
Transformation

- Transformation 오퍼레이션을 통해 기존의 RDD에서 새로운 RDD를 만든다.
- 기존의 RDD에서의 디펜던시가 생기게 된다.
- spark 시스템에서는 디펜던시를 저장하고 있다가, fault 시 fault tolerance를 수행한다.
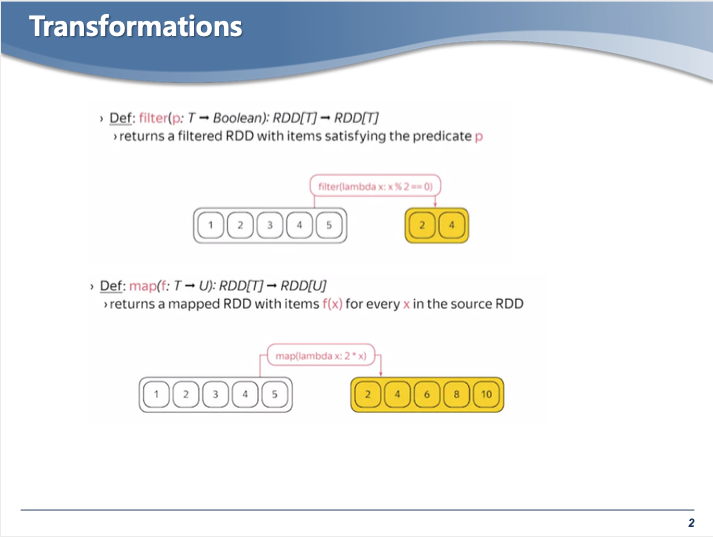
- 기존 RDD에 transformation action ( filter, map... )을 이용해서 새로운 RDD 를 만들게 되고, 기존 RDD와의 디펜던시가 생기게 된다.

- 조건에 True를 만족하는 것만 남겨 RDD를 생성하는 명령어
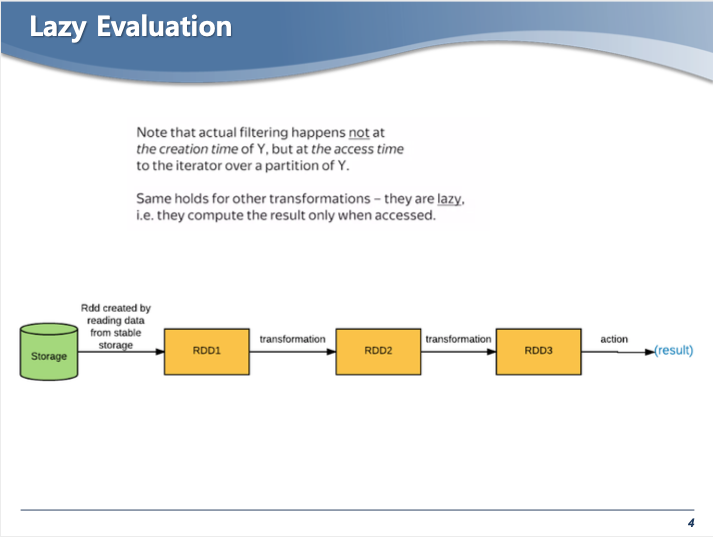
- Transformation은 Lazy Evaluation 특징을 가지고 있다.
- 스토리지에서 생성된 RDD에 여러가지 Trans. 명령어를 실행하면 새로운 RDD가 생긴다.
- 이때, 변경된 사항이 바로 storage에 Evaluation 저장되지 않는다.
- 디펜던시에 관한 정보(디펜던시 그래프)만 가지고 있다가
- Action (collect...) 명령어가 실행되면 이때 Evaluation 되어 결과를 보여준다.
- 그 이유는 실제로 필요한 데이터만 처리하기 위함
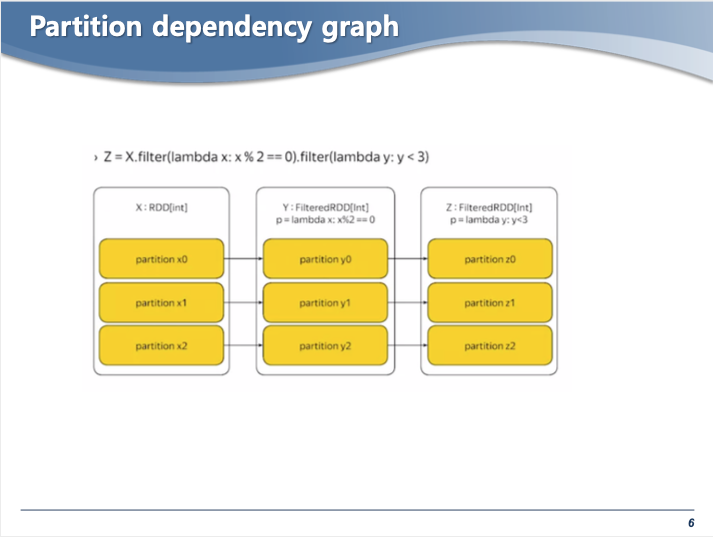
- 파티션 설정을 3으로 하였을 때, 위와같이 다른 노드(PC)에 분산이 되어 데이터가 처리 된다.
- filter 오퍼레이션을 취하면, 같은 노드에 저장이 된다.
- 데이터 셔플링을 줄이기 위함.
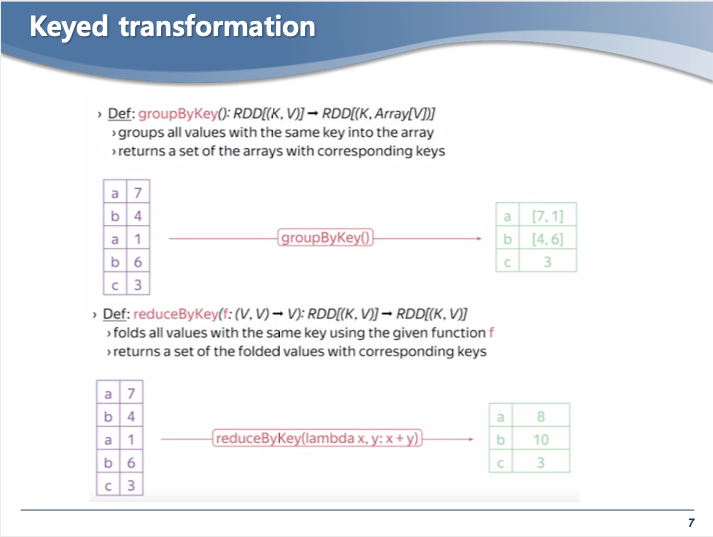
- Key 오퍼레이션들 (groupByKey, reduceByKey)은 파티션이 유지되지 않는다.
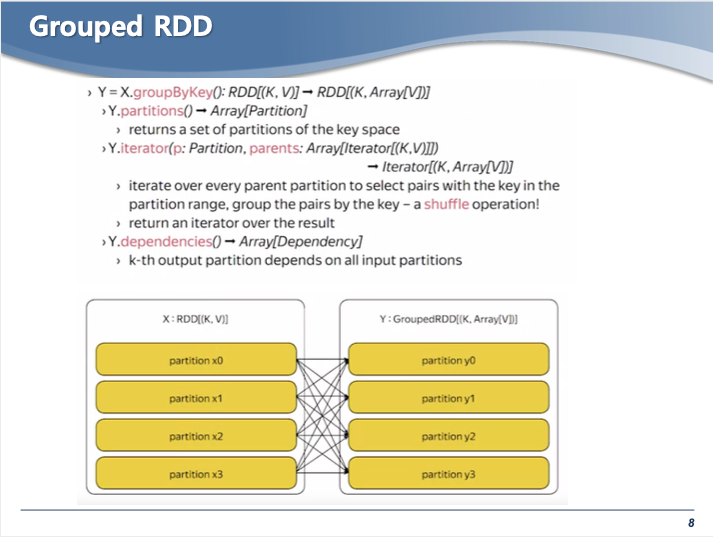
- 셔플링이 일어나서 여러개의 파티션으로 나누어지게 된다.
- 시간이 더 걸리게 된다.

- 그룹핑을 먼저한 후 조인 연산을 수행

- 미리 그룹핑을 하지 않고, 조인 연산을 수행
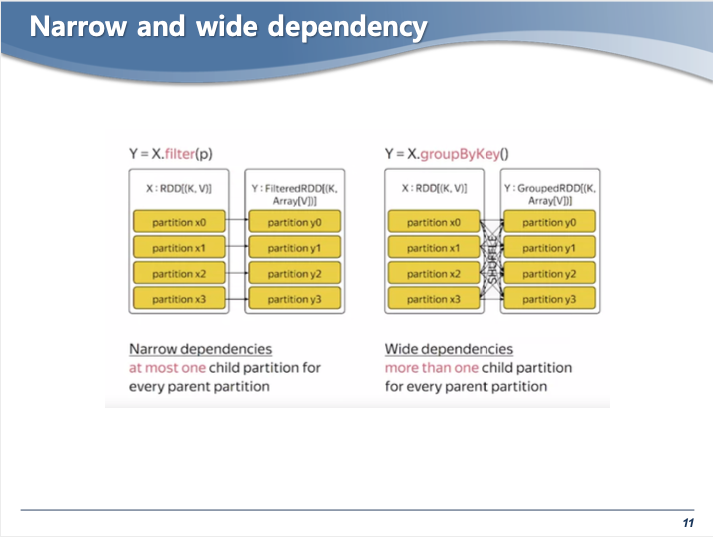
- Narrow dependency : 디펜던시가 하나의 파티션에서 유지되는 것 / map, filter ...
- Wide dependency : 디펜던시가 여러개의 파티션에서 유지되는 것 / key value Op.

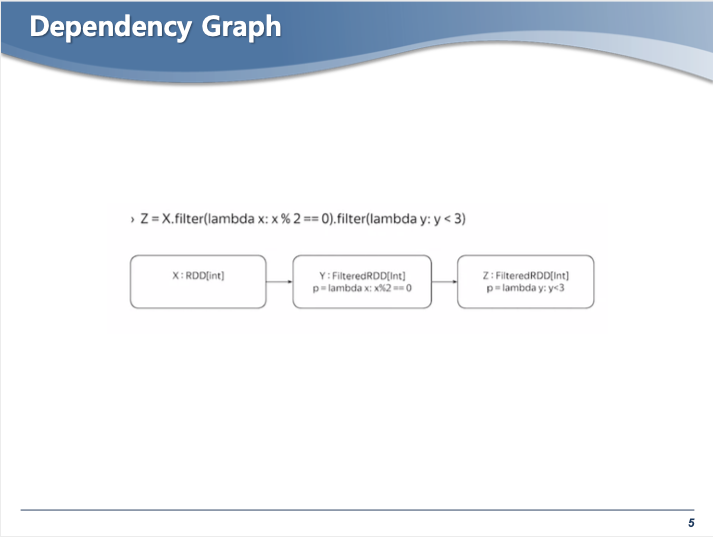
- 위 명령어 모두가 Transformation 오퍼레이션이다.
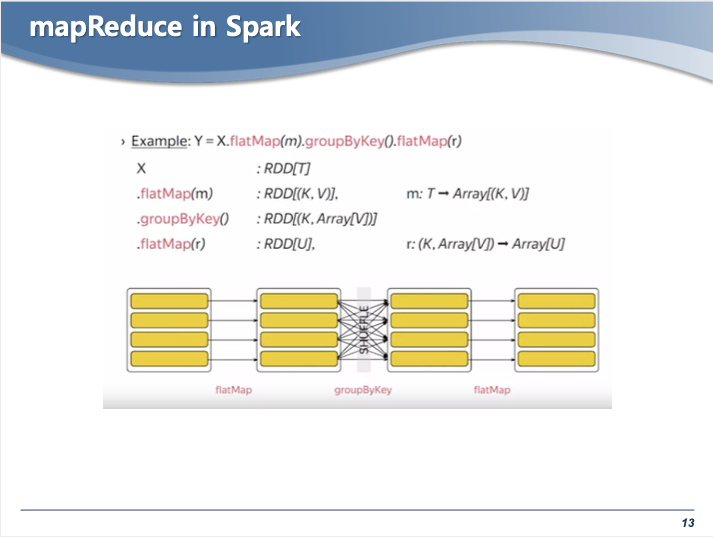
- example 명령어를 수행하면, 총 4개의 파티션이 생성된다 ( 기존1 + 새로운3 )
- 이러한 구조를 리니지 구조라고 한다. 리니지를 통해 RDD 디펜던시를 관리

- action (=excutor)를 수행하면, 실제로 RDD가 만들어진다.

- collect, select 문과 같은 함수를 Action 이라고 한다.
- 리니지를 통해 디펜던시를 파악하고 결과를 사용자에게 출력한다.

- 여러가지 Action 명령어들은 위와 같다.

- Resiliency : Fault tolerance를 위한 개념
- Determinism : Function이 실행될 때, 그 결과가 항상 같아야 한다.
- Freedom of side-effects : Func.을 수행했을 때, 다른 것들에 영향을 주지 않는다.
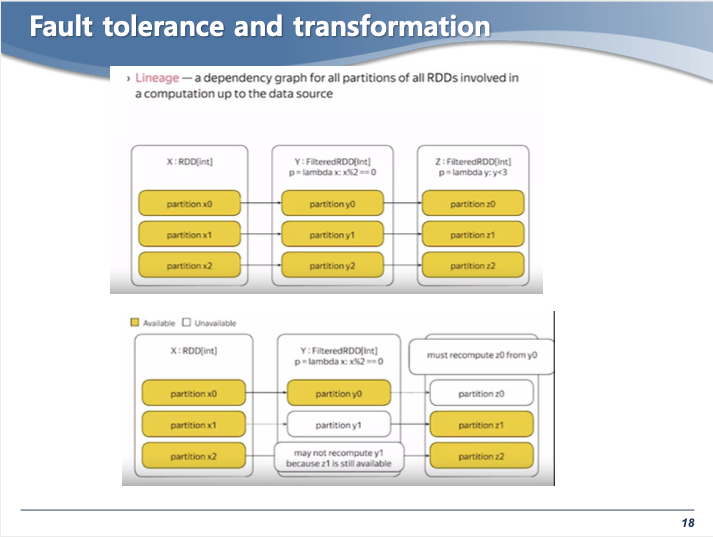
- Lineage : 데이터소스로부터 만들어진 디펜던시 그래프
- Spark 에서는 이 리니지를 저장해놓았다가, 문제가 생길 시 백트래킹을 통해 복구를 한다
- 아래 그림을 보면, 데이터에 문제가 생긴 부분 (하얀박스)이 있음.
- 리니지 정보를 확인하면 부모 RDD 에서 문제가 발생한 RDD 를 복구할 수 있다.
Lineage는 Lazy Evaluation 과 fault tolerance를 할 수 있음.

- Wide 디펜던시의 경우는 Narrow 디펜던시 보다 복잡하게 복구를 한다.
- 부모 RDD의 모든 partition을 참고해야 한다.
Narrow 디펜던시를 사용하는 것이 Lazy Evalution 과 fault tolerance 에 더 효과적임

'당신을 한 줄로 소개해보세요'를 이 블로그로 대신 해볼까합니다.