Keras
-
Deep Learning Framework
-
- Sequential API
-
- Functional API : 모델링에 유연
Fully-Connected : FC
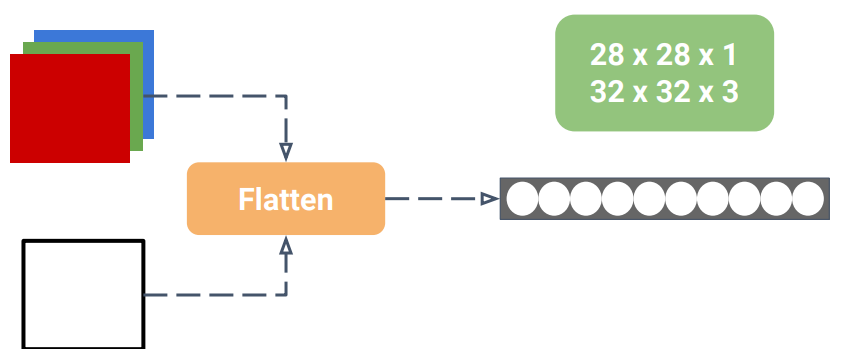
- 완전 연결 레이어 라고도 불림 ( 뉴런 하나 하나 모두 연결)
- Input 노드와 Output 노드가 모두 연결되어 있는 1차원 레이어를 의미
- 2차원 이미지에 FC Layer을 적용하려면 1차원 벡터로 변환하는 Flatten 과정이 필요
- activation = 'relu' : 선형 -> 비선형 변경
- +) relu : 0 이하는 0, 0 이상은 그대로 반환
- 흑백 이미지에서는 어느정도 성능이 나오나
- 하지만 컬러 값을 가지는 3차원 이미지라면 위치 정보를 손실함
CNN : Convolutional Neural Networks (합성곱 신경망)
-
이미지 데이터 구조를 그대로 사용하는 접근
-
한꺼번에 Feature의 개성을 고려하기 보다, 지역별 개성을 살려서 feature을 추출
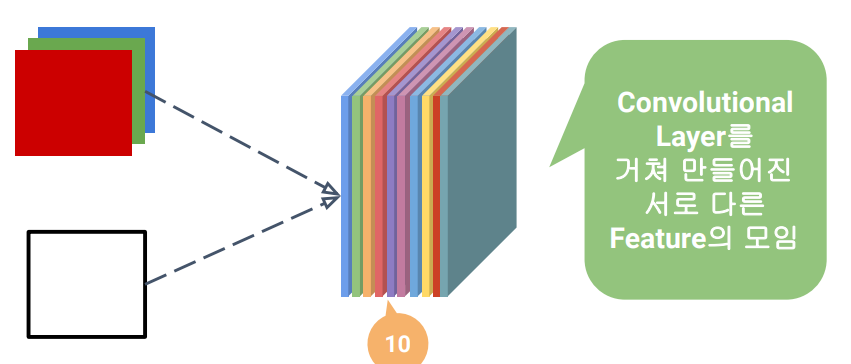
-
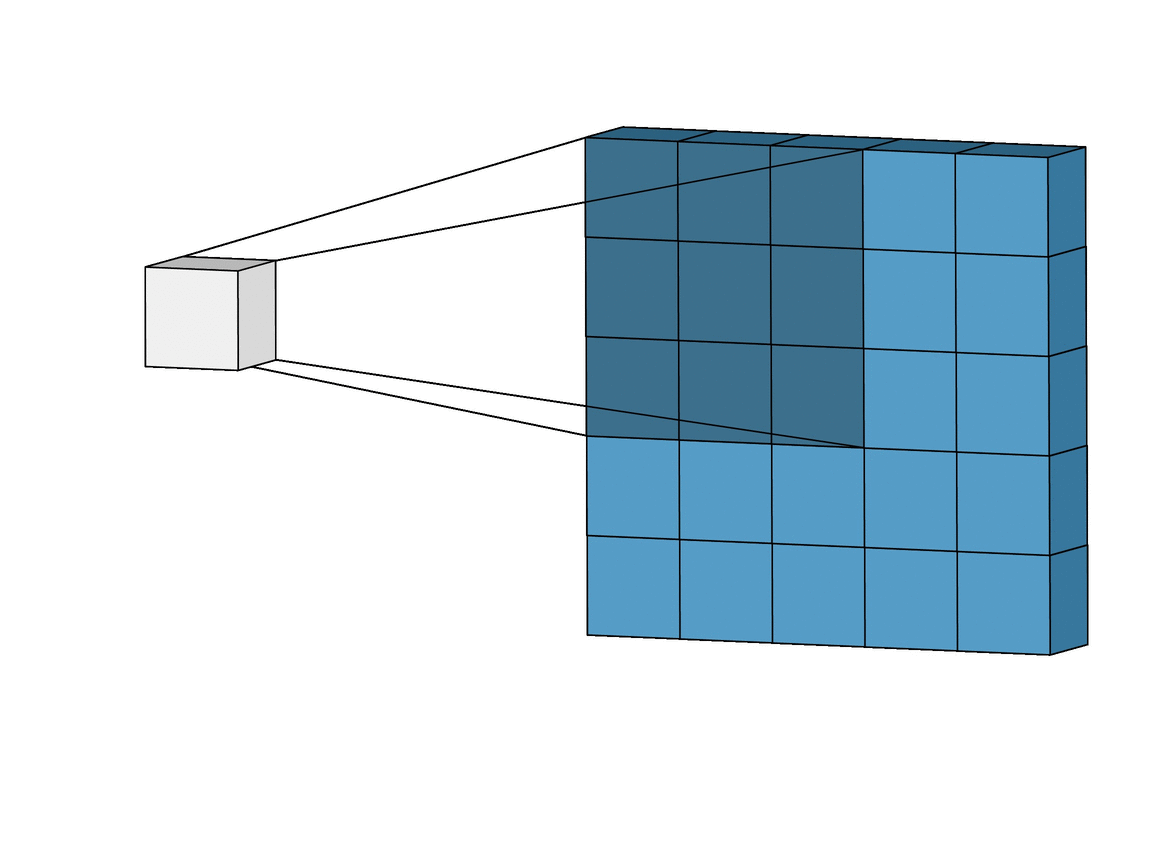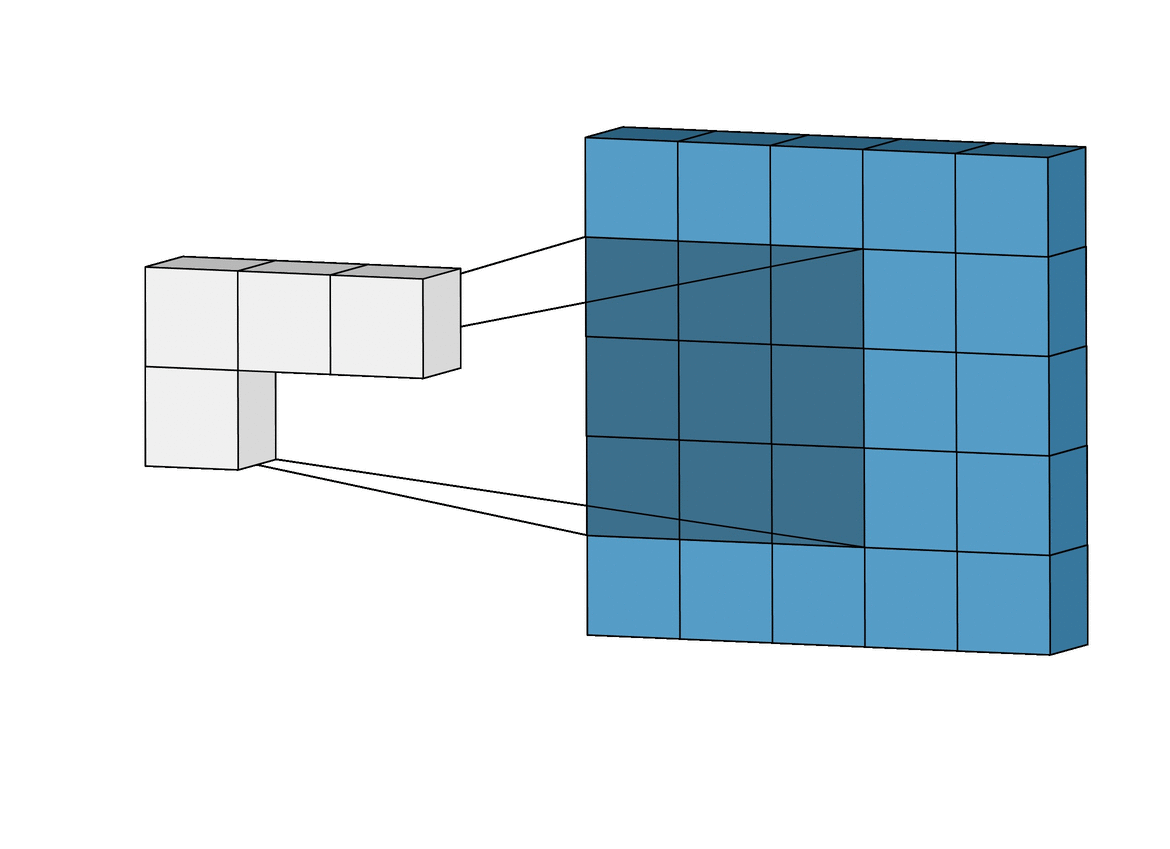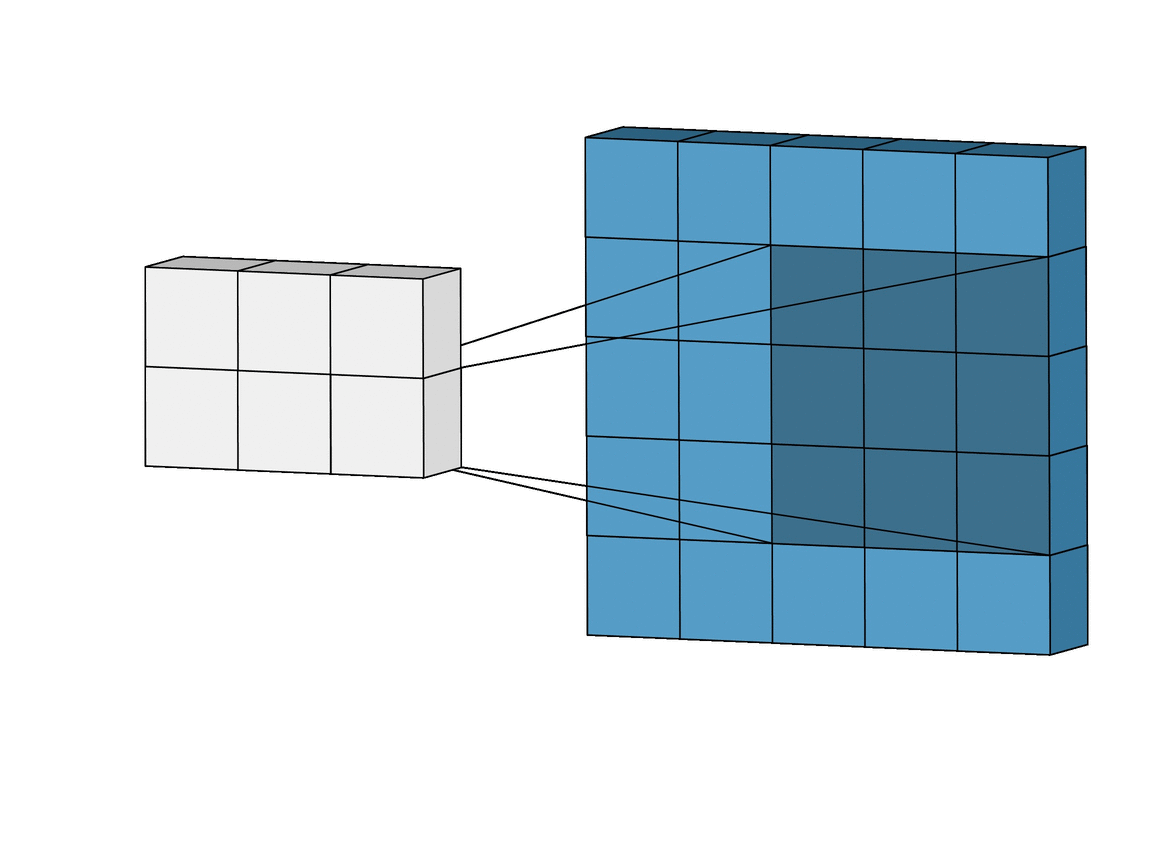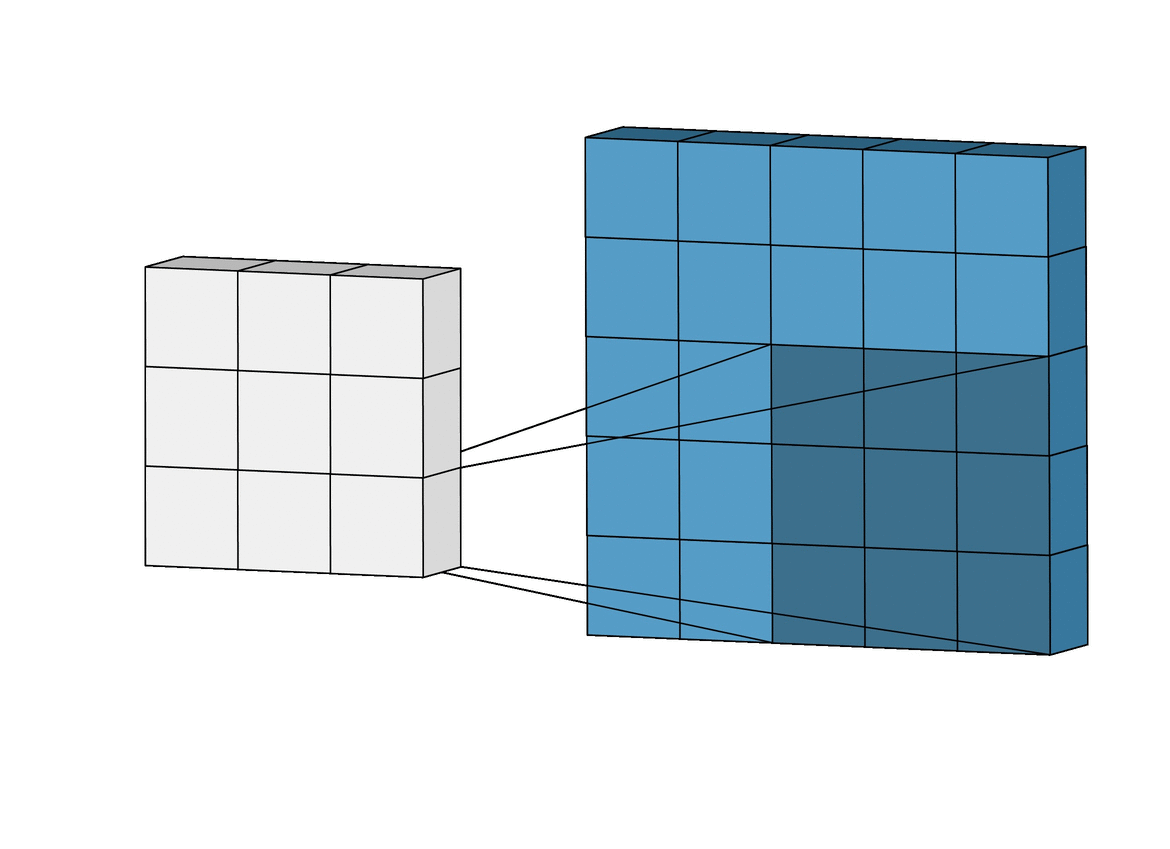
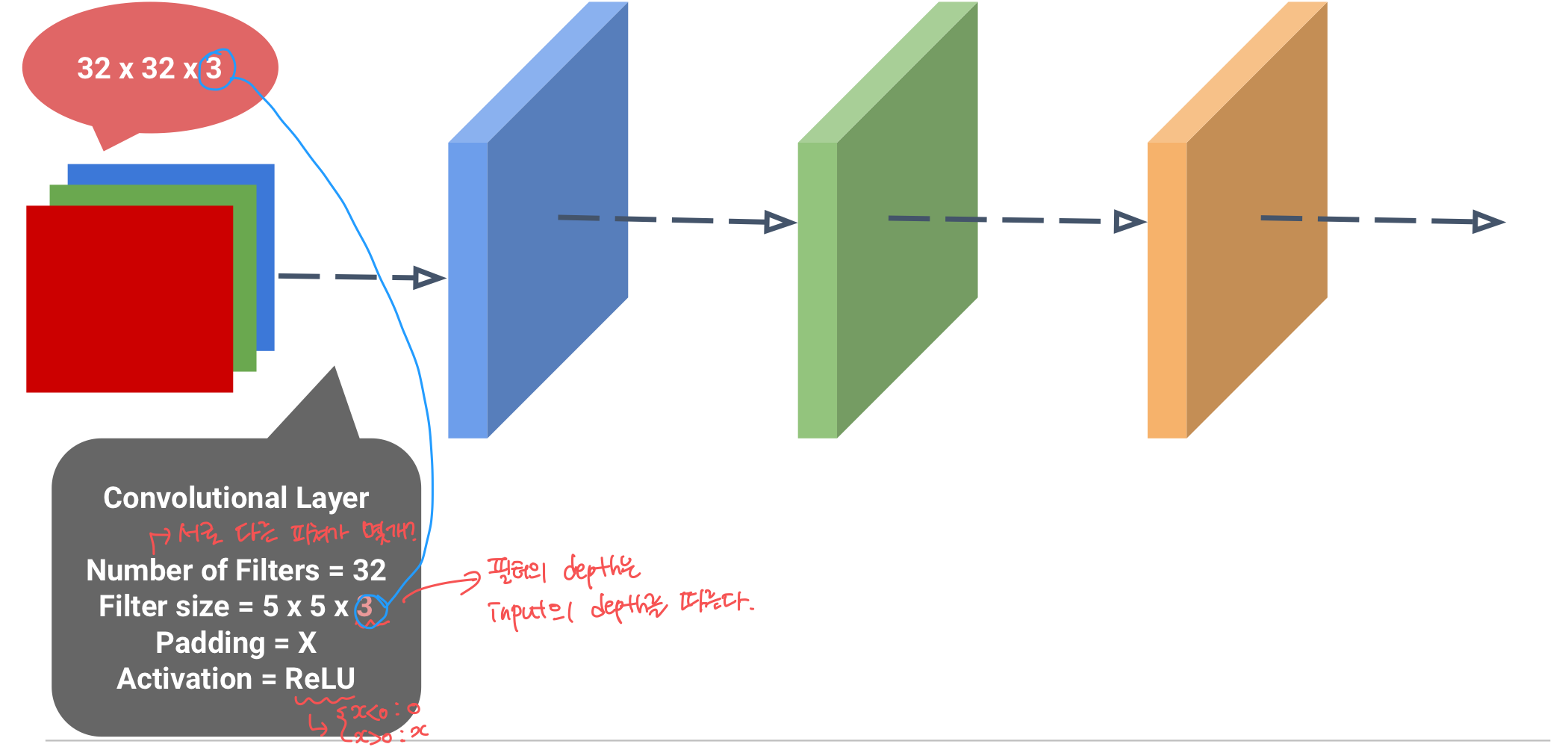
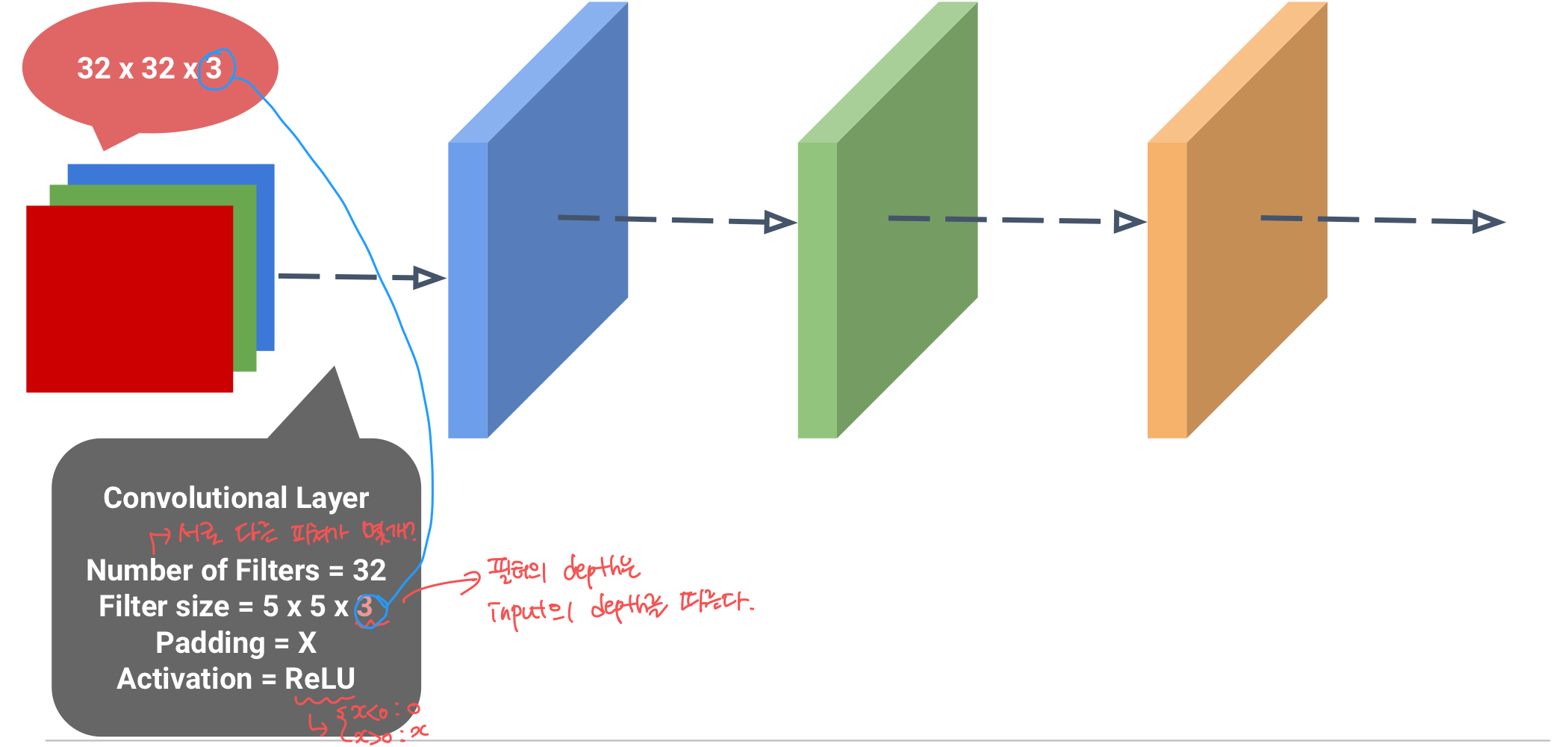
Filter 동작
-
feature map : 이미지 특징을 추출한 map
-
filter (=kernel) : 이미지로부터 내가 원하는 특징만 추출한 것
- filter는 이미지 데이터를 지정된 간격으로 움직이며 합성곱 계산을 수행
- filter을 거쳐 또 새로운 feature map이 생성되어 다음 filter의 input이 된다.
- 랜덤한 가중치를 가짐
- input의 depth를 filter의 depth가 따라간다
🌟 파라미터
- filter : 서로 다른 feature을 추출하는 필터를 몇개 생성? or 새롭게 제작하려는 feature map의 수(depth)
- kernel_size : 필터의 크기
- strides : filter가 이동하는 간격
- padding : filter 적용 전, 보존하려는 feature map 크기에 맞게, 입력 feature map의 상하좌우 각각 열과 행을 추가하여 0값을 채우는 것. (기본값 zero padding)
- Feature map 크기 유지
- 외각 정보 더 반영
| Stride =1, Zero Padding | 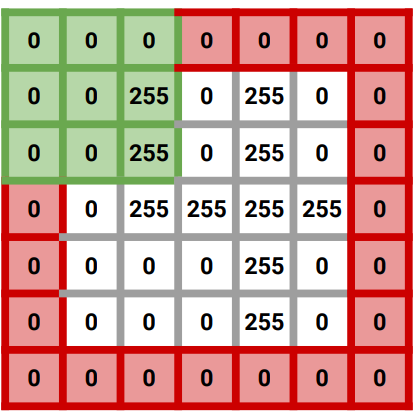 | 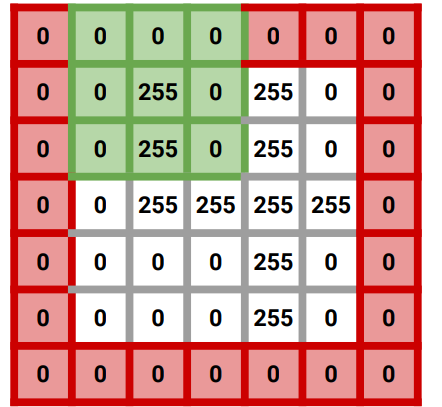 |
|---|
feature map 계산 수식

- 수식 결과가 정수가 아니더라도 Keras는 자동으로 보정
Pooling Layer
- feature map의 가로 세로만 영향을 주는 레이어.
- depth에는 영향을 주지 않음
- 연산량을 줄이기 위함
- max pooling | avg pooling
- max pooling : 국소적인 영역에서 max 값만 가져옴
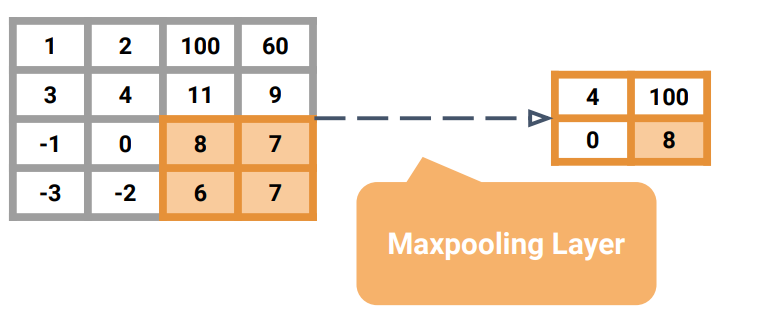
🌟 파라미터
- pool_size : pooling 필터 크기
- strides : pooling 필터 이동 방법
FC 실습 : notMNIST
- 데이터 로드
data = io.loadmat('notMNIST_small.mat')
data
x = data['images']
y = data['labels']
x.shape, y.shape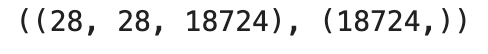
-
채널수 reshape

-
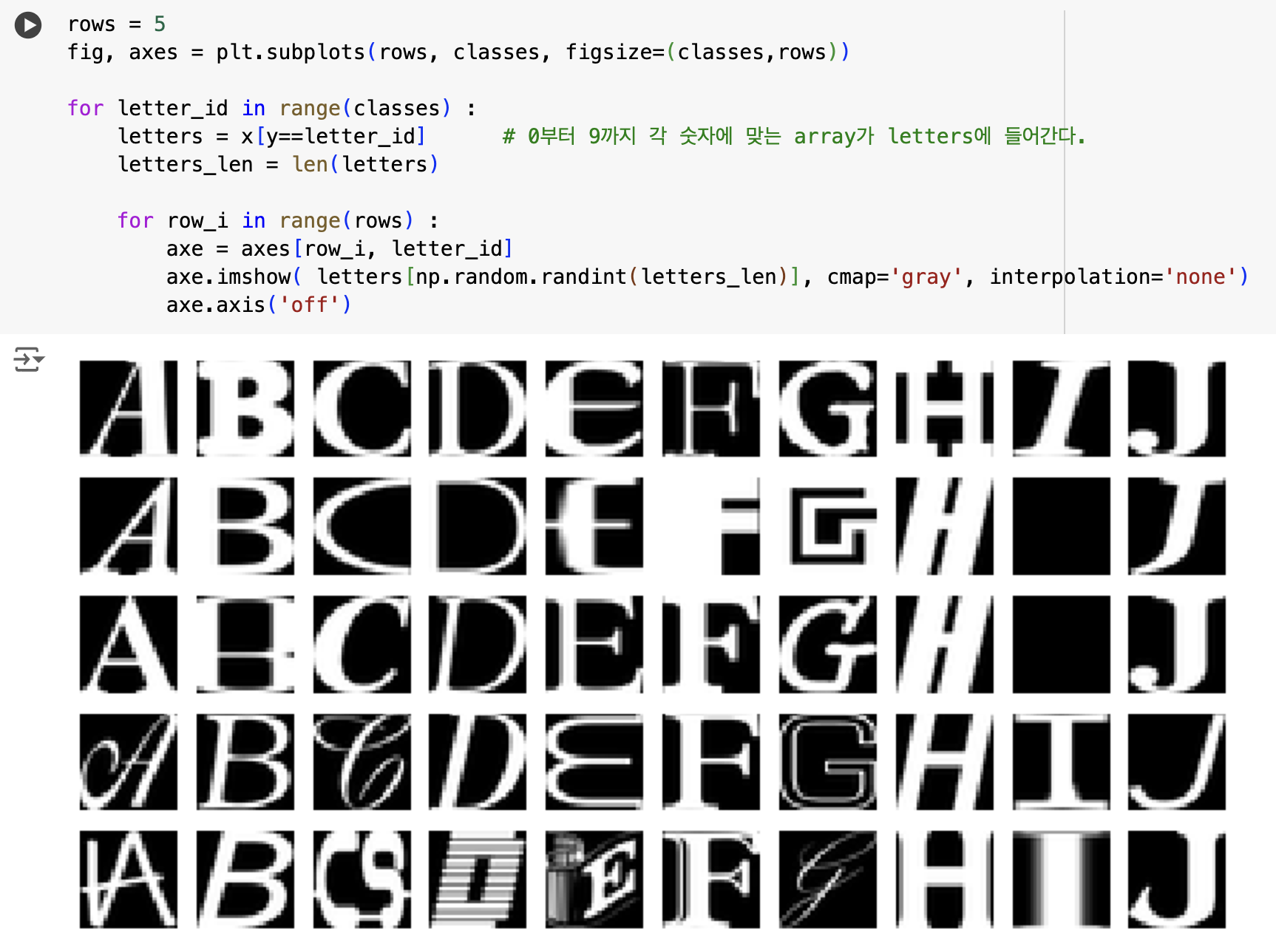
데이터 살펴보기
- 데이터 전처리
- data split

- 스케일링 (min-max scaling)

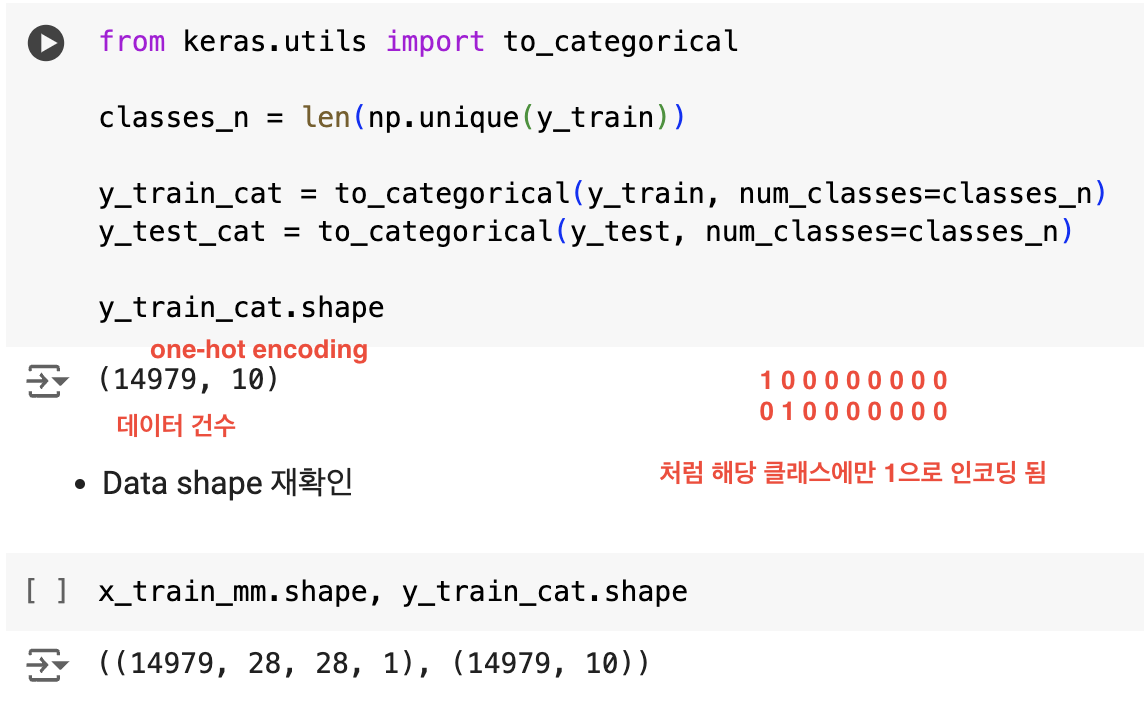
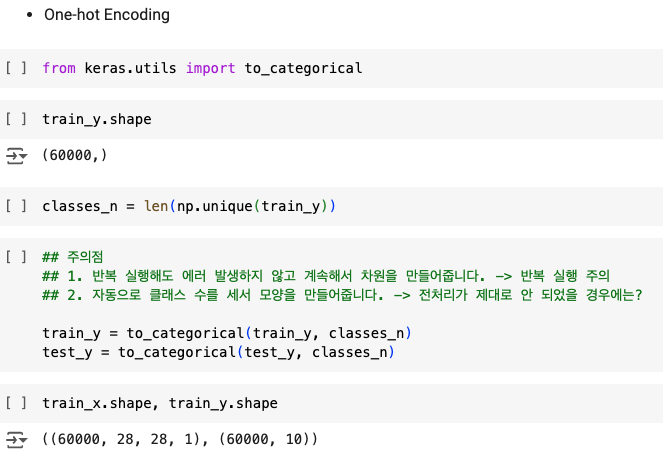
- one-hot encoding
- 반복 실행 주의
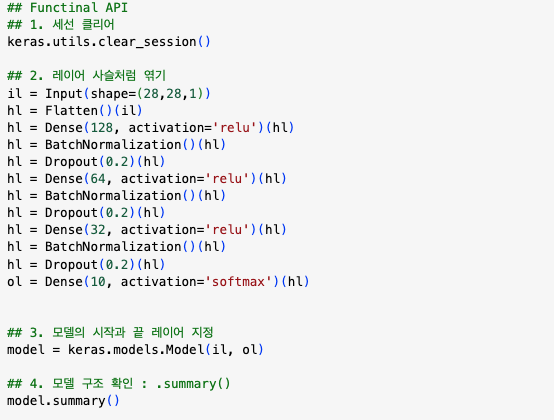
- 모델링
- Sequentail API


- Functional API
- 컴파일

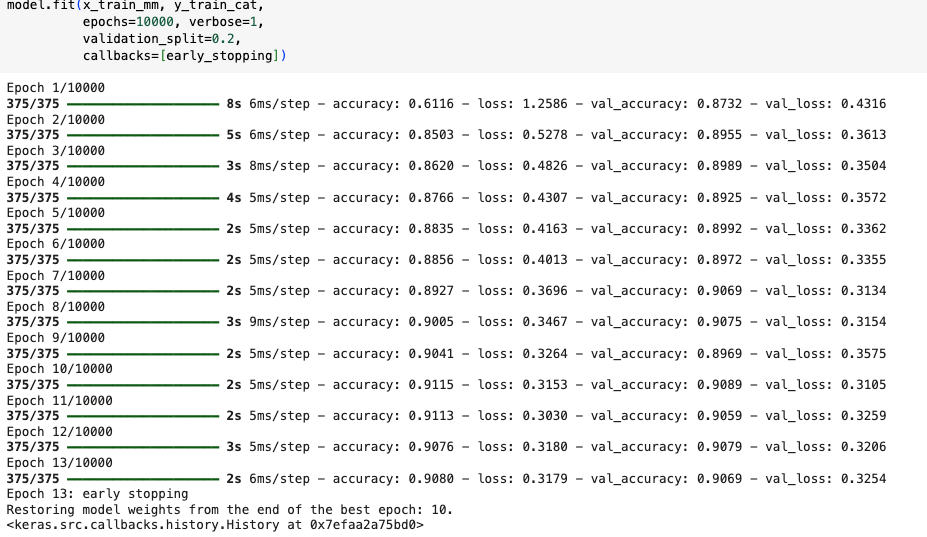
- Early Stopping

-
fit
-
predict
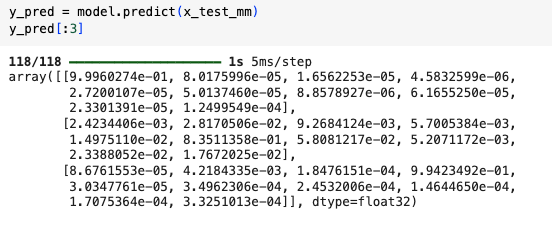
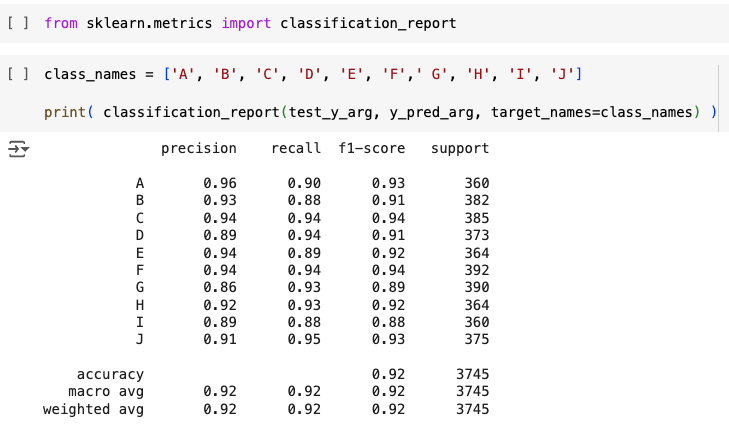
- 평가
CNN 실습 : MNIST
- 데이터 준비
- 케라스 업데이트
- 라이브러리 로딩
- 데이터 셋
- keras에서 자체적으로 mnist 데이터를 제공


- keras에서 자체적으로 mnist 데이터를 제공
- Convolutional Layer를 사용하기 위한 reshape

-
스케일링

-
one-hot encoding
- 모델링
-
모듈 불러오기

-
모델링 Sequential API
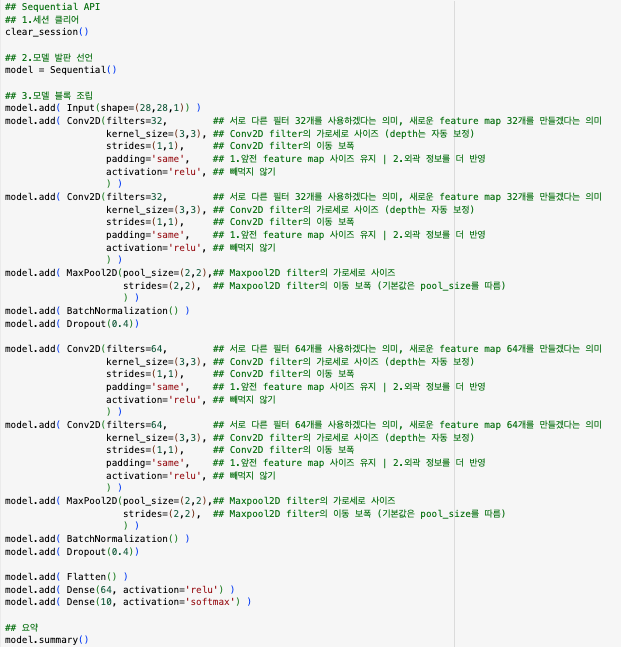
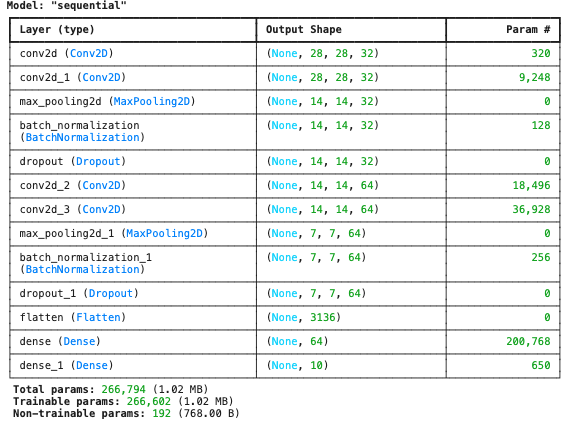
-
Functional API

-
컴파일

-
Early Stopping

+) batch_size : 전체 데이터셋을 쪼갠, 모델이 한 번에 처리하는 데이터 샘플의 개수.
+) epochs : 전체 학습 데이터셋을 모델이 한 번 학습한 것
BatchNormalization
- 모델 성능을 높이기 위한 테크닉
- 입력 데이터에 대해 각 채널마다 평균과 표준 편차를 계산
- 이 평균과 표준 편차를 사용하여 정규화를 수행하고, 스케일링과 이동을 수행하여 결과를 출력
- 입력 텐서의 각 배치에 대해 정규화를 수행
- 정규화를 통해 과적합(overfitting) 문제를 방지

복습 복습 복습