네이버 증권 크롤링
https://finance.naver.com/research/company_list.naver
- 정적 페이지
1. 임포트
import requests
import pandas as pd
from bs4 import BeautifulSoup2. URL 저장
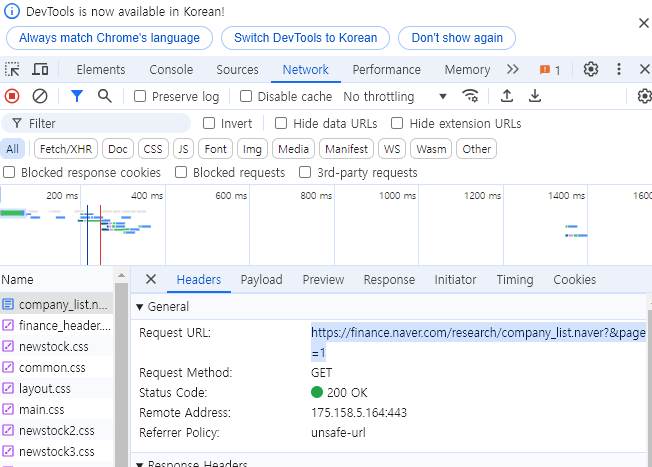
- 네트워크 가장 위의 것을 선택하여 URL 복사
# 1. URL
url='https://finance.naver.com/research/company_list.naver?&page=1'3. html 가져오기
# 2. request(URL) > response(HTML)
response = requests.get(url) #예시 페이지는 get방식으로 가져옴
response 
4. Parsing
HTML > BeautifulSoup > css-selector > DataFrame
4-1) HTML -> BeautifulSoup
# 첫번째 인자: response의 body를 텍스트로 전달
# 두번째 인자: "html"로 분석한다는 것을 명시
dom = BeautifulSoup(response.content,'html.parser')
type(dom) # select(), select_one()
4-2) BeautifulSoup -> css-selector
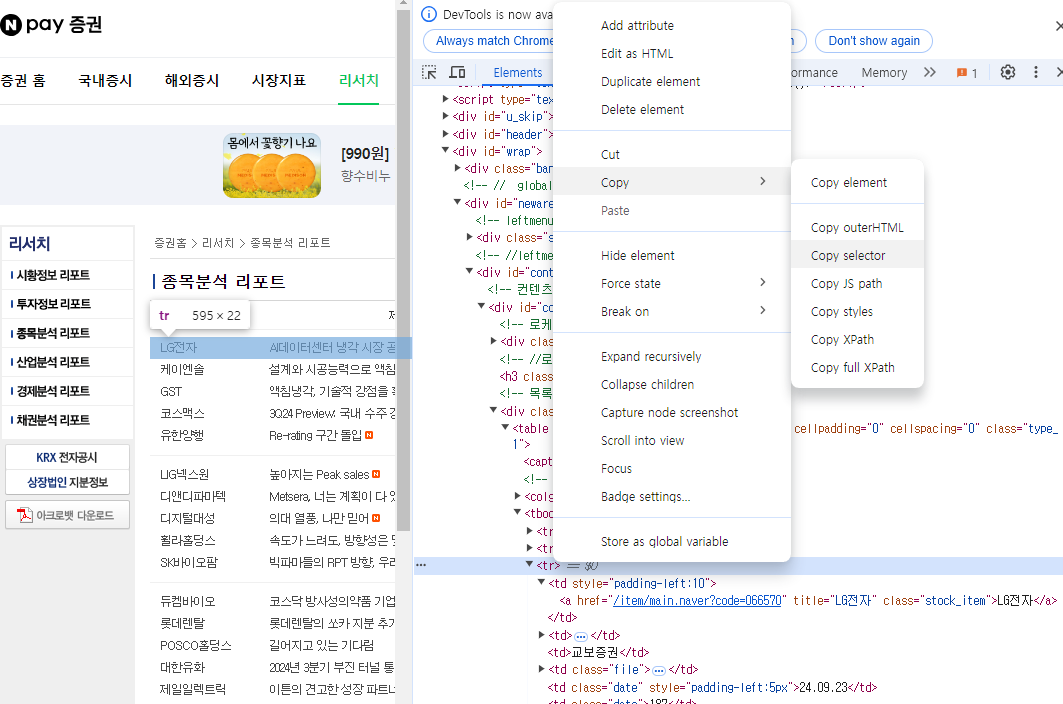
주의 : 개발자 도구의 copy - html selector을 너무 믿지 말자..(실제 소스와 개발자 도구 html의 코드가 다를 수 있다)
# html selector 오류 코드
# selector = '#contentarea_left > div.box_type_m > table.type_1 > tbody > tr:nth-child(3)'
selector = 'table.type_1 > tr'
elements = dom.select(selector)
len(elements)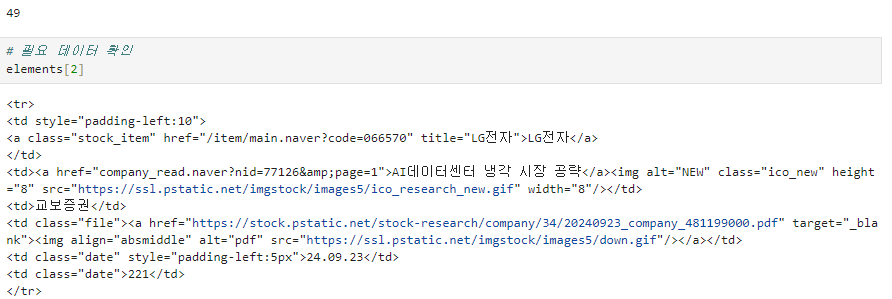
필요 태그 (tr 아래의 6개의 td 선택)
element = elements[2]
tag = element.select('td')
len(tag), tag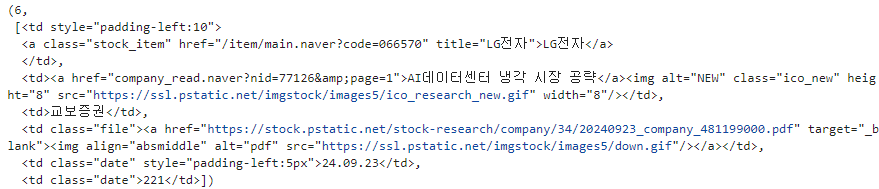
필요 엘리먼트 수집
data = {}
data['stock_name'] = tag[0].select_one('a').text #0번째 td태그 중 'a' 태그 선택
data['stock_link'] = tag[0].select_one('a').get('href') #해당 속성값 가져옴
data['title'] = tag[1].select_one('a').text
data['titme_link'] =tag[1].select_one('a').get('href')
data['writer'] = tag[2].text
data['pdf_link'] = tag[3].select_one('a').get('href')
data['date'] = tag[4].text
data['pv'] = tag[5].text
data
반복문을 이용하여 데이터 수집
tag != 6 이면 필요하지 않은 태그이기 때문에 제외한다.
# enumerate
rows = []
for idx, element in enumerate(elements):
tag = element.select('td')
print(idx, len(tag))
if len(tag) == 6:
data = {}
data['stock_name'] = tag[0].select_one('a').text #0번째 td태그 중 'a' 태그 선택
data['stock_link'] = tag[0].select_one('a').get('href') #해당 속성값 가져옴
data['title'] = tag[1].select_one('a').text
data['titme_link'] =tag[1].select_one('a').get('href')
data['writer'] = tag[2].text
data['pdf_link'] = tag[3].select_one('a').get('href')
data['date'] = tag[4].text
data['pv'] = tag[5].text
rows.append(data) 
4-3) css-selector > DataFrame
df = pd.DataFrame(rows)
df.tail(2)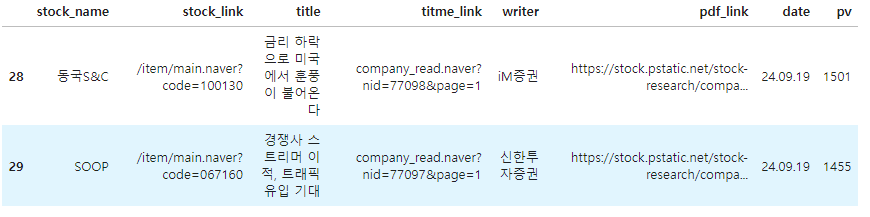
파일 다운받기
selenium
https://www.selenium.dev- 자동화를 목적으로 만들어진 다양한 브라우져와 언어를 지원하는 라이브러리
- 크롬 브라우져 설치
- 크롬 브라우져 드라이버 다운로드 (크롬 브라우져와 같은 버전)
- 다운로드한 드라이버 압축 해제
- chromedriver, chromedriver.exe 생성
- windows : 주피터 노트북 파일과 동일한 디렉토리에 chromedriver.exe 파일 업로드
- mac : sudo cp ~/Download/chromedirver /usr/local/bin
Selenium 4버전 이상에서는 크롬 드라이버를 따로 설치하지 않아도 된다
셀레니움 설치
#!pip install selenium
#!pip install webdriver_managerimport
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By# 직접 드라이버를 다운 받아서 설정
driver = webdriver.Chrome()from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager# 자동으로 본인 환경에 맞는 드라이버를 다운 받아서 설정
service = Service(ChromeDriverManager().install())driver = webdriver.Chrome(service=service)# 페이지 이동
driver.get('https://daum.net')# 브라우져 사이즈 조절
driver.set_window_size(200, 600)# 자바스크립트 코드 실행
driver.execute_script('alert("hello selenium!");')# alert 종료
alert = driver.switch_to.alert
alert.accept()# 검색어 입력
driver.find_element(By.CSS_SELECTOR, '#q').send_keys('selenium')By.CSS_SELECTOR# 검색버튼 클릭
driver.find_element(By.CSS_SELECTOR, '.btn_ksearch').click()# 브라우져 종료 : 자원(RAM)반환
driver.quit()xpath
- html element 선택하는 방법
- scrapy 에서는 기본적으로 xpath를 사용
scrapy 설치 및 임포트
!pip install scrapy
import scrapy
import requests
from scrapy.http import TextResponsexpath Selector
//*[@id="container"]/div[2]/ul/li[1]//: 최상위 엘리먼트*: 모든 하위 엘리먼트 : css selector의 한칸띄우기와 같다.[@id="value"]: 속성값 선택/: 한단계 하위 엘리먼트 : css selector의 >와 같다.[n]: nth-child(n)
Scrapy
Scrapy
- 웹사이트에서 데이터 수집을 위한 오픈소스 파이썬 프레임워크
- 멀티스레딩으로 데이터 수집
- daum news 데이터 수집
scrapy 설치 및 임포트
# !pip install scrapy
import scrapy, requests
from scrapy.http import TextResponse1. make project
!scrapy startproject news
!tree news
scrapy structure
- items : 데이터의 모양 정의
- middewares : 수집할때 header 정보와 같은 내용을 설정
- pipelines : 데이터를 수집한 후에 코드를 실행
- settings : robots.txt 규칙, 크롤링 시간 텀등을 설정
- spiders : 크롤링 절차를 정의
2. xpath
임포트
import scrapy, requests
from scrapy.http import TextResponseurl
url='https://news.daum.net/'
response = requests.get(url)
response = TextResponse(response.url, body=response.text, encoding='utf-8')
responsexpath
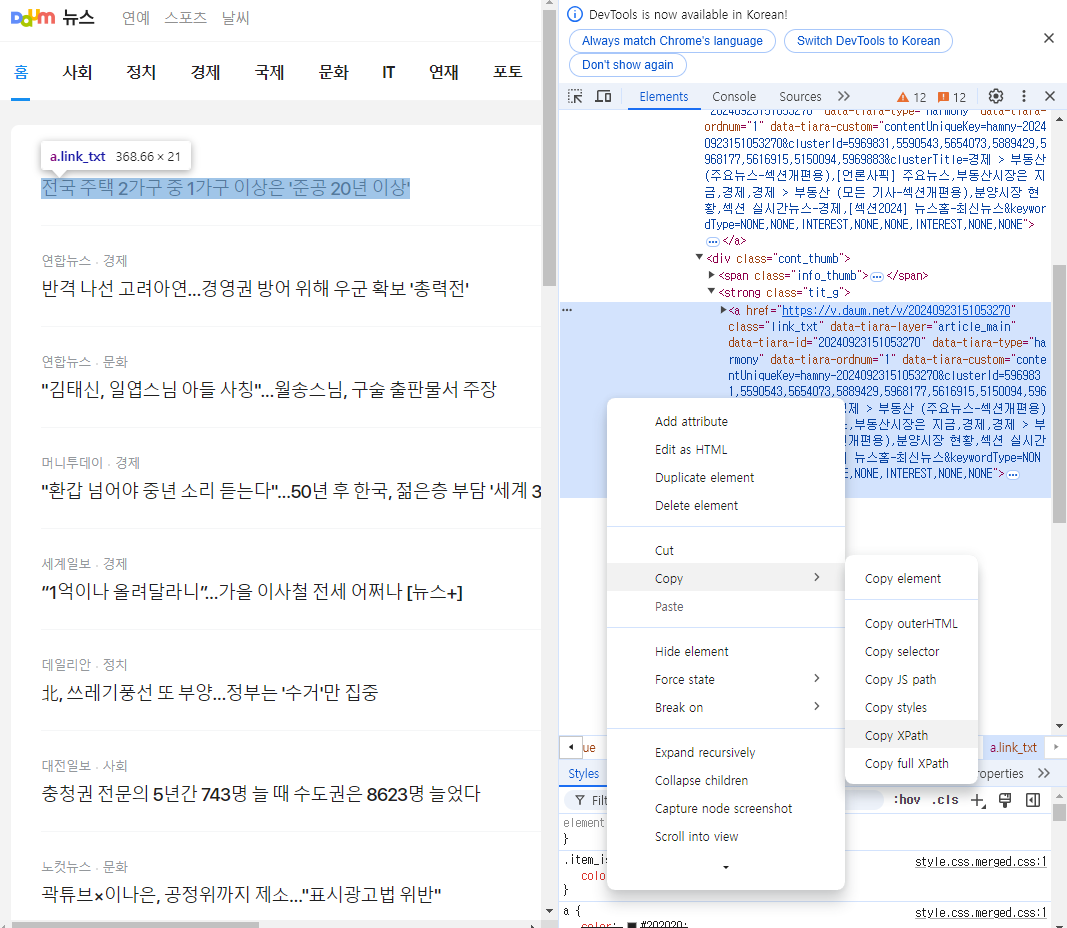
selector = '/html/body/div[2]/main/section/div/div[1]/div[1]/ul/li/div/div/strong/a/@href'
links = response.xpath(selector).extract()
len(links), links[:3]링크안 데이터 가져오기
link=links[0]
response = requests.get(link)
response = TextResponse(response.url, body=response.text, encoding='utf-8')
response
4-2) 기사 제목 가져오기
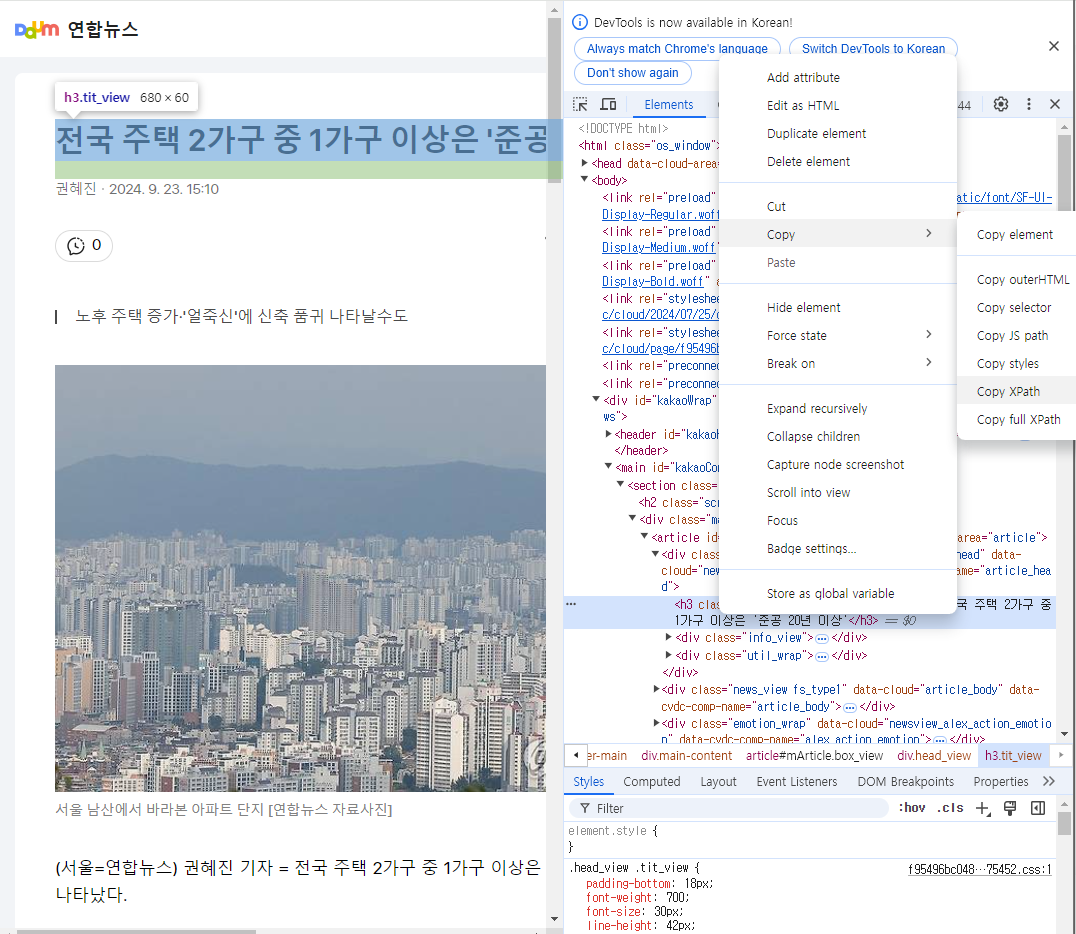
# 기사 제목 가져오기
title = response.xpath('//*[@id="mArticle"]/div[1]/h3/text()')[0].extract()
title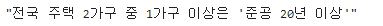
xpath
- html element 선택하는 방법
- scrapy 에서는 기본적으로 xpath를 사용
- syntax
- // : 최상위 엘리먼트
- * : 모든 하위 엘리먼트 : css selector의 한칸띄우기와 같다.
- [@id="value"] : 속성값 선택
- / : 한단계 하위 엘리먼트 : css selector의 >와 같다.
- [n] : nth-child(n)
3. items.py
- Data Model
# %load news/news/items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class NewsItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass오버라이딩
%%writefile news/news/items.py
import scrapy
class NewsItem(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()4. spider.py
- wirte crawling process
%%writefile news/news/spiders/spider.py
# 모듈 임포트
import scrapy
from news.items import NewsItem
#스파이더 클래스 정의
class NewsSpider(scrapy.Spider):
name = 'news' #스파이더의 이름
allow_domain = ['daum.net'] #크롤링을 허용할 도메인
start_urls = ['https://news.daum.net'] #크롤링을 시작할 URL을 정의
# 초기 응답을 처리 메서드
def parse(self, response):
#Path 표현식으로, 뉴스 기사 링크를 선택
selector = '/html/body/div[2]/main/section/div/div[1]/div[1]/ul/li/div/div/strong/a/@href'
#선택된 링크들을 추출
links = response.xpath(selector).extract()
#각 링크에 대해 scrapy.Request를 생성하고, parse_content 콜백 메서드를 호출
for link in links:
yield scrapy.Request(link, callback=self.parse_content)
#각 뉴스 기사 페이지의 내용을 처리
def parse_content(self, response):
item = NewsItem()
item['link'] = response.url
item['title'] = response.xpath('//*[@id="mArticle"]/div[1]/h3/text()')[0].extract()
yield item #item 객체를 반환- scrapy.Request는 Scrapy가 특정 URL을 요청하도록 지시하는 객체
- 콜백 메서드 호출: 각 요청에 대해 응답을 받으면 parse_content 메서드를 호출하여 해당 페이지의 내용을 처리
5. run scrapy
- news 디렉토리에서 아래의 커멘드 실행
- scrapy crawl news -o news.csv
+) yeild
- 함수가 값을 반환하고 함수의 상태를 유지한 채로 일시 중지할 수 있게 함
- 함수는 다음 호출 시 중단된 지점부터 실행을 재개
def generator_example():
yield 1
yield 2
yield 3
gen = generator_example()
print(next(gen)) # 1
print(next(gen)) # 2
print(next(gen)) # 3
- 이 예제에서 generator_example 함수는 yield를 사용하여 값을 생성.
- next 함수를 호출할 때마다 함수는 중단된 지점부터 실행을 재개

복습 복습 복습