
Chapter 1. 회귀 모델 성능 평가
평가 방법
분류 모델 평가 : 정확도를 높여라
- 분류 모델은 0인지 1인지 예측하는 것
- 예측 값이 실제 값과 많이 같을 수록 좋은 모델이라고 할 수 있음
-> 정확히 예측한 비율로 모델 성능을 평가
회귀 모델 평가 : 오차를 줄여라
- 회귀 모델이 정확한 값을 예측하기는 사실상 어려움
- 예측 값과 실제 값 차이(=오차)가 존재할 것이라 예상
- 예측 값이 실제 값에 가까울 수록 좋은 모델이라 할 수 있음
-> 예측한 값과 실제 값의 차이(=오차)로 모델 성능을 평가
알아둘 기호

오차
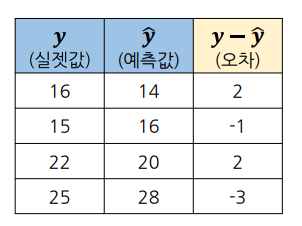
오차 평균
회귀 모델의 성능은 오차의 크기로 평가
-> 오차 각각의 값으로 표현하기 보다는 하나의 값으로 표현하는 것이 쉬움
오차 평균을 구해야 함
오차 합
- 오차 평균을 구하기 위해서는 오차 합을 구해야 함
-> 오차 제곱의 합과 오차 절대 값의 합을 사용

오차 제곱의 합
- 오차 제곱(SSE)의 합을 구한 후 평균을 구함 : MSE
- 오차의 제곱이므로 루트를 사용해 일반적인 값으로 표현 : RMSE
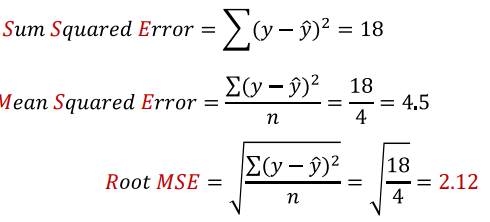
오차 절대값의 합
- 오차 절대값의 합을 구한 후 평균을 구함 : MAE
- 오차 비율을 표시하고 싶은 경우 MAPE를 사용
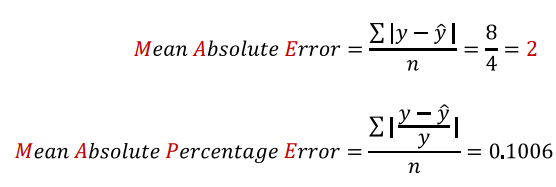
회귀 평가 지표 정리
값이 작을 수록 모델 성능이 좋음!
오차를 바라보는 다양한 관점
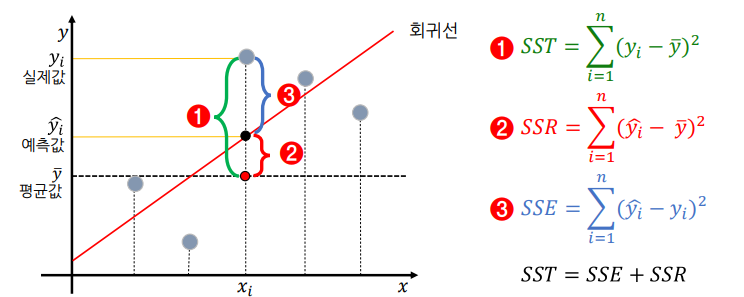
- SST: Sum Squared Total,전체 오차(최소한 평균 보다는 성능이 좋아야 하니, 우리에게 허용된(?) 오차)
- SSR: Sum Squared Regression, 전체 오차 중에서 회귀식이 잡아낸 오차
- SSE: Sum Squared Error, 전체 오차 중에서 회귀식이 여전히 잡아내지 못한 오차
결정 계수 (R-Squared)
- Coefficient of Determination
- MSE로 여전히 설명이 부족한 부분이 있음
- 모델 성능을 잘 해석하기 위해서 만든 MSE의 표준화된 버전이 결정 계수임
- 전체 오차 중에서 회귀식이 잡아낸 오차 비율(일반적으로 0 ~ 1 사이)
- 오차의 비 또는 설명력이라고도 부름
- 이면 𝑀𝑆𝐸 = 0이고 모델이 데이터를 완벽하게 학습한 것
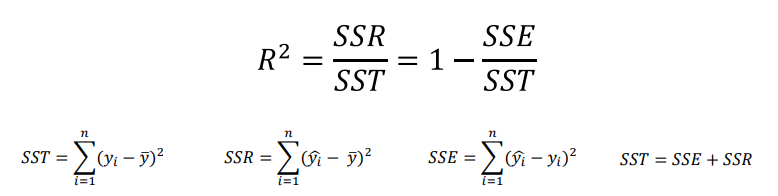
모델 평가하기
- 함수 불러오기
# 함수 불러오기
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_absolute_percentage_error
from sklearn.metrics import r2_score- 실젯값(y_test)과 예측값(y_pred)을 매개변수로 전달해 평가함
# 평가하기
# mean_absolute_error(실젯값, 예측값)
print(mean_absolute_error(y_test, y_pred))- MSE, RMSE, MAE, MAPE는 오류(Error) 이므로 작을 수록 좋음
- R2 Score는 클 수록 좋음
- 단순히 오차 절대값, 오차 제곱으로 계산되는 MAE, MSE는 함수 사용 시 실젯값, 예측값 위치를 바꿔도 되지만 바꾸지 않기를 권고
실습
1. 환경 준비
# 라이브러리 불러오기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings(action='ignore')
%config InlineBackend.figure_format = 'retina'
# 데이터 읽어오기
path = 'https://raw.githubusercontent.com/Jangrae/csv/master/airquality_simple.csv'
data = pd.read_csv(path)2. 데이터 이해
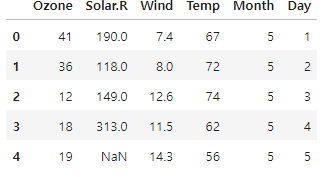
# 상위 몇 개 행 확인
data.head()
# 하위 몇 개 행 확인
data.tail()
# 변수 확인
data.info()
# 기술통계 확인
data.describe()
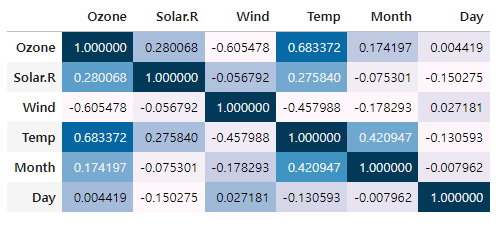
# 상관관계 확인
data.corr(numeric_only=True).style.background_gradient()
3. 데이터 준비
3-1) 결측치 처리
# 결측치 확인
data.isnull().sum()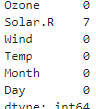
# 전날 값으로 결측치 채우기
data = data.fillna(method='ffill')
# 확인
data.isnull().sum()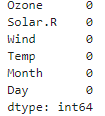
3-2) 변수 제거
# 변수 제거
drop_cols = ['Month', 'Day']
data = data.drop(columns=drop_cols)
# 확인
data.head()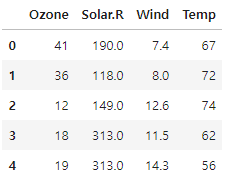
3-3) x, y 분리
# target 확인
target = 'Ozone'
# 데이터 분리
x = data.drop(columns=target)
y = data.loc[:, target]3-4) 학습용, 평가용 데이터 분리
# 모듈 불러오기
from sklearn.model_selection import train_test_split
# 7:3으로 분리
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=1)4. 모델링
# 1단계: 불러오기
from sklearn.linear_model import LinearRegression
# 2단계: 선언하기
model = LinearRegression()
# 3단계: 학습하기
model.fit(x_train, y_train)
# 4단계: 예측하기
y_pred = model.predict(x_test)5. 회귀 성능 평가
5-1) MAE (Mean Absolute Error)
# 모듈 불러오기
from sklearn.metrics import mean_absolute_error
# 성능 평가
print('MAE:',mean_absolute_error(y_test, y_pred))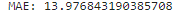
5-2) MSE (Mean Squared Error)
# 모듈 불러오기
from sklearn.metrics import mean_squared_error
# 성능 평가
print('MSE:',mean_squared_error(y_test, y_pred))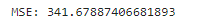
5-3) RMSE (Root Mean Squared Error)
# 모듈 불러오기
from sklearn.metrics import root_mean_squared_error
# 성능 평가
print('RMSE:',root_mean_squared_error(y_test, y_pred))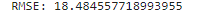
5-4) MAPE(Mean Absolute Percentage Error)
# 모듈 불러오기
from sklearn.metrics import mean_absolute_percentage_error
# 성능 평가
print('MAPE:',mean_absolute_percentage_error(y_test, y_pred))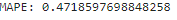
5-5) R2-Score
# 모듈 불러오기
from sklearn.metrics import r2_score
# 성능 평가
print('R2:',r2_score(y_test, y_pred))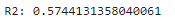
+) 참고
# 참고 : model.socre()를 사용해 R2 확인 : 평가 데이터에 대한 성능
model.score(x_test, y_test) # == R2 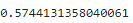
# 학습 데이터에 대한 성능
model.score(x_train, y_train)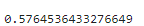
Chapter 2. 분류 모델 성능 평가
평가한 값에 이름을 부여
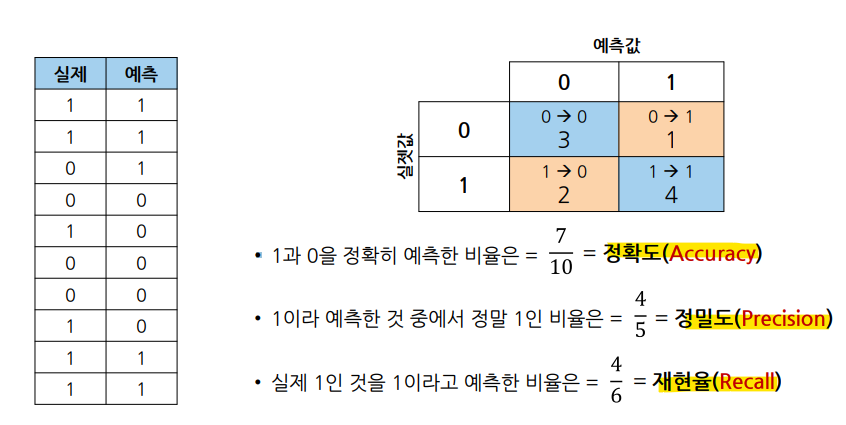
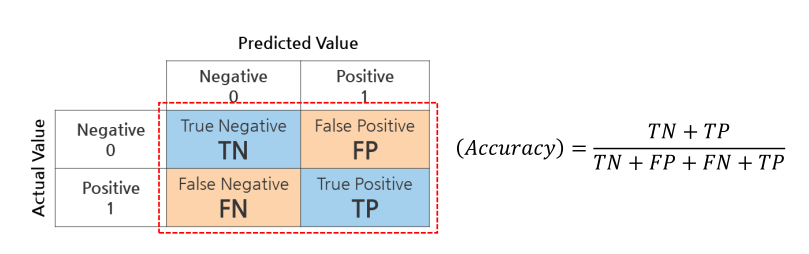
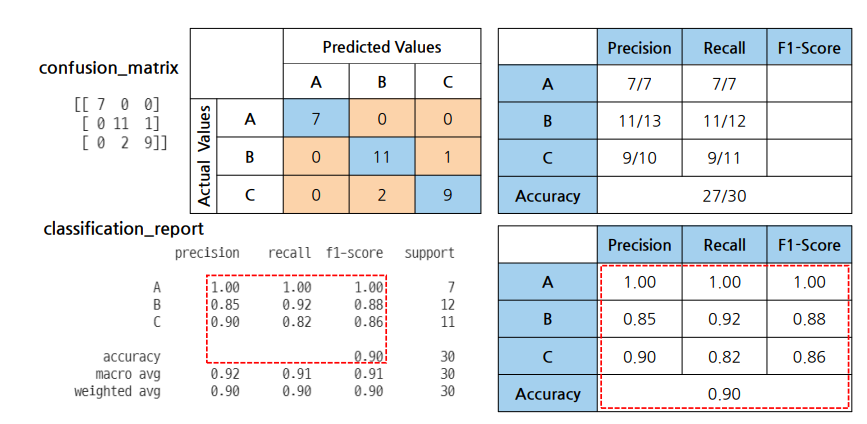
혼동 행렬: confusion Matrix
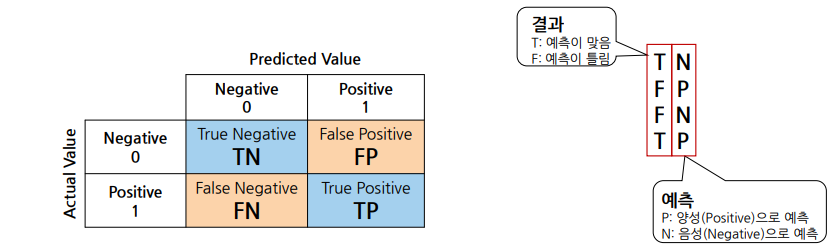
• TN(True Negative, 진음성): 음성으로 잘 예측한 것(음성을 음성이라고 예측한 것)
• FP(False Positive, 위양성): 양성으로 잘 못 예측한 것(음성을 양성이라고 예측한 것)
• FN(False Negative, 위음성): 음성으로 잘 못 예측한 것(양성을 음성이라고 예측한 것)
• TP(True Positive, 진양성): 양성으로 잘 예측한 것(양성을 양성이라고 예측한 것)

실습
# 모듈 불러오기
from sklearn.metrics import confusion_matrix
# 성능 평가
print(confusion_matrix(y_test,y_pred))
- 히트맵 시각화
plt.figure(figsize=(5,2))
sns.heatmap(confusion_matrix(y_test,y_pred),
annot=True,
cbar=False,
cmap='Blues')
plt.show()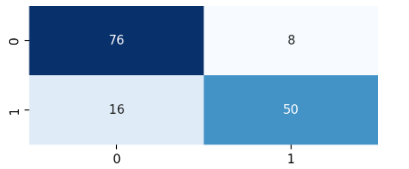
Accuracy : 정확도
- 정분류율 이라고 부르기도 함
- 전체 중에서 정확히 예측한 비율
- 가장 직관적으로 모델 성능을 확인할 수 있는 평가 지표
실습
# 모듈 불러오기
from sklearn.metrics import accuracy_score
# 성능 평가
print('정확도:',accuracy_score(y_test,y_pred))
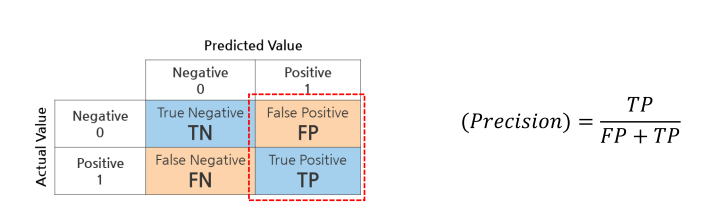
Precision : 정밀도
- Positive로 예측한 것(FP + TP) 중에서 실제 TP인 비율
- 예측 관점
실습
# 모듈 불러오기
from sklearn.metrics import precision_score
# 성능 평가
print(precision_score(y_test,y_pred,average=None)) #권고 : 0의 pre, 1의 pre
print(precision_score(y_test,y_pred))
print(precision_score(y_test,y_pred,average='binary')) # 기본값 1의 pre
print(precision_score(y_test,y_pred,average='macro')) # 평
print(precision_score(y_test,y_pred,average='weighted')) # 가중치 평균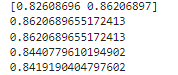
Recall : 재현율
- 실제 Positive (FN + TP) 중에서 positive로 예측한(TP) 비율
- 민감도(Sensitivity) 라고 부르는 경우가 많음
- 실제 관점
실습
# 모듈 불러오기
from sklearn.metrics import recall_score
# 성능 평가
print(recall_score(y_test, y_pred, average=None)) # 0, 1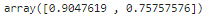
Specificity : 특이도
- 실제 Negative(TN+FP) 중에서 Negative로 예측한(TN) 비율
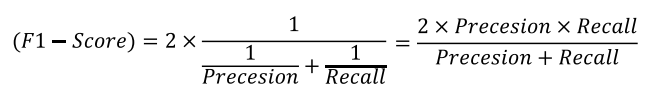
F1-Score
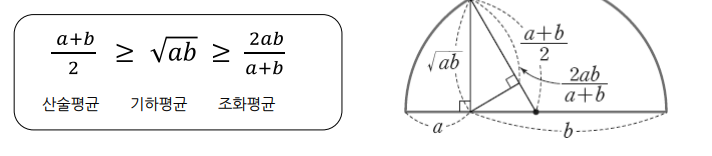
- 정밀도와 재현율의 조화 평균
- 분자가 같지만 분모가 다를 경우, 즉 관점이 다른 경우 조화 평균이 큰 의미를 가짐
- 정밀도와 재현율이 적절하게 요구될 때 사용
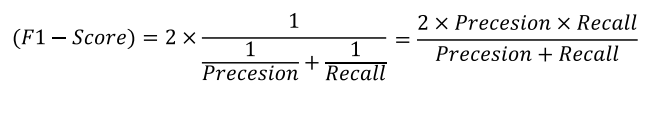
- 참고) 산술, 기하, 조화 평균 비교
실습
# 모듈 불러오기
from sklearn.metrics import f1_score
# 성능 평가
print(f1_score(y_test, y_pred, average=None))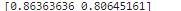
평가 지표
# 모듈 불러오기
from sklearn.metrics import classification_report
# 성능 평가
print(classification_report(y_test,y_pred))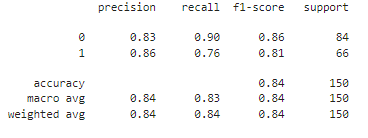

복습 복습 복습