Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models (2024)
Paper-Review

Paper Link : https://arxiv.org/pdf/2310.06117
※ 본 포스팅은 논문의 가장 중요한 내용에 대한 리뷰를 정리하여 올리기 때문에 다소 축약되거나 의역된 내용이 많습니다. 참고하세요.Abstract
다음은 STEP-BACK PROMPTING에 대한 설명입니다. 이는 특정한 세부 사항을 포함한 사례로부터 고수준 개념과 기본 원칙을 도출하기 위해 대규모 언어 모델(LLM)이 추상화를 수행할 수 있도록 하는 간단한 프롬프트 기법입니다. 개념과 원칙을 사용하여 추론을 안내함으로써, 대규모 언어 모델(LLM)은 올바른 추론 경로를 따라 솔루션에 도달하는 능력이 크게 향상됩니다. 우리는 PaLM-2L, GPT-4, 그리고 Llama2-70B 모델을 사용하여 STEP-BACK PROMPTING 실험을 수행했고, STEM, Knowledge QA, Multi-Hop Reasoning을 포함한 다양한 어려운 추론 중심 작업에서 상당한 성능 향상을 관찰했습니다. 예를 들어, STEP-BACK PROMPTING은 MMLU(물리학 및 화학)에서 PaLM-2L의 성능을 각각 7%와 11% 향상시키고, TimeQA에서는 27%, MuSiQue에서는 7% 향상시킵니다.
1. Introduction
자연어 처리(NLP) 분야는 트랜스포머 기반의 대규모 언어 모델(LLM)로 인해 획기적인 혁명을 목격하고 있습니다. 모델의 크기와 사전 훈련 코퍼스를 확장함으로써 모델의 능력과 샘플 효율성이 획기적으로 개선되었습니다. 이는 스케일링 법칙에서 얻은 통찰력뿐만 아니라, 다단계 추론과 지침 준수와 같은 새로운 능력 덕분입니다.
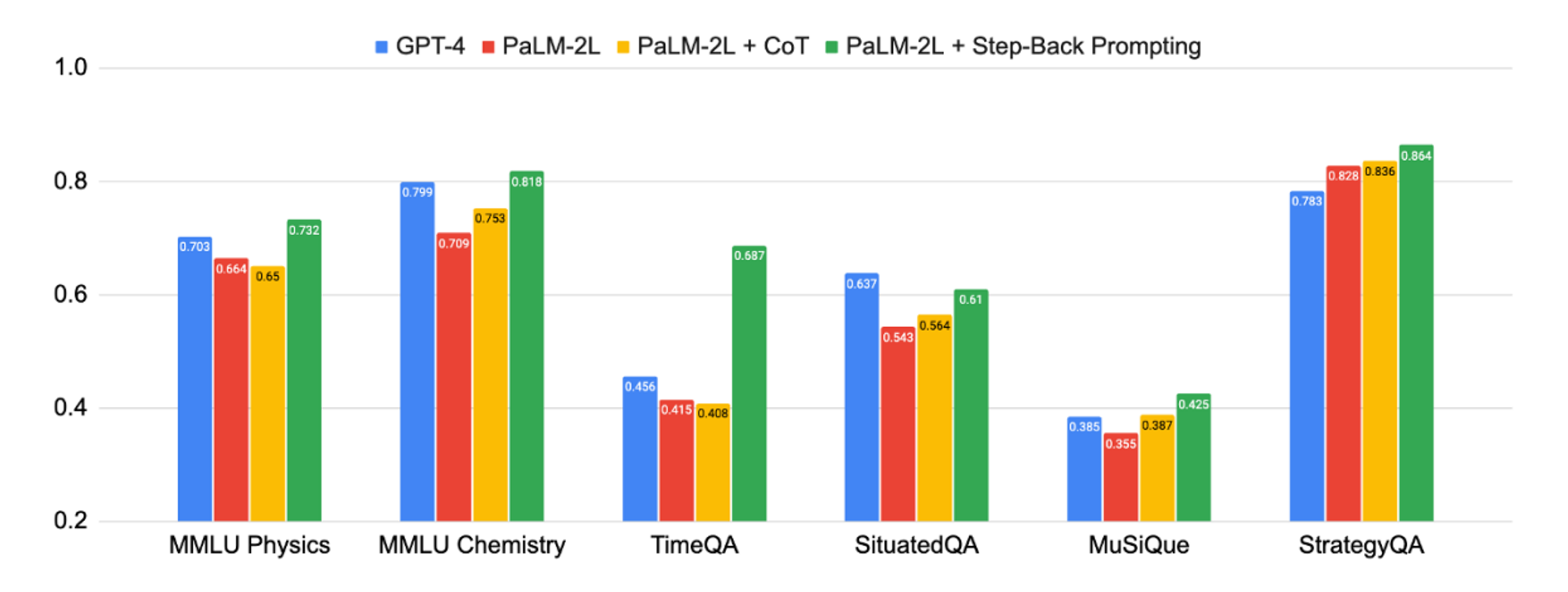
🔼 Figure 1 : Step-Back Prompting의 강력한 성능 : 우리의 제안된 추상화 및 추론 체계는 복잡한 (종종 다단계의) 추론이 요구되는 STEM, Knowledge QA, Multi-Hop Reasoning 등 다양한 어려운 작업에서 상당한 개선을 이끌어냅니다.
비록 큰 발전이 있었지만, 복잡한 다단계 추론은 최첨단 대규모 언어 모델(LLM)조차도 여전히 어려움을 겪고 있습니다. Lightman 등은 단계별 검증을 통해 프로세스를 감독하는 것이 중간 추론 단계의 정확성을 향상시키는 유망한 해결책이라고 제안합니다. Chain-of-Thought와 같은 기술은 올바른 디코딩 경로를 따를 성공률을 높이기 위해 일련의 일관된 중간 추론 단계를 생성하도록 도입되었습니다. 어려운 작업에 직면했을 때 사람들은 종종 한 걸음 물러서서 추상화를 통해 과정을 안내하는 고수준 원칙에 도달한다는 점에 영감을 받아, 우리는 중간 추론 단계에서 오류를 줄이기 위해 추론을 추상화에 기반하여 이끌어가는 STEP-BACK PROMPTING을 제안합니다.
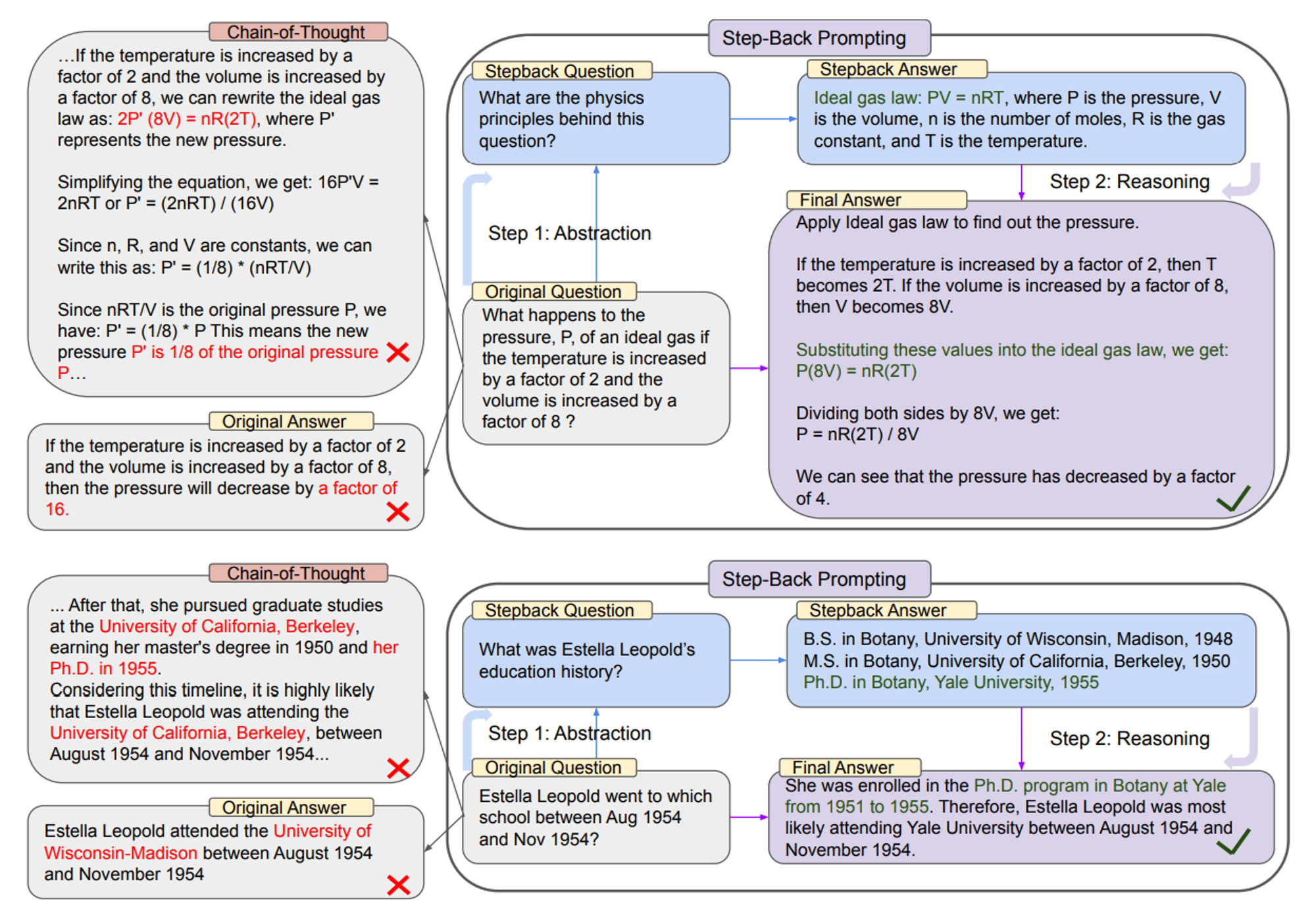
🔼 Figure 2 : 해당 그림은 STEP-BACK PROMPTING을 개념과 원칙에 따른 2 단계의 추상화와 추론으로 나타낸 것이다.
- 상단: MMLU 고등학교 물리학의 예시로, 추상화를 통해 이상 기체 법칙의 기본 원칙이 도출됩니다.
- 하단: TimeQA의 예시로, 추상화의 결과로 교육 이력이라는 고수준 개념이 도출됩니다.
- 왼쪽: PaLM-2L은 원래 질문에 답하지 못합니다. CoT Prompt는 중간 추론 단계에서 오류가 발생했습니다
(붉은색으로 강조 표시). - 오른쪽: PaLM-2L은 STEP-BACK PROMPTING을 통해 질문에 성공적으로 답합니다.
많은 인지 능력 중에서 추상화는 인간이 방대한 정보를 처리하고 일반적인 원칙을 도출하는 능력에서 보편적입니다. 예를 들어, 케플러는 수천 개의 측정을 케플러의 행성 운동 법칙 세 가지로 압축하여 태양 주위를 도는 행성의 궤도를 정확히 설명했습니다. 중요한 의사 결정에서 인간은 추상화가 환경에 대한 더 넓은 시야를 제공하기 때문에 이를 유용하게 여깁니다. 이 연구는 대규모 언어 모델(LLM)이 추상화와 추론의 두 단계 과정을 통해 많은 세부 사항을 포함하는 복잡한 작업을 어떻게 해결할 수 있는지를 탐구합니다. 첫 번째 단계는 대규모 언어 모델(LLM)에게 맥락 학습을 통해 한 걸음 물러서서 특정 예시에 대해 개념이나 원칙과 같은 고수준의 추상화를 도출하는 방법을 보여주는 것입니다. 두 번째 단계는 이러한 고수준 개념과 원칙을 바탕으로 추론 능력을 활용하여 추론하는 것입니다. 우리는 몇 개의 예시 시연을 사용하여 대규모 언어 모델에서 STEP-BACK PROMPTING을 실행합니다. 우리는 물리학과 화학과 같은 도메인별 추론, 사실적 지식이 필요한 지식 집중형 질문 답변, 멀티-홉 상식 추론을 포함하는 다양한 과제에서 실험을 수행했습니다. 그 결과, PaLM-2L에서 최대 27%의 성능 향상을 관찰하였으며, 이는 많은 세부 사항이 필요한 복잡한 과제에서도 STEP-BACK PROMPTING이 효과적임을 보여줍니다. Figure 1은 이 논문에서 제시한 모든 주요 결과를 요약한 것입니다. 일부 과제는 매우 어려운데, PaLM-2L과 GPT-4 모두 TimeQA와 MuSiQue에서 약 40%의 정확도만을 달성했습니다. Chain-of-Thought 프롬프트는 일부 과제에서 약간의 개선을 이끌어냈지만, STEP-BACK PROMPTING은 전반적으로 PaLM-2L의 성능을 향상시켰습니다: MMLU 물리학과 화학에서 각각 7%와 11%, TimeQA에서 27%, MuSiQue에서 7%의 성능 향상을 보였습니다. 우리는 다양한 분석을 수행한 결과, STEP-BACK PROMPTING이 Chain-of-Thought 프롬프트와 “take-a-deep-breath” (TDB) 프롬프트에 비해 최대 36%까지 성능을 크게 향상시키는 것을 발견했습니다. 질적 평가에서는 STEP-BACK이 기본 모델의 오류 중 상당 부분(최대 약 40%)을 수정하면서도 새로운 오류를 소량(최대 약 12%)만 도입하는 것을 확인했습니다. 또한 오류 분석을 통해 STEP-BACK PROMPTING의 대부분의 오류는 LLM의 추론 능력의 본질적인 한계에서 기인하며, 추상화 기술은 LLM에게 상대적으로 쉽게 시연될 수 있다는 것을 발견했습니다. 이는 STEP-BACK PROMPTING과 유사한 방법의 향후 개선 방향을 제시합니다.
2. Step-Back Prompting
STEP-BACK PROMPTING은 많은 과제들이 많은 세부 사항을 포함하고 있으며, 대규모 언어 모델(LLM)이 관련 사실을 찾아내어 과제를 해결하는 것이 어렵다는 점을 관찰한 데서 동기를 얻었습니다.
Figure 2의 첫 번째 예시(상단)에서 볼 수 있듯이, "온도를 2배로 증가시키고 부피를 8배로 증가시킬 경우, 이상 기체의 압력 P는 어떻게 변하는가?"라는 물리학 질문에 대해, 대규모 언어 모델(LLM)은 질문에 직접적으로 추론할 때 이상 기체 법칙의 기본 원칙에서 벗어날 수 있습니다. 마찬가지로, "Estella Leopold는 1954년 8월부터 1954년 11월 사이에 어떤 학교에 다녔는가?"라는 질문도 상세한 시간 범위 제약 때문에 직접적으로 답하기가 매우 어렵습니다. 두 경우 모두 한 걸음 물러서서 질문을 하는 것이 모델이 문제를 효과적으로 해결하는 데 도움이 됩니다.
우리는 한 걸음 물러선 질문을 원래 질문에서 더 높은 수준의 추상화를 통해 도출된 질문으로 정의합니다. 예를 들어, “Estella Leopold가 특정 기간 동안 어느 학교에 다녔는가?”라는 질문을 직접 묻는 대신, 한 걸음 물러선 질문(그림 2 하단)은 원래 질문을 포괄하는 고수준 개념인 “교육 이력”에 대해 묻는 것입니다. "Estella Leopold의 교육 이력"에 대한 한 걸음 물러선 질문에 답하는 것은, "Estella Leopold가 특정 기간 동안 어느 학교에 다녔는가?"라는 질문에 대한 추론에 필요한 모든 정보를 제공합니다. 전제는 한 걸음 물러선 질문이 일반적으로 훨씬 더 쉽다는 것입니다. 이러한 추상화를 바탕으로 추론을 진행하면, Figure 2의 왼쪽에 있는 Chain-of-Thought 예시에서처럼 중간 단계에서 발생할 수 있는 추론 오류를 피하는 데 도움이 됩니다. 요약하자면, STEP-BACK PROMPTING은 두 가지 간단한 단계로 구성됩니다:
- Abstraction(추상화) : 질문에 직접 답하는 대신, 먼저 대규모 언어 모델(LLM)이 더 높은 수준의 개념이나 원칙에 대해 일반적인 한 걸음 물러선 질문을 하도록 유도하고, 그 고수준 개념이나 원칙에 대한 관련 사실을 찾습니다. 한 걸음 물러선 질문은 각 작업에서 가장 관련성 높은 사실을 찾기 위해 고유하게 설계됩니다.
- Reasoning(추론) : 고수준 개념이나 원칙과 관련된 사실에 기초하여, 대규모 언어 모델(LLM)은 원래 질문에 대한 해결책을 추론할 수 있습니다. 우리는 이를 '추상화 기반 추론'이라고 부릅니다.
다음 섹션에서는 복잡한 추론을 포함하는 STEM, Knowledge QA, Multi-Hop Reasoning을 다루는 다양한 어려운 과제에 대해 STEP-BACK PROMPTING을 적용한 경험적 연구를 소개합니다.
3. Experimental Setup
다음은 우리가 실험한 작업과 모델을 정의한 내용입니다. 또한, 평가 지표와 고려한 기준선을 설명합니다.
3.1 Tasks
다양한 작업을 다음과 같이 실험합니다: (a) STEM, (b) Knowledge QA, (c) Multi-Hop Reasoning. 아래에서 우리가 고려한 데이터셋을 설명합니다 (자세한 내용은 부록 B를 참조하세요).
- STEM : 우리는 STEM 과제를 평가하기 위해 MMLU와 GSM8K를 사용합니다. MMLU는 모델의 언어 이해력을 평가하기 위해 다양한 분야에 걸친 일련의 벤치마크를 포함합니다. 우리는 심도 있는 추론이 필요한 고등학교 물리와 화학 부분의 MMLU를 고려합니다.
- Knowledge QA : 우리는 TimeQA를 고려하는데, 이 데이터셋은 시간에 민감한 복잡한 쿼리를 포함하고 있기 때문입니다. 또한, 시간적 또는 지리적 맥락에서 질문에 답해야 하는 모델을 요구하는 또 다른 어려운 개방형 검색 QA 데이터셋인 SituatedQA를 실험합니다.
- Multi-Hop Reasoning : 우리는 MuSiQue를 실험합니다. 이는 단일 단계 질문의 조합을 통해 만들어진 어려운 다중 단계 추론 데이터셋입니다. 또한, 해결을 위해 전략이 필요한 개방형 질문을 포함한 StrategyQA도 실험합니다.
3.2 Models
다음의 최신 대형 언어 모델(LLM)을 사용합니다: instruction-tuning 된 PaLM-2L, GPT-4, 그리고 Llama2-70B.
3.3 Evaluation
전통적인 평가 지표인 accuracy나 F1 점수는 최신 대형 언어 모델(LLM)의 생성물을 평가하는 데 한계가 있습니다. 이는 이러한 모델이 종종 긴 형식의 답변을 생성하여 이를 정확히 평가하기 어렵기 때문입니다. 대신, 우리는 PaLM-2L 모델을 사용하여 평가를 수행하는데, 이 모델을 몇 가지 예시를 제공하여 목표 답변과 모델의 예측 간의 동등성을 식별하도록 유도합니다. 이 평가에 사용된 몇 가지 예시, 프롬프트 및 기타 세부 사항은 부록 C에 있습니다.

🔼 Appendix C : Table 06 : PaLM-2L 모델에 사용한 few shot evaluation 프롬프트.
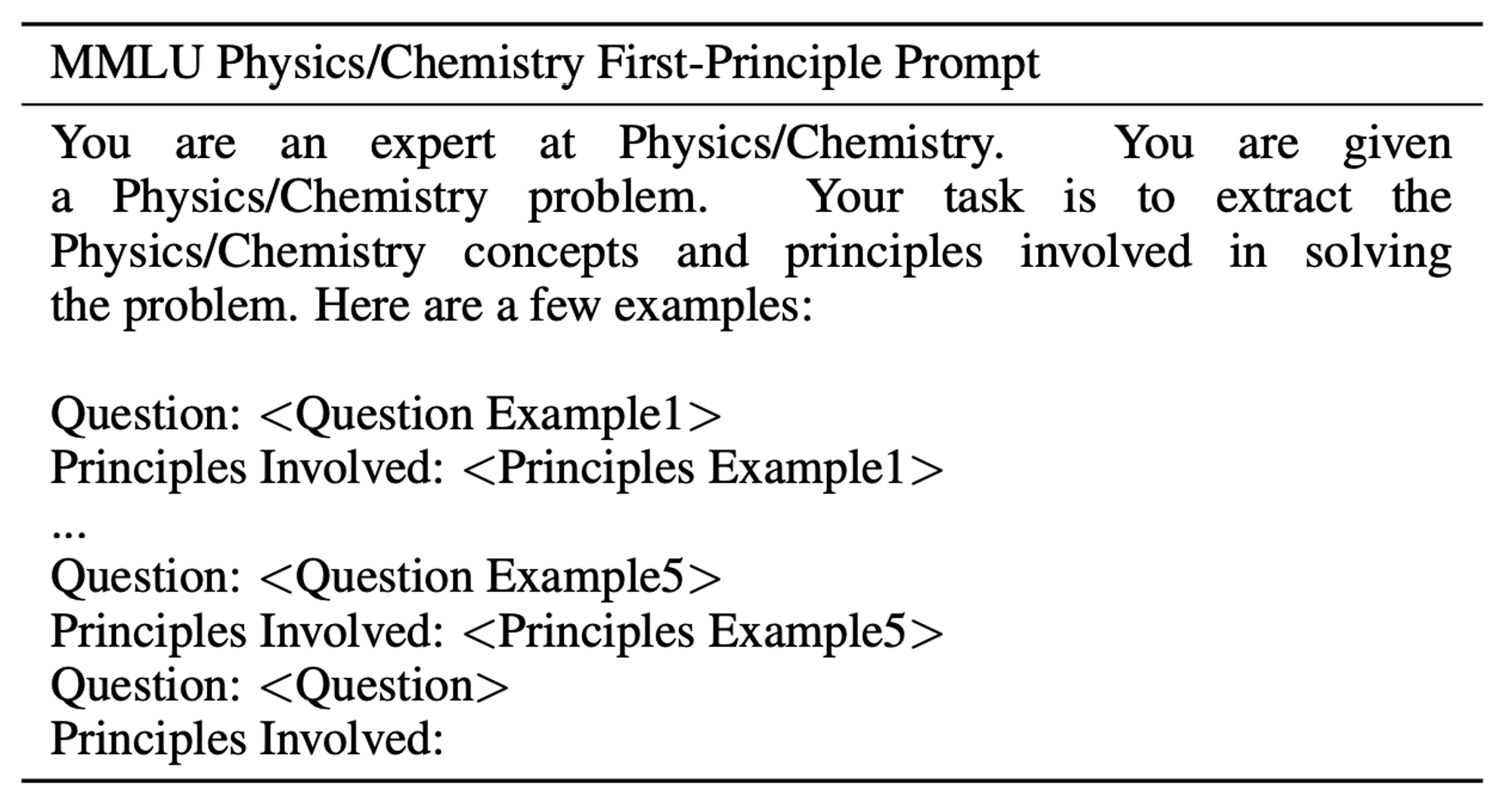
🔼 Appendix C : Table 07 : MMLU의 물리 및 화학 질문에 포함된 principle을 추출하는 프롬프트
3.4 Baseline Methods
- PaLM-2L, PaLM-2L 1-shot : PaLM-2L은 질문에 직접 질의하거나, 프롬프트에 질문-답변의 예시를 하나 포함시켜 사용합니다.
- PaLM-2L + CoT, PaLM-2L + CoT 1-shot : PaLM-2L 모델은 Zero-Shot CoT 프롬프트로 질의됩니다: 질문에 "Let’s think step-by-step"을 추가합니다. 원샷(1-shot)인 경우에는 프롬프트에 질문과 답변 쌍의 예시를 하나 제공하며, 여기서 답변은 CoT 스타일로 작성됩니다.
- PaLM-2L + TDB : Zero-shot prompting에서 질문 앞에 "Take a Deep Breath and work on this problem step-by-step"라는 문구를 추가합니다.
- PaLM-2L + RAG : 섹션 5와 6에서는 검색 증강 생성(RAG)을 사용하여, 검색된 구절을 대형 언어 모델(LLM)의 맥락으로 사용합니다.
- GPT-4 and Llama2-70B : 우리는 모든 방법에 대해 MMLU 과제에서 GPT-4와 Llama2-70B를 실행합니다. 또한, 모든 과제의 모든 기준선에서도 GPT-4를 실행합니다.
우리는 STEM 과제에 대해 RAG를 사용하지 않습니다. 이는 STEM 과제가 다른 사실 탐구 데이터셋과 달리 고유한 추론 특성을 가지고 있기 때문입니다. 모든 추론은 탐욕적 디코딩을 사용하여 수행됩니다.
4. STEM
우리는 STEP-BACK 프롬프트 기법을 STEM task에 평가하여, 고도로 전문화된 도메인에서 추론하는 데 있어 이 방법의 효율성을 측정합니다. 아래에서는 MMLU 고등학교 물리와 화학, 그리고 GSM8K 벤치마크에 STEP-BACK 프롬프트 기법을 적용한 실험 설정, 결과, 그리고 분석에 대해 설명합니다.
4.1 Step-Back Prompting
MMLU 벤치마크의 질문은 더 깊은 추론을 요구합니다. 또한, 물리와 화학의 원리와 개념을 이해하고 공식을 적용하는 능력도 필요합니다. 이 경우, 우리는 먼저 Newton’s first law of motion, Doffler Effect, Gibbs Free Energy 등과 같은 개념과 기본 원리의 형태로 모델에게 추상화 기술을 시연합니다.
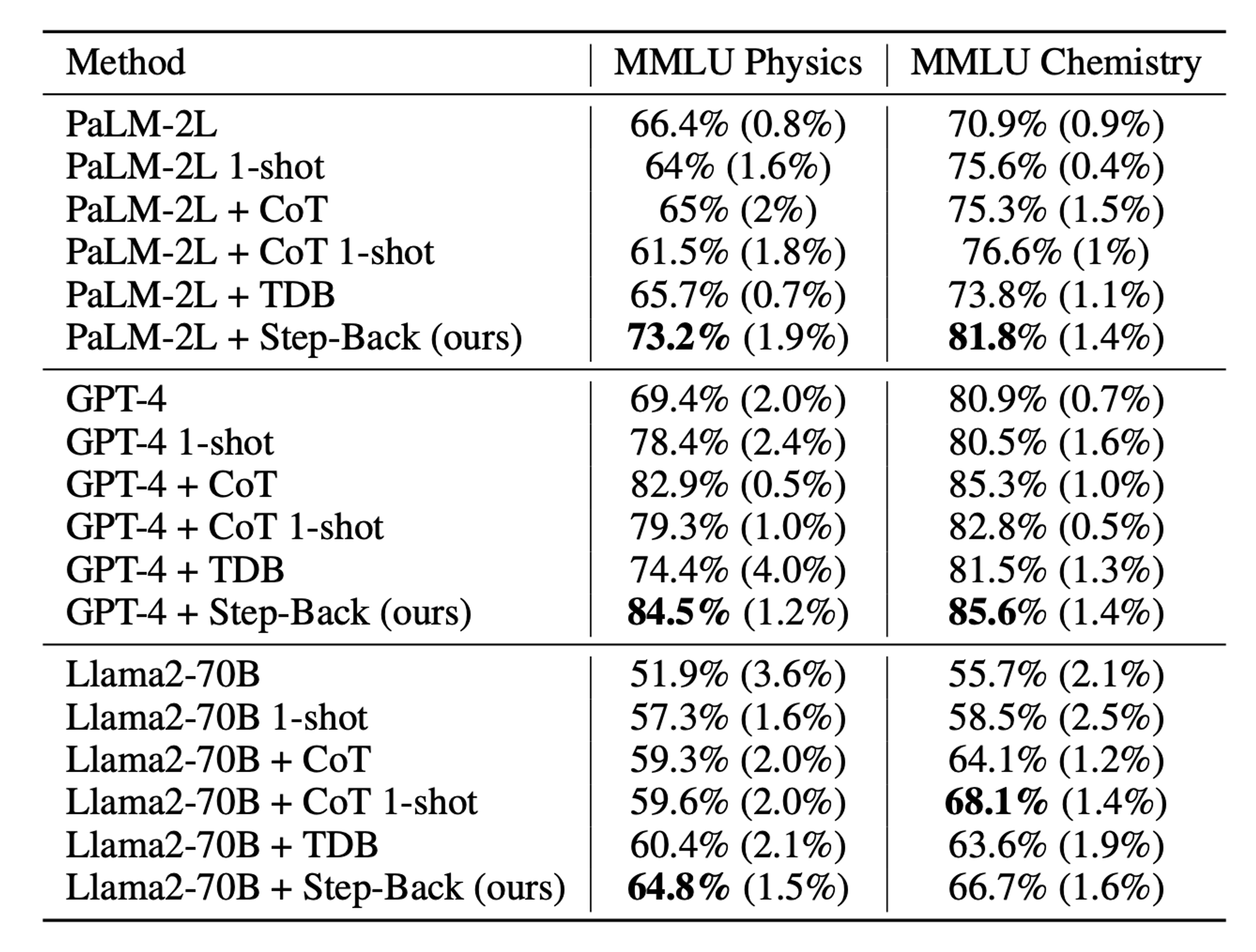
🔼 Table 01 : 세 가지 모델 계열에서 MMLU 과제에 대해 STEP-BACK 프롬프팅이 강력한 성능을 보였습니다. CoT: zero-shot, TDB: Take a Deep Breath.
여기서 암시된 STEP-BACK 질문은 "이 과제를 해결하는 데 관여하는 물리 또는 화학 원리와 개념은 무엇인가?"입니다. 우리는 모델에게 이 과제를 해결하는 데 필요한 관련 원리를 자신의 지식에서 찾아 설명하도록 시연합니다 (몇 가지 예시는 부록 D.1을 참조하세요).
4.2 Results
Table 01은 세 가지 모델 계열, 즉 PaLM-2L, GPT-4, Llama2-70B에서 다양한 설정에 따른 모델 성능을 보여줍니다. 5회 평가 실행에서 평균 정확도와 표준 편차(괄호 안에 표기)를 함께 보고합니다. PaLM-2L의 기준선 성능은 물리에서 66.4%, 화학에서 70.9%입니다. 우리는 CoT와 TDB zero-shot 프롬프팅이 모델 성능을 크게 향상시키지 않는다는 사실을 발견했습니다. 이는 이 과제들이 본질적으로 어려움과 깊은 추론을 요구하기 때문일 수 있습니다. PaLM-2L 1-shot과 PaLM-2L + CoT 1-shot도 기준선에 비해 성능을 크게 개선하지 못하여, 모델에게 추론 단계를 시연하는 것이 얼마나 어려운지 보여줍니다. 반면에, STEP-BACK 프롬프팅은 모델 성능을 상당히 향상시켰습니다: PaLM-2L에 비해 각각 7%와 11% 향상되었습니다. 마찬가지로, GPT-4와 Llama2-70B 모델에서도 STEP-BACK 프롬프팅은 우리가 테스트한 모든 기준선 방법 중에서 매우 경쟁력 있는 성과를 보여, STEP-BACK 프롬프팅이 모델에 구애받지 않는 방법임을 나타냅니다. GSM8K의 결과는 부록 A.1에 제시합니다.
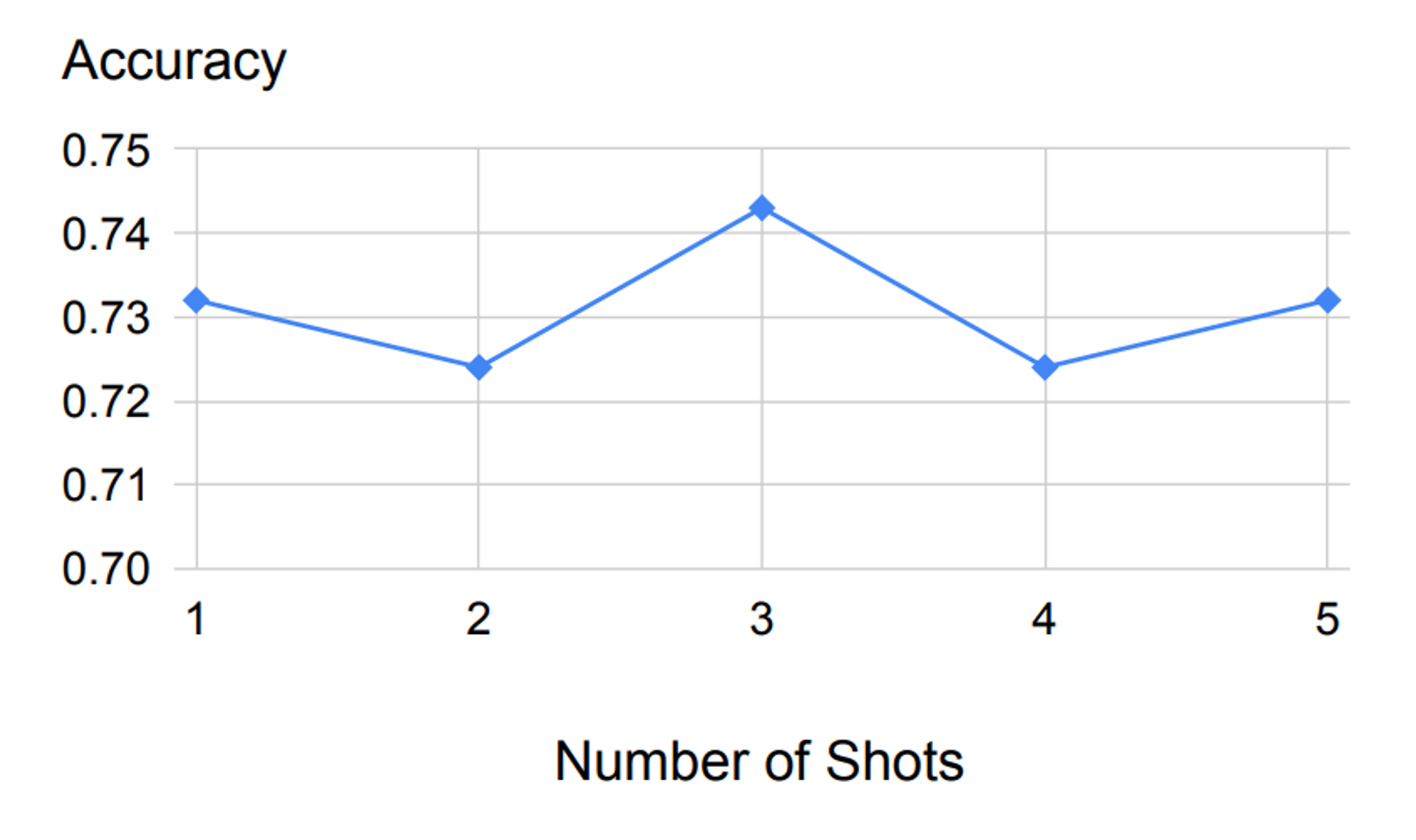
🔼 Figure 03 : STEP-BACK 프롬프팅의 정확도에 대한 소거 연구: MMLU 고등학교 물리에서 PaLM-2L을 사용하여 몇 가지 예시의 수에 따라 정확도를 비교한 결과, 다양한 샷 수에 대해 강력한 성능을 보임.
4.3 Ablation and Analysis
Few-shot Ablation.
먼저, Figure 03에서 STEP-BACK 프롬프팅이 데모로 사용된 (질문, 원칙) 쌍의 몇 샷 예시 수에 대해 강력한 성능을 보이는 것을 확인할 수 있습니다. 단일 예시를 초과하여 더 많은 데모 예시를 추가하는 것은 추가적인 개선을 가져오지 않았습니다. 이는 관련 원리와 개념을 검색하는 작업이 맥락 학습을 통해 상대적으로 쉽고 단일 예시만으로 충분하다는 것을 나타냅니다. 따라서, 소거 연구를 제외하고는 본 논문 전체에서 few-shot 프롬프팅에 단일 예시를 사용합니다.Math
Error Ablation.
MMLU 고등학교 물리 과제에서 STEP-BACK 프롬프팅의 예측을 기준선인 PaLM-2L 모델과 비교한 결과, STEP-BACK 프롬프팅이 기준선의 오류 중 20.5%를 수정했지만, 11.9%의 새로운 오류를 도입한 것을 발견했습니다.
STEP-BACK 프롬프팅에서 오류가 발생하는 원인을 더 잘 이해하기 위해, 우리는 테스트 세트에서 STEP-BACK 프롬프팅의 모든 잘못된 예측을 주석 처리하고, 이를 5가지 범주로 분류했습니다(각 범주의 예시는 부록 E.1을 참조하십시오).
- Principle Error : 오류는 추상화 단계에서 발생하는데, 이 단계에서 모델이 생성한 기본 원리가 잘못되었거나 불완전한 경우입니다
- Factual Error : 모델이 자신의 사실적 지식을 설명할 때 최소한 하나 이상의 사실 오류가 발생합니다.
- Math Error : 최종 답을 도출하는 과정에서 수학적 계산이 포함될 때, 중간 단계에서 최소한 하나 이상의 수학적 오류가 발생합니다.
- Context Loss : 모델의 응답이 질문의 맥락을 잃고 원래 질문에 대한 답변에서 벗어나는 오류가 최소한 하나 이상 발생합니다.
- Reasoning Error : 우리는 모델이 최종 답에 도달하기 전에 중간 추론 단계에서 최소한 하나의 오류를 범하는 경우를 추론 오류(Reasoning Error)로 정의합니다.
다섯 가지 유형의 오류는 모두 추론 단계에서 발생하며, 원칙 오류(Principle Error)는 추상화 단계의 실패를 나타냅니다. Figure 04에서 보듯이, 원칙 오류는 모델이 범하는 오류 중 작은 비율만을 차지하며, 90% 이상의 오류가 추론 단계에서 발생합니다.
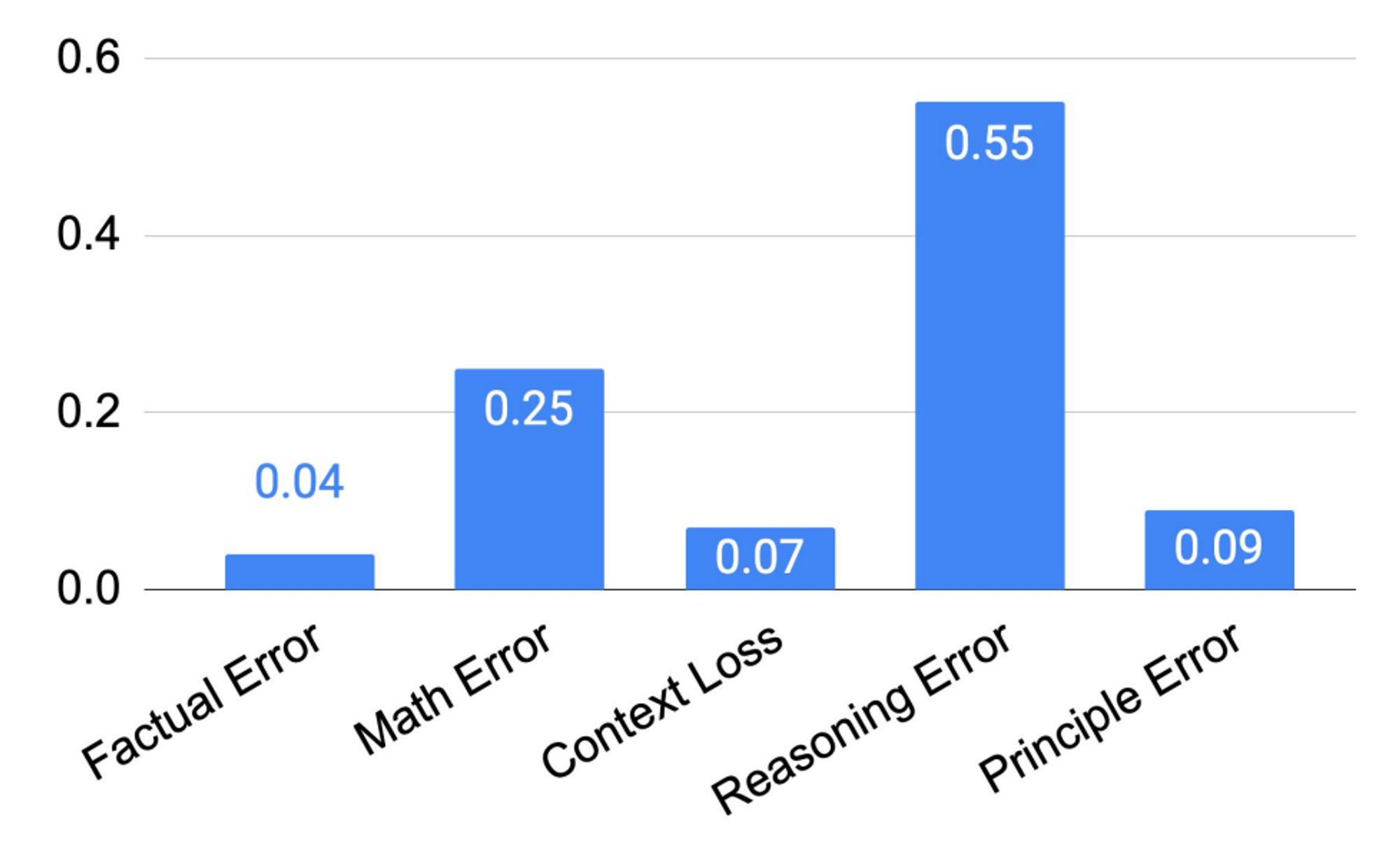
🔼 Figure 04 : STEP-BACK 프롬프팅을 MMLU 고등학교 물리 과제에서 오류 분석: STEP-BACK이 범하는 다섯 가지 유형의 오류 중 추론 오류가 가장 우세한 오류 유형입니다.
추론 단계에서 발생하는 네 가지 오류 유형 중, 추론 오류(Reasoning Error)와 수학 오류(Math Error)가 주요 오류 범주입니다. 이는 소거 연구에서 대형 언어 모델에게 추상화 기술을 시연하기 위해 아주 적은 수의 예시만 필요하다는 발견과 일치합니다. 추론 단계는 여전히 복잡한 추론이 필요한 MMLU와 같은 과제에서 STEP-BACK 프롬프팅이 얼마나 잘 수행될 수 있는지를 결정하는 병목 지점입니다. 특히 MMLU 물리 과제의 경우, 문제를 성공적으로 해결하기 위해서는 추론과 수학 기술이 매우 중요합니다. 비록 기본 원리가 올바르게 검색되었더라도, 올바른 최종 답을 도출하기 위해서는 전형적인 다중 단계 추론 과정을 거쳐야 하며, 이 과정에서 심층적인 추론과 수학이 필요합니다.
5. Knowledge QA
우리는 STEP-BACK 프롬프팅을 평가하기 위해 사실 지식이 많이 요구되는 질문 응답 벤치마크를 사용합니다. 지식 기반 질문 응답은 대형 언어 모델(LLMs)에게 도전적인 과제입니다. 이 섹션에서는 먼저 실험 설정을 설명한 후, STEP-BACK 프롬프팅에 대한 결과와 분석을 제시합니다.
5.1 Step-Back Prompting
우리는 Knowledge QA 범주에서 TimeQA와 SituatedQA에 대해 STEP-BACK 프롬프팅을 평가합니다. 먼저, 맥락 내 시연을 통해 대형 언어 모델에게 추상화 기술을 보여줍니다. Figure 02에 나와 있는 "Estella Leopold의 학력은 무엇인가?"라는 STEP-BACK 질문은 몇 가지 예시를 통해 대형 언어 모델이 생성한 것입니다(자세한 내용은 부록 D.2를 참조하세요). 이러한 질문들은 지식 집약적인 특성을 가지고 있기 때문에, 우리는 검색 증강(RAG)을 STEP-BACK 프롬프팅과 결합하여 사용합니다. STEP-BACK 질문은 관련 사실을 검색하기 위해 사용되며, 이 사실들은 최종 추론 단계를 구체화하는 데 필요한 추가적인 맥락으로 작용합니다(프롬프트에 대한 자세한 내용은 표 14를 참조하세요).
5.2 Results
우리는 TimeQA의 테스트 세트에서 모델들을 평가했습니다. Table 02에서 보듯이, baseline 모델인 GPT-4와 PaLM-2L은 각각 45.6%와 41.5%의 정확도를 달성하여 이 과제의 어려움을 강조했습니다. baseline 모델에 CoT나 TDB Zero-shot(또는 1-shot) 프롬프팅을 적용해도 성능이 향상되지 않았습니다. 반면에, baseline 모델에 일반적인 검색 증강(RAG)을 적용하면 정확도가 57.4%로 향상되어, 이 과제가 사실 집약적인 성격을 가지고 있음을 강조합니다. Step-Back + RAG의 결과는 높은 수준의 개념으로 돌아가서 검색 증강을 훨씬 더 신뢰성 있게 수행할 수 있음을 보여줍니다: TimeQA에서 정확도는 놀라운 68.7%를 달성했습니다.
다음으로, 우리는 TimeQA를 원본 데이터셋에서 제공된 난이도 수준에 따라 쉬운(Easy) 것과 어려운(Hard) 것으로 구분했습니다. 예상대로, 모든 방법이 어려운 하위 집합에서 더 나쁜 성능을 보였습니다. RAG는 쉬운 문제에서 정확도를 42.6%에서 67.8%로 향상시킬 수 있지만, 어려운 문제에서는 개선이 훨씬 적었습니다: 40.4%에서 46.8%로 증가했습니다. 이때 STEP-BACK 프롬프팅은 높은 수준의 개념과 관련된 사실을 검색하여 최종 추론을 구체화함으로써 두각을 나타냅니다: Step-Back + RAG는 어려운 문제에서 정확도를 62.3%까지 더 향상시켜, GPT-4의 42.6%를 능가합니다. 우리는 높은 수준의 개념(예: 학력 이력)과 관련된 사실이 낮은 수준의 세부 사항보다 훨씬 더 접근하기 쉽다는 가설을 세웁니다.
SituatedQA 벤치마크에서는, 성능이 54.3%에서 Step-Back + RAG(61%)로 중간 정도의 향상이 있었고, 이는 GPT-4의 63.2%와 비교하여 작은 차이입니다. TimeQA와 유사하게, CoT와 TDB와 같은 프롬프팅 기법은 SituatedQA에서는 크게 도움이 되지 않았습니다.
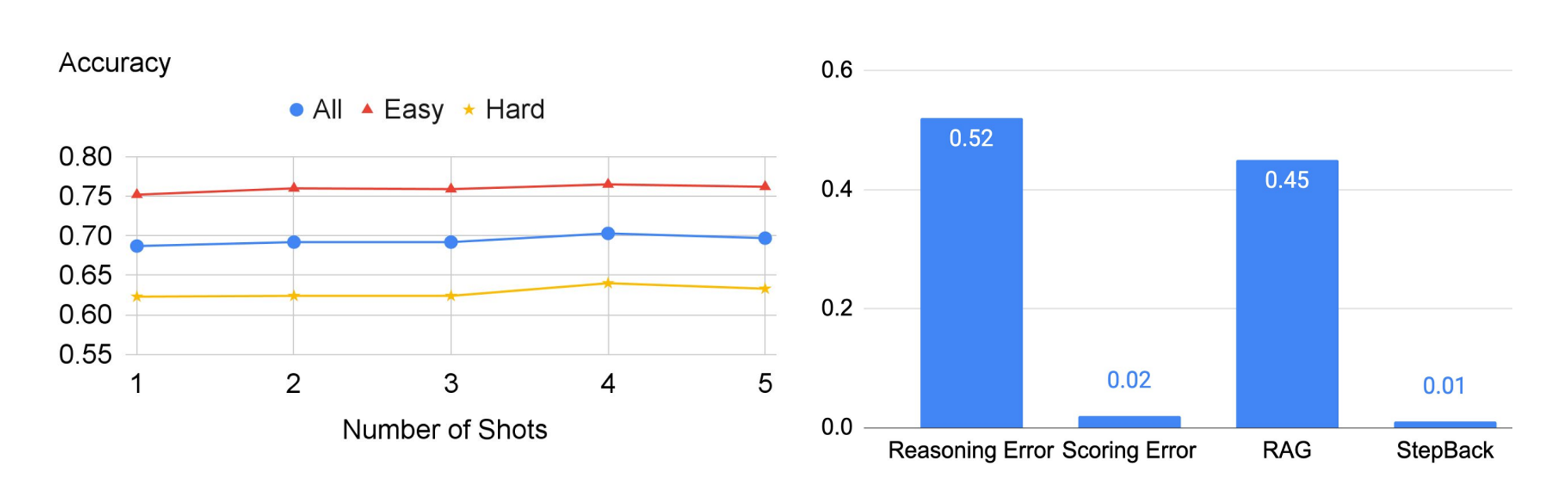
🔼 Figure 05 : TimeQA에서 STEP-BACK 프롬프팅의 abalation 연구 및 오류 분석. left: 몇 가지 shot 예시의 수에 따른 abalation 연구. right: STEP-BACK이 범하는 네 가지 유형의 오류 중, 추론과 RAG가 주요 오류 원인임을 나타냅니다.
5.3 Ablation and Analysis
Few-shot Ablation
Figure 05의 left에서 TimeQA에 대한 STEP-BACK 프롬프팅의 성능이 시연에 사용된 예시의 수에 대해 강력함을 보이며, 이는 PaLM-2L과 같은 모델에서 맥락 학습을 통한 추상화 기술의 샘플 효율성을 다시 한 번 강조합니다.
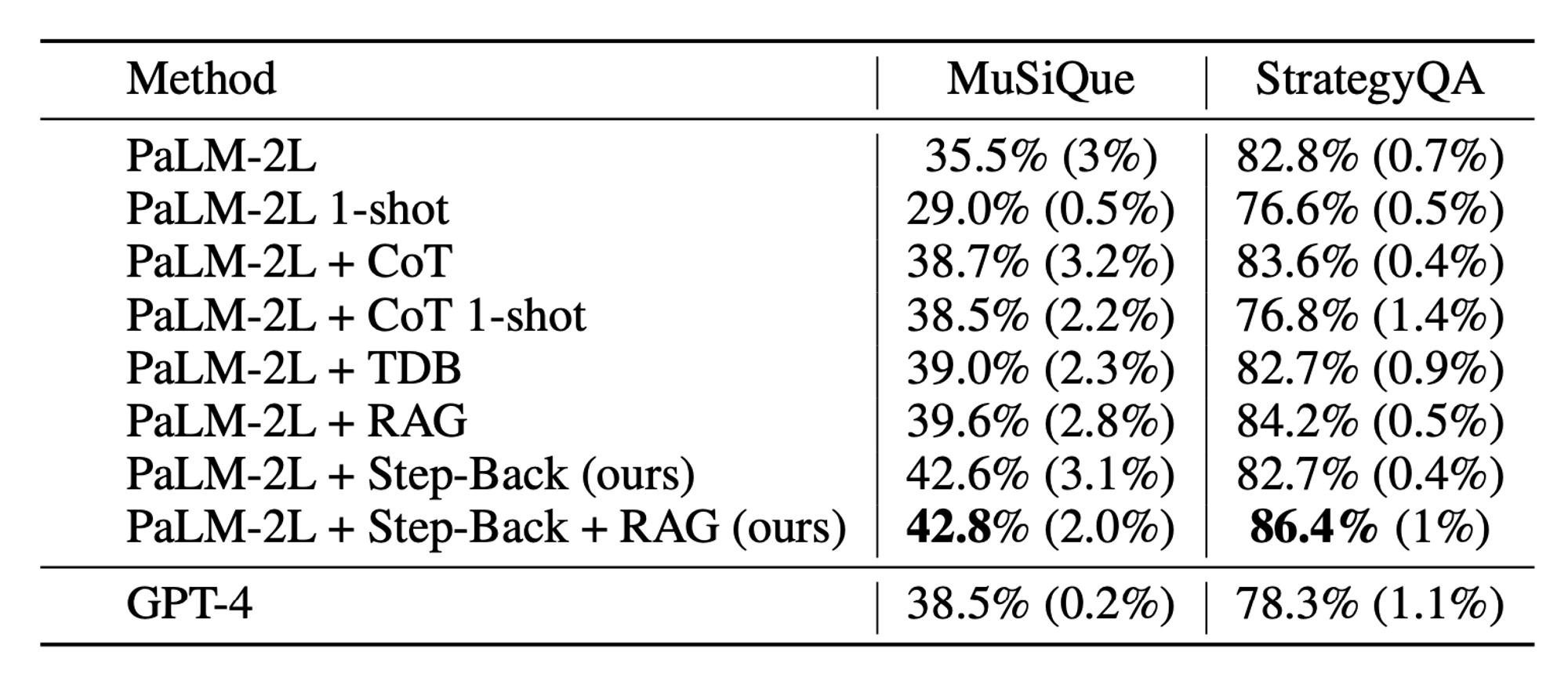
🔼 Table 03 : 다중 단계 추론에서 STEP-BACK 프롬프팅의 결과. CoT: 연쇄 추론 프롬프팅, TDB: 심호흡 프롬프팅, RAG: 검색 증강 생성. 평균 정확도는 5회 평가 실행의 결과이며, 표준 편차는 괄호 안에 포함되어 있습니다.
Error Analysis
Figure 05의 right는 TimeQA에서 STEP-BACK 프롬프팅이 범한 나머지 모든 오류의 분류를 보여줍니다. 4.3절과 유사하게, 우리는 오류를 다음과 같이 분류합니다.
- StepBack : 생성된 STEP-BACK 질문이 과제를 해결하는 데 도움이 되지 않습니다.
- RAG : STEP-BACK 질문이 적절하게 설정되었음에도 불구하고 RAG가 관련 정보를 검색하는 데 실패합니다.
- Scoring Error : judge 모델의 평가가 잘못되었습니다.
- Reasoning Error : 검색된 맥락은 적절하지만, 모델이 이 맥락을 통해 올바른 답을 도출하는 데 여전히 실패합니다.
우리는 StepBack이 거의 실패하지 않는다는 것을 발견했습니다. 반면에, 오류의 절반 이상이 추론 오류로 인해 발생한다는 것을 알았습니다. 또한, StepBack이 제공한 추상화로 인해 작업이 훨씬 쉬워졌음에도 불구하고, 45%의 오류가 적절한 정보를 검색하지 못한 데서 비롯된 것입니다. 이는 TimeQA 과제의 어려움을 반영합니다. TimeQA에 대한 추가 오류 분석은 부록 A에 있습니다.
6. Multi-Hop Reasoning
우리는 STEP-BACK 프롬프팅을 어려운 다중 단계 추론 벤치마크인 MuSiQue와 StrategyQA에서 평가합니다. STEP-BACK 프롬프팅 구현을 위해 5절에서와 동일한 절차를 따릅니다.
Table 03은 MuSiQue와 StrategyQA의 개발 세트에서 다양한 baseline의 성능을 보여줍니다. MuSiQue는 어려운 다중 단계 추론 벤치마크이기 때문에, PaLM-2L과 GPT-4의 baseline 성능이 낮습니다(PaLM-2L 35.5%, GPT-4 38.5%). 반면, StrategyQA는 이진 분류 과제이기 때문에 baseline 성능이 높습니다(PaLM-2L 82.8%, GPT-4 78.3%).
MuSiQue의 경우, CoT와 TDB는 모델 성능을 약간 향상시킵니다(각각 약 3%와 3.5%). 이는 이 과제의 본질적인 추론 특성 때문이며, 이러한 방법들이 도움이 될 수 있음을 나타냅니다. StrategyQA의 경우, CoT와 TDB는 성능에 큰 개선을 가져오지 않습니다. 이는 이 과제의 baseline 성능이 이미 높아서 이러한 프롬프팅 방법들이 성능을 개선할 여지가 제한적이기 때문일 수 있습니다.
종종 1-shot 성능이 zero-shot 방법보다 훨씬 낮은데, 이는 잠재적인 예제 편향(Zhao et al., 2021; Parmar et al., 2023) 때문일 수 있습니다. RAG는 모델 성능을 향상시킵니다(MuSiQue에서는 약 4%, StrategyQA에서는 약 2%). 추상화의 힘을 가진 STEP-BACK 프롬프팅은 모든 방법 중 최고의 성능을 보여줍니다: MuSiQue에서 42.8%, StrategyQA에서 86.4%로, 두 과제 모두에서 GPT-4를 크게 능가합니다. StrategyQA에 대한 자세한 오류 분석은 부록 A.3에 제시합니다.
7. Discussion
추상화는 불필요한 세부 사항을 제거하고 고수준의 개념과 원칙을 정제하여 문제 해결 과정을 안내함으로써, 인간이 복잡한 과제를 해결하는 데 도움을 줍니다. STEP-BACK PROMPTING은 Knowledge QA, Multi-Hop Reasoning, 과학 문제와 같은 복잡한 과제를 추상화와 추론의 두 가지 별도의 단계로 나누어 해결합니다. 경험적 실험을 통해 PaLM-2L과 같은 대규모 언어 모델(LLM)이 샘플 효율적인 맥락 학습을 통해 추상화 기술을 쉽게 습득할 수 있음을 입증했습니다. 고수준의 개념과 원칙을 기반으로 LLM은 내재된 추론 능력을 활용하여 해결책을 도출할 수 있습니다. 이는 중간 단계에서의 추론 실패 가능성을 줄여주며, 다양한 복잡한 추론 작업에서 성능 향상을 보이는 것으로 나타났습니다. 성공에도 불구하고 오류 분석을 통해 추론이 여전히 LLM에게 습득하기 가장 어려운 기술 중 하나임을 발견했습니다. STEP-BACK PROMPTING을 통해 과제의 복잡성이 크게 줄어들었음에도 불구하고, 추론은 여전히 주된 실패 원인으로 남아 있습니다.
그럼에도 불구하고, 추상화는 모든 상황에서 필수적이거나 가능한 것은 아닙니다. 예를 들어, "2000년에 미국 대통령은 누구였는가?"와 같은 간단한 질문의 경우, 한 걸음 물러서서 고수준의 질문을 할 필요가 없습니다. 이런 질문의 답은 이미 쉽게 얻을 수 있기 때문입니다. "빛의 속도는 무엇인가?"와 같은 질문은 기본 원칙 자체를 가리킵니다. 이 경우 추상화를 해도 아무런 차이가 없습니다.
8. Related Work
8.1 Prompting
Few-shot 프롬프팅은 모델의 매개변수를 업데이트하지 않고도 다양한 과제에서 모델 성능을 크게 향상시켰습니다. 우리 연구인 STEP-BACK 프롬프팅은 CoT 프롬프팅과 scratchpad(Nye et al., 2021)와 같은 범주에 속합니다. 이는 간단하고 범용적인 성격을 가지고 있기 때문입니다. 그러나 우리의 접근 방식은 복잡한 작업을 수행할 때 한 발 물러서는 것이 종종 도움이 된다는 사실에서 영감을 받아 추상화라는 핵심 아이디어에 초점을 맞추고 있습니다. 우리의 연구는 recitation-augmented language models(Sun et al., 2022)과도 관련이 있습니다. 그러나 그들의 연구와 달리 우리는 명시적으로 한 발 물러나 추상화를 수행하며, 작업의 성격에 따라 선택적으로 검색 증강을 사용할 수 있습니다.
8.2 Decomposition
Decomposition은 과제를 더 간단한 과제로 분해하고 이러한 과제를 해결하여 원래 과제를 완료하는 것으로 복잡한 과제에서 모델 성능을 향상시키는 효과적인 방법이었습니다(Zhou et al., 2022; Patel et al., 2022; Khot et al., 2022; Press et al., 2022). 여러 프롬프팅 방법이 이 점에서 성공을 거두었습니다. 반면에, 우리 연구인 STEP-BACK 프롬프팅은 질문을 더 추상적이고 고차원적으로 만드는 데 중점을 두고 있습니다. 이는 원래 질문을 종종 낮은 수준으로 분해하는 기존의 decomposition과는 다릅니다. 예를 들어, "1990년에 스티브 잡스가 어느 회사에서 일했습니까?"라는 일반적인 질문에 대해, "스티브 잡스의 고용 이력은 무엇입니까?"와 같은 추상적인 질문이 될 수 있습니다. 분해 방식은 "1990년에 스티브 잡스는 무엇을 하고 있었나요?", "스티브 잡스는 1990년에 고용되었나요?", "만약 고용되었다면, 그의 고용주는 누구였나요?"와 같은 하위 질문으로 이어질 것입니다. 더 나아가, "스티브 잡스의 고용 이력은 무엇입니까?"와 같은 추상적인 질문은 많은 질문들(예: "1990년에 스티브 잡스가 어느 회사에서 일했습니까?"와 "2000년에 스티브 잡스가 어느 회사에서 일했습니까?")이 같은 추상적인 질문으로 이어질 수 있기 때문에, 본질적으로 하나의 추상 질문이 여러 구체적인 질문들과 일대다 매핑 관계를 가질 수 있습니다. 이것은 decomposition과는 대조적입니다. decomposition에서는 주어진 질문을 해결하기 위해 여러 개의 하위 문제들이 필요하기 때문에, 일대다 매핑이 자주 발생합니다.
9. Conclusion
우리는 STEP-BACK PROMPTING을 추상화를 통해 대규모 언어 모델에서 깊은 추론을 이끌어내는 간단하지만 일반적인 방법으로 소개합니다. 사실 탐색, 상식 추론, 도메인별 추론 벤치마크를 대상으로 한 대규모 언어 모델(LLM) 실험에서 STEP-BACK PROMPTING이 모델 성능을 크게 향상시키는 것으로 나타났습니다. 우리는 추상화가 모델이 환각을 덜 일으키고 더 나은 추론을 할 수 있도록 도와주며, 이는 원래 질문에 대한 답변 시 추상화 없이 종종 숨겨진 모델의 본질을 반영한다고 가정합니다. 우리의 연구가 대규모 언어 모델의 숨겨진 잠재력을 이끌어내기 위한 인간 영감의 접근 방식을 더 많이 고취시키기를 바랍니다.
