AIVLE
1.[1week] GIT
프로젝트의 버전 관리와 백업 그리고 협업을 위해서 GIT을 사용한다.버전관리는 디버깅을 위한 것 ! !VS실행 - 폴더 생성 - New File - 폴더이름.txt - Source Control버전 메시지를 적어 커밋(변경사항 제출)처음 시작시 이메일과 이름 설정 (인
2.[1week] Python 프로그래밍 & 라이브러리(1)

Anaconda Prompt 실행파일 탐색기에서 아래의 경로로 이동 해당 위치에 실습 자료 저장프롬프트에서 해당 위치로 이동jupyter lab 입력파란 점이 있으면 실행중임shutdown▪ Shift + Enter : 셀 실행, 다음 셀 이동▪ Ctrl + Enter
3.[1week] Python 프로그래밍 & 라이브러리(2)
비즈니스 문제 해결 방법론범주형 : 몇개의 범주로 나누어진 자료를 의미명목형 : 단순히 분류된 자료 (성별,성공여부,혈액형)순서형 : 개개인의 값들이 이산적이며 그들 사이에 순서 관계가 존재하는 자료 (연령대, 매출등급)수치형 : 이산형과 연속형으로 이루어진 자료를 의
4.[2week] 데이터 처리(1)
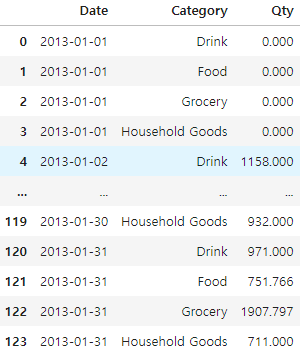
데이터 전처리에는 두 단계가 있음1\. 데이터 구조 만들기2\. 모델링을 위한 전처리ex) 나이 -> 나이대,고객 구매액 -> 고객 등급내가 원하는 구간으로 자르기 : bins = 분할된 범주에 이름 붙이기 : labels = 범주 이름 X 소괄호 : = 포함 X
5.[2week] 데이터 처리(2)
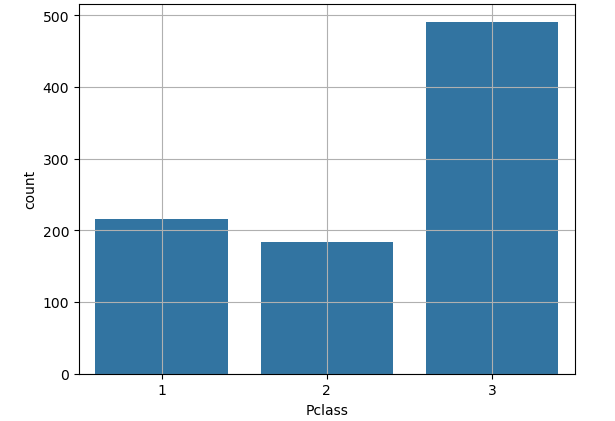
비즈니스 문제 해결 방법론비즈니스 이해 (Business Understanding): 프로젝트의 목적과 요구사항을 비즈니스 관점에서 이해하는 단계. 데이터 분석의 목표를 설정하고 초기 계획을 수립데이터 이해 (Data Understanding): 분석에 필요한 데이터를
6.[2week] 데이터 분석 및 의미 찾기(1)
휴가 낸거 복습하기..
7.[2week] 데이터 분석 및 의미 찾기(2)
데이터가 평균으로부터 얼마나 흩어져 있는지를 나타내는 통계적 척도데이터가 평균으로부터 얼마나 퍼져 있는지를 나타내는 통계적 척도분산의 제곱근이탈도 (devlation)데이터의 변동성전체 모집단에서 일부를 선택하여 데이터를 수집하는 과정 (모집단 추정)모 평균에 대한 추
8.[3week] AI_웹 크롤링(1)
Web Server & Client 구조 Client Request : 브라우저를 사용하여 Server에 데이터를 요청 Server Response : Client의 브라우저에서 데이터를 요청하면 요청에 따라 데이터를 Client로 전송 - Respons
9.[3week] AI_웹 크롤링(2)
동적 페이지 브라우저 WAS URL 접속 ------------------->request html request json response(JSON) JSON(str) -> list,dict -> DF 정적 페이지 브라우
10.[4week] 웹 크롤링(3)
ㅇ
11.[4week] ML - 머신러닝 소개
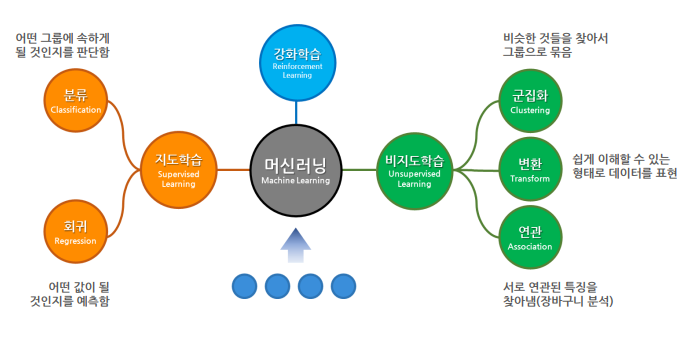
머신 러닝이란 ?컴퓨터에 여러 경험 데이터를 주고 인공 신경망으로 학습시켜서 예측하게 하는 것지도 학습 (Supervised Learning)학습 대상이 되는 데이터에 정답을 주어 규칙성즉, 데이터의 패턴을 배우게 하는 학습 방법비지도 학습 (Unsupervised L
12.[4week] ML - 성능 평가

분류 모델은 0인지 1인지 예측하는 것예측 값이 실제 값과 많이 같을 수록 좋은 모델이라고 할 수 있음\-> 정확히 예측한 비율로 모델 성능을 평가회귀 모델이 정확한 값을 예측하기는 사실상 어려움예측 값과 실제 값 차이(=오차)가 존재할 것이라 예상예측 값이 실제 값에
13.[5week] ML - 기본 알고리즘
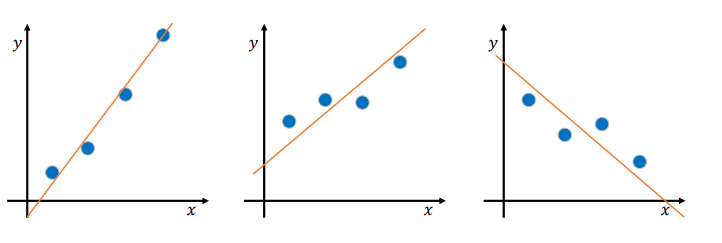
• 데이터는 다양한 형태를 가질 것이며 최선의 직선을 긋기가 쉽지 않음• 과연 위 직선이 가장 최선의 직선일 것인가?• 함수 𝑦 = 𝑎𝑥 + 𝑏 에서 최선의 기울기 𝑎와 𝑦 절편 𝑏를 결정하는 방법이 필요• 이것이 선형 회귀이며, 직선을 회귀선이라고 부름최
14.[5week] ML - 로지스틱 회귀, K-분할 교차 검증
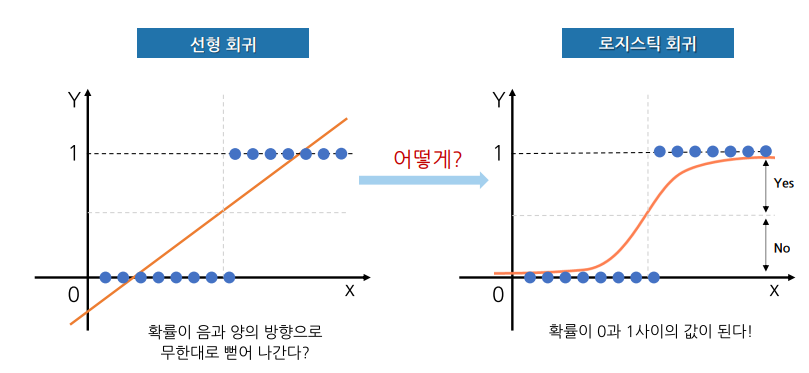
Chapter 4. Logistic Regression 선형회귀와 로지스틱 회귀 로지스틱 함수 분류 문제에 사용 시그모이드(sigmoid) 함수라고도 부름 확률 값 p는 f(x) 값이 커지면 1, 작아지면 0 에 가까워 짐 $$(-\infty,\infty)$$ 범위를 갖는 선형 판별식 결과로 $$(0,1)$$ 범위의 확
15.[5week] ML - 앙상블

전체 테이터 중에서 Target의 값이 1인 데이터가 매우 적을때 클래스 불균형이 일어남.실무에서는 Accuracy가 낮아지더라도 1에 대한 recall을 높여야 할 경우가 있음\-> 이때 Under Sampling, Over Sampling을 사용imblearn 설치
16.[6week] 딥러닝
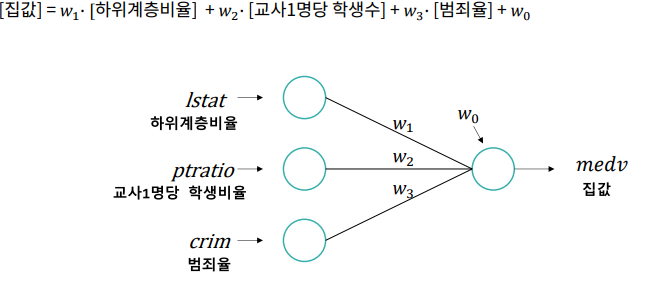
선형 회귀 모델데이터 불러오기타겟 선정NaN, 가변수화 (필요시)데이터 분할스케일링 (필수)모델링1) 모델 선언2) 학습3) 예측4) 검증$$medv = w_1 \* lstat + w_0$$▪ 가중치 초기값을 할당한다. (초기 모델을 만든다.)▪ (초기)모델로 예측한다
17.[7week] 딥러닝(2)
A Neural Network Playground - TensorFlow : https://bit.ly/487HdL1 Chapter 7. 성능 관리 적절한 모델 모델마다 각각 복잡도 조절 방법이 존재 복잡도를 조금씩 조절해가면서 (하이퍼파라미터 조정) train
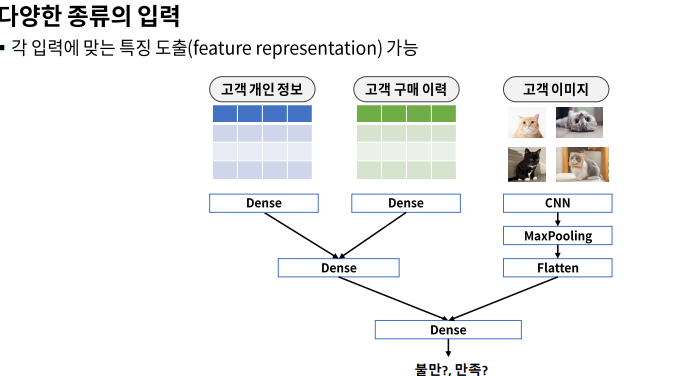
18.[8week] 시각지능 딥러닝(1) : FC, CNN
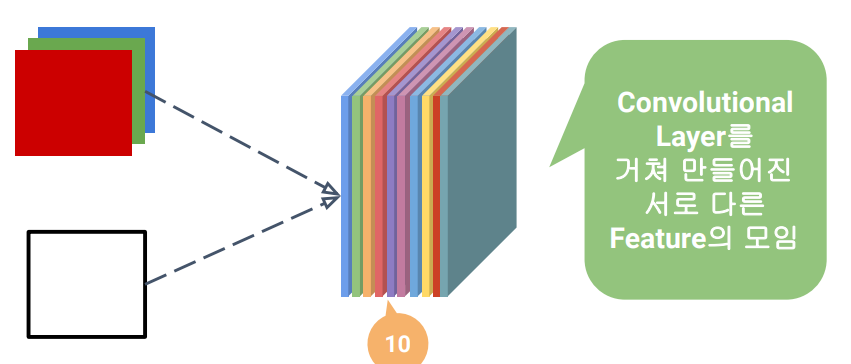
\+) relu : 0 이하는 0, 0 이상은 그대로 반환feature map : 이미지 특징을 추출한 mapfilter (=kernel) : 이미지로부터 내가 원하는 특징만 추출한 것filter는 이미지 데이터를 지정된 간격으로 움직이며 합성곱 계산을 수행filter
19.[8week] 시각 지능 딥러닝 (2) : Data Augmentaion, Transfer Learning,

Image Data Augmentation : 이미지 데이터 증강 기법 데이터 수집에 있어서 한계가 생길 수 있음 수집한 이미지 데이터만으로라도 이용해서 어떻게든 성능을 높여보자! 데이터 증강의 한계 과적합 위험: 너무 많은 증강을 통해 모델이 비정상적으로 학습할 수
20.[10week] 언어 지능 딥러닝

TF-IDF : TermFrequency - Inverse Document Frequency 어떤 문서를 주며 핵심어를 추출해야 한다고 할때, 컴퓨터는 1. 많이 언급 되는 단어 2. 그 중 이 문서에서만 등장하는 단어 를 기준으로 핵심어를 추출한다. 단
21.[14week] SQL
SQL Structured Query Language 데이터베이스에서 데이터를 조회하거나 처리할때 사용하는 구문 +) 이번 강의에서는 비교적 가벼운 MySQL을 통해 구문을 익힐 예정! +) 맥 homebrew : mysql 사용 - https://velog.io/@
22.[14 week] 가상화 클라우드
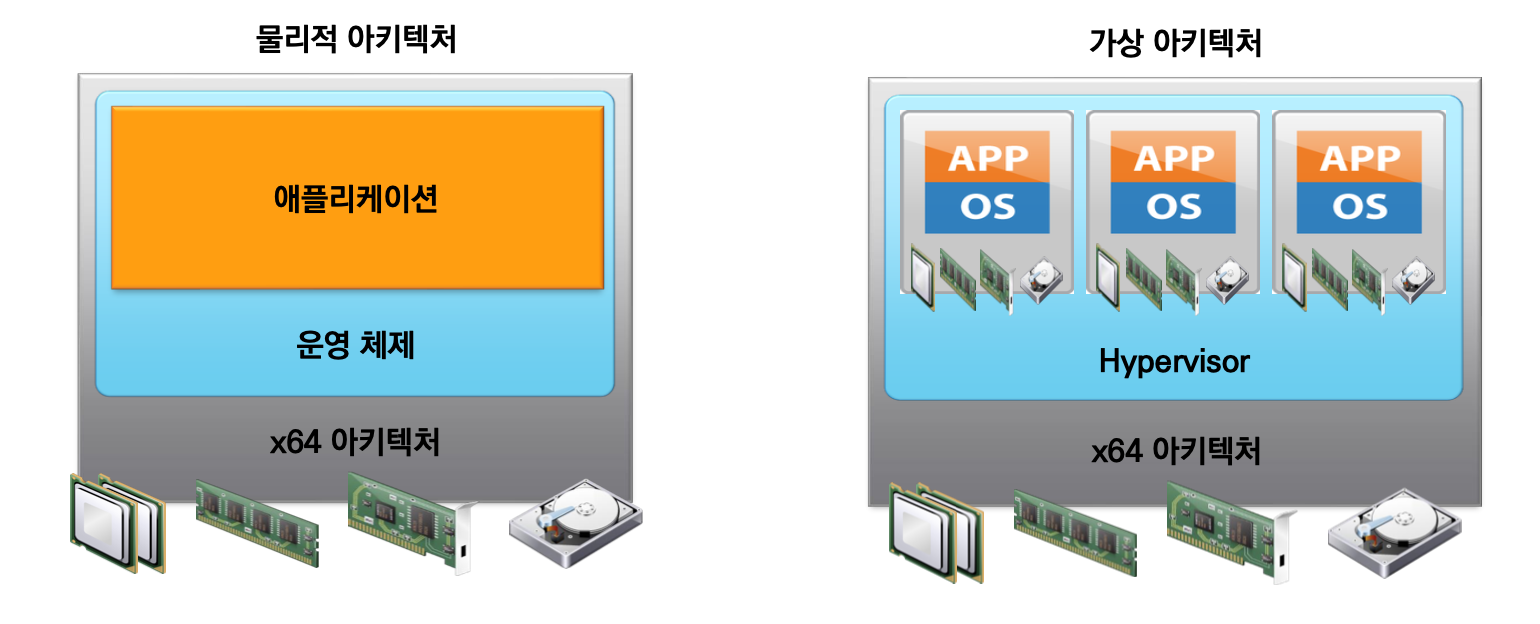
운영 체제에서 물리적 하드웨어를 분리하여 IT 담당자가 직면한 많은 문제에 대한 해결책을 제공하는 기술하나의 아키텍쳐에 하이퍼파이저가 메모리를 나눠 가상머신 VS를 여러개 구동.서버 가상화네트워크 가상화스토리지 가상화데스크톱 가상화서비스를 위한 물리적인 서버의 대수 감
23.VS CODE 가상환경 만들기
가상환경을 만들고자 하는 프로젝트 폴더를 생성venv 모듈을 사용하여 가상환경을 생성.venv는 가상환경 폴더 이름으로, 일반적으로 프로젝트 디렉토리 내에 생성됩니다.python3 명령어는 Mac에서 Python 3.x 버전을 실행하기 위해 사용됩니다.가상환경을 활성화
24.AICE Associate 합격 후기
올해부터 국가공인자격증 인정! AICE Associate란? AICE 는 한국 경제신문, KT에서 주관하는 AI 자격증 시험이다. 그 중 Associate는 실무에서 가장 많이 쓰는 Tabular 데이터에 대해 코딩(파이썬) 기반으로 데이터 분석 / 처리 / 모델링
25.[AI 여행 가이드 회고록] 네이버맵 메뉴 크롤링
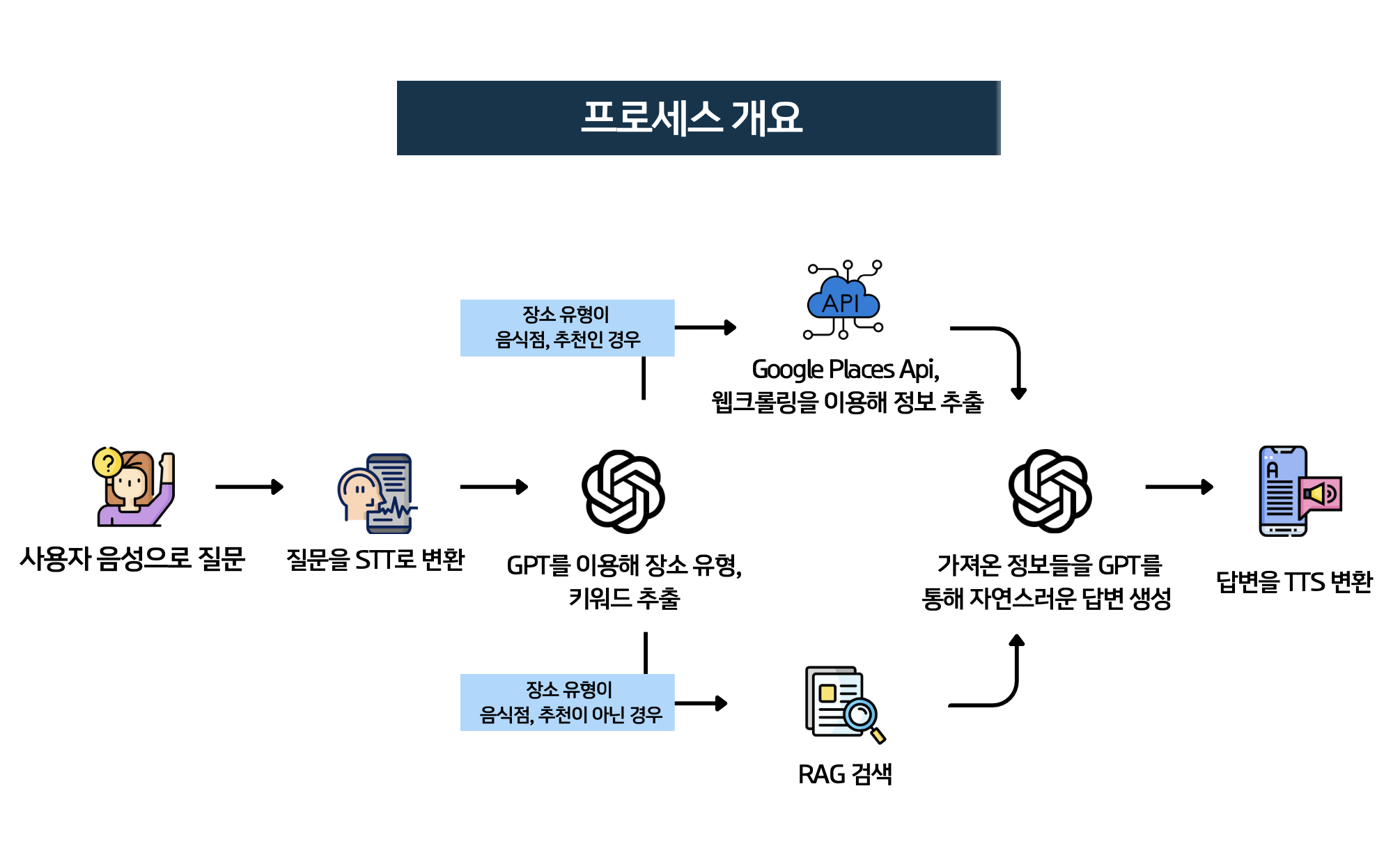
🔗 프로젝트 GitHub 바로 가기 GPT API를 활용하여 챗봇을 제작하며, 가장 큰 문제였던 것은 할루시네이션 문제였다. 만연하게 GPT의 성능을 믿고, 프롬프트만 잘 작성하면 되겠지~ 했었지만 그럴싸하게 내놓은 추천 카페, 음식점에 대한 답변은 사실 존재하지 않