API 통신
Naver API 사용해보기 (통합검색어 트렌드 API)
https://datalab.naver.com/
https://datalab.naver.com/keyword/trendSearch.naver
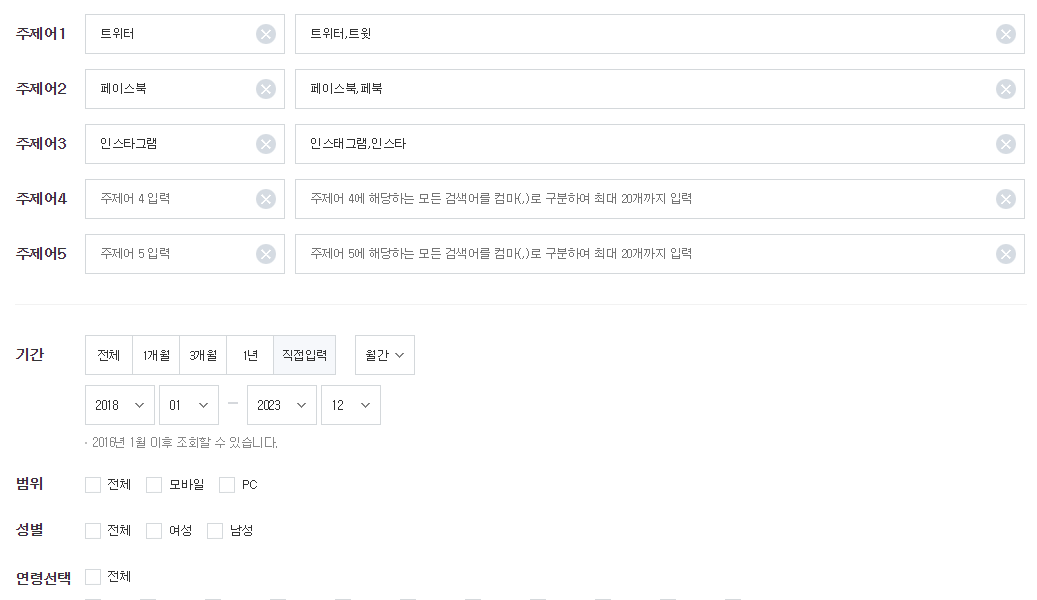
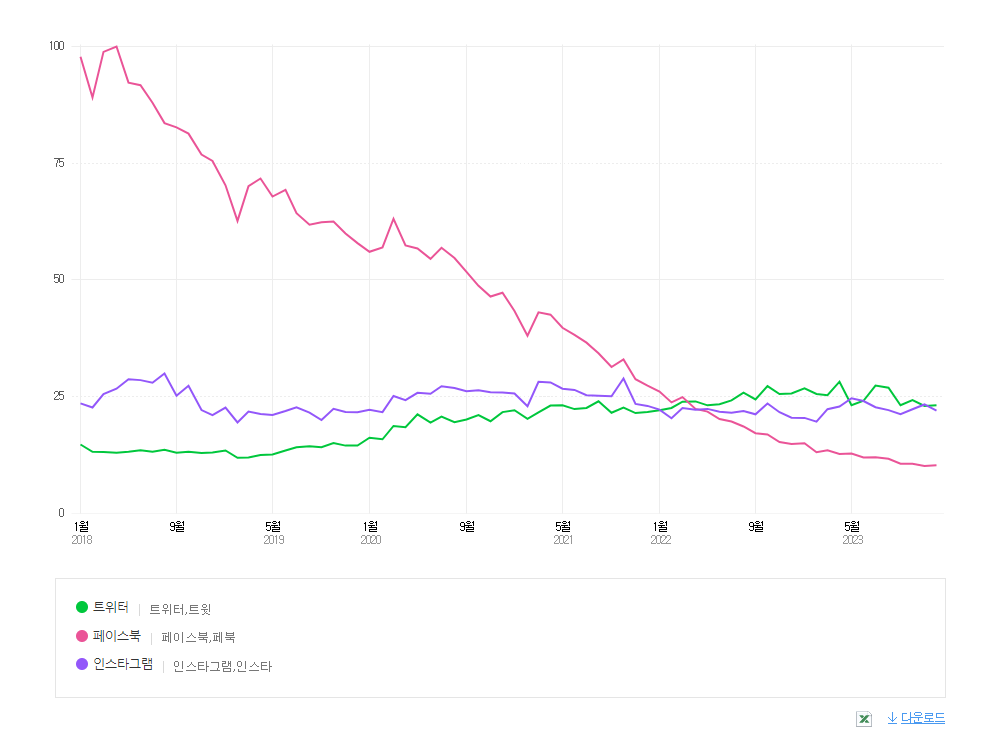
위의 데이터를 파이썬을 이용하여 크롤링 해보자
1. 패키지 임포트
import pandas as pd
import requests
import json2. Request Token 얻기
API를 사용하기 위해서는 로그인을 하고, 어플리케이션을 등록하여 네이버 WAS 측에서 key를 부여받아 헤더에 담아 요청하여야 데이터를 받아올 수 있다.
- 네이버 개발자 센터에 로그인
- 어플리케이션을 등록하여 클라이언트 ID와 클라이언트 시크릿을 발급.
- API 요청 시, 발급받은 클라이언트 ID와 클라이언트 시크릿을 헤더에 포함
CLIENT_ID = '발급받은 아이디'
CLIENT_SECRET = '발급받은 키'3. 통합 검색어 트렌드 API 사용하기
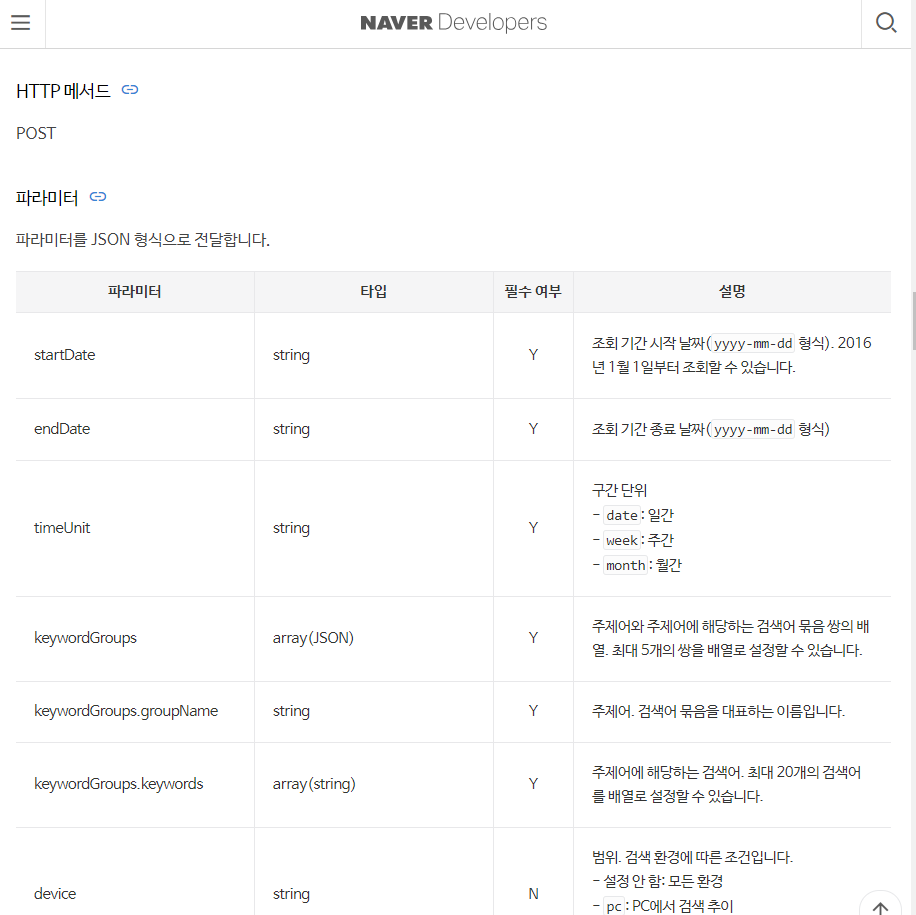
documents에 들어가보면 필요 파라미터의 설명이 나와있다.
# 1. URl
url = 'https://openapi.naver.com/v1/datalab/search'
# 2. request > response(json)
#파라미터 설정 (JSON 형태)
params={
'startDate' : '2018-01-01',
'endDate' : '2023-12-31',
'timeUnit' : 'month',
'keywordGroups' : [
{'groupName' : '트위터', 'keywords' : ['트위터','트윗'] },
{'groupName' : '페이스북', 'keywords' : ['페이스북','페북'] },
{'groupName' : '인스타그램', 'keywords' : ['인스타그램','인스타'] },
]
}
# http 요청 헤더
headers = {
'Content-Type' : 'application/json',
'X-Naver-Client-Id' : CLIENT_ID,
'X-Naver-Client-Secret' : CLIENT_SECRET,
}
# 한글을 요청할때는 json.dumps() 사용
response=requests.post(url,data=json.dumps(params),headers=headers)
response
# 3. parsing
data=response.json()['results']
#data
# 4. preprocessing 데이터 전처리
dfs=[]
for row in data :
df=pd.DataFrame(row['data'])
df['title']=row['title']
dfs.append(df)
# len(dfs), dfs[2]
result = pd.concat(dfs, ignore_index=True)
result.tail(2)
+ ) pivot 이용하기
pivot_df = result.pivot(index='period', columns='title', values='ratio')
pivot_df.tail(2)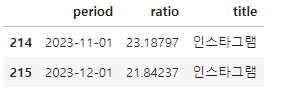
5. 시각화
# 시각화
import matplotlib.pyplot as plt
pivot_df.plot(figsize=(20, 5))
plt.show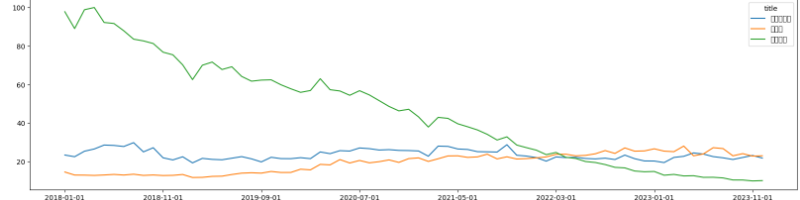
Zigbang 원룸 매물 데이터 수집
1. 패키지 임포트
import requests
import pandas as pd데이터 수집
URL 디코더/인코더 사이트 :
https://apis.zigbang.com/v2/search?leaseYn=N&q=%EB%A7%9D%EC%9B%90%EB%8F%99&serviceType=%EC%9B%90%EB%A3%B8
- 동이름으로 위도 경도 구하기
addr = '망원동'
url = f'https://apis.zigbang.com/v2/search?leaseYn=N&q={addr}&serviceType=원룸'
response = requests.get(url)
#response
data = response.json()['items'][0]
lat, lng = data['lat'], data['lng']
lat, lng #위도, 경도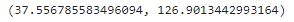
- 위도 경도로 geohash 알아내기
# geohash2 설치
!pip install geohash2
import geohash2
geohash=geohash2.encode(lat,lng,precision=5) # 숫자가 커질수록 더 작은 영역
geohash- geohash로 매물 아이디 가져오기
# 데이터 수집
url=f'https://apis.zigbang.com/v2/items/oneroom?geohash={geohash}&depositMin=0&rentMin=0&salesTypes[0]=전세&salesTypes[1]=월세&domain=zigbang&checkAnyItemWithoutFilter=true'
response = requests.get(url)
#response
# 매물 아이디 가져오기
item_ids = [data['itemId'] for data in response.json()['items']]
len(item_ids),item_ids[:5]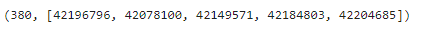
- 매물 아이디로 매물 정보 가져오기
url = f'https://apis.zigbang.com/v2/items/list'
params={
'domain': 'zigbang',
'item_ids' : item_ids
}
response=requests.post(url,params)
#response
#parsing
pd.options.display.max_rows=500
pd.options.display.max_columns=40 # 출력 컬럼 수 설정
data=response.json()['items']
df=pd.DataFrame(data)
df = df[df['address1'].str.contains(addr)].reset_index(drop=True)
df=df[['sales_title', 'deposit', 'rent', 'size_m2','floor','building_floor','title','manage_cost','address1']]
df.tail(3)
함수로 만들기
# 5. function
def oneroom(addr):
url = f'https://apis.zigbang.com/v2/search?leaseYn=N&q={addr}&serviceType=원룸'
response = requests.get(url)
data = response.json()['items'][0]
lat, lng = data['lat'], data['lng']
geohash = geohash2.encode(lat, lng, precision=5)
url = f'https://apis.zigbang.com/v2/items/oneroom?geohash={geohash}&depositMin=0&rentMin=0&salesTypes[0]=전세&salesTypes[1]=월세&domain=zigbang&checkAnyItemWithoutFilter=true'
response = requests.get(url)
item_ids = [data['itemId'] for data in response.json()['items']]
url = 'https://apis.zigbang.com/v2/items/list'
params = {'domain': "zigbang", 'item_ids': item_ids[:900]}
response = requests.post(url, params)
data = response.json()['items']
df = pd.DataFrame(data)
return df[['item_id', 'sales_title', 'deposit', 'rent', 'size_m2', 'floor', 'building_floor', 'title','manage_cost', 'address1']]
df=oneroom('개포동')
df.tail(2)
HTML
태그
- div : 레이아웃
- h1 ~ 6 : 제목 문자열 출력
- p : 한줄 문자열 출력
- span : 한 블럭 문자열 출력
- ul li : 메뉴 목록 출력
- a : 페이지 이동 : href(url)
- img : 이미지 출력 : src(url)
CSS - Selector
CSS 스타일을 적용시킬 HTML 엘리먼트를 찾기 위한 방법
element 선택 방법
-
tag : 가장 위 tag 선택
-
id : #(id)
-
class : .(class)
-
attribute : [val='...']
-
. : and : ex) p.n1
-
, : or : ex) .n1, .n2
-
nth-child(n) : 엘리먼트로 감싸져있는 n번째 엘리먼트가 설정한 셀렉터와 일치하면 선택 (1부터 시작)
-
> : 한단계 아래 : ex) div > p.n1
-
공백 : 모든 하위 : ex) div p

복습 복습 복습