4. 데이터 분석 방법론
CRISP - DM
-
비즈니스 문제 해결 방법론
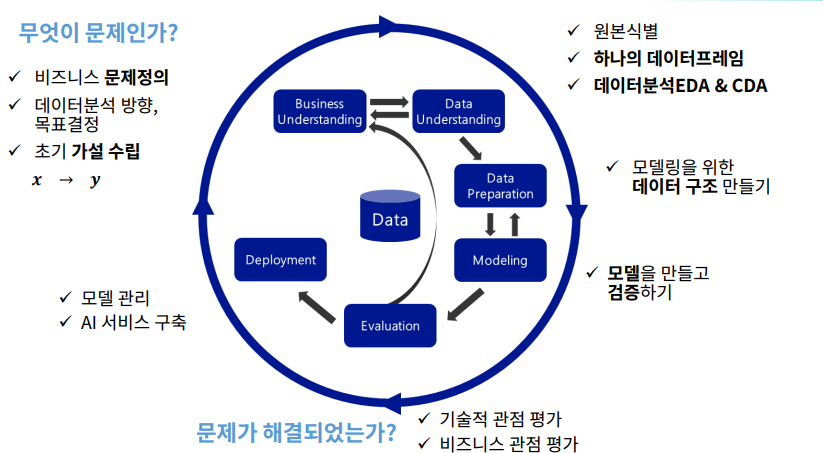
-
비즈니스 이해 (Business Understanding): 프로젝트의 목적과 요구사항을 비즈니스 관점에서 이해하는 단계. 데이터 분석의 목표를 설정하고 초기 계획을 수립 -
데이터 이해 (Data Understanding): 분석에 필요한 데이터를 수집, 데이터의 문제점과 숨겨진 인사이트를 발견 -
데이터 준비 (Data Preparation): 분석에 적합한 데이터셋을 준비하는 단계로, 데이터 정제, 통합, 변환 등의 작업이 포함 -
모델링 (Modeling): 다양한 모델링 기법을 적용하여 데이터를 분석. 모델의 성능을 평가하고 최적화 -
평가 (Evaluation): 모델링 결과가 비즈니스 목표에 부합하는지 평가. 분석 결과를 검토하고, 모델의 적용 가능성을 판단 -
전개 (Deployment): 완성된 모델을 실제 업무에 적용. 이를 통해 모델의 성능을 모니터링하고 유지보수 계획을 수립
①Business Understanding - 가설 수립
- 문제를 정의하고 요인을 파악하기 위해 가설 수립
- 귀무가설 : 기존 연구 결과로 이어져 내려오는 정설
- 대립 가설 : 기존의 입장을 넘어서기 위한 새로운 가설
가설 수립 절차

- 해결 해야 하는 문제가 무엇인가 ? (목표, 관심사,y)
- Y를 설명하기 위한 요인(x) 찾기
- 가설의 구조를 정의 (x -> y)
②Data Understanding
데이터 원본 식별 및 취득
- 초기 가설에서 도출된 데이터의 원본을 확인
데이터 탐색 : EDA, CDA
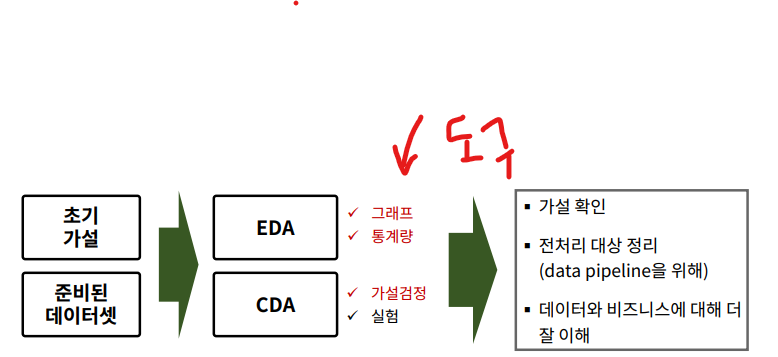
< 데이터 탐색 2가지 방법 >
- EDA (Exploratory Data Analysis)
- 탐색적 데이터 분석
- CDA (Confirmatory Data Analysis)
- 확증적 데이터 분석
< 데이터 탐색 순서 >
1. 단변량 분석 : 개별 변수의 분포 ex) 탑승객의 나이 분석
2. 이변량 분석1 : feature와 target 간의 관계 (가설을 확인하는 단계)
ex) 객실등급 -> 생존여부 (객실등급에 따라 생존 여부에 차이가 있나?)
3. 이변량 분석2 : feature들 간의 관계
③Data Preparation
개요
- 모든 셀에 값이 있어야 한다.
- 모든 값은 숫자이어야 한다.
- 값의 범위를 일치시켜야 한다 (옵션)
수행되는 내용
- 결측치 조치
- 가변수화
- 스케일링
- 데이터 분할
④Modeling
모델링 ( 학습, Learning, Training)
- 데이터로부터 패턴을 찾는 과정
- 오차를 최소화 하는 패턴
- 결과물 : 모델 (모델은 수학식으로 표현)
필요한 준비물
- 학습데이터
- 알고리즘
5. 시각화 라이브러리
- 파이썬 시각화 패키지
환경 준비
라이브러리 불러오기
import pandas as pd
import numpy as np
# 시각화 라이브러리
import matplotlib.pyplot as plt
import seaborn as sns데이터 불러오기
path = 'https://raw.githubusercontent.com/DA4BAM/dataset/master/airquality_simple2.csv'
data = pd.read_csv(path)
data['Date'] = pd.to_datetime(data['Date'])
data.dropna(axis = 0, inplace = True)
data.head()참고 : df.dropna(axis=,inplace=,how=)
- 결측치 레이블 삭제
기본 차트 그리기
plt.plot(1차원 값)
- x축 : 인덱스
- y축 : 1차원 값
- 라인차트를 그려줌
# 차트 그리기
plt.plot(data['Temp'])
# 화면에 보여주기
plt.show()
plt.plot(x축, y축) : x축과 y축의 값 지정하기
- plt.plot(x축, y축)
- plt.plot(x축, y축, data = )
# 타입1
plt.plot(data['Date'], data['Temp'])
plt.show()
# 타입2
plt.plot('Date', 'Temp', data = data)
plt.show()
차트 꾸미기
x축,y축 이름, 타이틀 붙이기
plt.plot(data['Date'], data['Ozone'])
plt.xticks(rotation = 30) # x축 값 꾸미기 : 방향을 30도 틀어서
plt.xlabel('Date') # x축 이름 지정
plt.ylabel('Ozone') # y축 이름 지정
plt.title('Daily Airquality') # 타이틀
plt.show()
라인 스타일 조정하기
- color=
- 'red','green','blue' ...
- 혹은 'r', 'g', 'b', ...
- https://matplotlib.org/stable/gallery/color/named_colors.html
- linestyle=
- 'solid', 'dashed', 'dashdot', 'dotted'
- 혹은 '-' , '--' , '-.' , ':'
- marker=
| marker | description |
|---|---|
| "." | point |
| "," | pixel |
| "o" | circle |
| "v" | triangle_down |
| "^" | triangle_up |
| "<" | triangle_left |
| ">" | triangle_right |
plt.plot(data['Date'], data['Ozone']
,color='green' # 칼러
, linestyle='dotted' # 라인스타일
, marker='o') # 값 마커(모양)
plt.xlabel('Date')
plt.ylabel('Ozone')
plt.title('Daily Airquality')
plt.xticks(rotation=45)
plt.show()
여러 그래프 겹쳐서 그리기
# 첫번째 그래프
plt.plot(data['Date'], data['Ozone'], color='green', linestyle='dotted', marker='o')
# 두번째 그래프
plt.plot(data['Date'], data['Temp'], color='r', linestyle='-', marker='s')
plt.xlabel('Date')
plt.ylabel('Ozone')
plt.title('Daily Airquality')
plt.xticks(rotation=45)
# 위 그래프와 설정 한꺼번에 보여주기
plt.show()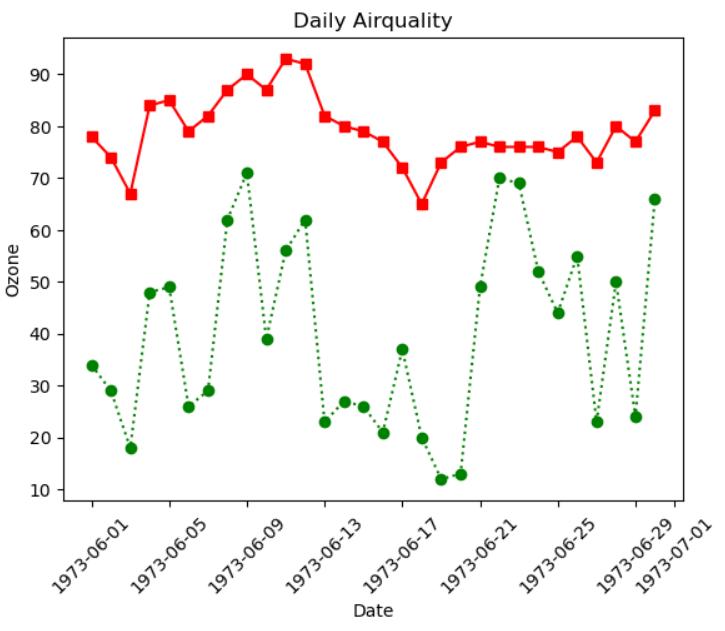
범례, 그리드 추가
plt.plot(data['Date'], data['Ozone'], label = 'Ozone') # label = : 범례추가를 위한 레이블값
plt.plot(data['Date'], data['Temp'], label = 'Temp')
plt.legend(loc = 'upper right') # 레이블 표시하기. loc = : 위치
plt.grid()
plt.show()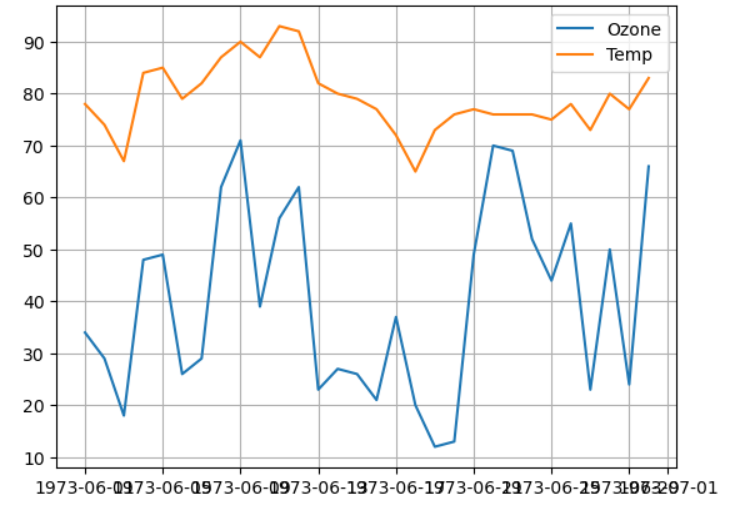
추가 기능
여러 그래프 나눠서 그리기
- plt.subplot(row, column, index)
- row : 고정된 행 수 (틀)
- column : 고정된 열 수 (틀)
- index : 순서 (순번): 1부터 시작
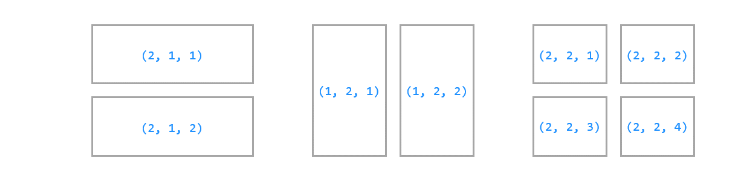
plt.figure(figsize = (12,8))
plt.subplot(3,1,1) # 틀
plt.plot('Date', 'Temp', data = data) #그래프
plt.grid()
plt.subplot(3,1,2) #틀
plt.plot('Date', 'Wind', data = data)
plt.subplot(3,1,3)
plt.plot('Date', 'Ozone', data = data) #그래프
plt.grid()
plt.ylabel('Ozone')
plt.tight_layout() # 그래프간 간격을 적절히 맞추기
plt.show()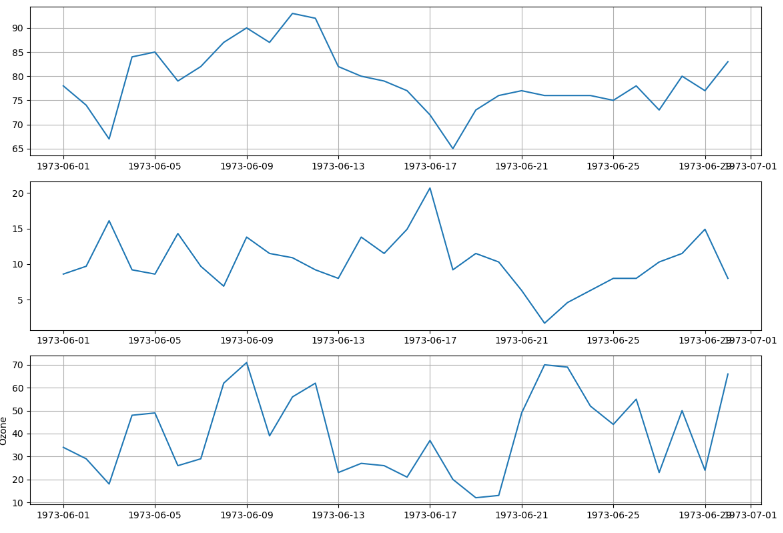
6. 단변량 분석 - 숫자
숫자형 변수 – 정리하는 두가지 방법
1. 숫자로 요약하기 : 정보의 대푯값
- 평균(mean) : np.mean() / df.mean()
- 중앙값(median) : np.mdian() / df.median()
- 최빈값(mode) : df.mode()
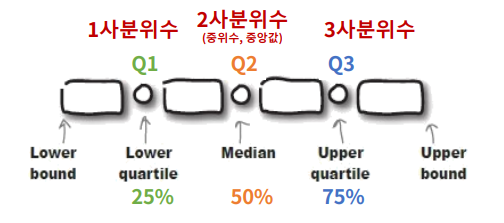
- 사분위수(Quantile)
- 데이터를 오름차순으로 정렬한 후, 전체를 4등분하고, 각 경계에 해당되는 값
- (25%,50%,75%)을 의미
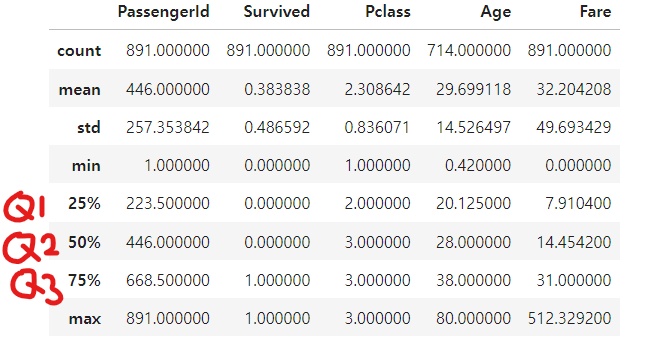
기초통계량
- 숫자 몇 개로 분포를 요약
df.describe()- count : 데이터 개수.
- Age의 개수가 다른 변수에 비해 적은 것은 NaN이 존재하기 때문
- 사분위수
- 25% : 1사분위수
- 50% : 2사분위수
- 75% : 3사분위수
2. 구간을 나누고 빈도수(frequecy) 계산
숫자형 변수 시각화 하기
Histogram
plt.his(변수명,bins=구간 수)
plt.hist(titanic.Fare, bins = 5, edgecolor = 'gray')
plt.xlabel('Fare')
plt.ylabel('Frequency')
plt.show()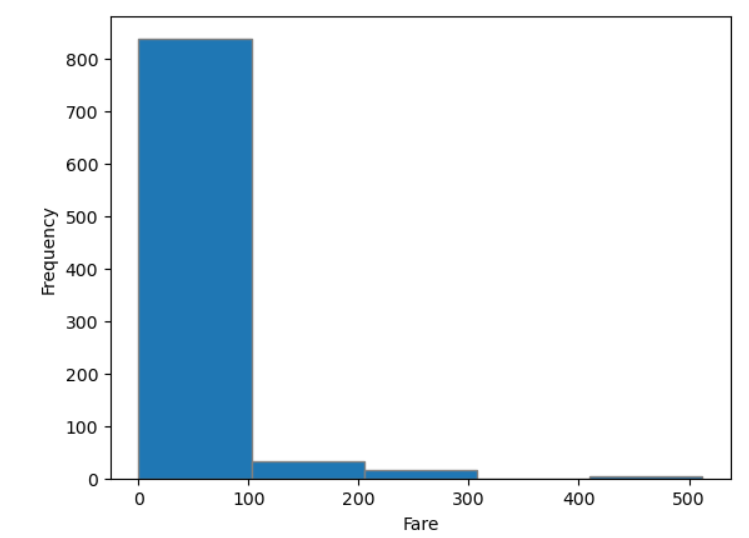
주의 !
히스토그램을 그릴 때, 주의 할 점 : bins를 적절히 조절
- 구간의 개수에 따라서 파악할 수 있는 내용이 달라짐.
sns.histplot(x=,data=,bins=)(간편~👍👍)
sns.histplot(x= 'Fare', data = titanic, bins = 20)
plt.show()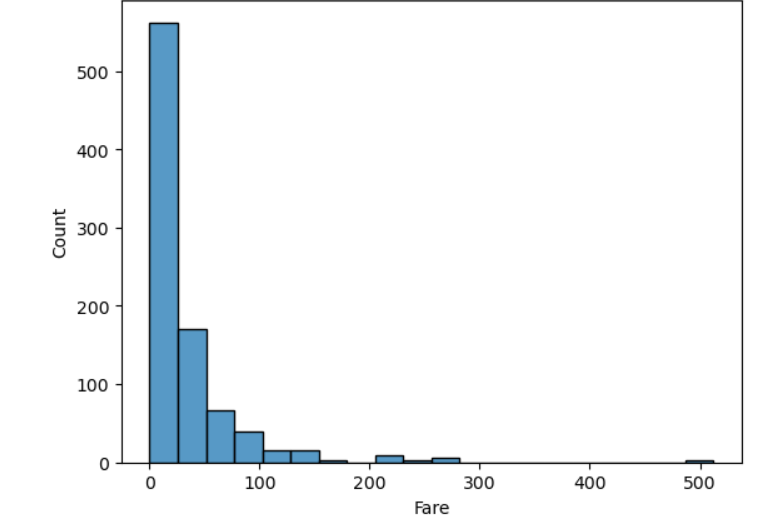
그래프 읽기
- 축의 의미 파악
- 값의 분포로부터 파악할 내용
- 희박한 구간? 밀집 구간?
- 왜 그 구간은 희박한가? 에 대한 비즈니스 의미 파악
Density Plot (KDE Plot) (밀도함수 그래프)
- 히스토그램과 달리 구간의 너비를 정하지 않아도 됨.
- 밀도함수 그래프 아래 면적은 1
sns.kdeplot(x=,data=)
#sns.kdeplot(titanic['Fare'])
sns.kdeplot(x='Fare', data = titanic)
plt.show()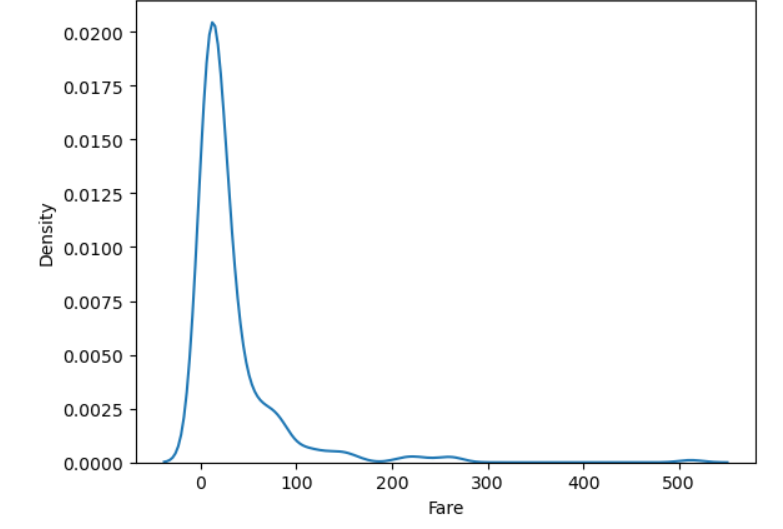
히스토그램과 밀도함수 그래프 동시에 나타내기
- sns.histplot(x=,data=,bins=,kde=True)
Box Plot
- 두부분으로 나뉨
- 박스 (Box): 제1사분위수(Q1)와 제3사분위수(Q3) 사이의 범위를 나타내며, 데이터의 중간 50%를 포함
- 수염
- 최솟값(Minimum): Q1에서 1.5 IQR(사분위 범위)을 뺀 값보다 큰 데이터 중 가장 작은 값.
- 최댓값(Maximum): Q3에서 1.5 IQR을 더한 값보다 작은 데이터 중 가장 큰 값.
- 이상치(Outliers): 수염의 범위를 벗어난 데이터로, 작은 원이나 점으로 표시
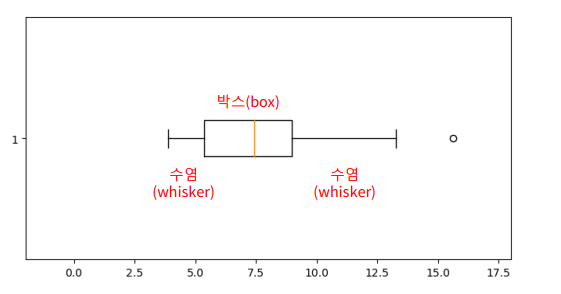
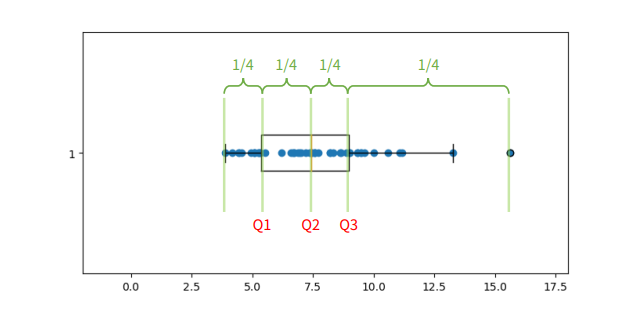
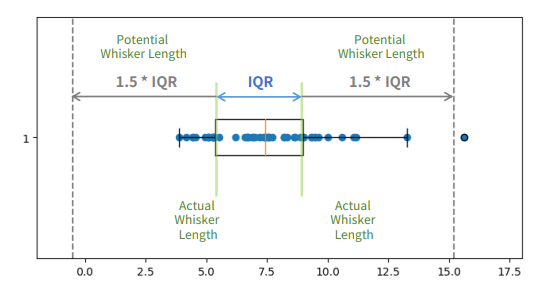
- IQR (Inter Quartile Range)
- 3사분위수 - 1사분위수
plt.boxplot( 변수, vert = )- 사전에 반드시 NaN을 제외(sns.boxplot 은 NaN을 알아서 제거해 줌)
- vert 옵션 : 횡(False), 종(True, 기본값)
# titanic['Age']에는 NaN이 있습니다. 이를 제외한 데이터
temp = titanic.loc[titanic['Age'].notnull()]
plt.boxplot(temp['Age'])
plt.grid()
plt.show()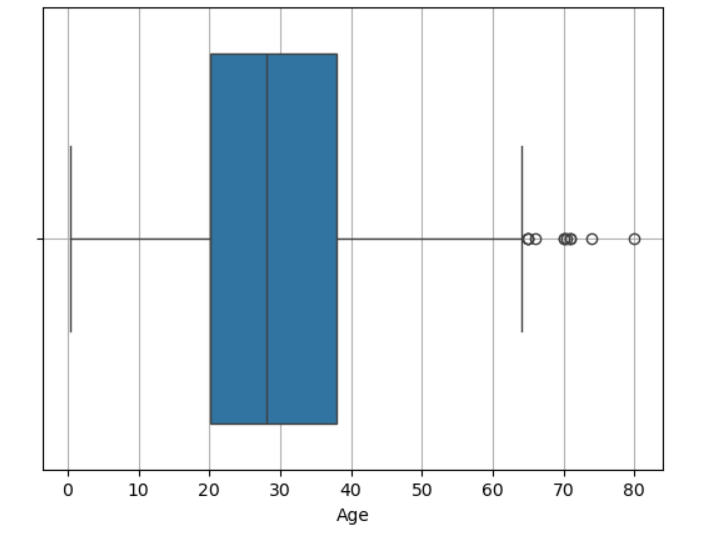
sns.boxplot(x or y = )
sns.boxplot(x = titanic['Age']) #seaborn 패키지 함수들은 NaN을 알아서 빼줍니다.
plt.grid()
plt.show()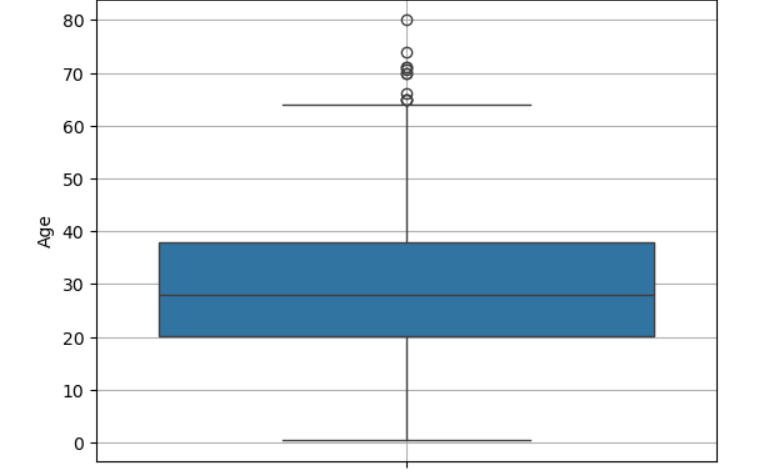
6.단변량 분석 - 범주형
범주별 개수를 세면 됨~
범주형 변수 숫자로 요약하기
시리즈.value_counts(): 범주별 빈도수시리즈.value_counts(normalize = True): 범주별 비율
범주형 변수 시각화 :Bar Plot
sns.countplot(x=,data=)
- 알아서 범주 별 빈도수가 계산 되고 bar plot으로 그려짐
sns.countplot(x = 'Pclass', data = titanic)
plt.grid()
plt.show()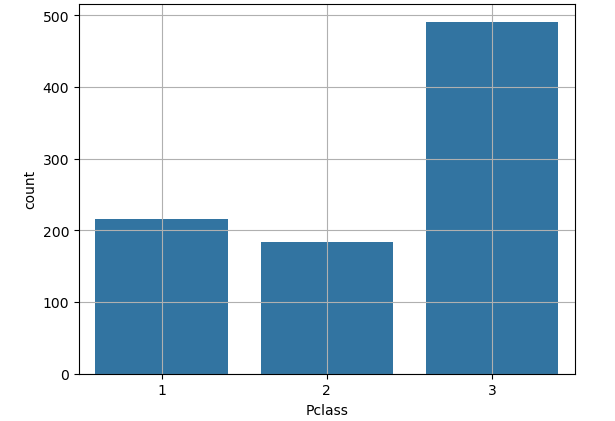
plt.bar
- 직접 범주 별 빈도수를 계산하고 그 결과를 입력해야 bar plot이 그려짐
