- 모델이 훈련중에 접한 것보다 더 긴 시퀀스 길이에 대해서도 추정할 수 있기 때문
4. Why Self-Attention
- self-attention과 recurrent, convolution layer를 다음에 대해 비교함.
- Layer당 계산 복잡도
- sequential parallelize 할 수 있는 계산량
- network에서 long-range dependency 사이의 path 길이
- network에서 순회해야하는 forward 와 backward의 path 길이가 이런 dependency를 학습하는 능력에 영향을 주는 주요 요인
- input과 output sequence에서 position의 조합 간의 path가 짧을수록, long-range dependecy를 학습하기가 쉬움
- -> input과 output position 사이의 최대 path 길이를 비교할 것

5. Training
5.1 Training Data and Batching
- English-German
- 450만개의 sentence pairs로 구성된 WMT 2014 English-German 데이터셋 활용함.
- 문장들은 byte-pair 인코딩으로 인코딩 되어있음.
- Source target vocabulary는 37000개임.
- English-French
- 3600만개의 sentence로 구성된 WMT 2014 English-French 데이터셋 활용함.
- 32000개의 word-piece vocabulary로 구성됨.
5.2 Hardware and Schedule
- 8개의 NVIDIA P100 GPU를 사용함.
- base model은 12시간 동안 (100,000 step) 학습함.
- big model 은 3.5일 동안 (300,000 step) 학습함.
5.3 Optimizer

- Adam optimizer 사용함.
5.4 Regularization
- Residual Dropout
- 하위 레이어 입력이 추가되고 정규화되기 전에, 각 하위 계층의 출력에 드롭아웃을 적용함.
- 인코더와 디코더 스택 모두에서 임베딩과 위치 인코뎅의 합계에 드롭아웃을 적용함.
- Label Smoothing
- 훈련하는동안 label smoothing value 을 사용함.
- 모델이 불확실해지긴 하지만 정확도와 BLUE 점수를 향상하였음.
6. Results
이 시점 Transformer가 아주 혁신이었다! (자세한건 논문에!!)
