데이터 구조
CRISP-DM
- 비즈니스 문제 해결 방법론
데이터 유형
- 범주형 : 몇개의 범주로 나누어진 자료를 의미
- 명목형 : 단순히 분류된 자료 (성별,성공여부,혈액형)
- 순서형 : 개개인의 값들이 이산적이며 그들 사이에 순서 관계가 존재하는 자료 (연령대, 매출등급)
- 수치형 : 이산형과 연속형으로 이루어진 자료를 의미
- 이산형 : 이산적인 값을 갖는 데이터 (판매량,매출액,나이)
- 연속형 : 연속적인 값을 갖는 데이터 (신장,체중,온도)
기본 구조 : 2차원 데이터
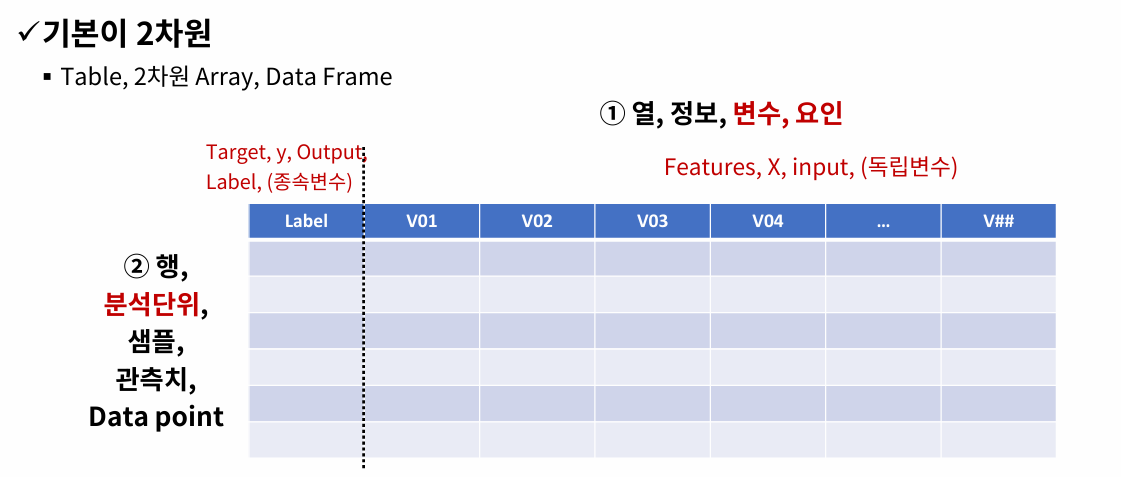
- 행이 중요!
데이터구조를다루는패키지
- Numpy : 수치 연산
- Pandas : 비즈니스 데이터 표현
Numpy 기초
- 빠른 수치 계산을 위해 C언어로 만들어진 Python 라이브러리
- 벡터와 행렬 연산에 편리한 기능들을 제공 (선형 대수)
- 데이터 분석용 라이브러리인 Pands와 Matplotlib의 기반으로 사용됨
- Array(벡터,행렬) 단위로 데이터 관리
라이브러리 불러오기
- 별칭 없이 라이브러리 불러오기
import numpy
a=numpy.array([1,2,3,4,5])- 별칭 주고 라이브러리 불러오기
import numpy as np
a=np.array([1,2,3,4,5])- 특정 함수만 불러오기
from numpy import array
a=array([1,2,3,4,5])Numpy 용어 정리
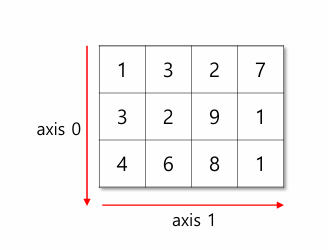
- Axis : 배열의 각 축 ex) axis0, axis1
- Axis 0 : 단위 데이터(row)의 건수
- Axis 1 : 변수의 건수
- Rank : 축의 개수(차원) ex) Rank 2 Array
- Shape : 축의 길이 ex) (3,4)
- (행의 개수, 열의 개수)
배열 만들기
- 1차원 배열
- [...] 형태
a = np.array([1, 2, 3, 4, 5])
print(a) # [1 2 3 4 5]
print(type(a)) # <class 'numpy.ndarray'>
print(a.ndim) # 1 <-- 차원
print(a.shape) # (5, ) <-- 모양
print(a.dtype) # int32 <-- 데이터 형식- 2차원 배열
- [[...],[...]] 형태
a = np.array([[1.5, 2.5, 3.2],
[4.2, 5.7, 6.4]])
print(a)
print(a.ndim) # 2
print(a.shape) # (2, 3)
print(a.dtype) # float64- 3차원 배열
- [[[…],[…]].[[…],[…]]] 형태
a3 = [[[1, 3, 1],
[4, 7, 6],
[8, 3, 4]],
[[6, 2, 4],
[8, 1, 5],
[3, 5, 9]]]
print(a.ndim) # 3
print(a.shape) # (2,3,3)
print(a.dtype) # int64- 3차원 배열 읽기 (2,3,3)
- (3,3) 크기 2차원 배열이 2개 !
- Axis 0 은 데이터 건수
- reshape 메서드
- 배열을 사용할 때 다양한 형태(Shape)로 변환
- (m, -1) 또는 (-1, n) 처럼 사용해 행 또는 열 크기 한 쪽만 지정
# (2, 3) 형태의 2차원 배열 만들기
a = np.array([[1, 2, 3],
[4, 5, 6]])
# (3, 2) 형태의 2차원 배열로 Reshape
b = a.reshape(3, 2)참조 : 배열을만드는여러함수들
- np.zeros( ) :0으로채워진배열
- np.ones( ) : 1로채워진배열
- np.full( ) : 특정값으로채워진배열
- np.eye( ) : 정방향행렬
- np.random.random( ) : 랜덤값으로채운배열
배열 데이터 조회
인덱싱
- 1차원 배열은 리스트와 방법이 같음
- 배열[행, 열] 형태로 특정 위치의 요소를 조회
- 배열[[행1,행2,..], :] 또는 배열[[행1,행2,..]] 형태로 특정 행을 조회
- 배열[:, [열1,열2,...]] 형태로 특정 열을 조회
- 배열[[행1,행2,...], [열1,열2,...]] 형태로 특정 행의 특정 열을 조회
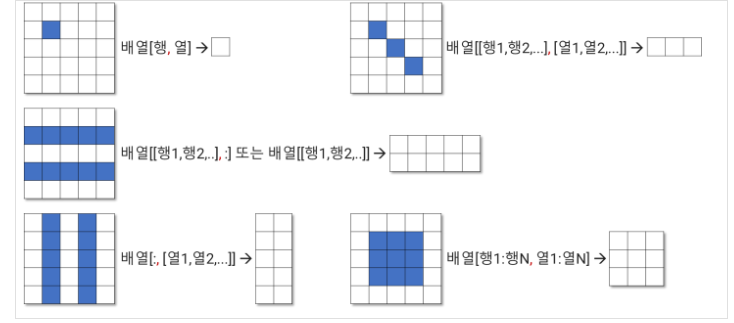
슬라이싱
- 배열[행1:행N,열1:열N] 형태로 지정해 그 위치의 요소를 조회
- 조회 결과는 2차원 배열
- 마지막 범위 값은 대상에 포함 X
조건 조회
- 조건에 맞는 요소를 선택하는 방식이며, 불리안 방식
# 2차원 배열 만들기
score= np.array([[78, 91, 84, 89, 93, 65],
[82, 87, 96, 79, 91, 73]])
# 요소 중에서 90 이상인 것만 조회
print(score[score >= 90])- 검색 조건을 변수로 선언해 사용 가능
# 요소 중에서 90 이상인 것만 조회
condition = score >= 90
print(score[condition])배열 연산
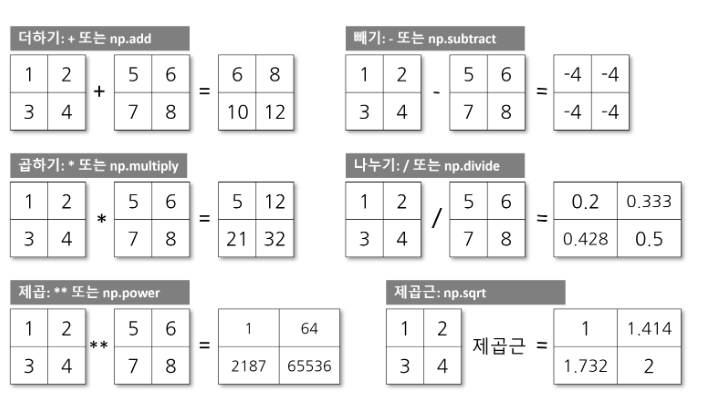
배열 집계
- np.sum()
- axis = 0 : 열 기준 집계
- axis = 1 : 행 기준 집계
- 생략하면 : 전체 집계
- 동일한 형태로 사용 가능한 함수 : np.max(), np.min, np.mean(), np.std()
# array를 생성합니다.
a = np.array([[1,5,7],[2,3,8]])
# 전체 집계
print(np.sum(a))
# 열기준 집계
print(np.sum(a, axis = 0))
# 행기준 집계
print(np.sum(a, axis = 1))자주 사용되는 함수들
- np.argmax(), np.argmin() : 가장 큰(작은) 값의 인덱스 반환
print(a)
# 전체 중에서 가장 큰 값의 인덱스
print(np.argmax(a))
# 행 방향 최대값의 인덱스
print(np.argmax(a, axis = 0))
# 열 방향 최대값의 인덱스
print(np.argmax(a, axis = 1))
- np.where(조건문, True일때 값, False일 때 값)
# 선언
a = np.array([1,3,2,7])
# 조건
np.where(a > 2, 1, 0)Pandas 기초
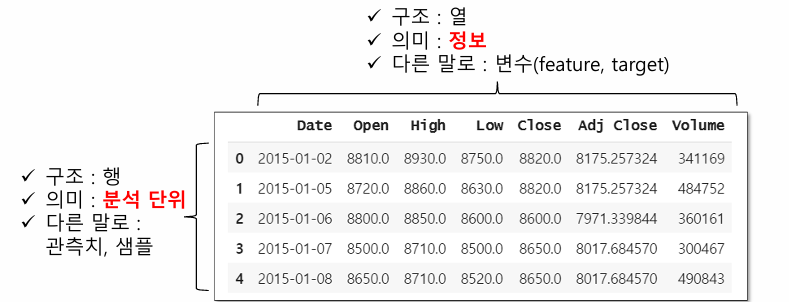
데이터 프레임 (Dataframe)
- 데이터분석에서 가장 중요한 데이터구조
- 일반적으로 접하게 되는 테이블 형태, 엑셀 형태
- 변수들의 집합→ 각 열을 변수라고 부름
- 인덱스 (=행 이름)
- 열 이름
시리즈 (Series)
- 하나의 정보에 대한 데이터들의 집합
- 데이터 프레임에서 하나의 열을 떼어낸 것.(1차원
라이브러리 불러오기
# 라이브러리 불러오기
import pandas as pd딕셔너리로 만들기
- 딕셔너리로 데이터프레임을 만들면 딕셔너리의 키가 열 이름
- 인덱스를 지정하지 않으면 행 번호가 인덱스
# 딕셔너리 만들기
dict1 = {'Name': ['Gildong', 'Sarang', 'Jiemae', 'Yeoin'],
'Level': ['Gold', 'Bronze', 'Silver', 'Gold'],
'Score': [56000, 23000, 44000, 52000]}
데이터프레임 만들기
df = pd.DataFrame(dict1)CSV 파일 읽어오기
- read_csv(path)
# 데이터 읽어오기
path = 'https://raw.githubusercontent.com/DA4BAM/dataset/master/titanic_simple.csv'
data = pd.read_csv(path)
# 상위 10행만 확인
data.head(10)데이터프레임 정보 확인
- .head(): 앞쪽데이터확인
- .tail() : 뒤쪽 데이터 확인
- .shape 속성: 데이터프레임모양확인 → (행수, 열수) 형태
- .info() : 인덱스, 열, 값 개수, 데이터형식정보등확인
- .describe() :기초 통계정보확인
데이터 정렬
- .sort_values(by='특정열',ascending = True/False): 특정열을 기준으로 정렬
- ascending = True: 오름차순정렬(기본값)
- ascending = False: 내림차순정렬
# 단일 열 정렬
tip.sort_values(by='total_bill', ascending=False
# 복합 열 정렬
tip.sort_values(by=['total_bill', 'tip'], ascending=[False, False])고유값 확인
- .unique() : 고유값 확인
# day 열 고유값 확인
tip['day'].unique()- .value_counts() : 고유 값과 그 개수 확인
Pandas2
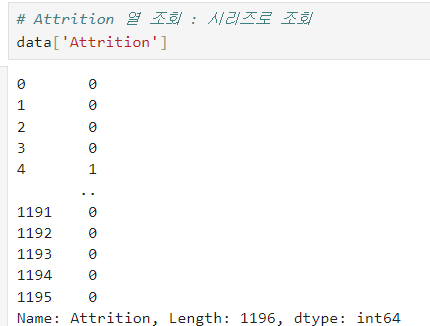
특정 열 조회
-
Dataframe['column'] : 1차원(시리즈)로 조회
-
Dataframe[['column']] : 2차원(데이터프레임)으로 조회
- 대괄호 2개가 아니라, 칼럼 이름을 리스트로 입력한 것!
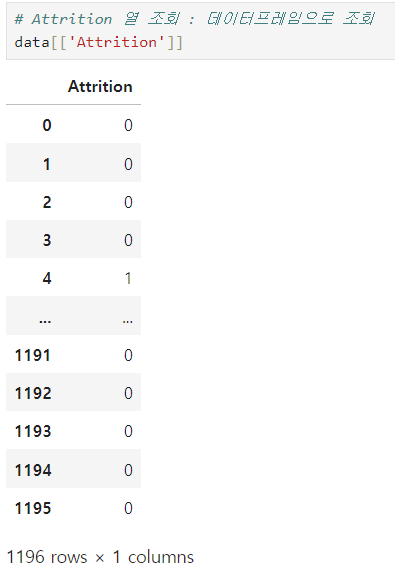
- 대괄호 2개가 아니라, 칼럼 이름을 리스트로 입력한 것!
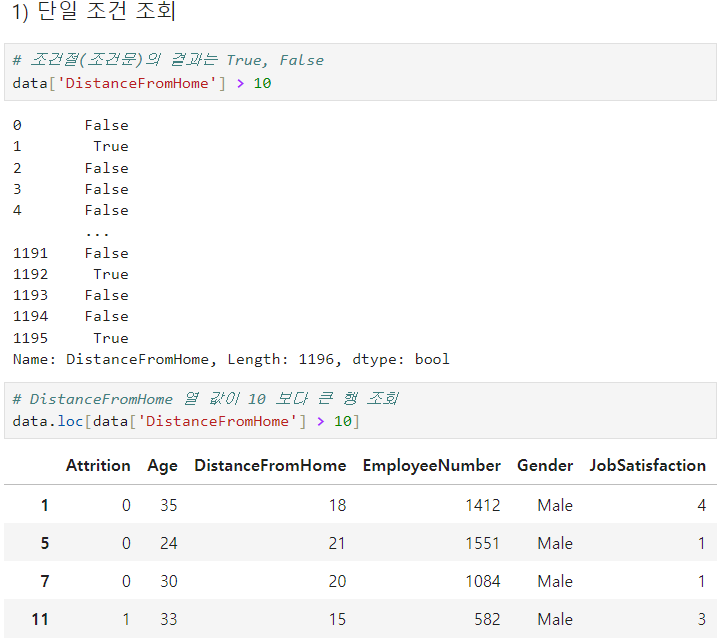
조건으로조회: .loc[ 행조건 , 열이름 ]
-
열 이름 생략 가능
-
열 이름 1개 -> 결과 : 시리즈
-
열 이름 여러개를 리스트로 -> 결과 : 데이터 프레임
-
여러 조건으로 조회
- and 와 or 사용
- (조건1) & (조건2) 처럼 괄호로 묶어야함.
-
.isin([값1,값2...]) :값1 또는 값2 또는...값n인 데이터만 조회
- 값들은 리스트 형태로 입력
- data.loc[data['JobSatisfaction'].isin([1,4])]
-
.between(값1, 값2): 값1 ~ 값2까지 범위안의 데이터만 조회
- inclusive = 'both' (기본값) /'left'/'right'/'neither'
- data.loc[data['Age'].between(25, 30)]
집계 함수
- 합: sum()
- 평균: mean()
- 최댓값: max()
- 최솟값: min()
- 개수: count(
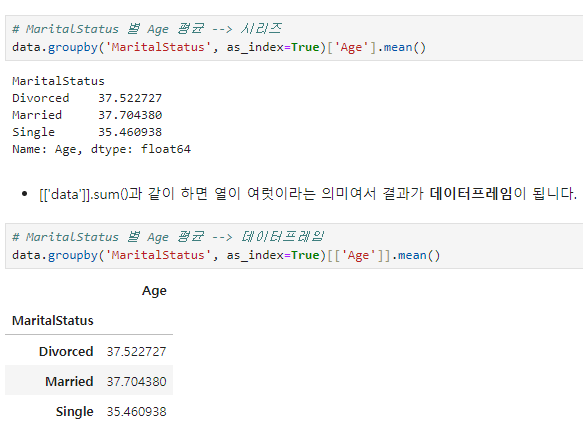
Fare_mean=data['Fare'].mean()groupby()
- dataframe.groupby( ‘집계기준변수’, as_index = )[‘집계대상변수’].집계함수
- 집계기준변수: ~~별 에 해당되는 변수 혹은 리스트. 범주형 변수 (예: 월별, 지역별 등)
- 집계대상변수: 집계 함수로 집계 할 변수 혹은 리스트. (예: 매출액합계)
- as_index = True → 집계기준변수를 인덱스로 사용 (default: True)
- [[tip']].sum() → 결과가 데이터프레임이 됨

복습 복습 복습