Data Warehouse, Data Lake
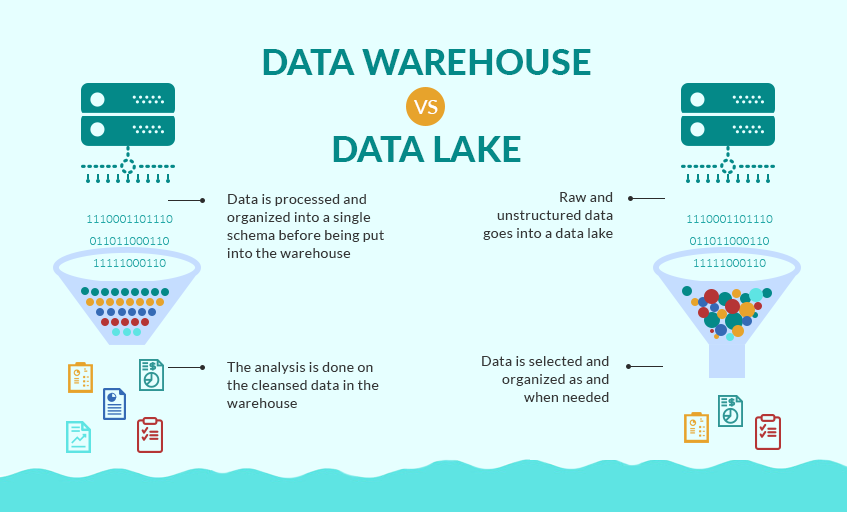
- 데이터를 저장하는 방식 크게 두가지 -> Data Warehouse , Data Lake
Data Warehouse

- 데이터에 대한 스키마를 만들고
- 스키마에 따라 쿼리를 보내 데이터를 얻는 방식
- 데이터를 스키마로 변환하는 과정이 중요함
- 시간이 많이 걸림
Data Lake
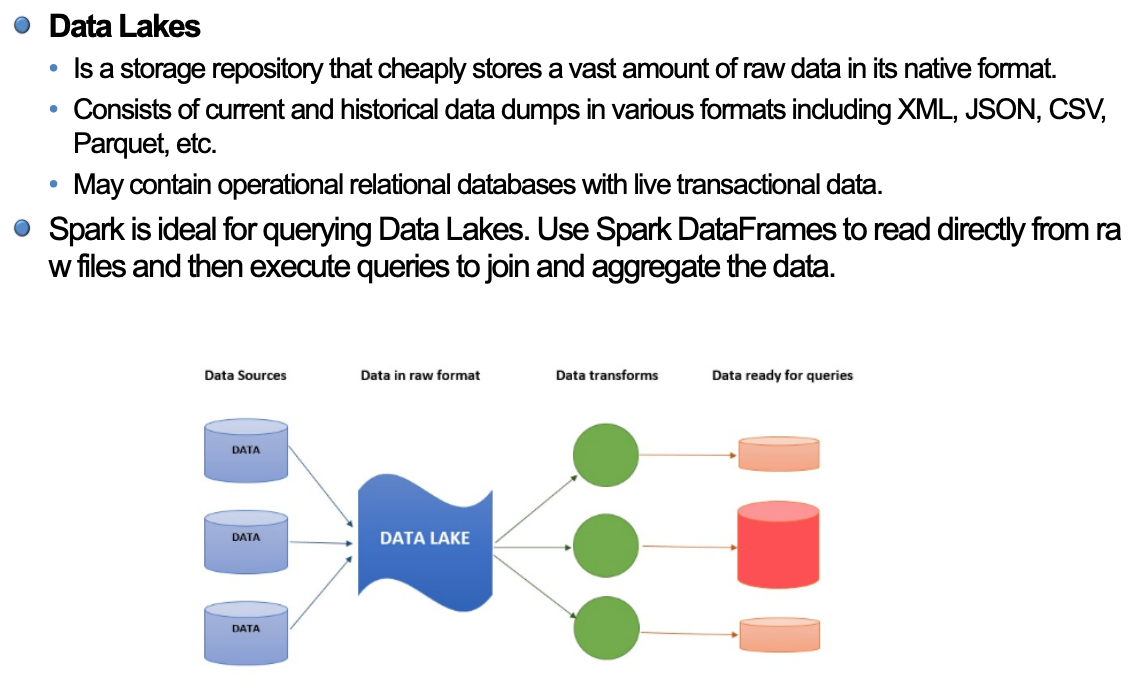
-
스토리지처럼 데이터를 있는 그대로 가지고 있음
-
데이터를 용도에 따라 변환을 해줌
-
Low format (xml, json, csv, parquet)으로 가지고 있음
-
select, filter, agg 등으로 편리하게 데이터를 처리할 수 있음
예제
Dataset

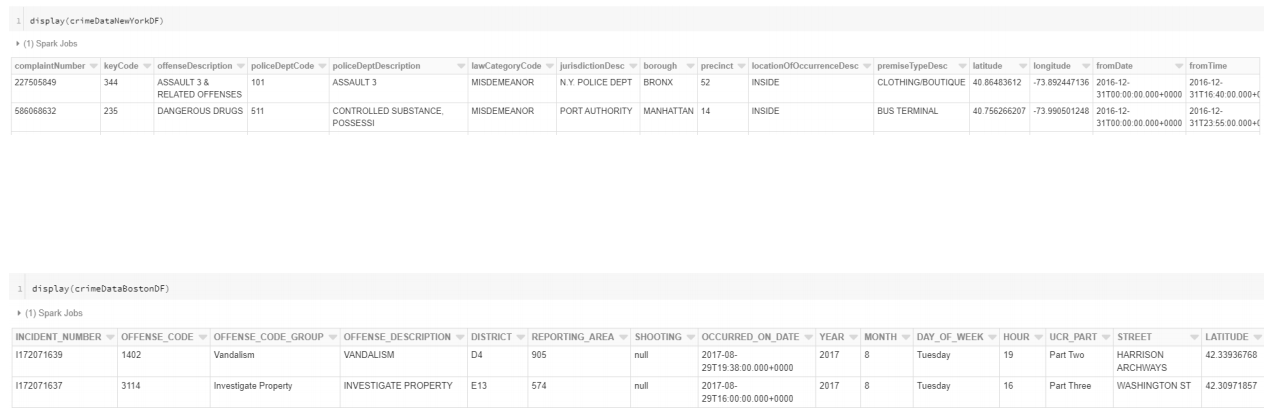
위와 같은 데이터가 있을 때
Data Lake for cirme data

- 두 데이터는 같은 정보를 가지고 있지만, 컬럼의 이름이 다르다.
- DataWarehouse로는 이를 용도에 맞게끔 스키마로 정의해서 구분해야 하지만,
- DataLake는 프로그램으로 필요한 데이터만 추출할 수 있다. -> normalize
Goal
세개(보스턴, 뉴욕, 시카고) 도시에서 발생하는 월별 homicide 통계
Normalization for month, count
- 두개의 데이터를통해 얻고자 하는 것들이 위와 같다고 할 때
Same type of data, different structure
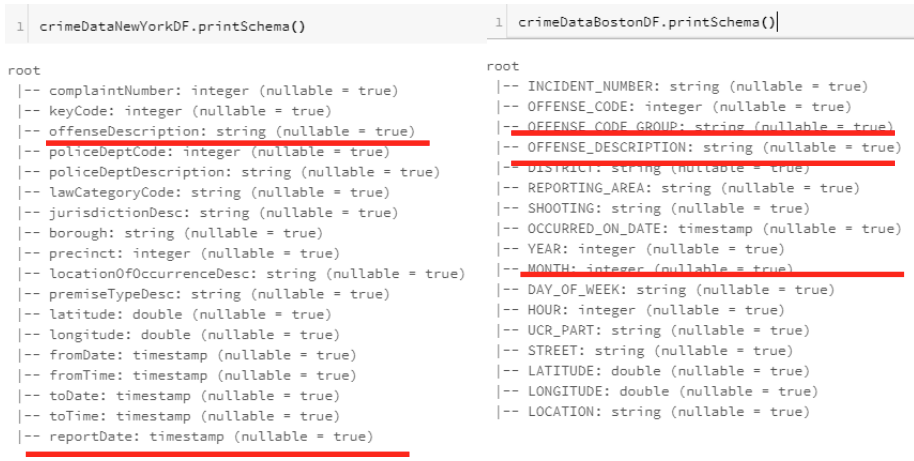
- 서로 다른 스트럭쳐를 가지고 있는 데이터를 어떻게 처리를 할 수 있을 것인가?
SomeData
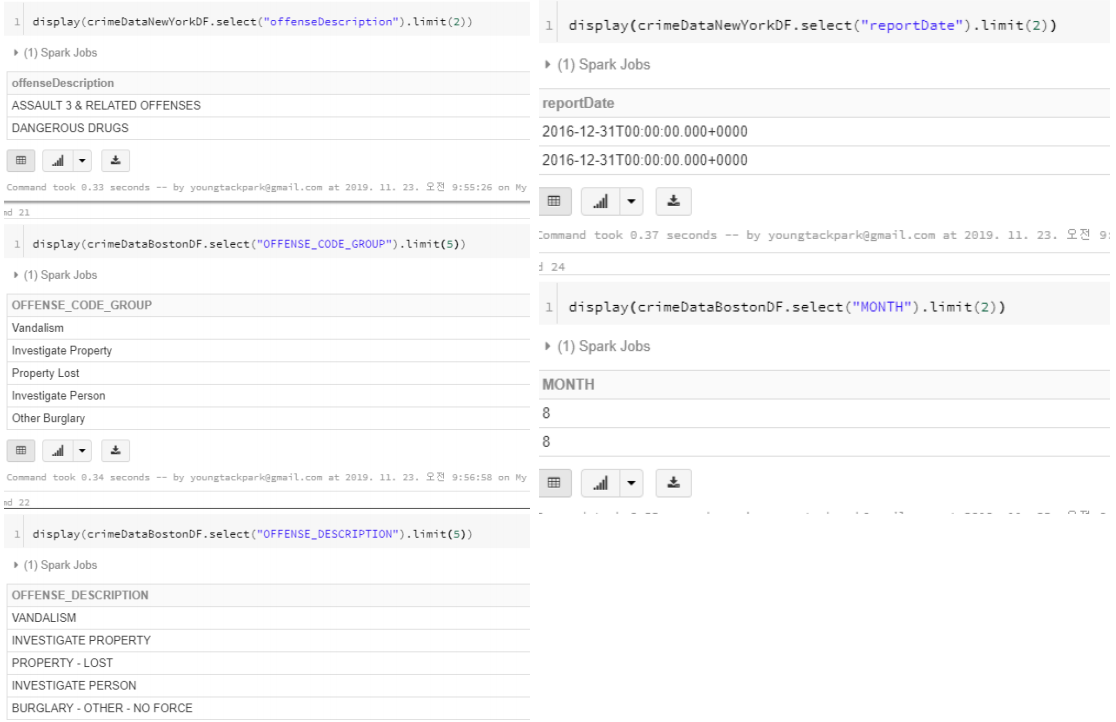
- 보스턴은 offenseDescription 으로 카멜케이스
- 뉴욕은 OFFENSE_CODE_GROUP 으로 다 대문자의 필드
와 같이 다른 구조를 가지고 있음
Normalize
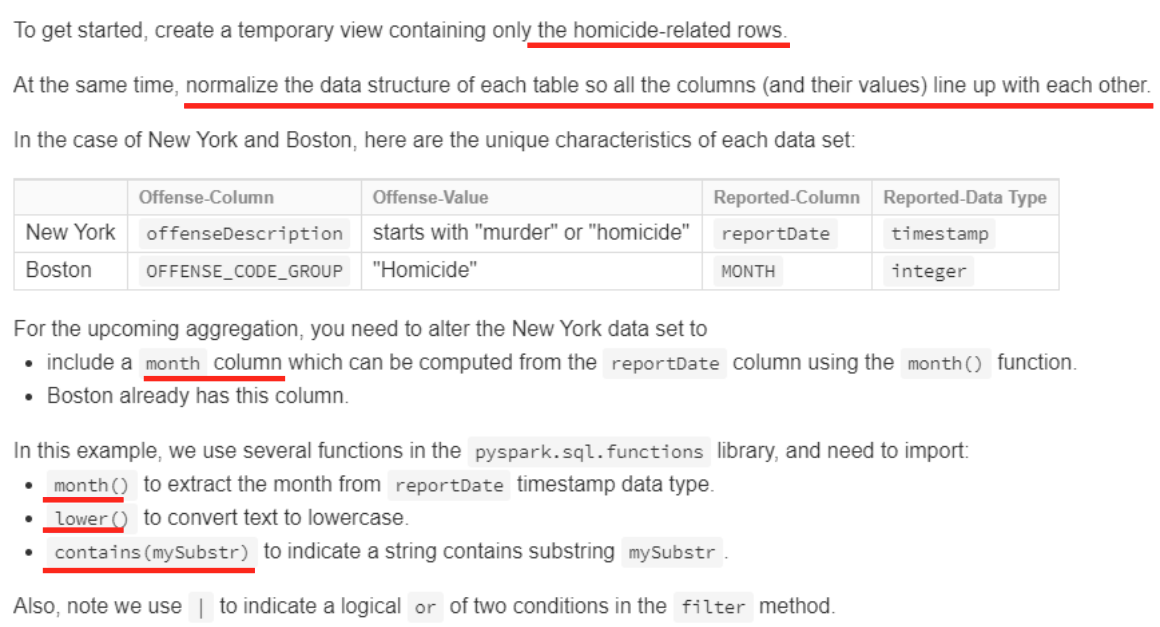
- 위와 같은 절차를 거쳐 normalize를 수행한다.
crimeDataNewyorkDF normalization
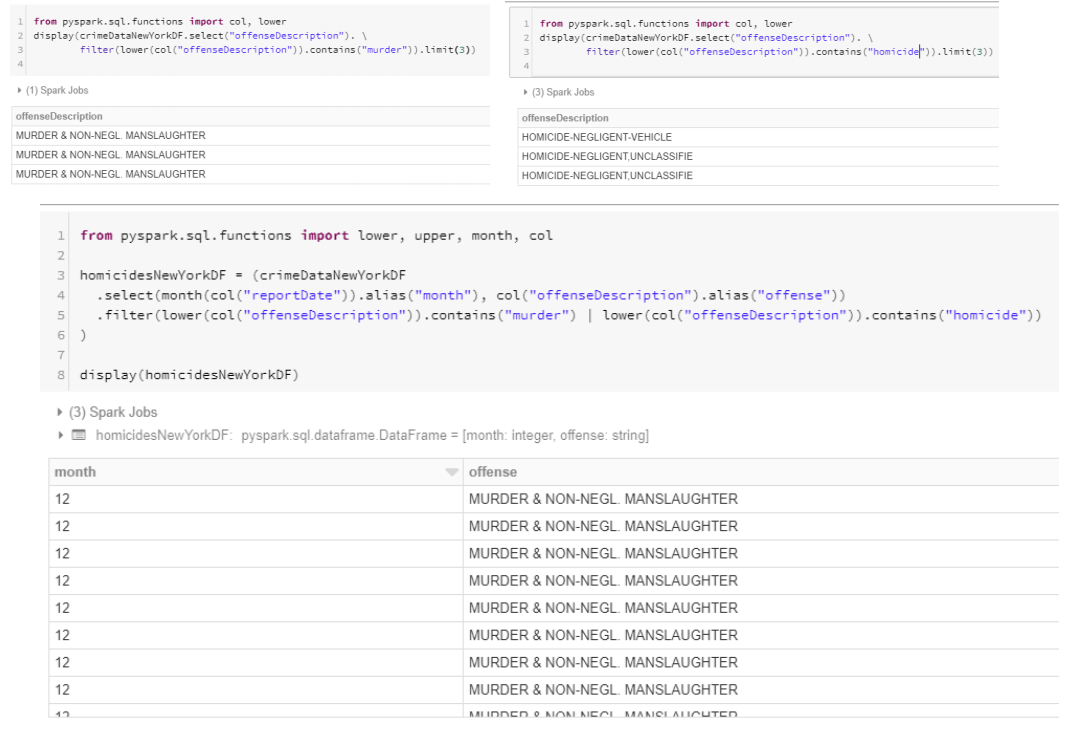
crimeDataBostonDF normalization
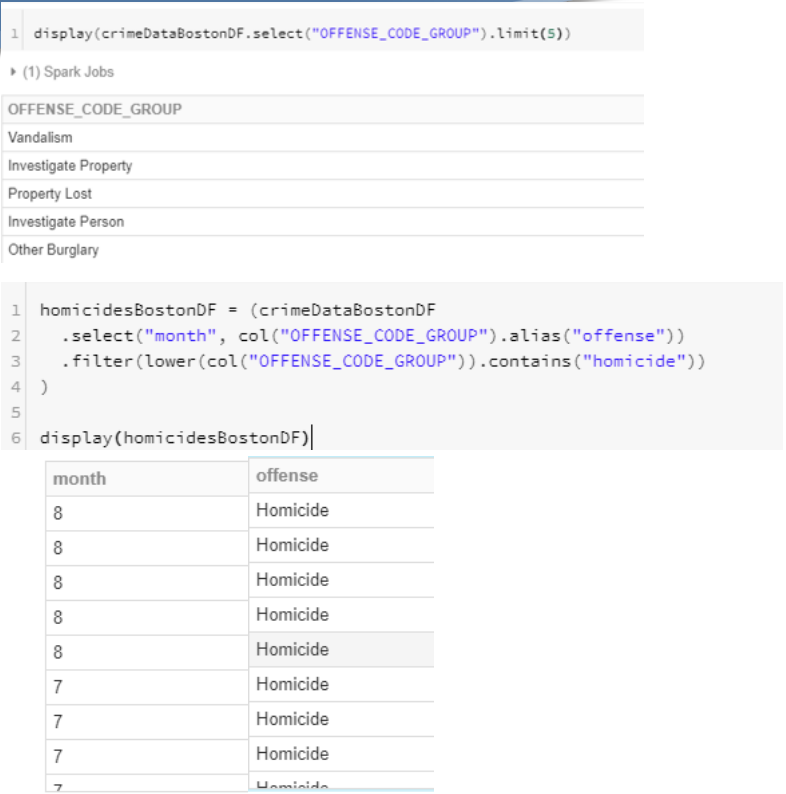
- 최종적으로 월별로 범죄분류를 통해 통계를 낼 수 있게 준비한다.
Normalized Result
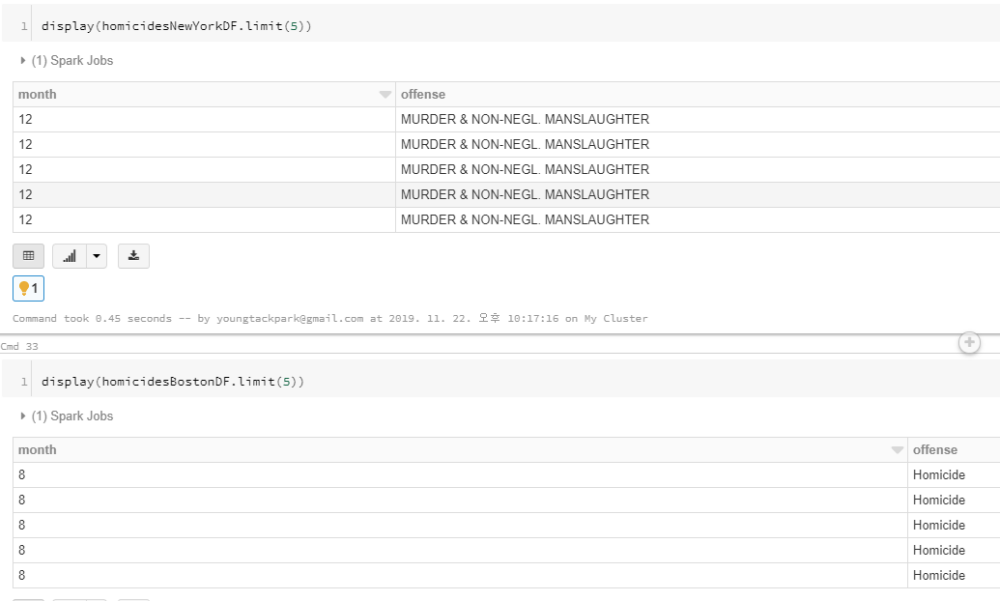
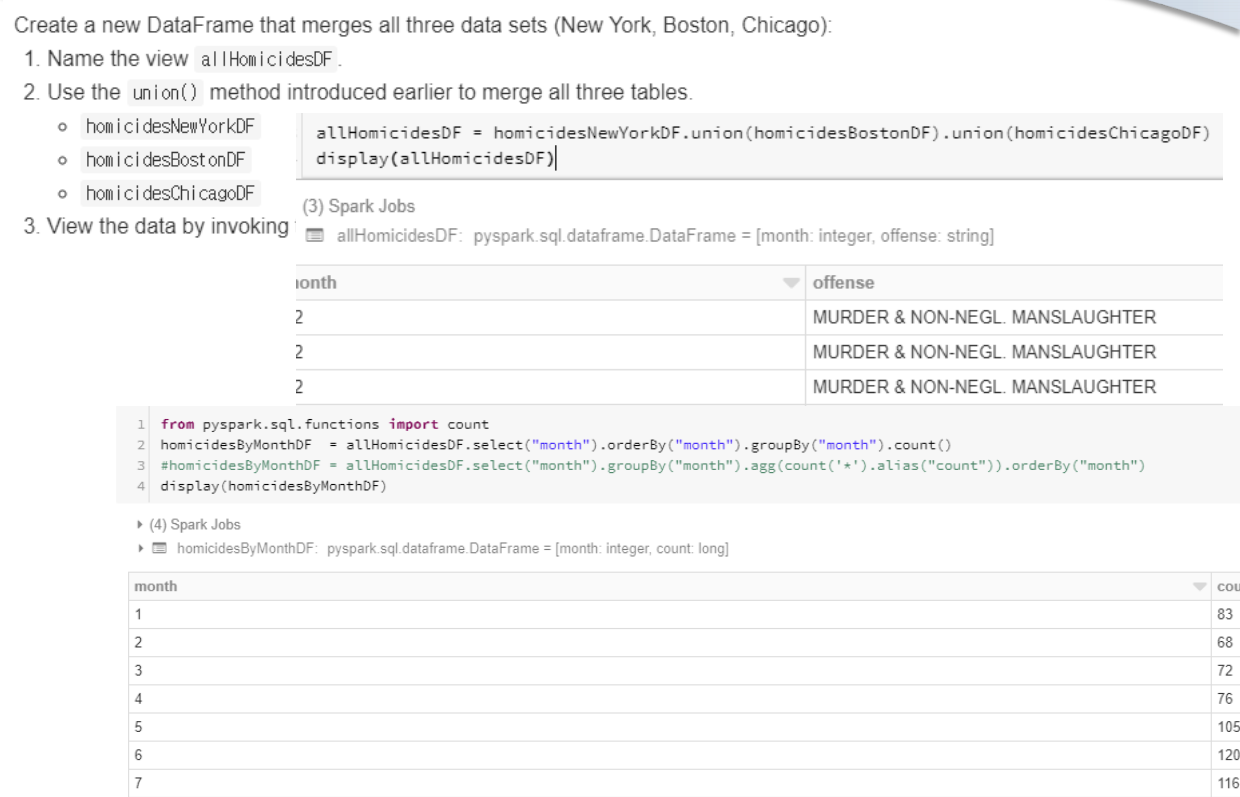
- 두 데이터를 Union 후 GroupBy, Count를 거치면 목표한 월별 범죄율을 구할 수 있다.
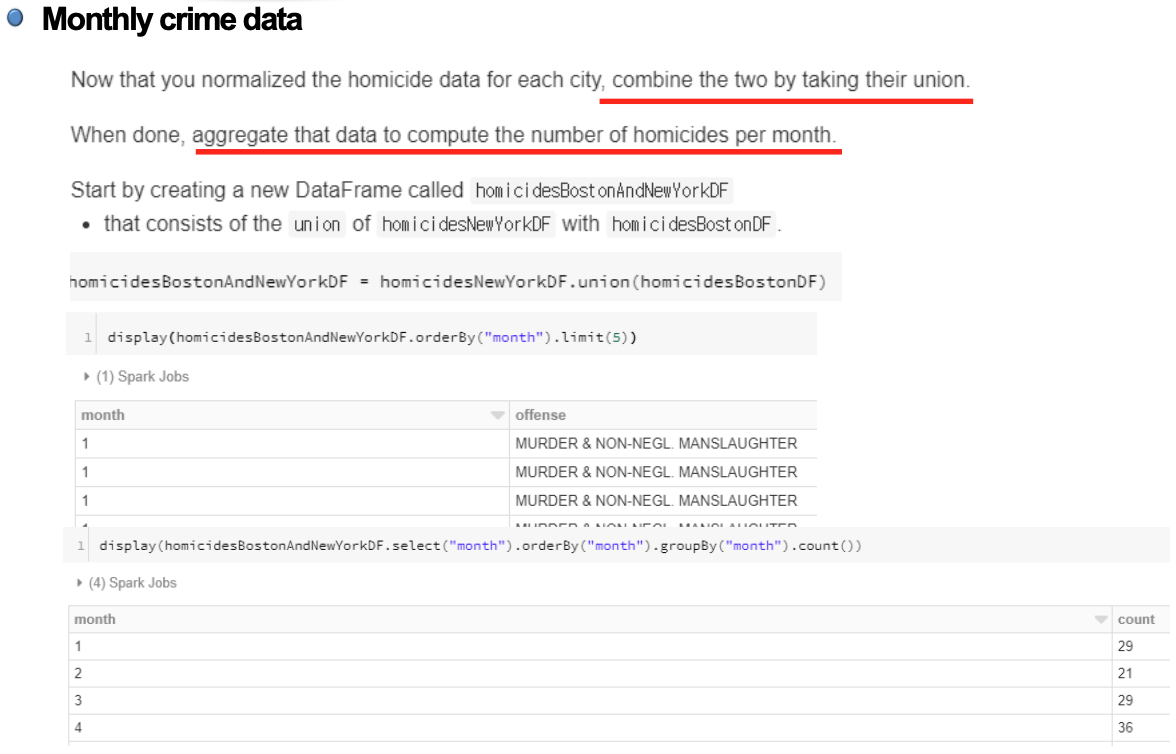
Chicago data normalization
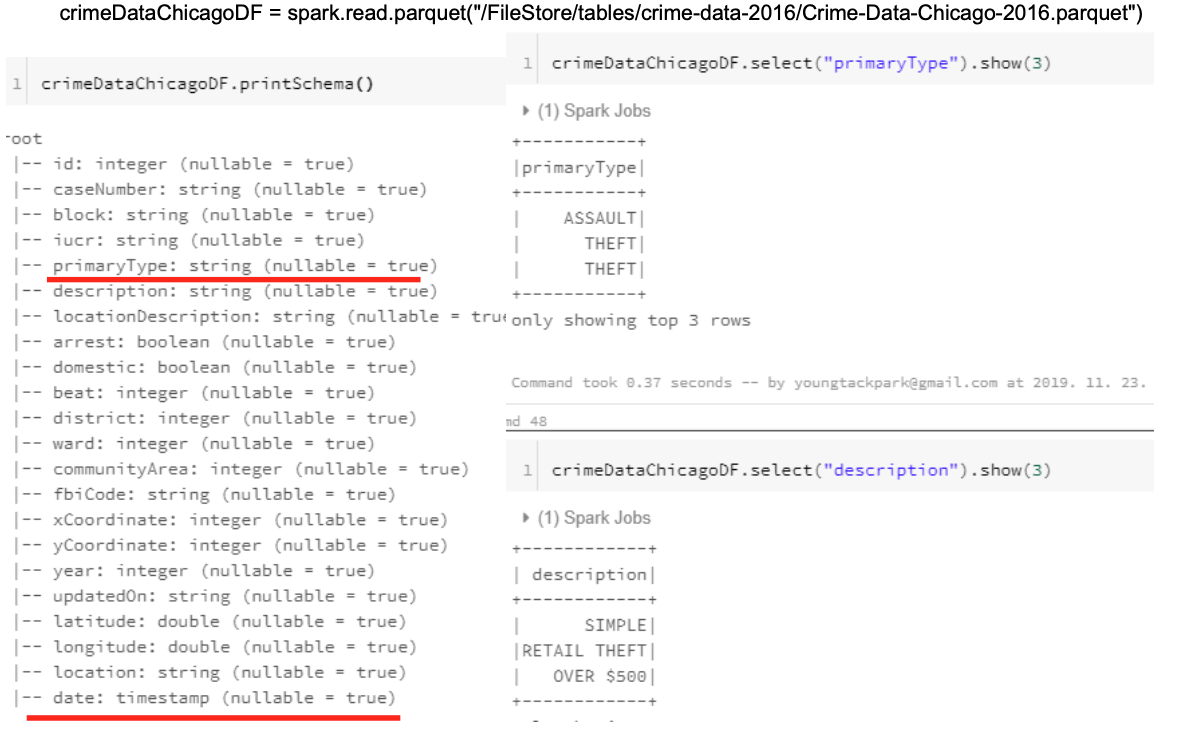
- 시카고 또한 비슷한 정보를 다른 형식으로 가지고 있음.
Chicago data normalization
- homicidesChicagoDF를 만든다.
- month, offense 컬럼을 찾는다.
- filter 로 homicide 를 추출한다.
- show()로 시각화한다.
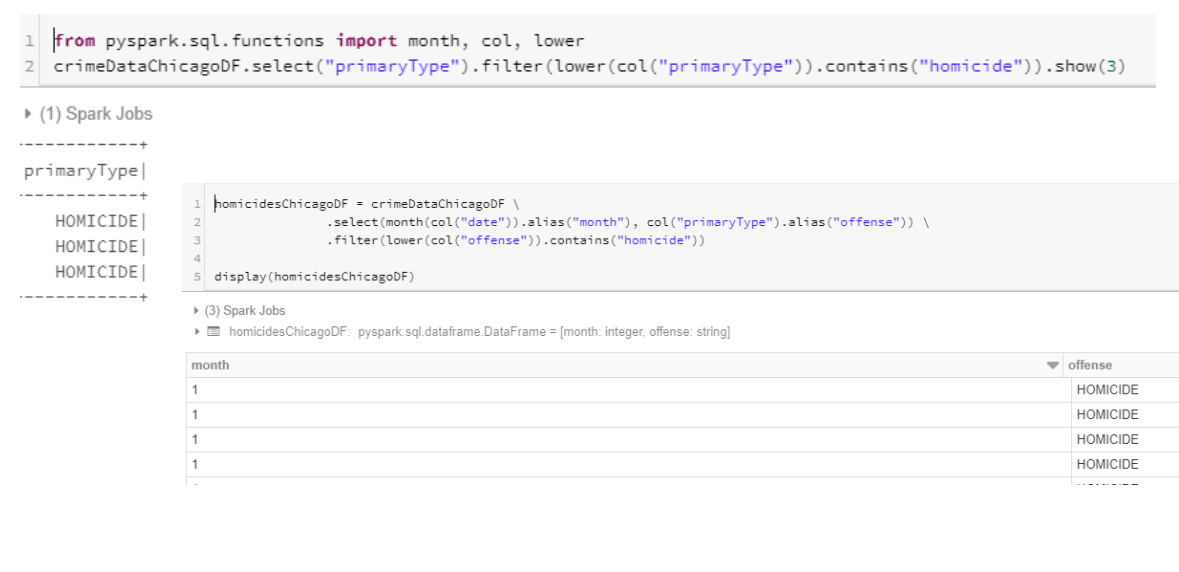
Fianl union
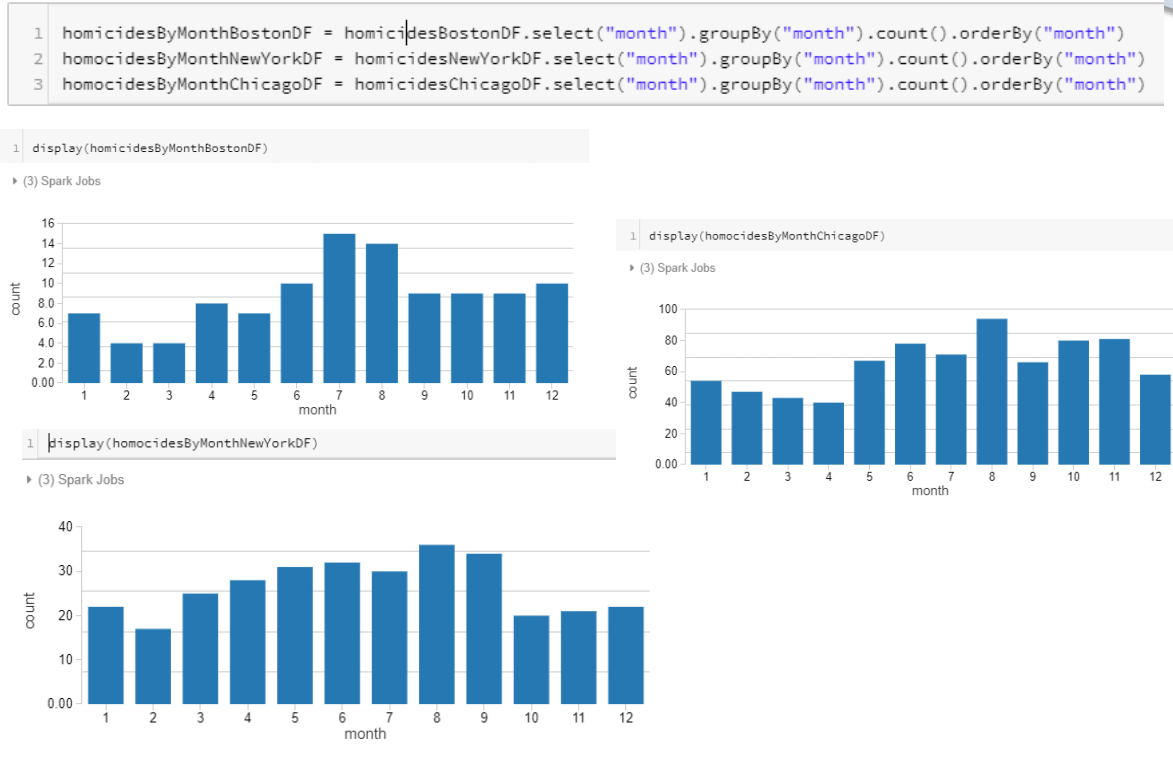
세 도시의 결과값들을 확인하면
Visualization
Add city name
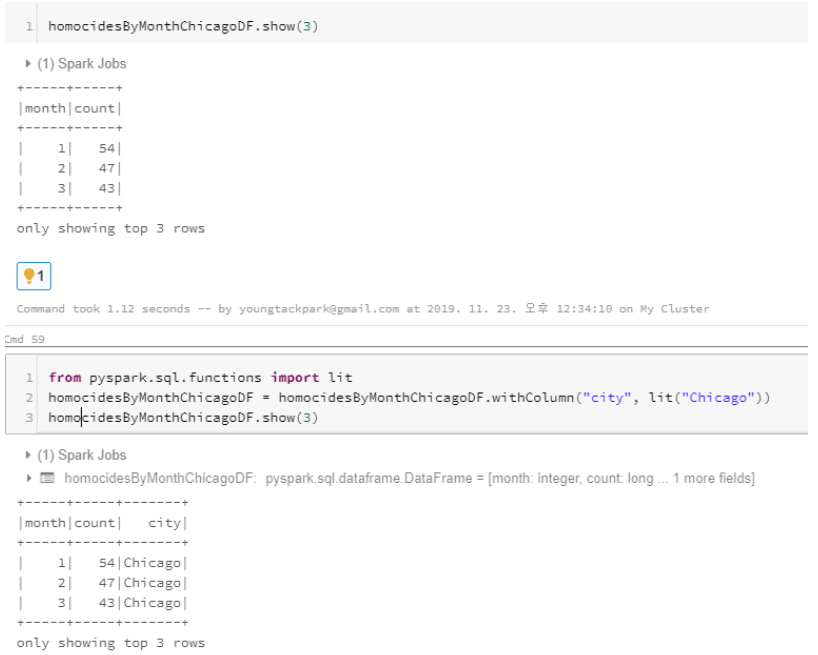
- 각 도시별로 데이터를 확인하려면 cityname 컬럼을 생성하면 된다.
visualization
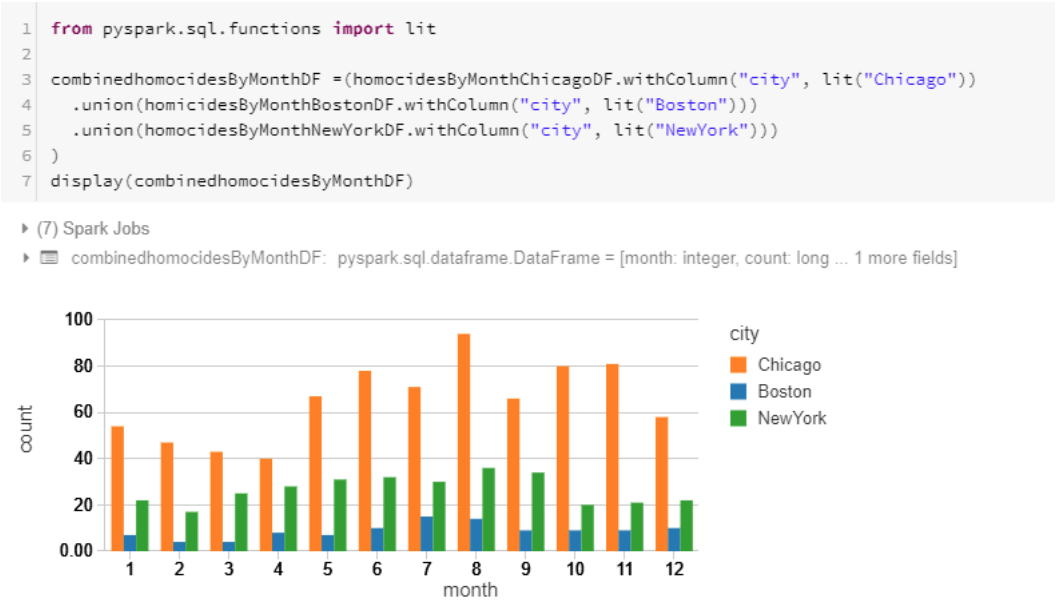
DataLake를 사용하면 어떤 종류의 데이터라도 어플리케이션의 쓰임에 맞게 사용할 수 있다는 장점이 있다.
Crime rate
각 도시의 인구별로 나눠서 비율을 구할 수 있음.
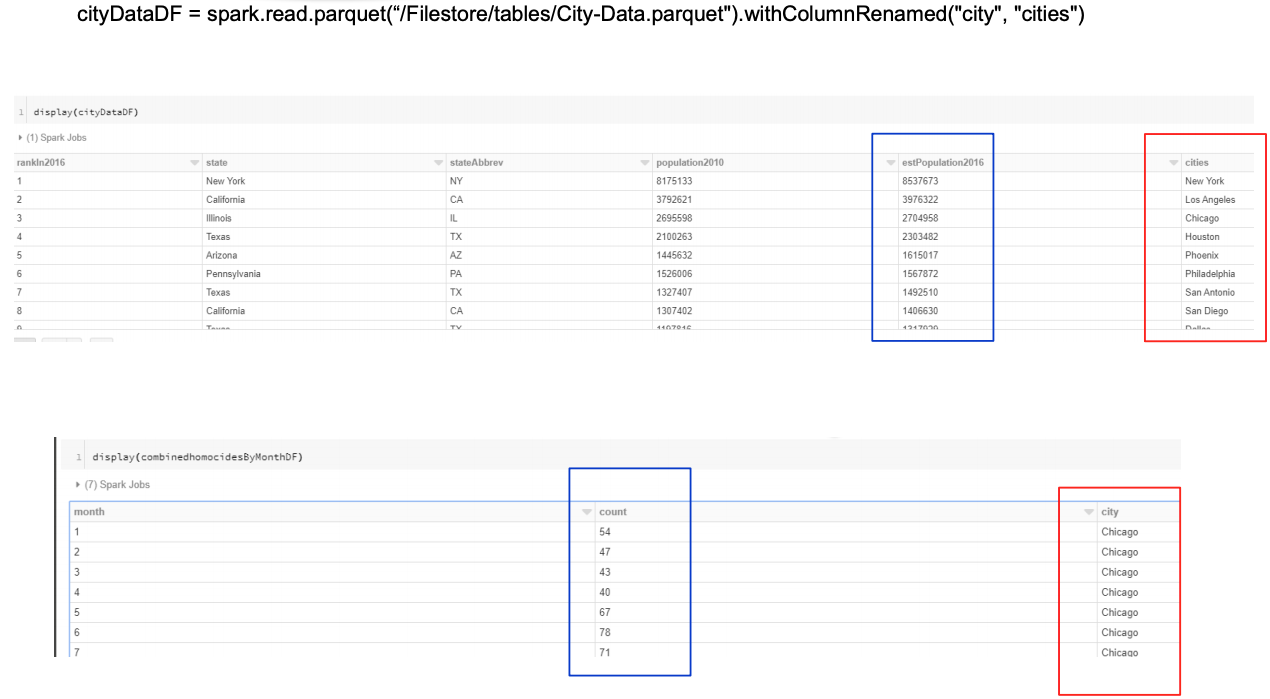
Visualization
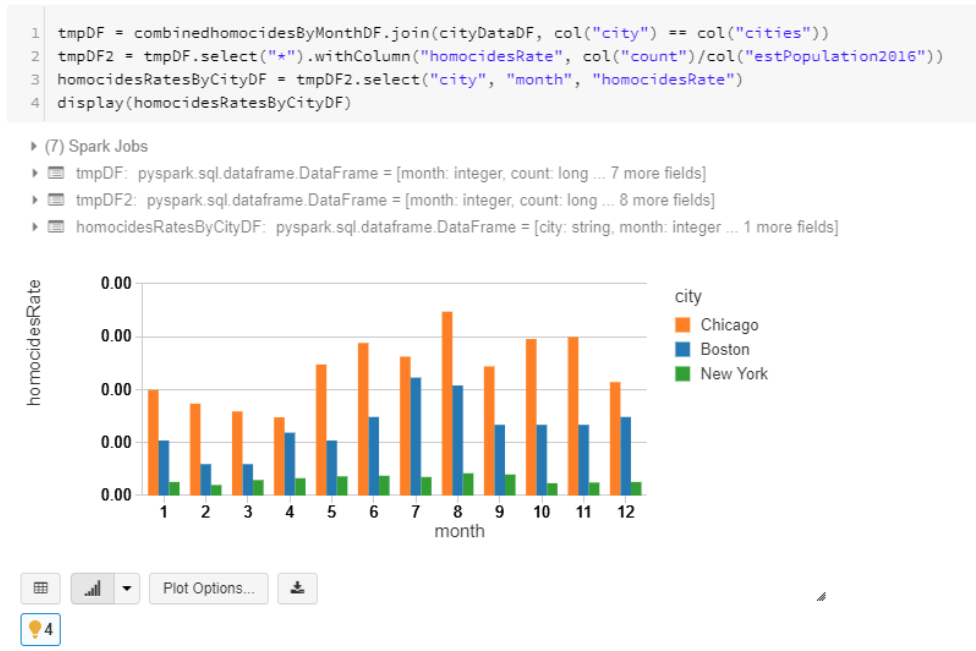
- 두 데이터를 city==cities 로 join
- 인구비율 데이터를 추출
- visualize할 데이터 select

'당신을 한 줄로 소개해보세요'를 이 블로그로 대신 해볼까합니다.