
Seq2Seq(Sequence-to-sequence)
Seq2Seq 모델은 한 시퀀스를 다른 시퀀스로 변환해주는 딥러닝 모델이다. 자연어 처리 분야에서 주로 사용되며, RNN이나 LSTM을 어떻게 조립하느냐에 따라서 Seq2Seq 구조가 만들어진다.
Seq2Seq 구조
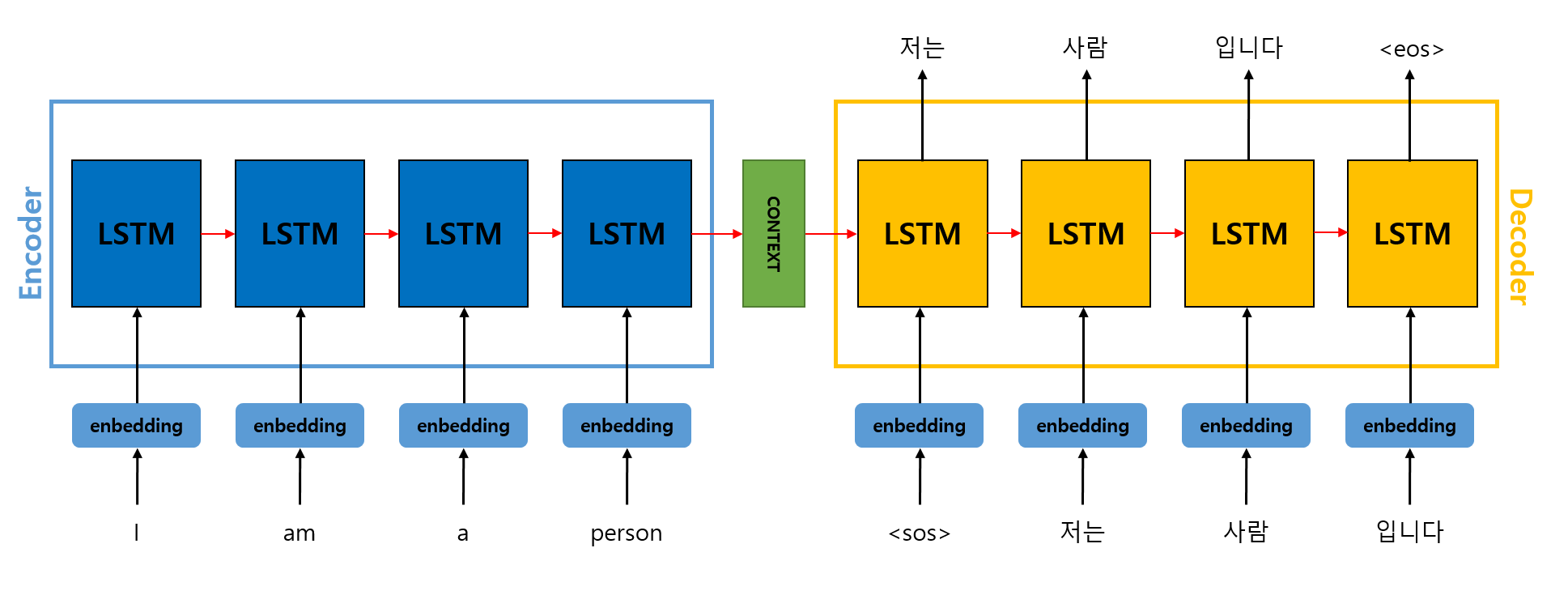 기본적인 Seq2Seq 구조는 그림과 같다. Encoder와 Decoder로 이루어져 있고, 요즘은 RNN 대신 LSTM으로 대체되는 경향이라고 한다.
기본적인 Seq2Seq 구조는 그림과 같다. Encoder와 Decoder로 이루어져 있고, 요즘은 RNN 대신 LSTM으로 대체되는 경향이라고 한다.
모든 정보를 내포하고 있는 Encoder 마지막 시점의 Context vector를 Decoder의 첫 셀의 첫 Context Vector로 넣어준다. 즉, Encoder 마지막 step에서의 hidden state가 Decoder 첫 step의 hidden state로 입력되게 된다. 실제 Context vector는 수백 이상의 차원을 갖고 있다.
Encoder에 입력되는 단어 토큰들은 임베딩 벡터로 변환된 후에 입력되게 된다.
Train 과정
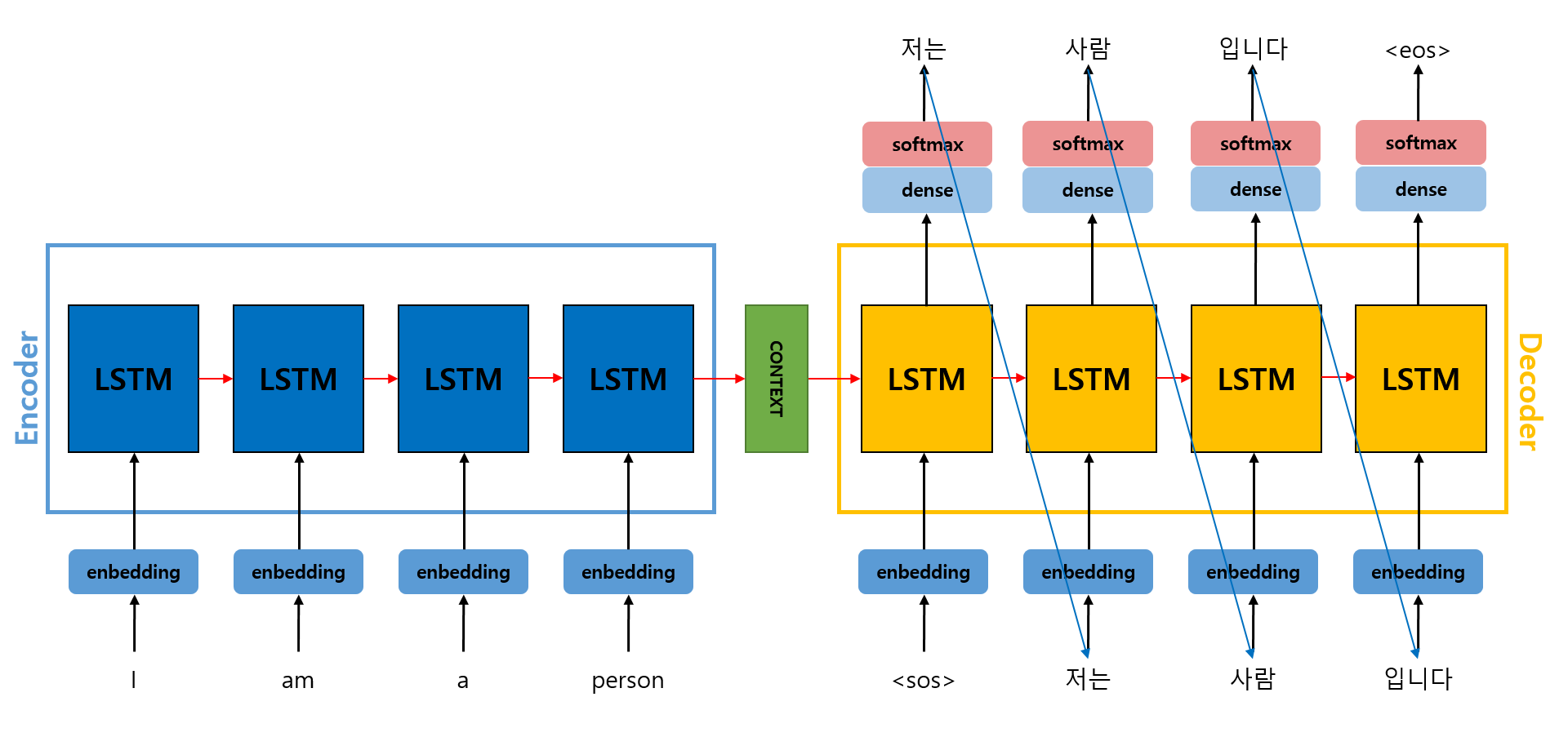 학습과정은 위 그림과 같다. Decoder의 output 토큰의 선정기준은 softmax를 통해 가장 높은 확률 값을 가진 토큰이 출력되게 되는 것이다. 예를 들어 '사람'이라는 토큰이 출력된 근거는 '나는'이라는 토큰 뒤에 '사람'이라는 토큰이 나올 확률이 제일 높았다는 것이다.
학습과정은 위 그림과 같다. Decoder의 output 토큰의 선정기준은 softmax를 통해 가장 높은 확률 값을 가진 토큰이 출력되게 되는 것이다. 예를 들어 '사람'이라는 토큰이 출력된 근거는 '나는'이라는 토큰 뒤에 '사람'이라는 토큰이 나올 확률이 제일 높았다는 것이다.
파란색 화살표를 보면 알 수 있듯이, Decoder의 input에 이전 시점의 output 토큰을 넣어준다.
 만약 '학생'이라는 토큰이 잘못 출력되어도 학습 과정에서는 정답 토큰인 '사람'을 다음 step의 입력에 그대로 넣어준다(Teacher forcing). 잘못된 토큰을 그대로 넣어주게 된다면 이후 step들에게 영향을 줘서 계속해서 잘못된 토큰을 출력하게 되기 때문이다.
만약 '학생'이라는 토큰이 잘못 출력되어도 학습 과정에서는 정답 토큰인 '사람'을 다음 step의 입력에 그대로 넣어준다(Teacher forcing). 잘못된 토큰을 그대로 넣어주게 된다면 이후 step들에게 영향을 줘서 계속해서 잘못된 토큰을 출력하게 되기 때문이다.
기존처럼 예측값과 정답값과의 Loss를 계산 후 역전파를 진행하여 학습을 진행하게 된다.
Test 과정
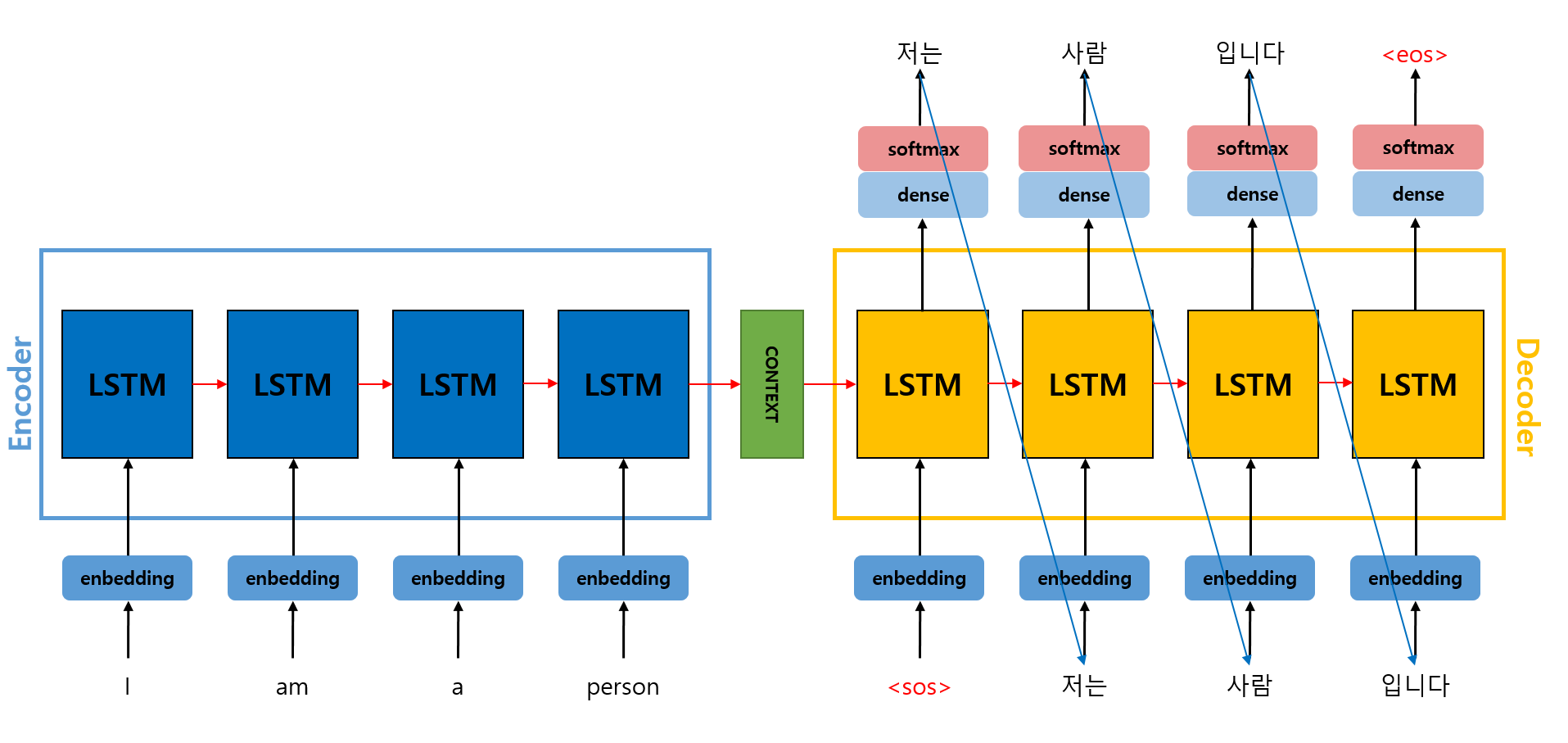 테스트 과정은 위의 학습 과정과 매우 유사하지만 잘못된 토큰이 출력되어도 다음 step에 입력에 그대로 넣어준다. Decoder의 첫 step에 (Start of sequence) 토큰이 입력된 이후 동일한 과정이 진행되게 되고, 이 과정은 (End of sequence) 토큰이 출력으로 나올 때 까지 진행된다(이는 학습 과정에서도 마찬가지이다).
테스트 과정은 위의 학습 과정과 매우 유사하지만 잘못된 토큰이 출력되어도 다음 step에 입력에 그대로 넣어준다. Decoder의 첫 step에 (Start of sequence) 토큰이 입력된 이후 동일한 과정이 진행되게 되고, 이 과정은 (End of sequence) 토큰이 출력으로 나올 때 까지 진행된다(이는 학습 과정에서도 마찬가지이다).
