
Caching
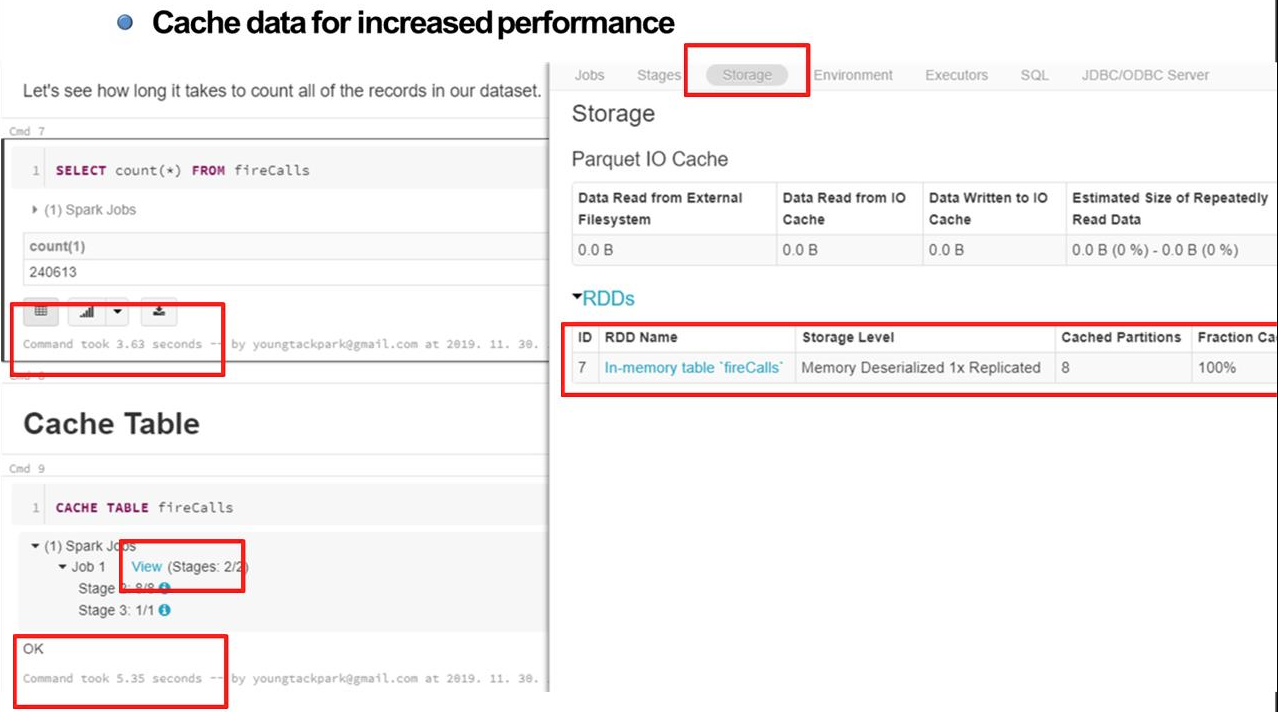
- cache없이 명령을 수행했을 때 3.63초가 소요되는 것을 확인할 수 있다.
- CACHE 키워드를 이용하면 테이블을 메모리에 cache할 수 있게 된다.
- 우측 자료를 보면 RDD 메모리에 8개의 파티션, 모든 조각들이 cache된 것을 확인할 수 있다.
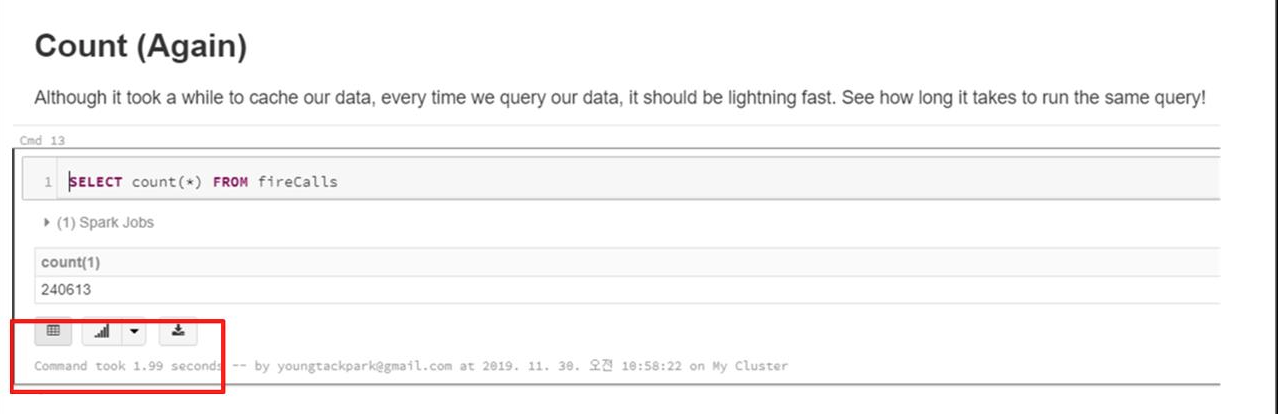
- Cache 이후 같은 명령어를 수행해보면, 수행시간이 줄어든 것을 확인할 수 있다.
Lazy Cache
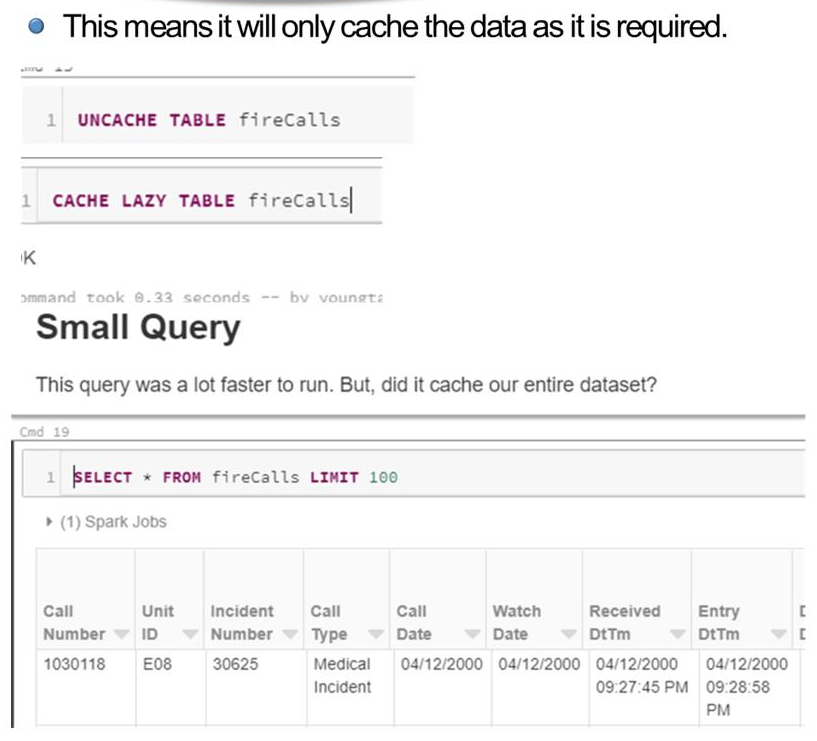
- Lazy Cache 란. 필요한 만큼만 cache를 하는 것이다.
- 이전에 cache된 테이블을 uncache 후 Lazy Cache를 명시한 후, 100개의 결과를 보여주는 Small Query를 수행한다.
- 이때, 수행하면서 사용한 데이터를 메모리에 Cache 한다.
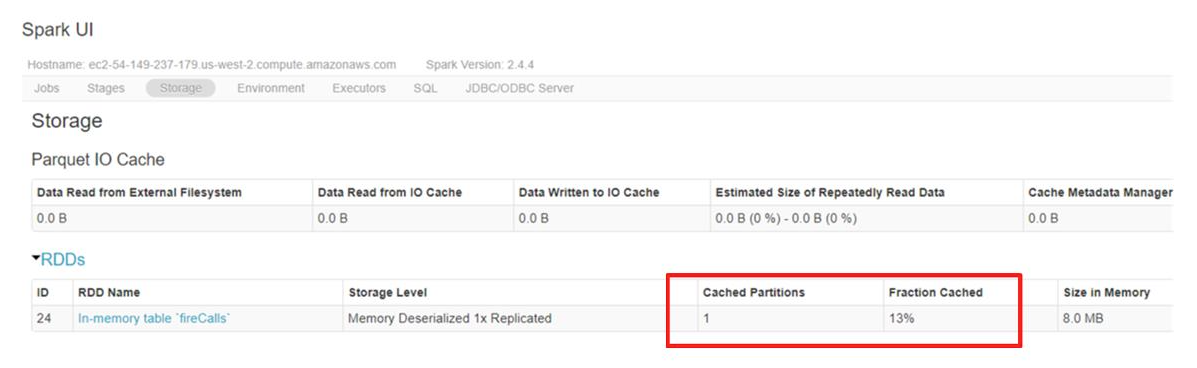
- 1개의 파티션, 13% 가 Cache 된 것을 확인할 수 있다.
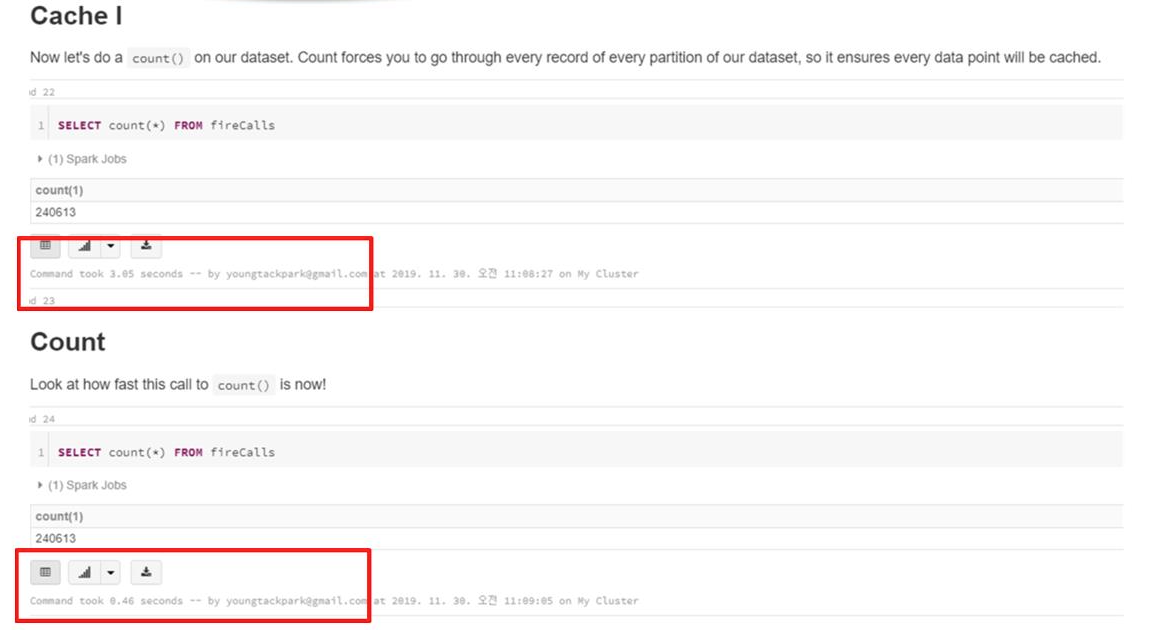
- 위 명령을 보면, 첫번째에는 3.05 초, 두번째에는 0.46 초의 수행 시간을 확인할 수 있다.
- 첫번째 명령어를 수행하면 사용한만큼의 데이터가 Cache가 되어, 반복되는 다음 같은 작업에서 빠른 속도를 보인 것을 확인할 수 있다.
Clear Cache
Clear Cache키워드로 메모리에 Cache 된 내용을 지울 수 있다.
Shuffle partitions
Spakr RDD를 배웠을 위 두가지 트랜스폼을 배웠음
- Narrow transformation : 나눠진 파티션 안에서 작업이 이루어짐. 속도가 빠름
e.g : select, where, etc. - Wide Transformation : 파티션이 셔플링되면서 작업이 이루어짐. 속도가 느려짐
e.g : group by, order by, Join, etc.
Shuffle Default Partition
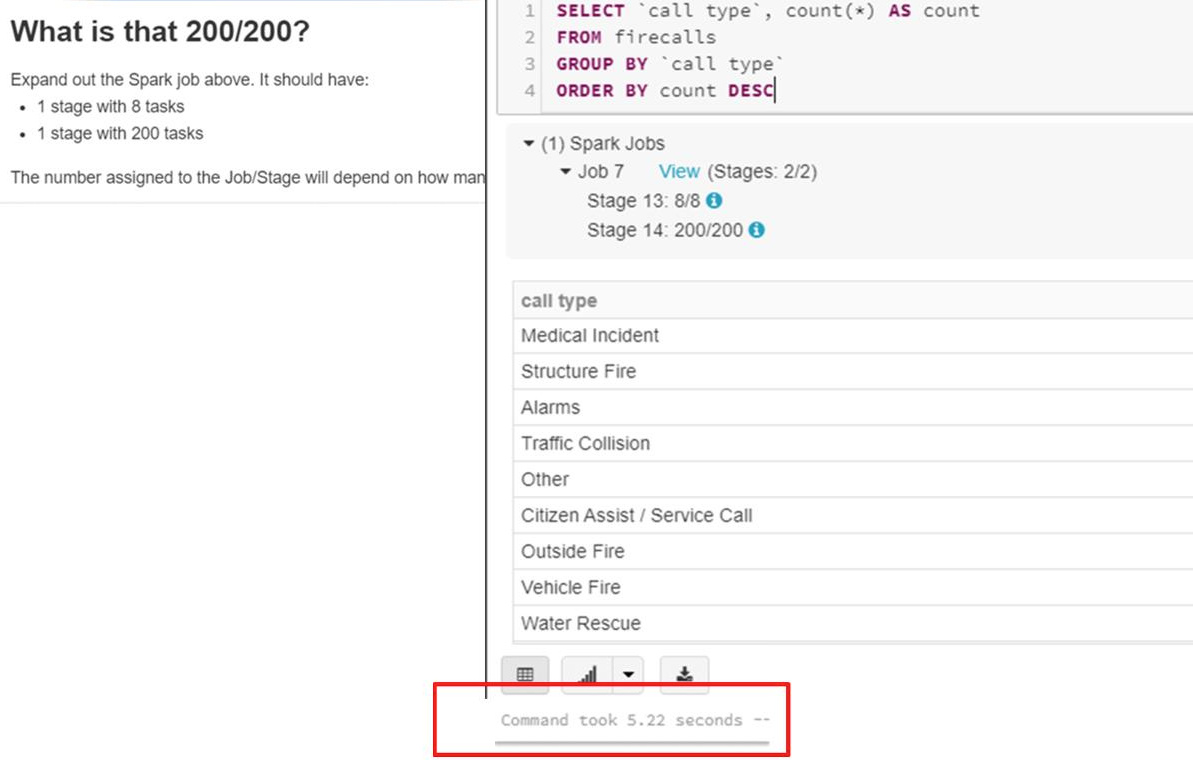
- GROUP BY, ORDER BY 은 실행되면서 Wide Transformation 을 수행해서 파티션들이 셔플링이 된다.
- 위 자료를 보면 시간은 5.22 정도 걸렸다.
- Job 을 보게되면 8개의 파티션에서 200개의 파티션이 사용된 것을 볼 수 있다.
: 파티션이 셔플링 될 때의 디폴트 값이 200이기 때문이다. - 데이터의 양이 많지 않다면, 디폴트 셔플링 파티션 수를 줄여서 성능을 개선할 수 있다.
SET spark.sql.shuffle.partitions=8 # Shuffling Partiton Control
명령어를 통해서 디폴트 값을 수정할 수 있다.
Speed up
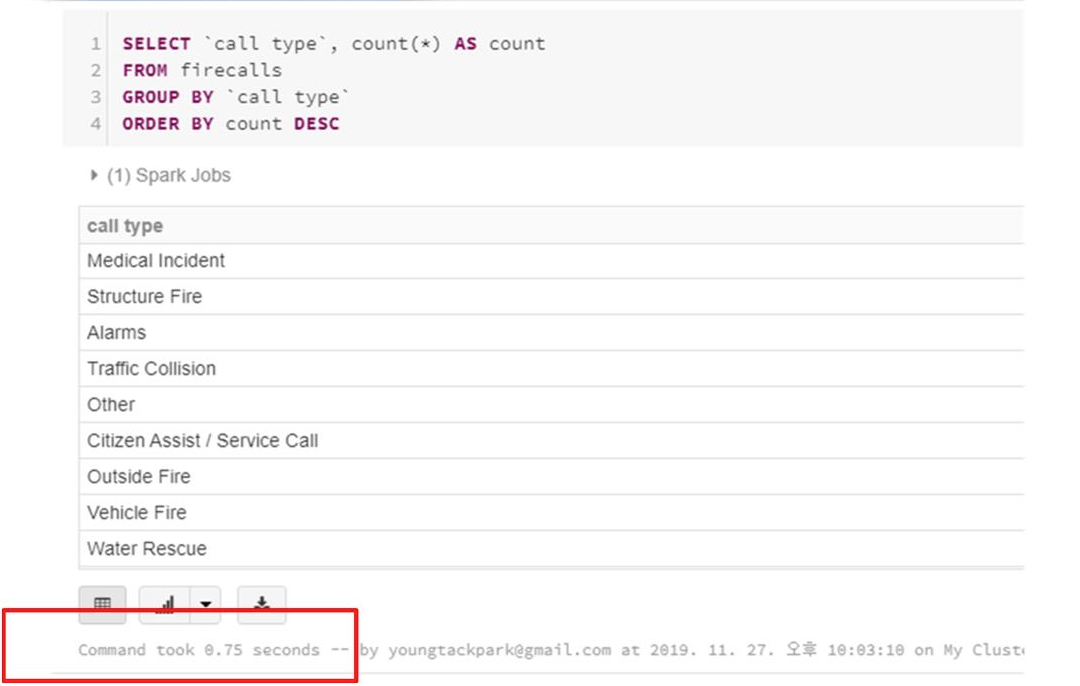
- 셔플링되는 파티션의 수를 수정하고나서 같은 명령어를 수행하면 수행시간이 줄어든 것을 확인할 수 있다. 이는 셔플링되는 수가 적어졌기 때문에 명령 수행 속도가 빨라진 것이다.
Speed up
- join 연산은 시간이 오래걸리는 대표적인 연산이다. 하지만 많이 활용되는 연산이라 성능을 높이기 위한 연구가 진행되었다.
broadcast join
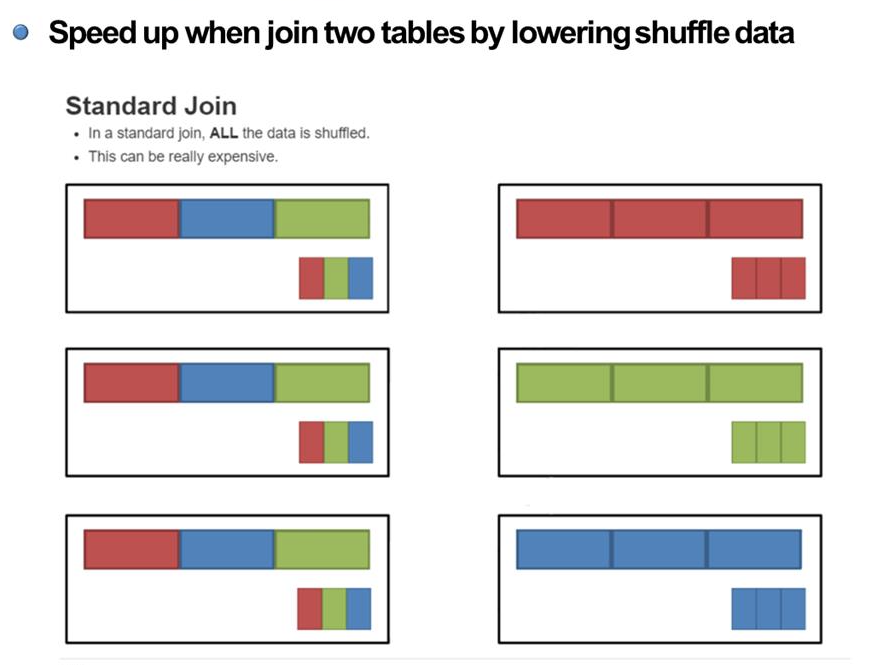
: 일반적인 join 연산은 좌측의 파티션들이 오른쪽 파티션과 같이 셔플링이 된 다음, 필드가 같은 것끼리 join을 하는 방식을 사용하고 있다.
-> 이는 셔플링이 많이 일어나다보니 시간이 오래 걸린다.
-> broadcast 제안.

: 작은데이터들만 셔플링을 통해 오른쪽과 같이 만들어진 후, 큰 데이터와 작은 데이터가 Join하는 방식
-> 작은 데이터들만 셔플링을 하고, 큰 데이터는 셔플링하지 않음으로써 셔플링에 드는 비용을 줄인다.
Experiment tables
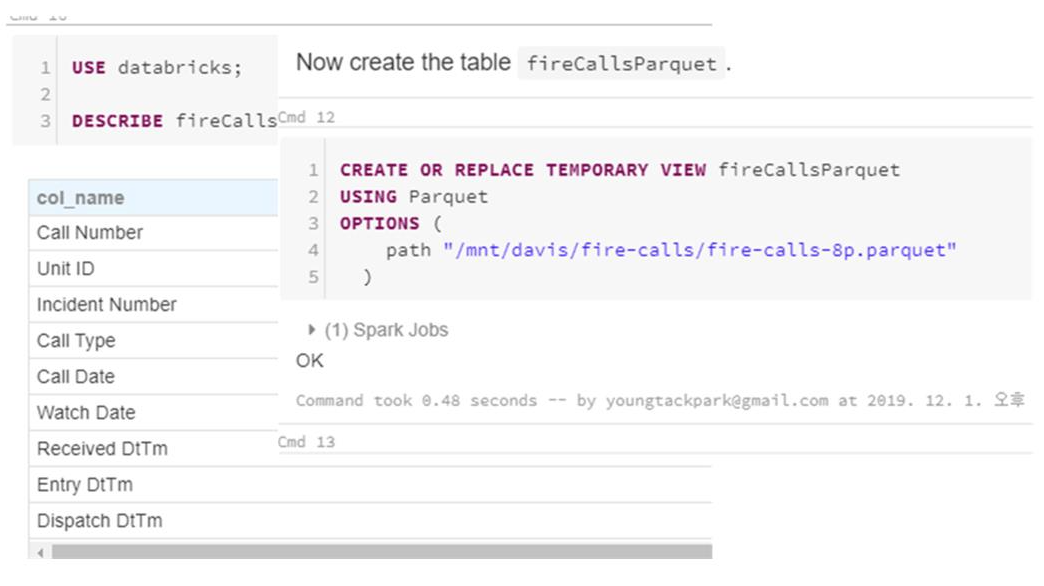
- 두개의 테이블을 (fireCalls, fireCallsParquet) 만든다.

- 테이블의 크기를 확인한다.
: fireCalls > fireCallsParquet 이므로, fireCallsParquet이 작은 데이터임을 확인할 수 있다.
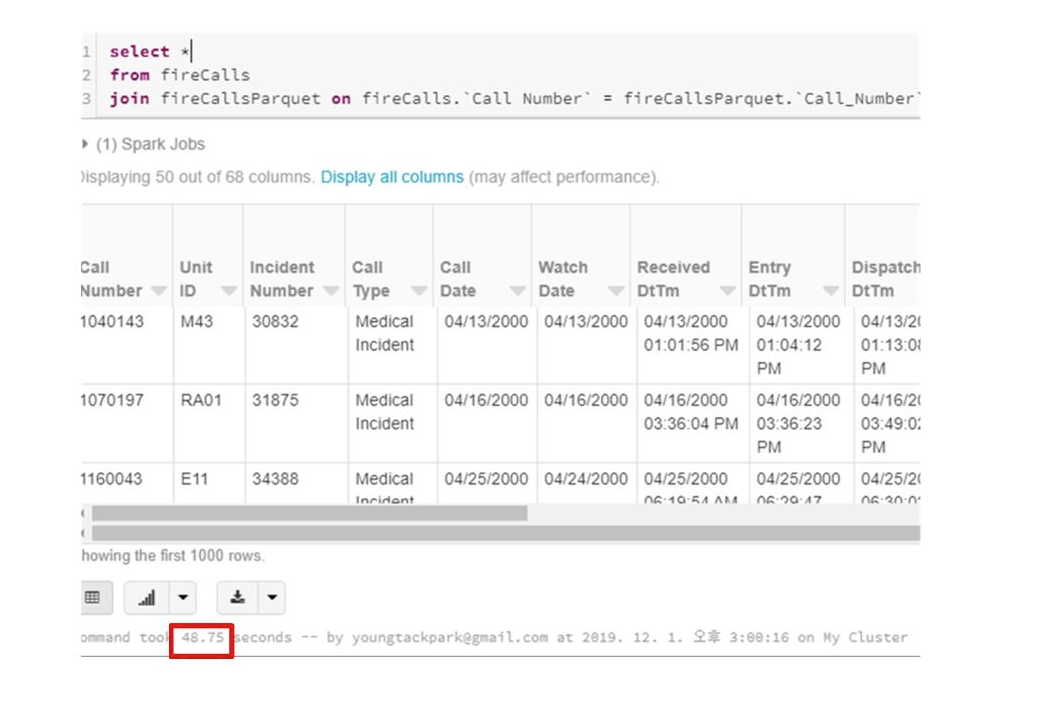
- 두 테이블에 일반적인 join 연산시 걸리는 시간을 확인한다.

- Broadcast join을 위한 준비
스파크 내부적으로는 10MB 까지는 BroadCast join에서 작은 테이블로 자동으로 지정함.
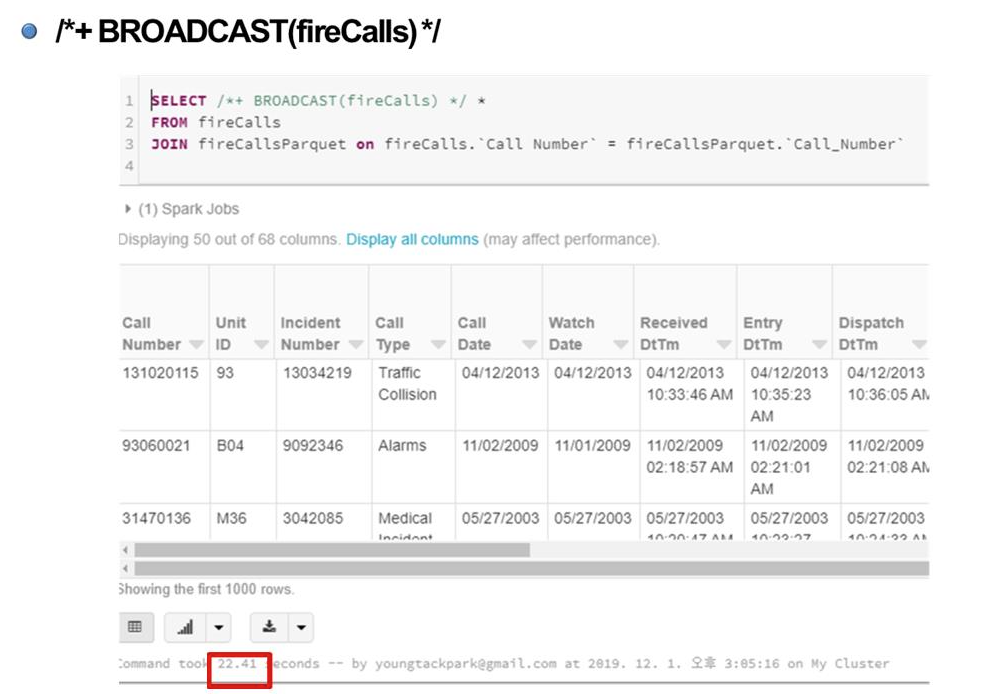
-
fireCalls을 브로드캐스팅해서 join을 하는 문법
: 어떤 것을 기준으로 join을 할 것인지 힌트(명시)를 준다.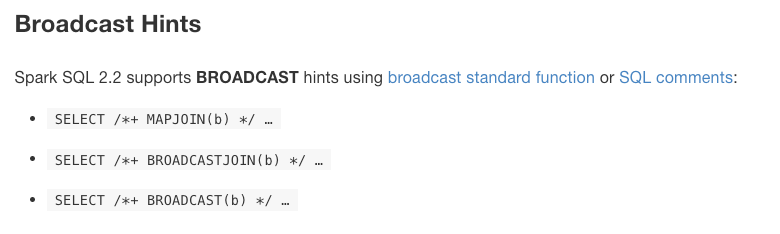
Explain

- SparkSQL 명령을 수행했을 때, 내부를 동작을 로그로 띄워 설명해주는 키워드
- 위 자료를 보면 상단 명령을 SortMergeJoin을 수행했다는 것을, 아래 자료를 보면 BroadcastHashJoin을 수행했다라는 것을 알 수 있다.

'당신을 한 줄로 소개해보세요'를 이 블로그로 대신 해볼까합니다.