Interleaving Retrieval with Chain-of-Thought for Knowledge-Intensive Multi-Step Questions (2023)
Paper-Review

Paper Link : https://arxiv.org/pdf/2212.10509
※ 본 포스팅은 논문의 가장 중요한 내용에 대한 리뷰를 정리하여 올리기 때문에 다소 축약되거나 의역된 내용이 많습니다. 참고하세요.Abstract
프롬프트 기반의 대형 언어 모델(LLM)은 자연스러운 언어 추론 단계 또는 여러 단계를 거친 Question Answering을 위한 Chain-of-Thought(CoT)을 생성하는 데 놀라운 능력을 가지고 있습니다. 그러나 필요한 지식이 LLM에 없거나 최신 상태가 아닌 경우에는 어려움을 겪습니다. 질문을 사용해 외부 지식 소스에서 관련 텍스트를 검색하는 것은 LLM에 도움이 되지만, 우리는 이 단일 단계의 검색-읽기 접근법이 여러 단계의 QA에는 불충분하다는 것을 관찰했습니다. 여기서 검색할 내용은 이미 도출된 내용에 따라 달라지며, 이는 다시 이전에 검색한 내용에 따라 달라질 수 있습니다. 이를 해결하기 위해 우리는 IRCoT라는 새로운 접근법을 제안합니다. 이는 CoT의 단계와 검색을 교차하여 검색을 CoT와 함께 안내하고, 검색된 결과를 사용하여 CoT를 개선하는 다단계 QA 접근법입니다. GPT-3와 함께 IRCoT를 사용하면 네 가지 데이터셋(HotpotQA, 2WikiMultihopQA, MuSiQue, IIRC)에서 검색 성능이 최대 21포인트, 하위 QA 성능이 최대 15포인트 향상됩니다. 분포 밖(OOD) 설정에서와 추가 훈련 없이도 Flan-T5-large와 같은 훨씬 작은 모델에서도 유사한 상당한 성능 향상을 관찰했습니다. IRCoT는 모델의 환각을 줄여 사실적으로 더 정확한 CoT 추론을 가능하게 합니다.
1. Introduction
LLM은 적절한 프롬프트를 받을 경우, 일련의 자연어 추론 단계를 생성하여 복잡한 질문에 답할 수 있습니다. 이러한 일련의 추론 단계는 'Chain of Thoughts (CoT)'이라고 불립니다. 이러한 접근법은 질문에 답하기 위해 필요한 모든 정보가 문맥으로 제공되거나(예: 대수학 문제), 모델의 파라미터에 존재한다고 가정될 때(예: 상식 추론) 성공적이었습니다.
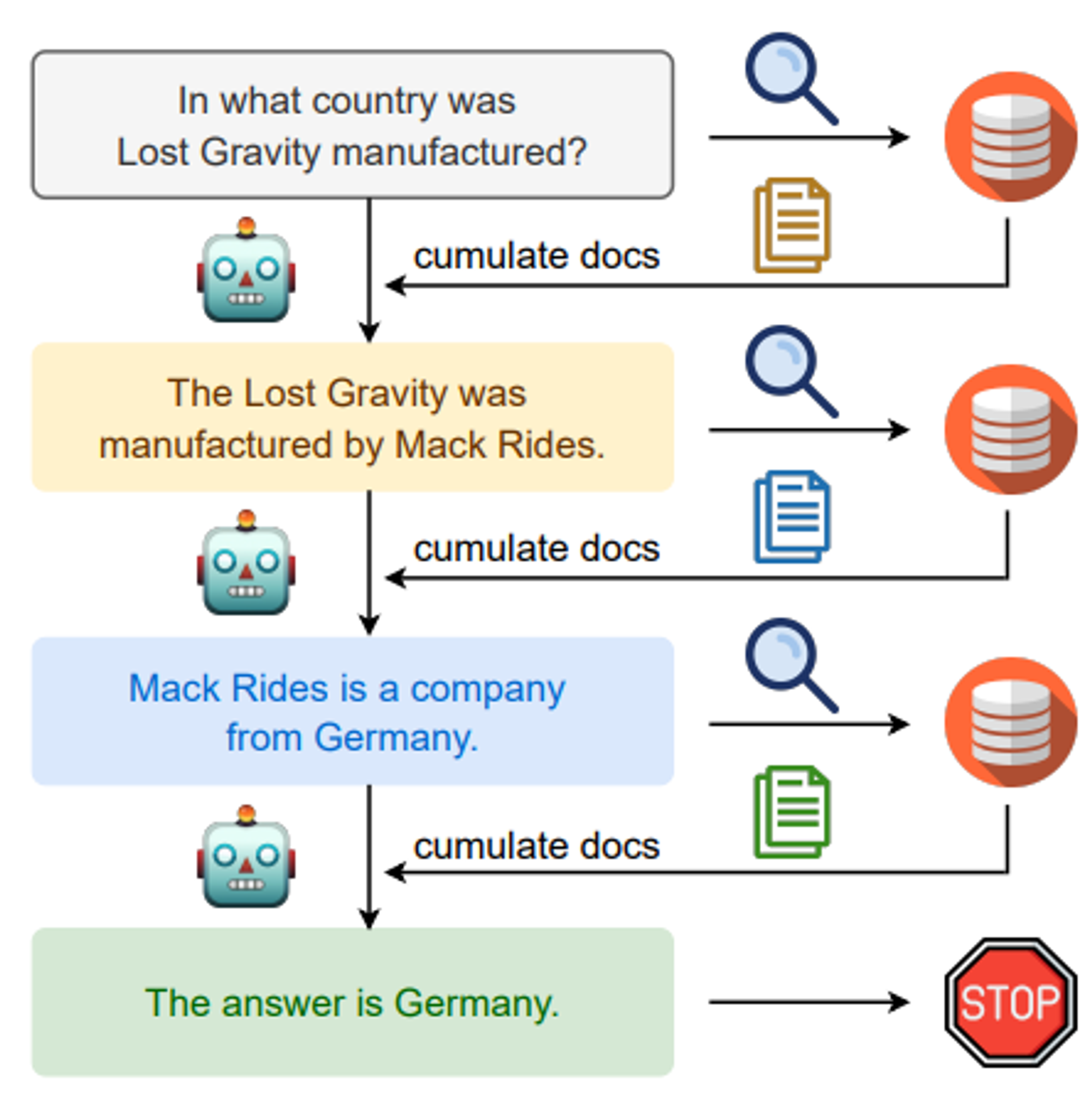
🔼 Figure 01 : IRCoT는 Chain-of-Thought (CoT) 생성과 지식 검색 단계를 교차하여 CoT를 통해 검색을 안내하고, 반대로 검색된 정보를 통해 CoT를 향상시킵니다. 이 교차 접근법은 질문만을 질의로 사용하는 표준 검색 방식과 비교했을 때, 이후의 추론 단계에 더 관련성이 높은 정보를 검색할 수 있도록 합니다.
그러나 많은 오픈 도메인 질문의 경우, 필요한 모든 지식이 항상 모델의 파라미터에 존재하거나 최신 상태로 유지되지 않기 때문에, 외부 소스에서 지식을 검색하는 것이 유용합니다.
어떻게 복잡하고 다단계의 추론을 요구하는 개방형 도메인의 지식 집약적인 작업에서 CoT 프롬프트를 강화할 수 있을까요?
질문만을 기반으로 지식 소스에서 한 번의 검색을 통해 관련 지식을 추가하는 방법은 많은 사실 기반 작업에 대해 언어 모델을 성공적으로 강화할 수 있지만, 이 전략은 더 복잡한 다단계 추론 질문에 대해서는 명확한 한계를 가지고 있습니다. 이와 같은 질문에 대해서는, 종종 부분적인 지식을 검색하고, 부분적인 추론을 수행하며, 지금까지의 부분 추론 결과를 바탕으로 추가 정보를 검색하고, 이를 반복해야 합니다. 예를 들어, Figure 01에 제시된 질문인 "Lost Gravity는 어느 나라에서 제조되었나요?"를 고려해보세요.
질문(특히 롤러코스터 Lost Gravity)을 질의로 사용하여 검색된 위키피디아 문서에는 Lost Gravity가 어디에서 제조되었는지 언급되어 있지 않습니다. 대신, 먼저 그것이 Mack Rides라는 회사에 의해 제조되었다는 것을 추론한 다음, 추론된 회사 이름을 바탕으로 추가 검색을 수행하여 제조 국가를 알아내야 합니다. 이러한 직관을 바탕으로 우리는 이 문제에 대한 교차 접근법을 제안합니다. 이 접근법의 아이디어는 검색을 사용하여 CoT추론 단계를 안내하고, CoT 추론을 사용하여 검색을 안내하는 것입니다. Figure 01은 우리의 검색 방법의 개요를 보여주며 우리는 이것을 IRCoT라고 부릅니다.
우리는 질문을 질의로 사용하여 기본 단락 집합을 검색하는 것으로 시작합니다. 그 후, 다음 두 단계를 번갈아 수행합니다:
(i) CoT 확장 : 질문, 지금까지 수집된 단락들, 그리고 지금까지 생성된 CoT 문장을 사용하여 다음 CoT 문장을 생성합니다.
(ii) 검색된 정보 확장: 마지막 CoT 문장을 질의로 사용하여 추가 단락을 검색하고 수집된 집합에 추가합니다. 우리는 CoT가 답을 보고하거나 허용된 최대 추론 단계 수에 도달할 때까지 이 단계를 반복합니다. 종료 시, 모든 수집된 단락이 검색 결과로 반환됩니다. 마지막으로, 이를 사용하여 직접 질문 응답 프롬프트 또는 CoT 프롬프트를 통해 질문에 답하는 데 필요한 문맥으로 활용합니다.
우리는 개방형 도메인 설정에서 4개의 다단계 추론 데이터셋인 HotpotQA, 2WikiMultihopQA, MuSiQue, IIRC에 대해 시스템의 효율성을 평가합니다. OpenAI GPT-3 (code-davinci-002)을 사용한 실험 결과, IRCoT를 사용한 검색이 기준이 되는 단일 단계 질문 기반 검색보다 11~21 포인트 더 높은 회수율을 기록하며, 고정 예산 최적 회수 설정에서 훨씬 더 효과적임을 보여줍니다. IRCoT를 프롬프트 기반 리더와 함께 사용할 경우, downstream few-shot QA 성능이 최대 15점(F1) 향상되며, 생성된 CoT 에서 실제 오류가 최대 50%까지 감소합니다. 우리의 접근법은 훨씬 더 작은 Flan-T5 모델(11B, 3B, 0.7B)에서도 유사한 경향을 보이며 작동합니다. 특히, 우리는 IRCoT를 사용한 Flan-T5-XL (3B) 모델이 단일 단계 질문 기반 검색을 사용하는 58배 더 큰 GPT-3보다도 뛰어난 성능을 보인다는 것을 발견했습니다. 또한, 이러한 성능 향상은 한 데이터셋의 예시를 다른 데이터셋에서 테스트할 때 사용하는 분포 외(out-of-distribution, OOD) 설정에서도 유지됩니다. 마지막으로, 우리의 QA score는 최근 연구에서 보고된 개방형 도메인 질문 응답(ODQA)에 대한 few-shot prompting 관련 점수를 초과한다는 점을 언급합니다. 하지만, 이들과 공정하게 직접 비교하는 것(apples-to-apples comparison)은 불가능합니다.
요약하자면, 우리의 주요한 contribution은 LLM의 Chain-of-Thought 생성 능력을 활용하여 검색을 안내하고, 검색을 통해 CoT 추론을 향상시키는 새로운 검색 방법인 IRCoT를 제안한 것입니다.
IRCoT에 대한 증명:
- 여러 다단계 개방형 도메인 QA Dataset에서, IID (Independent Identically Distribution)와 OOD (Out of Distribution) 모두에서 검색 성능과 few-shot 응답 성능을 개선합니다.
- 생성된 CoT 응답에서 사실적 오류를 줄입니다.
- 대규모 모델(175B)과 소규모 모델(Flan-T5 시리즈, ≤11B) 모두에서 훈련 없이 성능을 향상시킵니다.
2. Related Work
Prompting for Open-Domain QA.
LLM은 프롬프트상에서 몇개의 예제를 간단하게 사용하는것으로 다양한 task를 배울 수 있습니다. 몇 개의 예시(=few shot) 또는 아예 없는 경우(=zero shot)를 제공하여 프롬프트를 하면, CoT를 통해 복잡한 질문에 답할 수 있다는 것입니다. 프롬프트 방식은 Open-Domain QA에 적용되고 있습니다. 그러나 다단계 개방형 질문에 대한 검색 및 질문 응답 성능 향상에서의 가치는 상대적으로 덜 연구된 상태입니다.
최근에 다단계 개방형 질문 응답(QA)을 위한 세 가지 접근 방식이 제안되었습니다. SelfAsk는 질문을 하위 질문으로 분해하고 Google 검색 API를 호출하여 하위 질문에 답변하는 방법입니다. DecomP 는 작업을 분해하고 적절한 하위 모델에 하위 작업을 위임하는 일반적인 프레임워크입니다. 이 방법 역시 질문을 분해하지만, BM25 기반의 검색기를 통해 검색 작업을 위임합니다. 이 두 접근 방식은 CoT 추론을 위해 개발된 것이 아니며, 검색 문제에 중점을 두지 않고, 단일 단계의 QA 모델을 사용해 분해된 질문에 답변해야 합니다. 최근 제안된 ReAct 시스템은 문제를 추론과 행동 단계를 생성하는 일련의 과정으로 구성합니다. 이러한 단계들은 훨씬 더 복잡하고, 훨씬 더 큰 모델(PaLM-540B)을 필요로 하며, 다단계 개방형 질문 응답(ODQA)에서 CoT를 능가하려면 세밀한 조정이 필요합니다. 또한, 이러한 연구들 중 어느 것도 훈련 없이 작은 모델에 대해 효과적인 것으로 증명된 바 없습니다. 이러한 접근 방식들과 직접적인 비교는 쉽지 않지만(지식 코퍼스, LLMs, 예시의 차이로 인해), 우리가 수행한 ODQA의 성능은 그들이 보고한 모든 수치보다 훨씬 높다는 것을 알 수 있었습니다.
Supervised Multi-Step Open-Domain QA.D
이전 연구에서는 개방형 질문 응답(QA)을 위한 반복 검색을 완전한 지도 학습 환경에서 탐구했습니다. Rajarshi Das는 신경 질의 표현을 사용하여 검색을 수행한 후, 읽기 이해 모델의 출력을 기반으로 이를 업데이트하는 반복 검색 모델을 제안(=Multi-step Retriever-Reader Interaction for Scalable Open-domain Question Answering, 2019)했습니다. Yair Feldman and Ran El-Yaniv는 유사한 신경 질의 재구성 아이디어를 다중 단계 개방형 질문 응답(QA)에 적용(=Multi-Hop Paragraph Retrieval for Open-Domain Question Answering, 2019)했습니다. Xiong은 널리 사용되는 Dense Passage Retrieval (DPR)를 다중 단계 설정으로 확장(=Answering Complex Open-Domain Questions with Multi-Hop Dense Retrieval, 2021)했으며, 이는 Khattab에 의해 이후 개선(=Baleen: Robust Multi-Hop Reasoning at Scale via Condensed Retrieval, 2021)되었습니다. Asai는 위키피디아 단락에 존재하는 엔티티 링크가 유도하는 그래프 구조를 활용하여 반복적인 다단계 검색(=Learning to Retrieve Reasoning Paths over Wikipedia Graph for Question Answering, 2019)을 수행했습니다. GoldEn (Gold Entity) 검색기(= Answering Complex Open-domain Questions Through Iterative Query Generation, 2019)는 상용 검색기로부터 검색된 단락을 기반으로 텍스트 질의를 반복적으로 생성하지만, 다음 질의 생성기를 위해 훈련 데이터를 필요로 합니다. Nakano는 브라우저와 상호작용하여 장문의 질문에 답하기 위해 GPT-3을 사용했지만, 이러한 상호작용에 대한 인간 주석에 의존(= WebGPT : Broswer-assisted question-answering with human feed, 2022)했습니다. 이 모든 방법은 대규모 데이터셋에 대한 지도 학습에 의존하며, few-shot으로 설정된 상황에서는 쉽게 확장될 수 없습니다.
3. Chain-of-Thought-Guided Retrieval and Open-Domain QA
우리의 목표는 knowledge source를 포함한 많은 수의 document를 사용하여 few-shot을 구성한 knowledge-intensive multi-step reasoning question (Q)에 대답하는 것입니다. 이를 위해 우리는 먼저 검색하고 읽는 방식(retrieve-and-read paradigm)을 따릅니다. 이 방식에서는 검색기가 먼저 지식 원천에서 문서를 검색하고, QA 모델이 검색된 문서와 질문을 읽어 최종 답변을 생성합니다. 우리의 기여는 주로 검색 단계에 있으며, 읽기 단계에서는 표준 프롬프트 전략을 사용합니다. 앞서 언급한 바와 같이, 다단계 추론에서는 검색이 다음 추론 단계를 안내할 수 있으며, 이는 다시 다음에 검색할 내용을 결정하는 데 도움이 될 수 있습니다. 이러한 점은 다음에 논의할 우리의 교차 전략(interleaving strategy)을 도입하는 동기가 됩니다.
3.1 Interleaving Retrieval with Chain-of-Thought Reasoning
우리가 제안한 검색 방법인 IRCoT는 다음 세 가지 요소로 구성됩니다:
(i) 질의를 받아서 corpus 또는 knowledge source에서 일정 수의 단락을 반환할 수 있는 기본 검색기
(ii) zero/few-shot Chain of Thought 생성 기능을 갖춘 언어 모델
(iii) 답변에 도달하는 방법을 자연어로 설명하는 추론 단계를 포함한 소수의 주석된 질문과, 이 추론 사슬과 답변을 집합적으로 뒷받침하는 지식 원천의 단락들.
IRCoT의 개요는 Figure 02에 있습니다. 우리는 먼저 질문 Q를 질의로 사용하여 K개의 단락을 검색하여 기본 단락 세트를 모읍니다. 그다음, 종료 기준을 충족할 때까지 두 가지 단계(reason and retrieve)를 반복적으로 교차 수행합니다. 검색에 의해 안내되는 추론 단계(“추론”)에서는 질문, 지금까지 모은 단락, 그리고 지금까지 생성된 연쇄 사고 문장을 사용하여 다음 CoT 문장을 생성합니다. 작업을 위한 프롬프트 템플릿은 다음과 같은 형태를 띱니다:
Wikipedia Title: <Page Title>
<Paragraph Text>
...
Wikipedia Title: <Page Title>
<Paragraph Text>
Q: <Question>
A: <CoT-Sent-1> ... <CoT-Sent-n>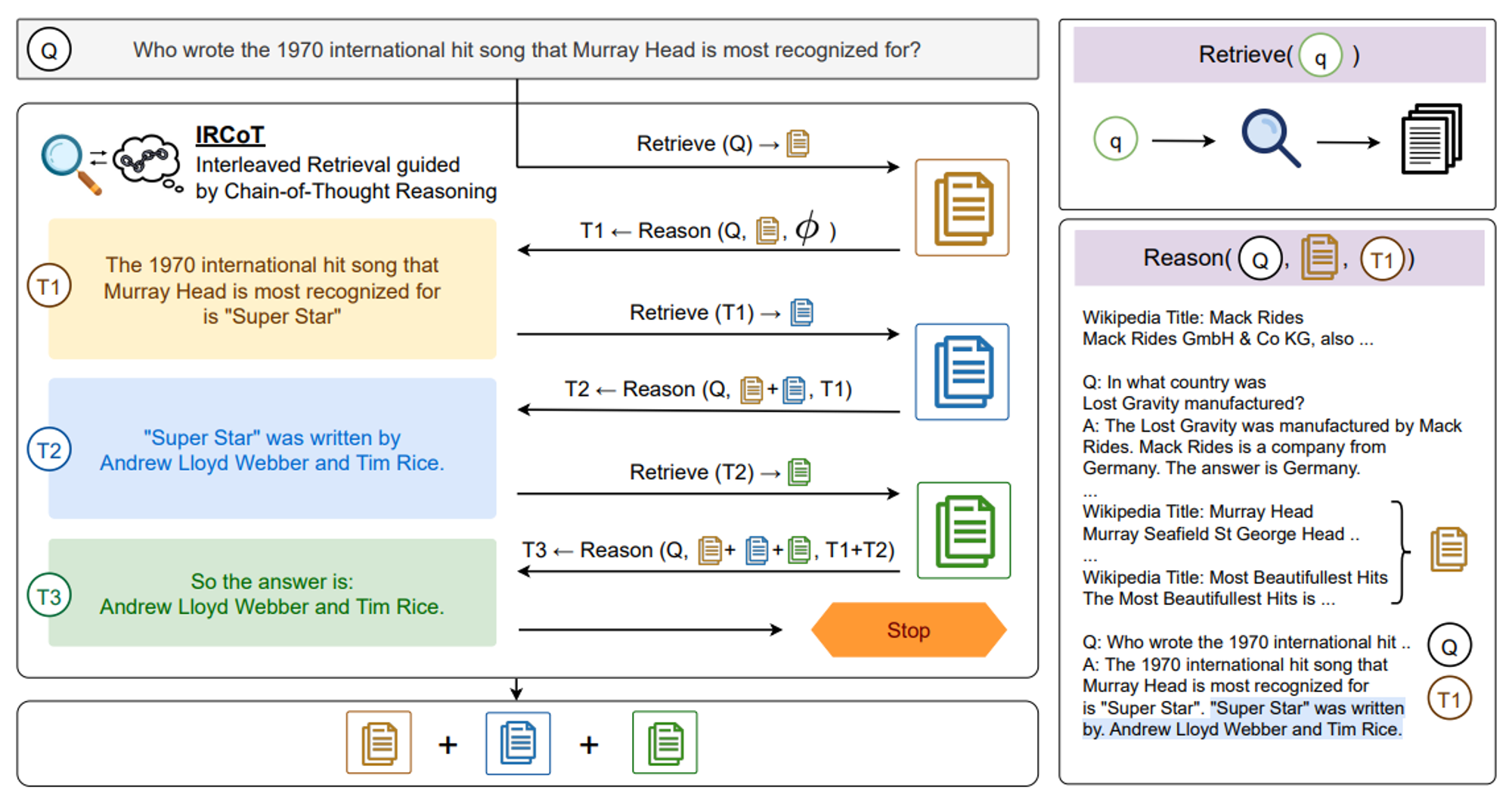
🔼 Figure 2 : IRCoT는 연쇄 사고(CoT) 생성 단계와 검색 단계를 교차 수행하여 CoT로 검색을 안내하고 반대로 검색으로 CoT를 안내합니다. 우리는 질문을 질의로 사용하여 K개의 문서를 검색하는 것으로 시작하고, 종료될 때까지 두 단계를 번갈아 반복합니다. (i) 추론 단계에서는 질문, 지금까지 검색된 단락, 그리고 CoT 문장들을 기반으로 다음 CoT 문장을 생성합니다. (ii) 검색 단계에서는 마지막 CoT 문장을 기반으로 추가로 K개의 단락을 검색합니다. 생성된 CoT에 "answer is:”이라는 문구가 포함되거나, 단계 수가 정해진 임계치를 초과하면 프로세스가 종료됩니다. 종료 시에는 모든 단락의 모음이 검색 결과로 반환됩니다.
우리는 모델에게 지금까지 생성된 연쇄 사고(CoT) 문장만 보여주고 나머지를 모델이 완성하도록 합니다. 모델이 여러 문장을 출력할 수 있지만, 각 추론 단계에서는 첫 번째로 생성된 문장만 사용하고 나머지는 버립니다. 맥락 내 시연 예시에서 사용되는 단락은 실제 답변을 뒷받침하는 단락과 무작위로 샘플링된 M개의 단락을 위의 형식으로 섞어 연결한 것입니다. 테스트 인스턴스의 경우, 지금까지 모든 이전 검색 단계에서 모은 모든 단락을 모델에 보여줍니다.
생성된 CoT 문장에 "answer is:"라는 문자열이 포함되어 있거나 최대 단계 수에 도달하면, 프로세스를 종료하고 수집된 모든 단락을 검색 결과로 반환합니다. CoT에 의해 안내되는 검색 단계("검색")에서는 마지막으로 생성된 CoT 문장을 질의로 사용하여 추가 단락을 검색하고, 이를 수집된 단락에 추가합니다. 우리는 수집된 단락의 총 수를 제한하여 모델의 맥락 한도 내에 적어도 몇 개의 시연을 포함할 수 있도록 합니다.
3.2 Question Answering Reader
QA Reader는 검색기에서 가져온 단락을 사용하여 질문에 답변합니다. 우리는 두 가지 프롬프트 전략을 통해 구현된 두 가지 버전의 QA 리더를 고려합니다: Wei et al. (2022)에서 제안한 CoT프롬프트와 Brown et al. (2020)에서 제안한 직접 프롬프트입니다. CoT 프롬프트의 경우, §3.2에 나온 것과 동일한 템플릿을 사용하지만, 테스트 시에는 모델이 전체 CoT를 처음부터 생성하도록 요청합니다. CoT의 마지막 문장은 "answer is: ..." 형식을 취하도록 되어 있어, 이를 통해 답변을 프로그램적으로 추출할 수 있습니다. 만약 이 형식이 아닐 경우, 전체 생성물이 답변으로 반환됩니다. 직접 프롬프트의 경우, CoT 프롬프트와 동일한 템플릿을 사용하지만, 답변 필드("A: ")에는 CoT 대신 최종 답변만 포함됩니다. 자세한 내용은 부록 G를 참조하십시오.
4. Experimental Setup
다음은 오픈 도메인 환경에서 4개의 다중 단계 질의응답(QA) 데이터셋을 평가한 결과입니다: HotpotQA, 2WikiMultihopQA, MuSiQue의 답변 가능한 하위집합, 그리고 IIRC의 답변 가능한 하위집합. HotpotQA의 경우, 오픈 도메인 환경을 위해 제공된 위키피디아 말뭉치를 사용했습니다. 다음은 나머지 세 개의 데이터셋에 대한 설명입니다. 이 데이터셋들은 원래 독해나 혼합 환경에서 제공되었으며, 우리는 이와 관련된 문맥을 사용하여 오픈 도메인 환경을 위한 말뭉치를 구성했습니다 (자세한 내용은 부록 A 참조하십시오). 각 데이터셋에 대해, 우리는 원래 개발 세트에서 무작위로 추출한 100개의 질문을 하이퍼파라미터 조정에 사용하고, 다른 500개의 무작위로 추출된 질문을 테스트 세트로 사용했습니다.
4.1 Models
Retriever.
우리는 Elasticsearch 6에 구현된 BM25 (Robertson et al., 2009)를 기본 검색기로 사용합니다. 두 개의 검색 시스템을 비교했습니다:
(ⅰ) One-step Retriever(OneR) : 질문을 쿼리로 사용하여 K개의 단락을 검색합니다. 우리는 개발 세트에서 가장 좋은 성능을 보이는 값을 선택합니다.
(ⅱ) IRCoT Retriever 는 §3에서 설명된 우리의 방법입니다. 우리는 BM25를 기본 검색기로 사용하며, OpenAI GPT-3 (code-davinci-002)와 Flan-T5의 다양한 크기를 CoT 생성기로 사용하여 실험을 진행했습니다.
이 언어 모델들에게 맥락 내 예시를 보여주기 위해, 우리는 모든 데이터셋에 대해 20개의 질문에 대한 체인 오브 생각(CoTs)을 작성했습니다(부록 §G 참조). 그런 다음 각 데이터셋에서 각각 15개의 질문을 샘플링하여 3개의 시범 (“training”) 세트를 만들었습니다. 각 실험에서는 첫 번째 시범 세트를 사용하여 개발 세트에 가장 적합한 하이퍼파라미터를 찾고, 선택된 하이퍼파라미터를 사용하여 각 시범 세트를 테스트 세트에서 평가합니다. 각 실험에 대해 이 세 가지 결과의 평균과 표준 편차를 보고합니다.
테스트 시점에는 모델의 컨텍스트 길이 제한 내에서 가능한 한 많은 시범 예제를 포함시킵니다. GPT-3 (code-davinci-002)의 컨텍스트 제한은 8K word-piece입니다. Flan-T5-*는 상대적 위치 임베딩을 사용하기 때문에 명확한 제한은 없지만, 80G A100 GPU 메모리에 맞출 수 있는 최대한도로 Flan-T5의 컨텍스트를 6K word-piece으로 제한합니다.
Retrieval Metric.
우리는 모든 검색 시스템에 대해 최대 15개의 단락을 허용하고, 검색된 단락 집합 중에서 정답 단락의 재현율을 측정합니다. 우리는 개발 세트에서 재현율을 최대화하는 하이퍼파라미터 (및 IRCoT의 경우 )를 찾고, 이를 테스트 세트에 사용합니다. 따라서 보고된 메트릭은 고려된 각 시스템에 대한 고정 예산 최적 재현율로 볼 수 있습니다.
QA Reader.
QA Reader를 구현하기 위해, 우리는 IRCoT 검색기의 추론 단계에서 사용된 것과 동일한 언어 모델(LM)을 사용합니다. 우리는 Flan-T5-로 구현된 질의응답(QA) 리더가 직접 프롬프트 전략(Direct Prompting)에서 더 나은 성능을 보이고, GPT-3는 체인 오브 생각(CoT) 프롬프트 전략에서 더 나은 성능을 보인다는 것을 발견했습니다(부록 E 참조). 따라서 실험에서는 Flan-T5-를 사용한 질의응답(QA)에 대해 직접 프롬프트 전략을, GPT-3에는 체인 오브 생각(CoT) 전략을 사용합니다.
QA Reader에는 한 가지 하이퍼파라미터 M이 있습니다. 이는 맥락 내 시범 예제에서 방해 단락의 수를 나타냅니다. 우리는 M 값을 범위에서 검색합니다. IRCoT 검색기와 함께 사용할 때, M 값은 CoT생성기와 리더 모두에 적용됩니다.
Open-Domain QA (ODQA) Models.
검색기와 리더를 결합하여, 다양한 언어 모델로 구성된 ODQA(오픈 도메인 질의응답) 모델인 OneR QA와 IRCoT QA로 실험을 진행합니다.
QA.
IRCoT QA의 경우, 체인 오브 생각(CoT) 생성기와 리더에 동일한 언어 모델(LM)을 사용합니다. 또한 검색기 없이 질의응답(QA) 리더인 NoR QA를 사용하여 언어 모델이 자체 파라메트릭 지식만으로 질문에 얼마나 잘 답할 수 있는지를 평가하는 실험도 진행합니다. ODQA(오픈 도메인 질의응답) 모델의 최적의 하이퍼파라미터를 선택하기 위해, 우리는 개발 세트에서 답변의 F1 점수를 최대화하는 하이퍼파라미터 K와 M을 탐색합니다. IIRC는 다른 데이터셋과 약간 다르게 구조화되어 있습니다. 이 데이터셋의 질문은 주요 문단에 기반을 두고 있으며, 추가로 지원하는 단락은 이 문단에서 언급된 엔티티의 위키피디아 페이지에서 가져옵니다. 이를 고려하여 검색기와 리더를 약간 수정했습니다 (부록 B 참조).
5. Results
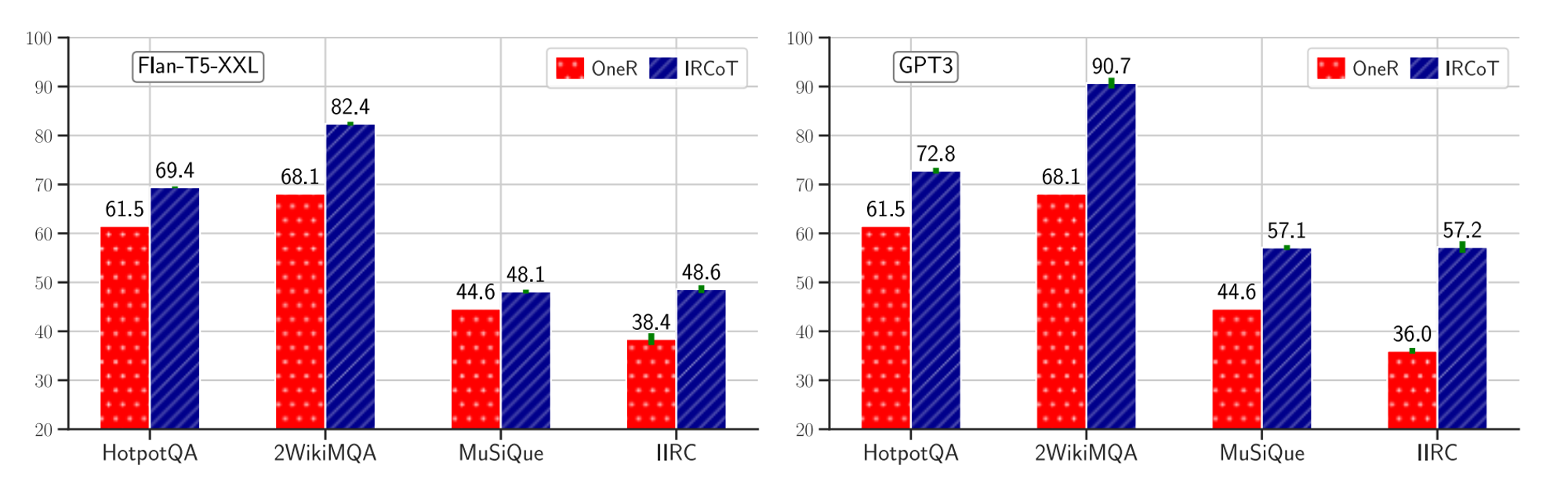
🔼 Figure 03 : Flan-T5-XXL(왼쪽)과 GPT-3(오른쪽) 모델에서 생성된 단일 단계 검색기(OneR)와 IRCoT의 검색 재현율입니다. IRCoT는 두 모델과 모든 데이터셋에서 OneR을 능가합니다.
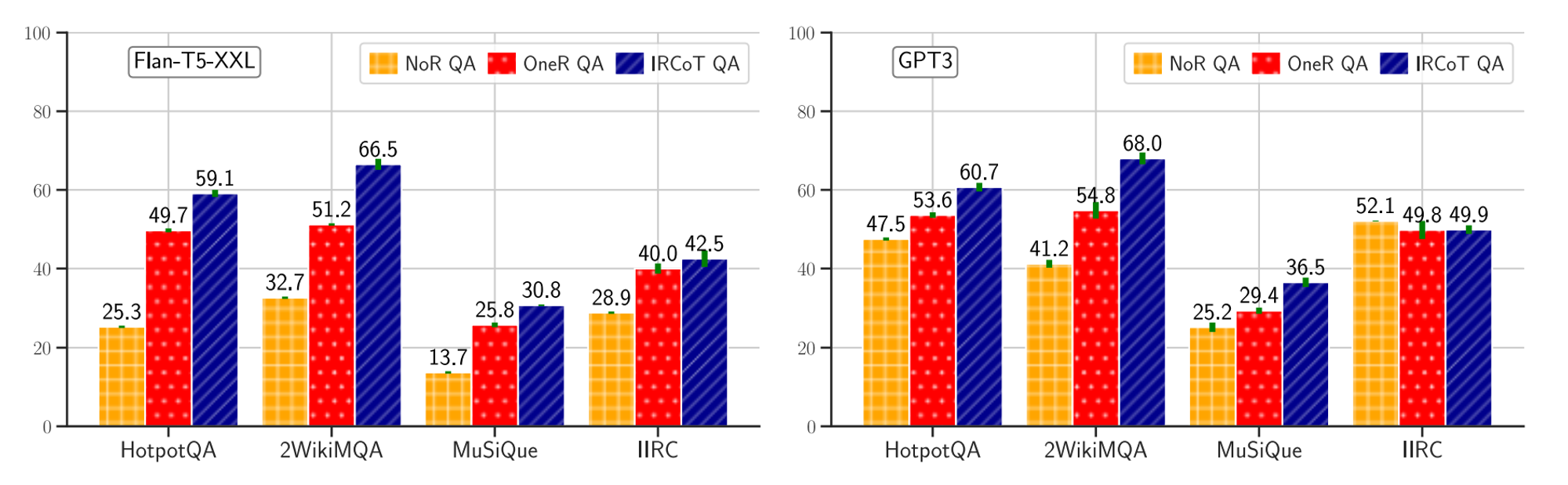
🔼 Figure 04 : ODQA 모델의 답변 F1 점수를 (i) 검색기 없이(NoR QA), (ii) 단일 단계 검색기(OneR QA), (iii) Flan-T5-XXL(왼쪽) 및 GPT-3(오른쪽) 모델에서 생성된 IRCoT QA로 측정한 결과입니다. IRCoT QA는 모든 데이터셋에서 두 모델 모두에 대해 OneR QA와 NoR QA를 능가하지만, IIRC 데이터셋에서는 GPT-3를 제외하고 성능이 더 우수합니다.
※ 이해를 돕기위한 부가설명을 덧붙이겠다.
- "NoR QA"는 언어모델에게 다른 프롬프트 없이 직접 질의한것
- "OneR QA"는 검색기를 하나 붙인것
- "IRCoT"는 "OneR QA"와 동일하나 프롬프트를 본 논문에서 제시한 것을 사용한 것을 말한다.
IRCoT retrieval is better than one-step.
Figure 03은 Flan-T5-XXL과 GPT-3 언어 모델로 만든 OneR과 IRCoT 검색기를 비교한 것입니다. 두 모델 모두에서 IRCoT는 모든 데이터셋에서 단일 단계 검색을 상당히 능가합니다. Flan-T5-XXL의 경우, IRCoT는 단일 단계 검색과 비교하여 우리의 재현율 메트릭을 HotpotQA에서 7.9점, 2WikiMultihopQA에서 14.3점, MuSiQue에서 3.5점, IIRC에서 10.2점 향상시킵니다. GPT-3의 경우, 이 개선치는 각각 11.3점, 22.6점, 12.5점, 21.2점입니다.
IRCoT QA outperforms NoR and OneR QA.
Figure 04는 Flan-T5-XXL과 GPT-3 언어 모델로 만든 NoR, OneR, IRCoT 검색기를 사용한 ODQA 성능을 비교한 것입니다. Flan-T5-XXL의 경우, IRCoT QA는 HotpotQA에서 OneR QA를 9.4점, 2WikiMultihopQA에서 15.3점, MuSiQue에서 5.0점, IIRC에서 2.5 F1 점수로 능가합니다. GPT-3의 경우, 해당 수치는 IIRC를 제외하고 각각 7.1점, 13.2점, 7.1 F1 점수입니다. GPT-3의 경우, IRCoT는 IIRC에서 QA 점수를 개선하지 못했지만, 검색 성능은 21점으로 크게 향상되었습니다(그림 3 참조). 이는 아마도 IIRC에 대한 관련 지식이 이미 GPT-3에 포함되어 있기 때문일 가능성이 높으며, NoR QA 점수가 유사하다는 점이 이를 뒷받침합니다. 다른 데이터셋과 모델 조합에서는 NoR QA가 IRCoT QA보다 훨씬 성능이 떨어지며, 이는 모델의 파라메트릭 지식의 한계를 나타냅니다.
IRCoT is effective in OOD setting.
새로운 데이터셋에 대해 체인 오브 생각(CoT)을 작성하는 것이 항상 쉬운 것은 아니므로, 우리는 NoR, OneR, 그리고 IRCoT의 새로운 데이터셋에 대한 일반화 성능을 평가합니다. 즉, OOD(도메인 외부) 설정에서 평가합니다. 이를 위해, 하나의 데이터셋에서 가져온 프롬프트 시범 예제를 사용하여 다른 데이터셋을 평가합니다. 모든 데이터셋 쌍에 대해, Flan-T5-XXL과 GPT-3 모두에서 IID 설정과 동일한 경향을 발견했습니다: IRCoT 검색이 OneR보다 우수하며(Figure 05 참조), IRCoT QA는 OneR QA와 NoR QA 모두를 능가합니다(Figure 06 참조).
IRCoT generates CoT with fewer factual errors.
우리 접근법이 생성된 CoT의 사실성도 개선하는지 평가하기 위해, 우리는 네 개의 데이터셋 각각에서 무작위로 추출한 40개의 질문에 대해 NoR QA, OneR QA, 그리고 IRCoT QA를 사용하여 GPT-3으로 생성된 CoT를 수동으로 주석 처리했습니다. 우리는 체인 오브 생각(CoT)에서 적어도 하나의 사실이 진실이 아닐 경우, 해당 CoT를 사실 오류가 있는 것으로 간주했습니다. 그림 7에 나타난 것처럼, NoR은 가장 많은 사실 오류를 발생시키고, OneR은 그보다 적게, IRCoT는 가장 적게 발생시킵니다. 특히, IRCoT는 HotpotQA에서 OneR에 비해 사실 오류를 50% 줄이고, 2WikiMultihopQA에서는 40% 줄입니다.
표 2는 다양한 방법에 따른 CoT 예측이 질적으로 어떻게 다른지를 보여줍니다. NoR은 완전히 파라메트릭 지식에 의존하기 때문에 종종 첫 문장에서 사실 오류를 발생시키고, 이로 인해 전체 CoT가 틀어지게 됩니다. OneR은 질문과 가장 가까운 관련 정보를 검색할 수 있어 초기 단계에서 이러한 오류를 덜 발생시키지만, 여전히 CoT 후반부에서 오류를 범합니다. 반면 IRCoT는 각 단계에서 이러한 오류를 방지할 수 있는 경우가 많습니다.
IRCoT is also effective for smaller models.
IRCoT가 다양한 크기의 언어 모델(LM)에서 얼마나 효과적인지 확인하기 위해, 우리는 그림 8에 스케일링 플롯을 제시합니다. 우리는 Flan-T5 {base (0.2B), large (0.7B), XL (3B), XXL (11B)}와 GPT-3 code-davinci-002 (175B)를 사용하여 OneR과 IRCoT의 재현율을 비교합니다. IRCoT는 가장 작은 모델(0.2B)로도 OneR보다 우수하며, 성능은 모델 크기에 따라 대체로 향상됩니다. 이는 CoT 생성 능력이 작은 모델에서도 검색 성능을 개선하는 데 활용될 수 있음을 보여줍니다. 또한, 우리는 그림 9에서 모델 크기가 QA 점수에 미치는 영향을 보여줍니다. 가장 작은 모델(0.2B)을 제외한 모든 크기에서 IRCoT QA는 OneR QA보다 우수한 성능을 보입니다. 더 나아가, IRCoT는 3B 모델을 사용해도 모든 데이터셋에서 58배 더 큰 175B GPT-3 모델을 사용한 OneR과 NoR보다 더 뛰어난 성능을 보입니다.
IRCoT is SOTA for few-shot multistep ODQA.
우리는 IRCoT QA를 최근의 다섯 가지 ODQA(오픈 도메인 질의응답) 접근 방식과 비교합니다: Internet-Augmented QA, RECITE, ReAct, SelfAsk, 그리고 DecomP. 비록 이러한 비교는 직접적인 대결은 아니지만, 각 방법이 서로 다른 API, 지식 소스, 심지어 LLM을 사용하기 때문에(자세한 내용은 부록 C 참조), IRCoT가 최근 시스템들에 대해 게시된 최고 성능과 비교하여 어떻게 수행되는지를 리더보드 스타일로 탐구하는 것은 여전히 유의미합니다.
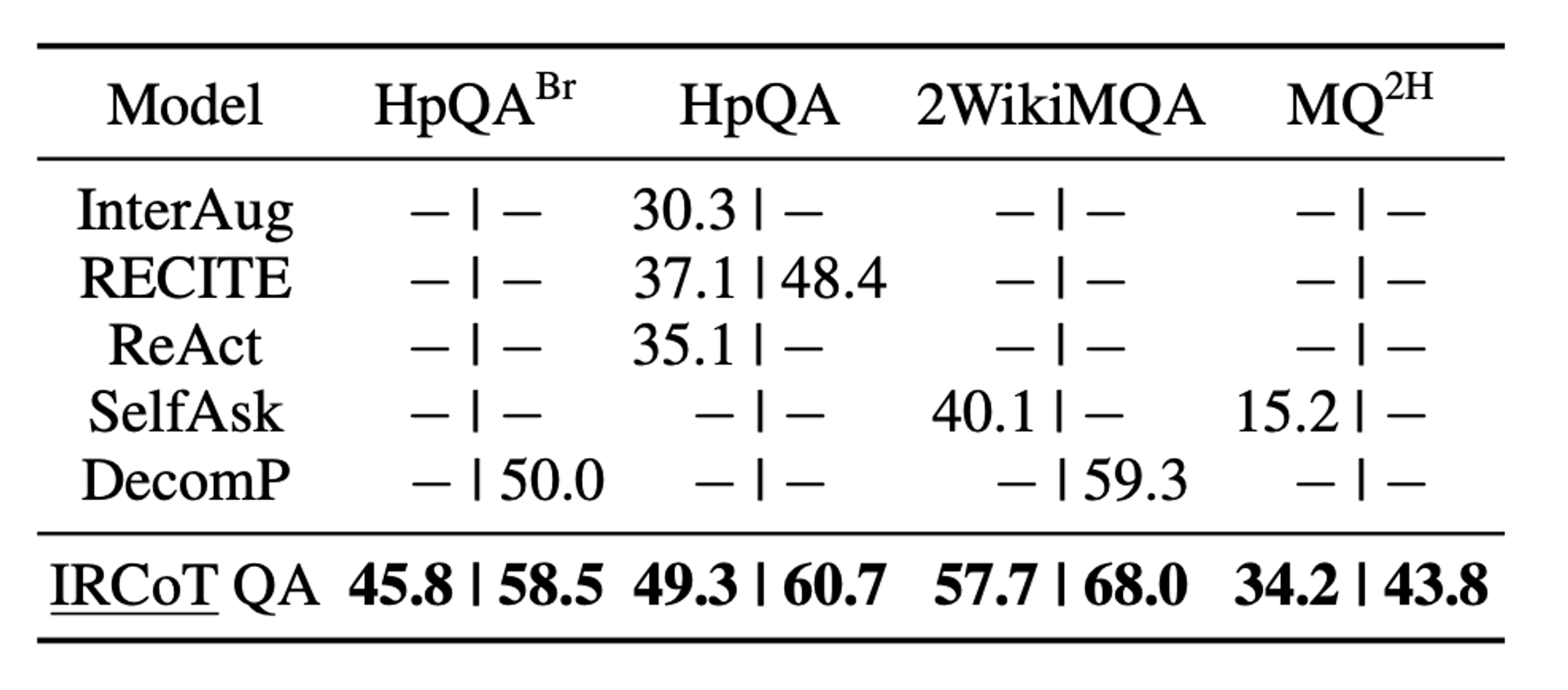
🔼 Table 01 : 다른 LLM 기반 ODQA 시스템과 EM 및 F1 점수 비교. ‘−’: 점수가 제공되지 않음. HpQABr: HotpotQA의 브리지 질문 하위집합. MQ2H: MuSiQue 2-hop 질문. GPT-3를 사용한 IRCoT QA(우리의 접근 방식)은 다른 시스템보다 큰 차이로 우수한 성능을 보입니다. 참고: 비교는 텍스트에서 논의된 바와 같이 직접적인 비교는 아닙니다. 부록 §C에서는 최신 SOTA(최첨단 기술) 성과를 포함하여 동시대 및 최신 연구 결과를 보고합니다.
Table 01 에서 보이는 것처럼, IRCoT QA는 최근의 모든 시스템을 큰 차이로 능가하여, 검색 강화 LLM(지도 학습 없이)을 통해 달성할 수 있는 새로운 최첨단 성과를 세웠습니다.
6. Conclusions
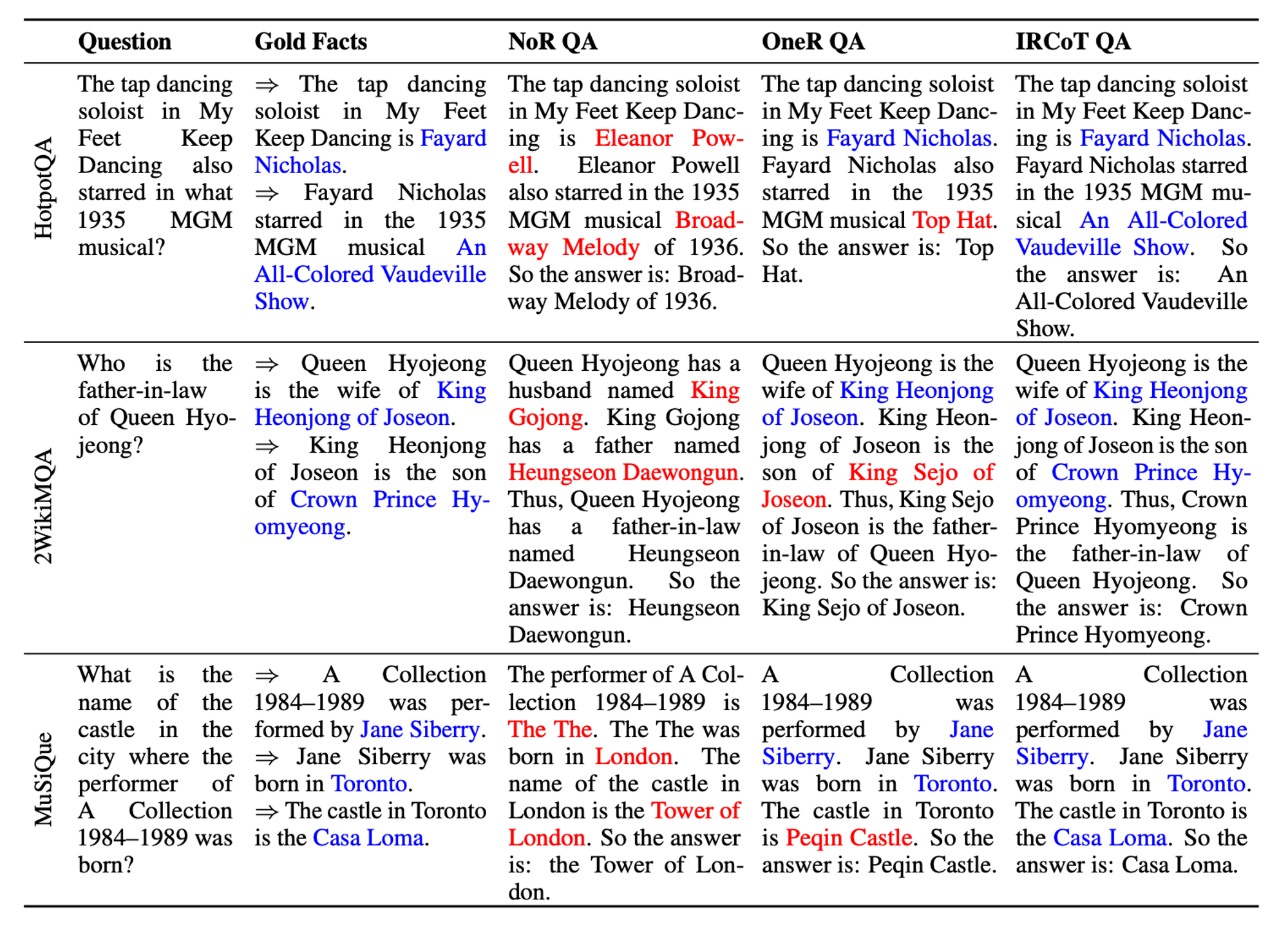
🔼 Table 02 : 다양한 방법으로 GPT-3이 생성한 CoT예시. NoR은 parametric knowledge에 의존하기 때문에, 첫 문장에서 사실적 오류를 자주 발생시켜 전체 CoT의 흐름이 잘못되게 합니다. OneR은 질문과 가장 관련 있는 정보를 검색할 수 있어 초기에 이러한 오류를 덜 발생시키지만, 여전히 CoT의 후반부에서는 오류를 발생시킵니다. 반면, IRCoT는 각 단계 후에 검색을 수행하기 때문에 각 단계에서 이러한 오류를 방지할 수 있는 경우가 많습니다. 더 많은 예시는 부록 D에 있습니다.
CoT 프롬프트는 LLM(대형 언어 모델)이 다중 단계 추론을 수행하는 능력을 크게 향상시켰습니다. 우리는 이 능력을 활용하여 검색 성능을 개선하고, 나아가 소수의 예제로 복잡하고 지식 집약적인 오픈 도메인 과제에서 QA 성능을 향상시켰습니다. 이러한 과제에는 단일 단계의 질문 기반 검색이 충분하지 않다고 주장하며, 상호 연동된 CoT 추론과 검색 단계를 사용하여 서로 단계별로 안내하는 IRCoT를 도입했습니다. 네 개의 데이터셋에서 IRCoT는 대형 및 상대적으로 소형 언어 모델 모두에서 단일 단계 검색과 비교하여 검색 및 QA 성능을 크게 개선합니다. 또한, IRCoT가 생성한 CoT는 사실적인 오류가 적습니다.
Limitations
IRCoT는 기본 언어 모델이 Zero-shot / Few-shot으로 CoT를 생성할 수 있는 능력에 의존합니다. 이러한 능력은 대형 언어 모델(100억 개 이상의 파라미터)에서는 흔히 제공되지만, 소형 언어 모델(200억 개 이하의 파라미터)에서는 흔치 않아서 IRCoT의 채택 가능성을 어느 정도 제한합니다. 그러나 최근의 관심도가 급증하는 것을 고려할 때, 소형 언어 모델들도 점차 이러한 능력을 습득하게 될 가능성이 높아지며, 이는 IRCoT가 더 많은 언어 모델들과 호환될 수 있게 만들 것입니다. IRCoT는 기본 언어 모델이 긴 입력을 지원하는 것에도 의존합니다. 이는 여러 개의 검색된 단락뿐만 아니라 질의응답(QA) 또는 CoT의 예시 몇 개가 함께 모델의 입력에 포함되어야 하기 때문입니다. 이는 우리가 사용한 모델들로 뒷받침되었습니다. code-davinci-002 (GPT-3)는 8K 토큰을 허용하고, Flan-T5-*는 상대적인 위치 임베딩을 사용하여 GPU 메모리 제약이 허용하는 한 확장 가능하도록 되어 있습니다. 미래의 연구에서는 언어 모델이 긴 입력을 지원할 필요성을 줄이기 위해, 검색된 모든 단락을 언어 모델에 전달하는 대신 이를 재정렬하고 선택하는 전략을 탐구할 수 있습니다. IRCoT 검색기와 QA의 성능 향상(OneR 및 ZeroR 기준을 초과하는)은 추가적인 계산 비용을 수반합니다. 이는 IRCoT가 CoT의 각 문장마다 별도로 (L)LM에 호출을 하기 때문입니다. 향후 연구는 예를 들어, 언제 더 많은 정보를 검색해야 하는지, 그리고 언제 현재 정보를 가지고 추가적인 추론을 수행해야 하는지를 동적으로 결정하는 것에 초점을 맞출 수 있습니다.
마지막으로, 우리의 실험 중 일부는 OpenAI의 상업용 LLM API(code-davinci-002)를 사용하여 수행되었습니다. 이 모델은 우리가 논문을 제출한 후 OpenAI에 의해 폐기되어, 이러한 API를 사용하는 다른 작업들과 마찬가지로 우리의 최선의 노력에도 불구하고 이 실험을 재현하는 것이 어려워졌습니다. 논문에서 논의된 경향들(IRCoT > OneR > NoR)은 여전히 유효할 것이라고 믿습니다. 또한, GPT-3와 유사한 경향을 보이는 Flan-T5-*를 사용한 모든 실험은 공개된 모델 가중치 덕분에 여전히 재현 가능할 것입니다.
Ethical Considerations
언어 모델은 종종 부정확하고 잠재적으로 편향된 정보를 생성하는 것으로 알려져 있습니다. 이는 특히 민감한 질문에 대해 문제를 일으킬 수 있습니다. 우리의 접근 방식과 같은 검색 강화 방법은 외부 텍스트에 기반을 둔 생성을 통해 이 문제를 어느 정도 완화할 것으로 기대되지만, 이는 편향되거나 공격적인 발언을 생성하는 문제를 해결하지 못합니다. 따라서 이러한 시스템을 사용자 대면 애플리케이션에 배포할 때는 적절한 주의가 필요합니다. 본 연구에서 사용된 모든 데이터셋과 모델은 허용 가능한 라이선스와 함께 공개적으로 이용 가능합니다. HotpotQA는 CC BY-SA 4.0 라이선스15를 가지고 있고, 2WikiMultihopQA는 Apache-2.0 라이선스16를, MuSiQUe와 IIRC는 CC BY 4.0 라이선스17를 가지고 있습니다. Flan-T5-* 모델은 Apache-2.0 라이선스를 따릅니다.
부록에 해당하는 A ~ G는 내용이 너무 길어져 스킵하니 직접 찾아보셔라 😊
