Attention
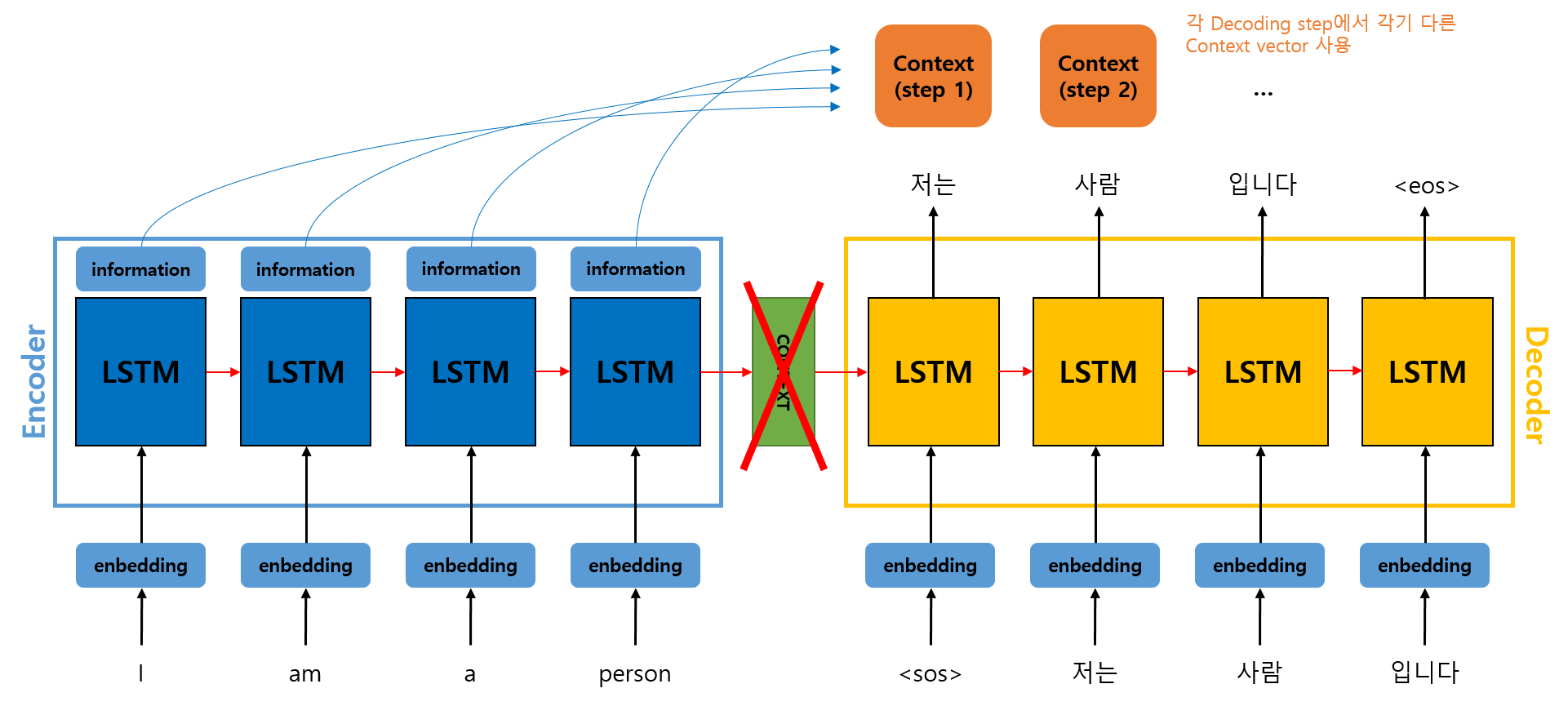
저번 포스팅에서 Seq2Seq 모델을 구현했었는데, 마지막에 알 수 있었던 사실이 있었다. 바로 입력 데이터의 Sequence 길이가 길어질수록 Accuracy가 증가한다는 것이다. Seq2Seq의 특성 상, 최종 Hidden state에서 앞쪽 입력 token에 대한 정보는 희미해진다. 즉, 입력 Sequence가 길어질수록 Context vector에서 입력에 대한 정보를 정확하게 압축할 수 없게되는 것이다.
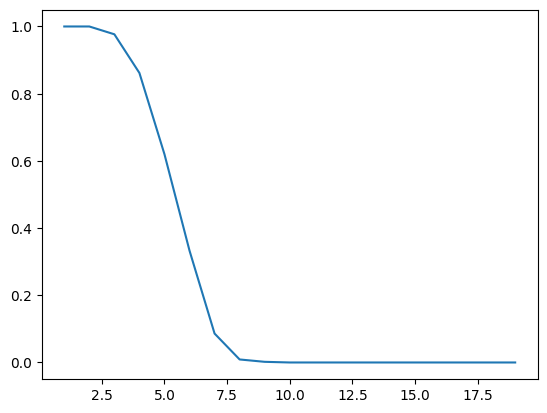 x축은 입력 Sequence의 길이, y축은 그에 따른 Accuracy 값이다.
x축은 입력 Sequence의 길이, y축은 그에 따른 Accuracy 값이다.
그러므로 이러한 배경으로 인해 Attention, Transformer 모델이 탄생하게 되는데, 이번 포스팅에선 Attention 모델에 대해 다뤄볼 것이다.
Attention 모델에서는 입력 데이터의 전체 혹은 일부분을 다시 살펴보면서 어떤 부분이 더 중요한지 판단하고, 그 중요한 부분에 더 집중하는 메커니즘이 발생한다. 이렇게 되면 디코더의 현재 step에서 디코딩할 단어와 연관된 중요한 부분을 입력 데이터 내에서 다시 되짚어 보며 찾게되므로 입력 Sequence가 매우 길어진다고 해도 좋은 성능을 낼 수 있을 것이다.
아래에 그 과정을 더 자세히 설명할 것이다.
Overview
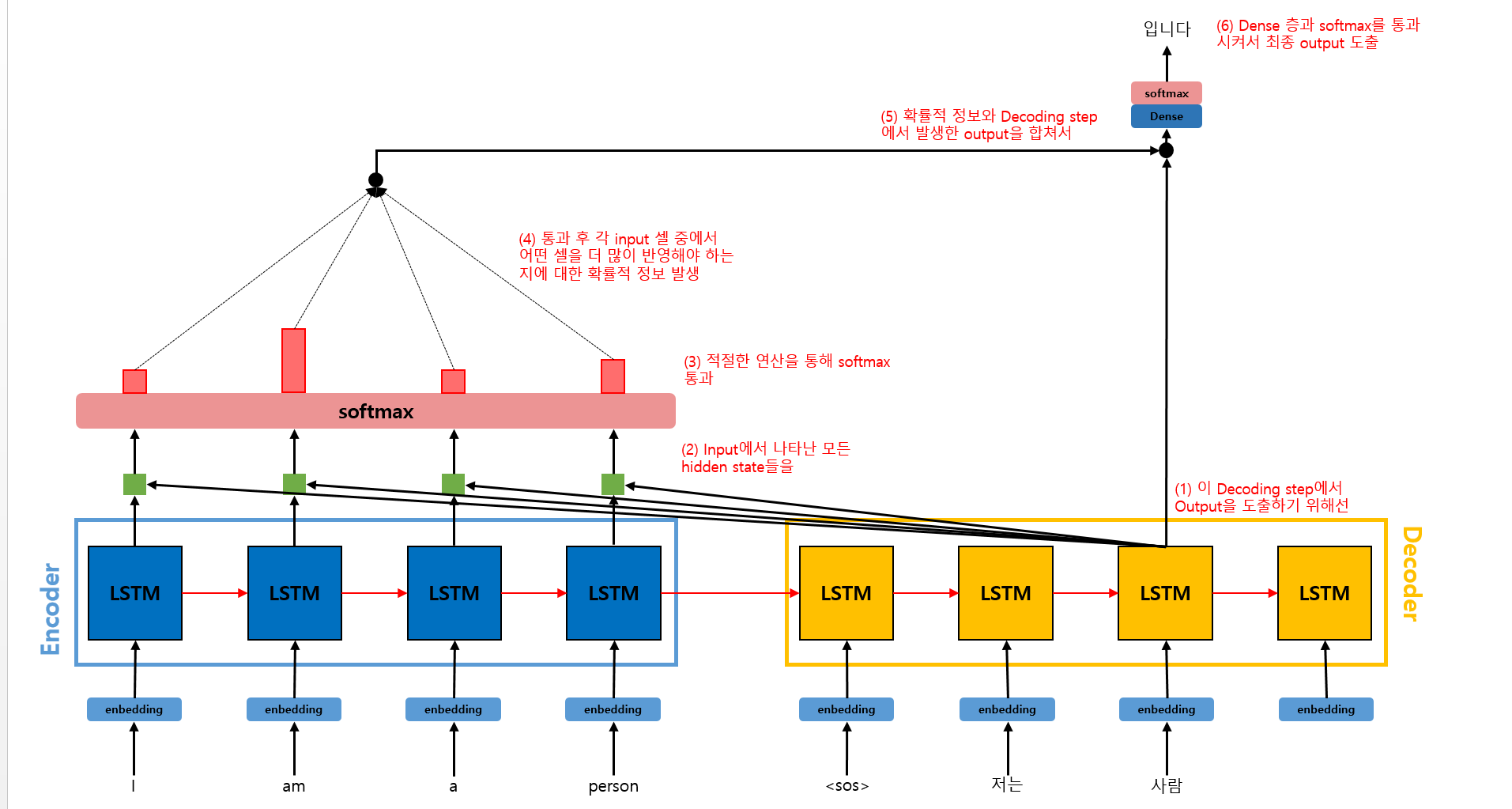
 올바른 출력을 위해선 어떤 입력 token을 더 많이 고려해야 할까? 위와 같은 번역기 모델을 예시로 들어보겠다.
올바른 출력을 위해선 어떤 입력 token을 더 많이 고려해야 할까? 위와 같은 번역기 모델을 예시로 들어보겠다.
'저는'을 출력하기 위해선 'I' token의 정보가 더 필요하고, '사람'을 출력하기 위해선 'person' token의 정보가 더 필요하다. 이때 한국어와 영어는 어순, 토큰수, 길이도 다르므로 Seq2Seq 모델만을 사용하면 한계가 있다.
그러므로 올바른 출력을 위해 Attention 메커니즘을 이용하여 특정 입력 token을 더 고려해야할 필요가 있다. 각각의 Decoding step에서 입력들에 대해 다른 가중치를 부여하여 이를 참고해 output을 출력하면 될 것이다.
그러므로 각 Decoding step에서는 각기 다른 Context vector를 활용하게 된다. 이때의 Context vector는 Encoder가 각 입력 token을 압축한 정보의 가중합이다.
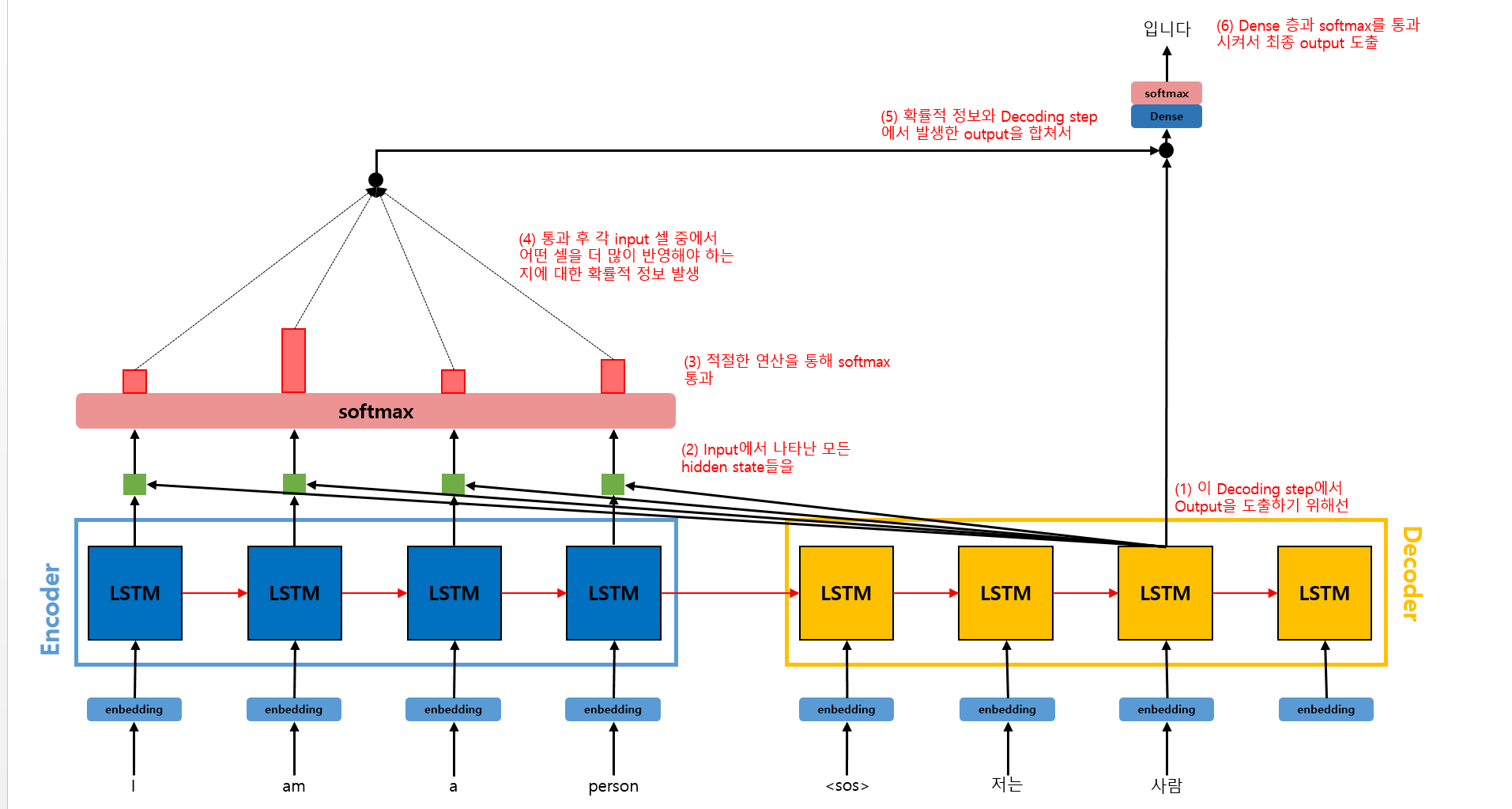 위 그림은 Attention 메커니즘의 Overview이다. 이제 각 단계들에 대해 더 자세히 알아보겠다.
위 그림은 Attention 메커니즘의 Overview이다. 이제 각 단계들에 대해 더 자세히 알아보겠다.
Attention Score
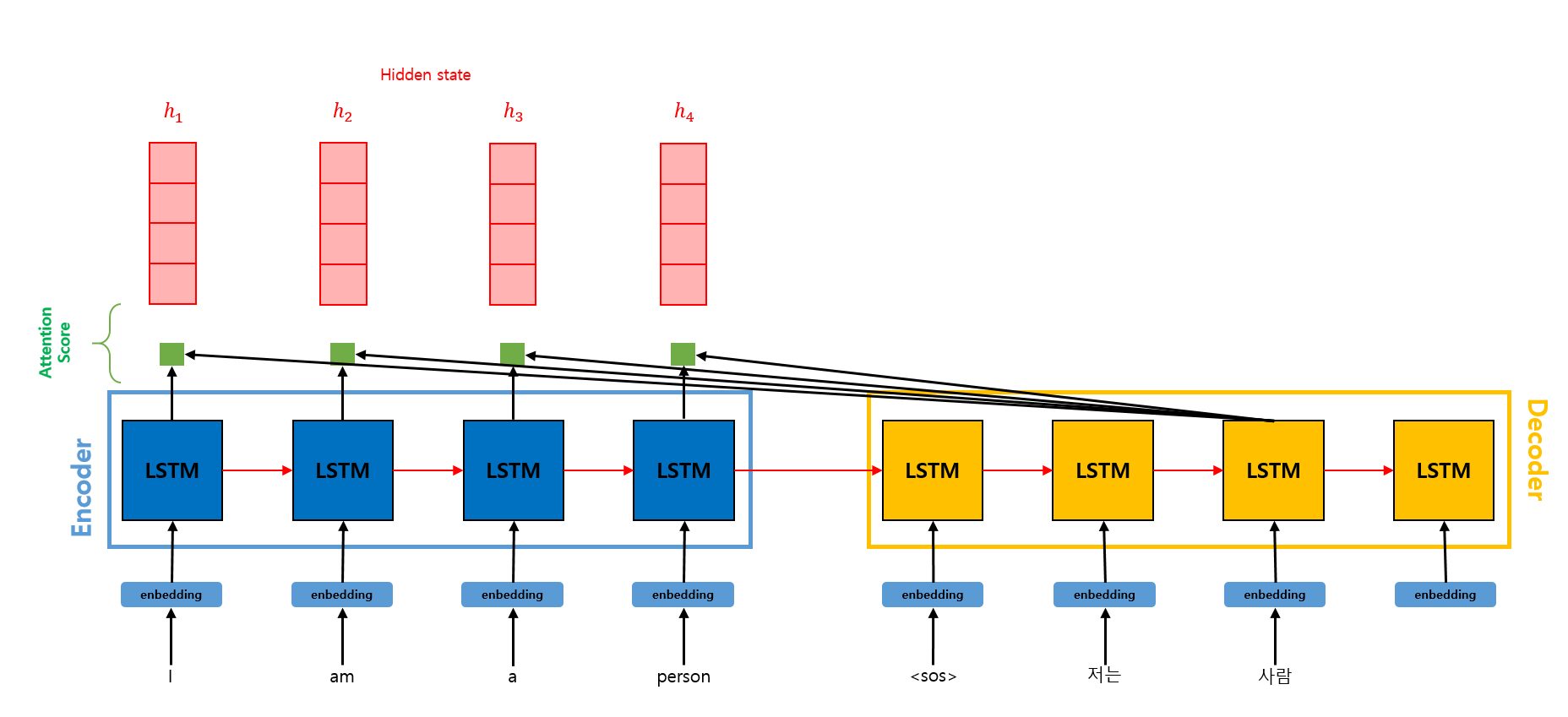 우선 Attention Score를 구해야 한다.
우선 Attention Score를 구해야 한다.
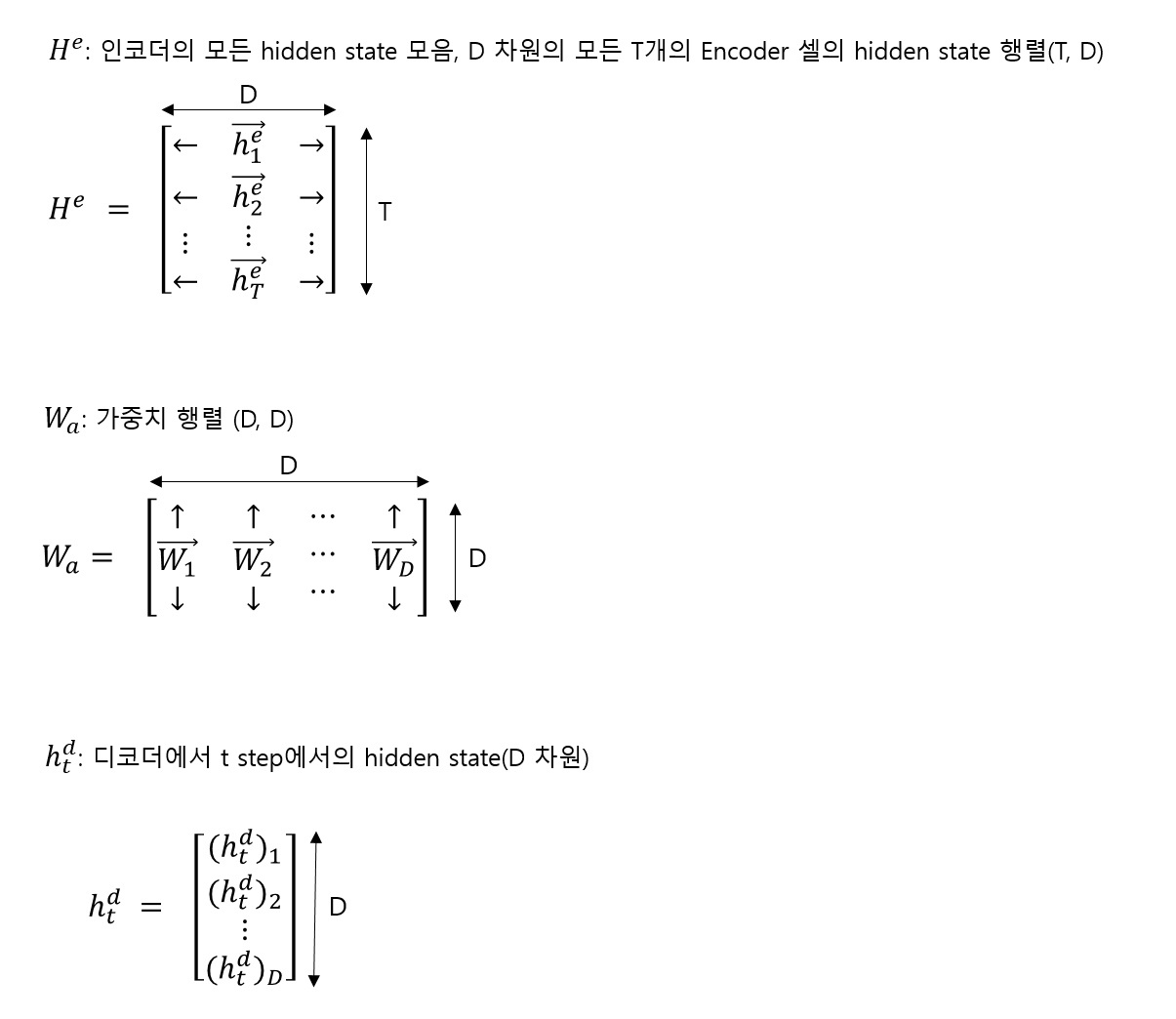
 그림과 같이 구하면 된다.
그림과 같이 구하면 된다.
Attention Weight
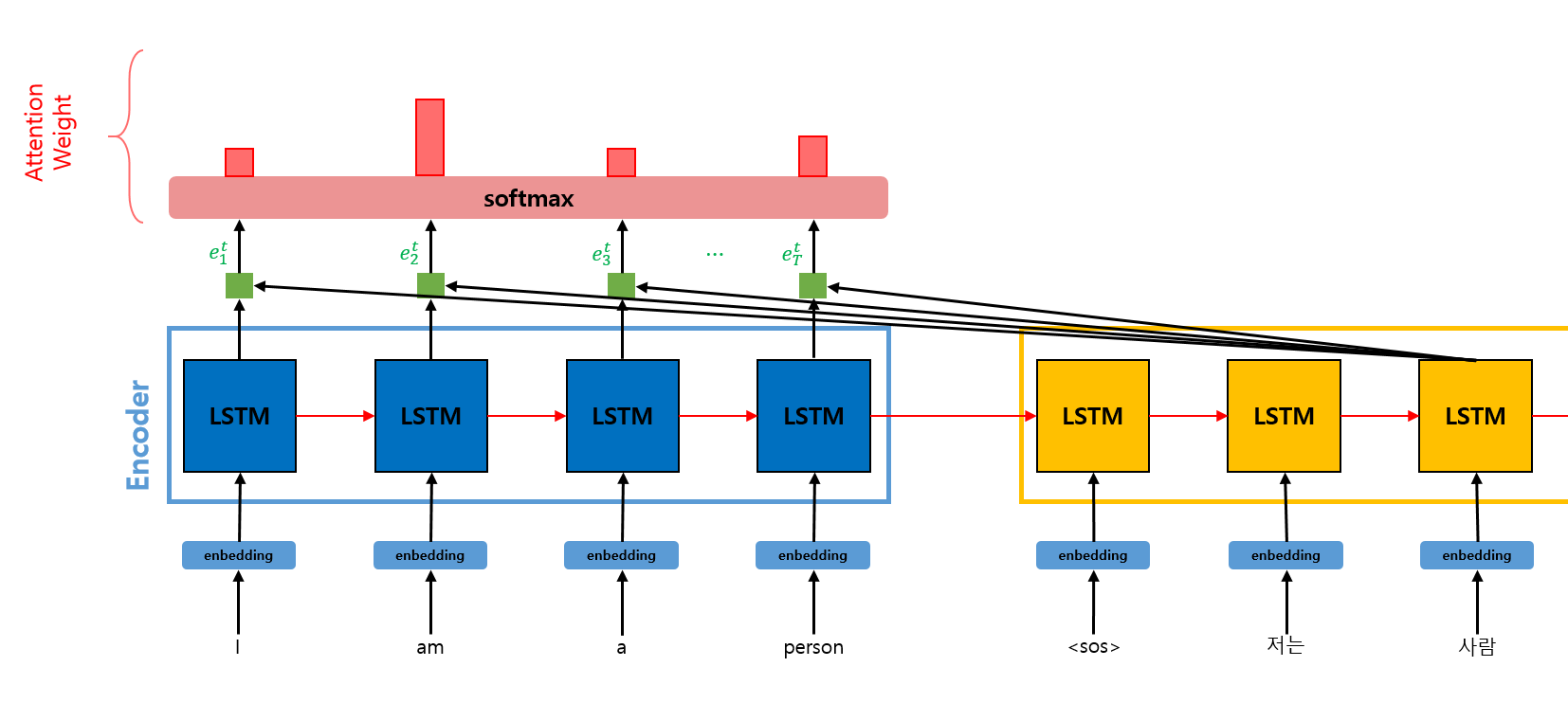 이전 단계에서 구한 Attention Score를 softmax 함수에 통과시켜서 Attention Weight를 구한다.
이전 단계에서 구한 Attention Score를 softmax 함수에 통과시켜서 Attention Weight를 구한다.
이 Attention Weight는 softmax를 통해 도출되었으므로 확률의 정보를 가지고 있다. 이를 바탕으로 t번째 step에서 얻어야 하는 Decoding 결과를 위해 어떤 input token의 hidden state를 얼마만큼의 %로 반영해야 하는지 알 수 있다.
Context Vector
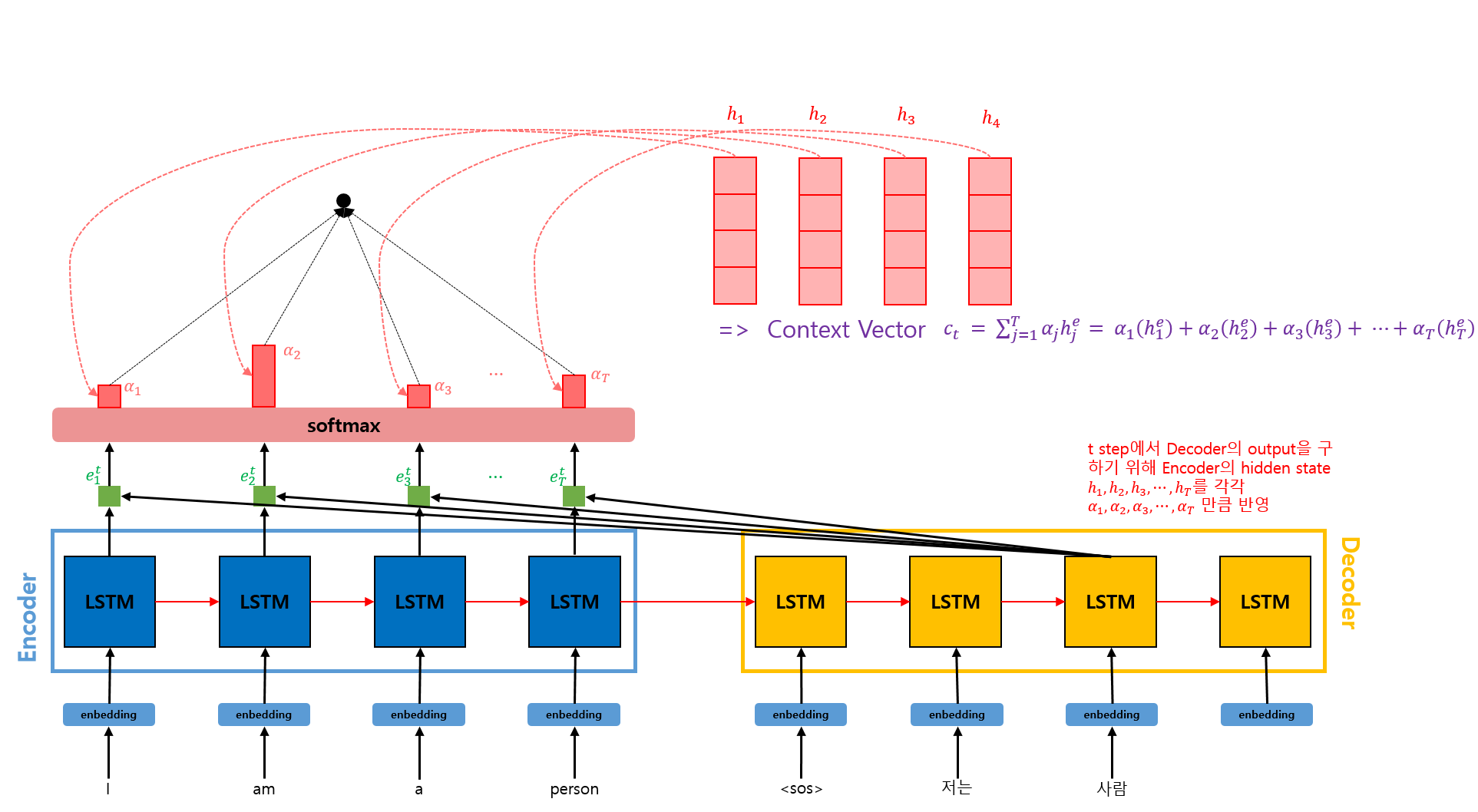 각 Encoder 셀의 Attention Weight와 hidden state를 가중합하여 Context Vector를 구한다. Context Vector는 Attention Value라고도 불린다.
각 Encoder 셀의 Attention Weight와 hidden state를 가중합하여 Context Vector를 구한다. Context Vector는 Attention Value라고도 불린다.
Context Vector의 식은 아래와 같다.
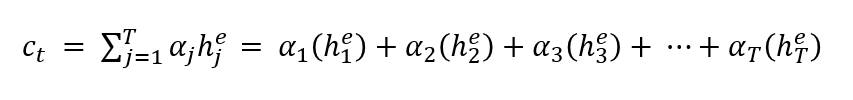
Context Vector & Output Concatenate
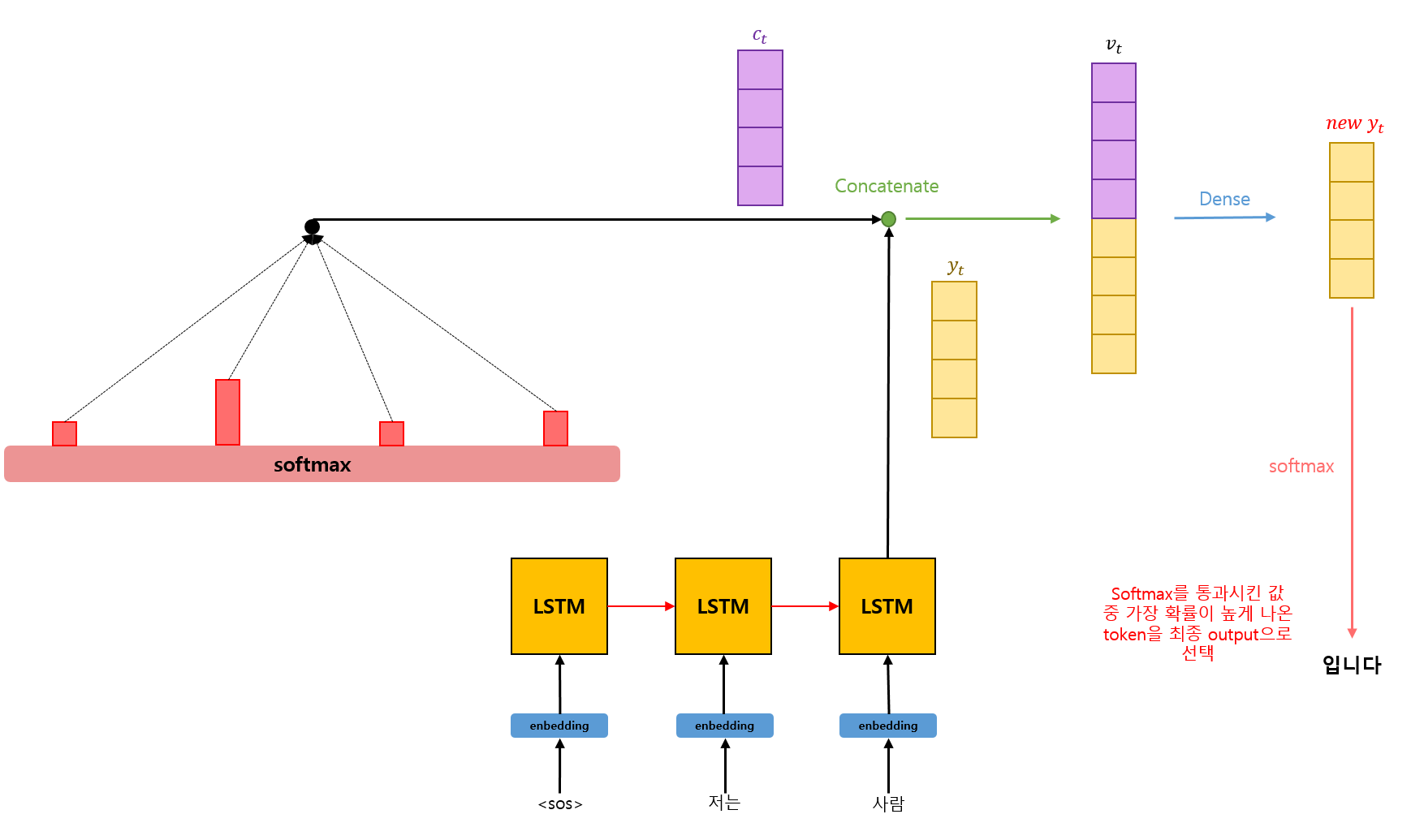 Context Vector와 Decoder의 t번째 step에서의 output 값()을 연결한다.
Context Vector와 Decoder의 t번째 step에서의 output 값()을 연결한다.
이후 Dense layer를 통과시켜 새로운 를 도출해낸 후 softmax에 통과시킨다. softmax에 통과된 값들 중 가장 확률이 높게 나온 token을 최종 output으로 선택한다.
