
mAP - Object Detection 성능 평가 지표
mAP는 mean Average Precision의 약자로, CNN 기반의 Object Detection과 같은 작업에서 모델의 성능을 평가하기 위한 지표이다. 이 지표는 예측한 객체의 위치와 클래스가 실제 값과 얼마나 잘 일치하는지를 측정한다. 이를 계산하기 위해서는 Precision, Recall 등에 대해 먼저 알아햐 하는데, 이에 대한 설명들과 mAP에 대한 최종적인 정의는 아래에 서술하겠다.
Precision
Precision은 정밀도를 뜻한다. 모든 검출 결과 중 옳게 검출한 비율을 의미한다. 식으로 나타내면 아래와 같다.
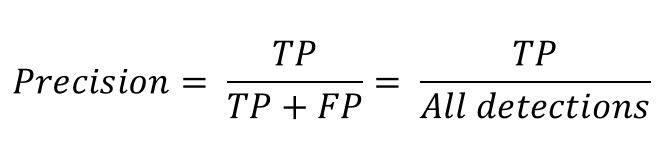 여기서 TP는 True Positive이고, FP는 False Positive이다. 위 2개 용어들을 포함한 4개의 용어들에 대한 내용은 아래 표를 통해 서술하겠다.
여기서 TP는 True Positive이고, FP는 False Positive이다. 위 2개 용어들을 포함한 4개의 용어들에 대한 내용은 아래 표를 통해 서술하겠다.
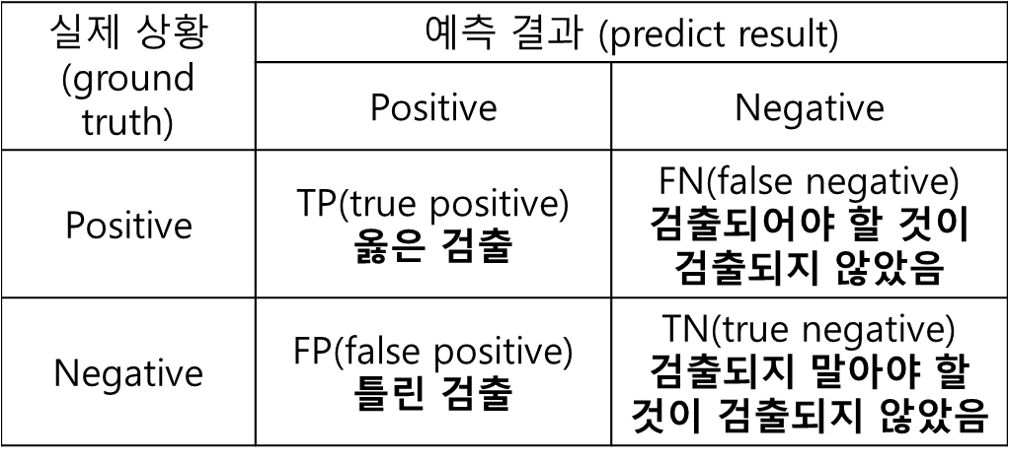 TP: 실제 Positive인 값을 Positive로 예측함
TP: 실제 Positive인 값을 Positive로 예측함
TN: 실제 Negative인 값을 Negative로 예측함
FP: 실제 Negative인 값을 Positive로 예측함
FN: 실제 Positive인 값을 Negative로 예측함
즉 Precision에서 TP은 실제로 올바르게 검출된 것이고, FP는 검출되지 말아야 할 것이 검출이 되버린 것을 의미한다. 만약 어떤 모델이 특정 Object 10개를 검출하였는데, 그 중 8개가 옳게 검출해낸 것(TP)이라면, Precision = 8/10 = 0.8이다.
Recall
Recall은 재현율을 뜻한다. 검출을 해내야하는 Object들 중에서 제대로 검출된 것의 비율을 의미한다. 식으로 나타내면 아래와 같다.
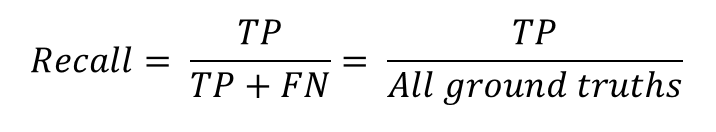 즉 Recall에서 TP는 Precision에서와 마찬가지로 실제로 올바르게 검출된 것이고, FN은 검출되어야 했으나 검출되지 않은 것을 뜻한다. 그러므로 TP + FN은 모든 Ground truth를 의미한다. 만약 실제로 검출되어야 할 object는 10개인데, 그 중에서 5개만 검출이 되었다면, Recall = 5/10 = 0.5이다.
즉 Recall에서 TP는 Precision에서와 마찬가지로 실제로 올바르게 검출된 것이고, FN은 검출되어야 했으나 검출되지 않은 것을 뜻한다. 그러므로 TP + FN은 모든 Ground truth를 의미한다. 만약 실제로 검출되어야 할 object는 10개인데, 그 중에서 5개만 검출이 되었다면, Recall = 5/10 = 0.5이다.
IoU(Intersection over Union)
 위와 같이 고양이의 위치에 바운더리 박스를 적용한 이미지가 있다고 가정해보자. 이 바운더리 박스는 사용자가 지정한 ground truth 값이다. ground truth 바운더리 박스는 마땅이 검출되어야 할 object를 감싸고 있다.
위와 같이 고양이의 위치에 바운더리 박스를 적용한 이미지가 있다고 가정해보자. 이 바운더리 박스는 사용자가 지정한 ground truth 값이다. ground truth 바운더리 박스는 마땅이 검출되어야 할 object를 감싸고 있다.
 동일한 이미지에서, ground truth 바운더리 박스가 주어지지 않은 상황일때 어떤 모델이 위와 같이 바운더리 박스를 예측했다고 가정해보자.
동일한 이미지에서, ground truth 바운더리 박스가 주어지지 않은 상황일때 어떤 모델이 위와 같이 바운더리 박스를 예측했다고 가정해보자.
이때 Overlapping region은 아래와 같다.

Combined region은 아래와 같다.

이를 통해 IoU를 구할 수 있다.
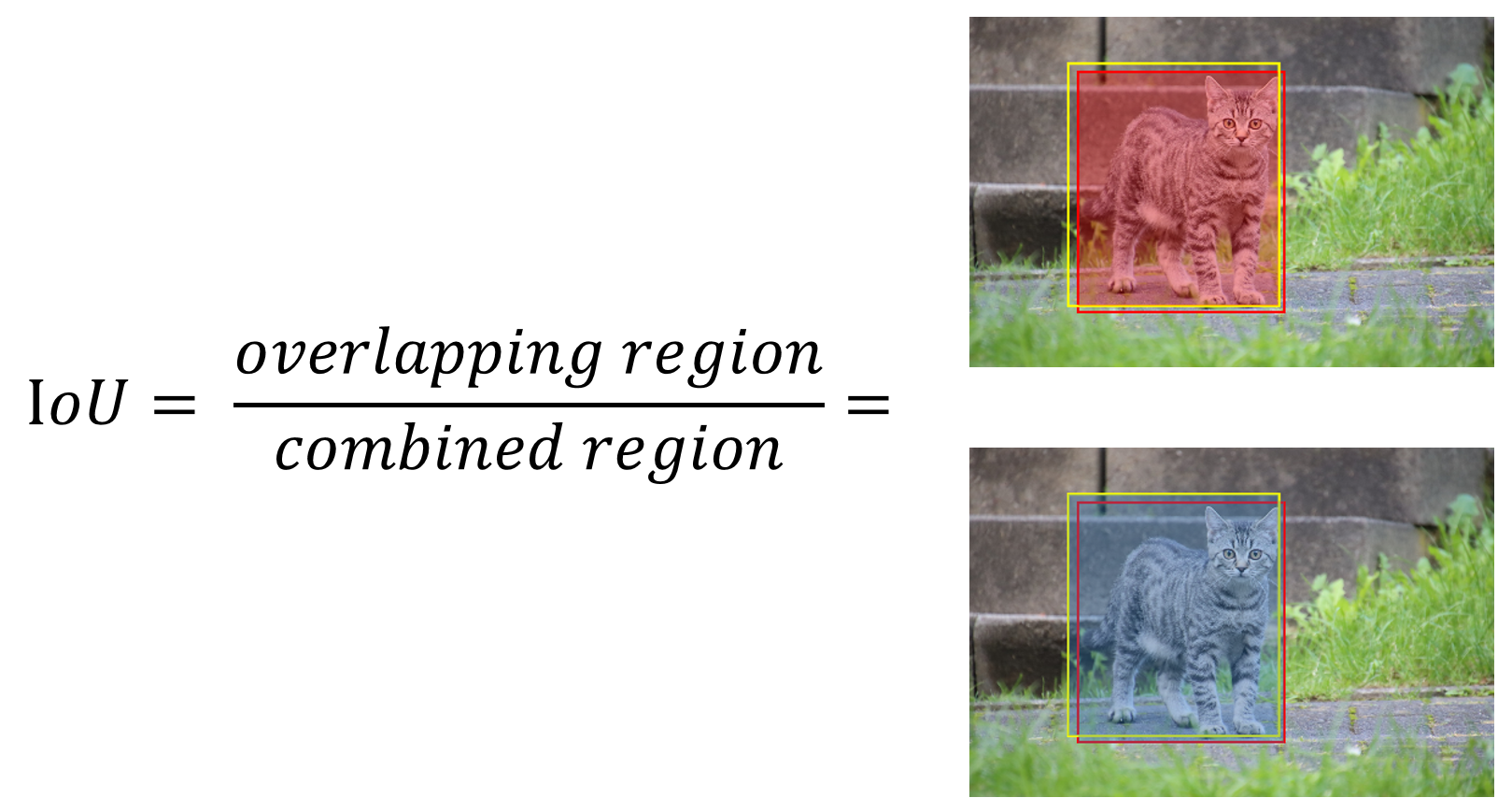
IoU 계산 결과 값이 0.5 이상이면 제대로 검출(TP)되었다고 판단한다. 만약 0.5 미만이면 잘못 검출(FP)되었다고 판단한다. (이 값은 임의로 설정 가능하다.)
PR(Precision-Recall) Curve
PR(Precision-Recall) 곡선은 Confidence 레벨에 대한 Threshold 값의 변화에 의한 Object Detection 모델의 성능을 평가하는 방법이다. 이때 Confidence 레벨은 Detection한 것에 대해 모델이 얼마나 확신이 있는지를 알려주는 값이다.
Confidence 레벨이 높다고 해서 무조건 정확하게 Detection 했다고는 할 수 없다. 모델 스스로 그러한 느낌 또는 확신을 갖고 있는 것이다. Confidence 레벨이 낮으면 그만큼 Detection 결과에 대해 자신이 없는 것을 뜻한다.
이러한 모델이나 알고리즘의 사용자가 보통 Confidence 레벨에 대한 Threshold 값을 부여하는데, 만약 Threshold 값이 0.4라면 Confidence 레벨로 0.1 혹은 0.2를 갖고 있는 Detection은 무시되게 된다.
따라서 이 Confidence 레벨에 대한 Threshold 값의 변화에 따라 Precision, Recall의 값도 달라지게 된다.
아래 예시를 통해 이를 더 설명해보겠다.
한 사진에 15대의 자동차가 존재하고, 학습된 모델에 의해서 총 10대의 자동차가 Detection 되었다고 가정해보자. 이때 각 Detection의 Confidence 레벨과 옳게 검출되었는지 아닌지에 대한 여부는 아래 표와 같다고 한다.
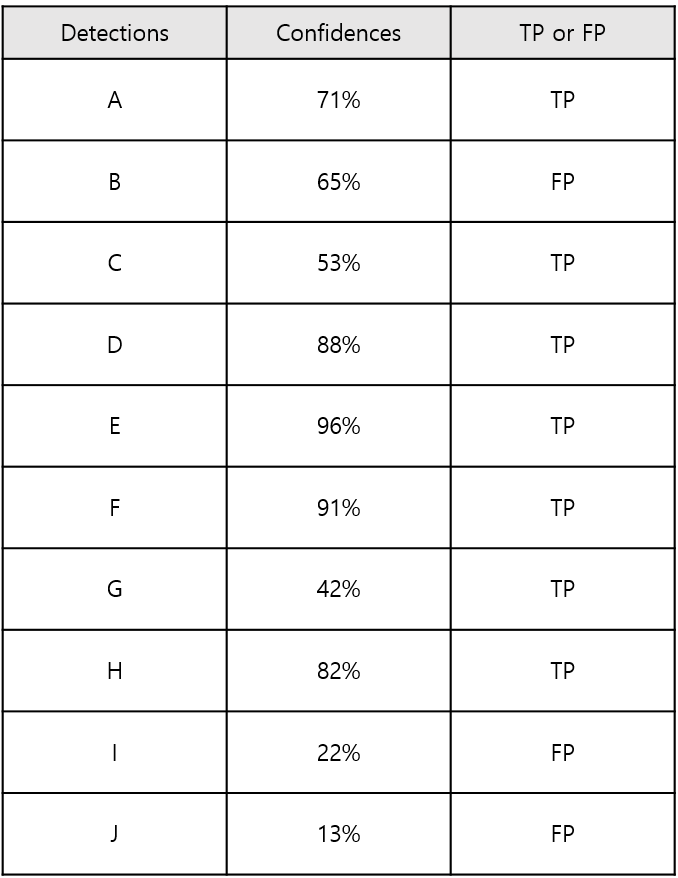 10대 중 7대가 제대로 검출되었고, 3대는 잘못 검출되었다. 이 경우에는 Precision = TP/(TP+FP) = 옳게 검출된 자동차 수/총 검출된 자동차 수 = 7/10 = 0.7이 되고, Recall = 옳게 검출된 자동차 수/실제 자동차 수 = 7/15 = 0.47이 된다. 이것은 Confidence 레벨이 13%와 같이 아주 낮더라도 검출해낸 것을 모두 인정했을 때의 결과이다.
10대 중 7대가 제대로 검출되었고, 3대는 잘못 검출되었다. 이 경우에는 Precision = TP/(TP+FP) = 옳게 검출된 자동차 수/총 검출된 자동차 수 = 7/10 = 0.7이 되고, Recall = 옳게 검출된 자동차 수/실제 자동차 수 = 7/15 = 0.47이 된다. 이것은 Confidence 레벨이 13%와 같이 아주 낮더라도 검출해낸 것을 모두 인정했을 때의 결과이다.
위 표를 Confidence 레벨에 따라 내림차순으로 정렬하면,
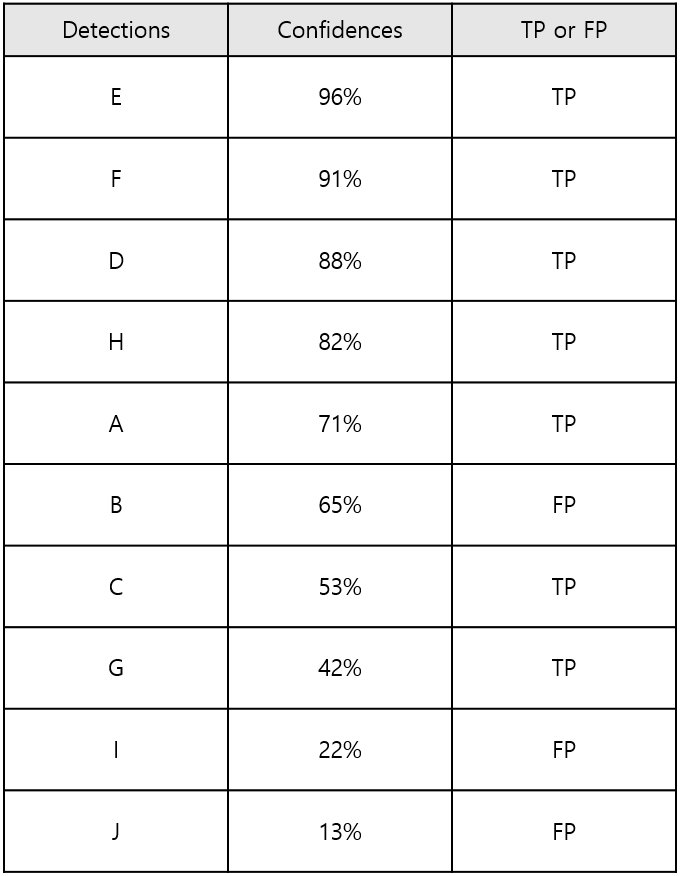 위와 같다.
위와 같다.
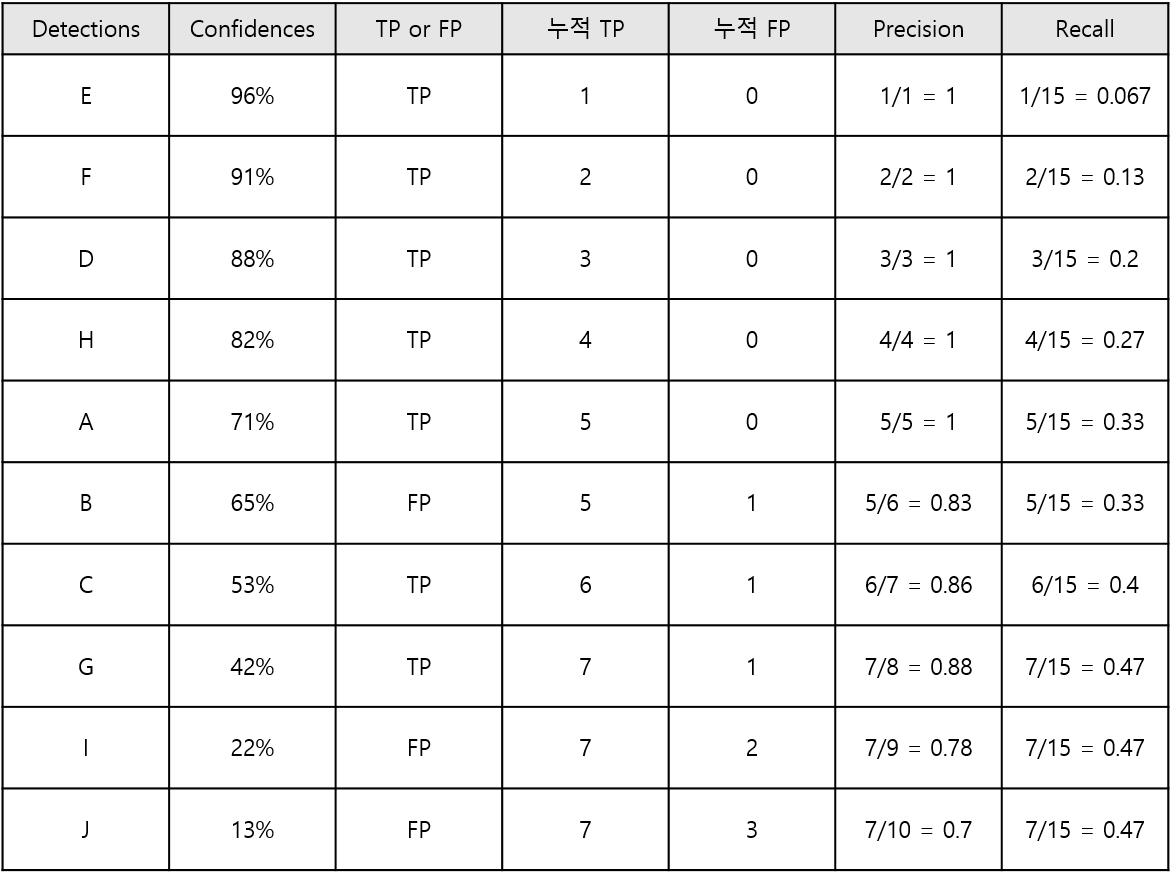
Confidence 레벨에 대한 Threshold 값을 적용해서 96%로 했다면, 하나만 검출한 것으로 판단할 것이고, 이때 Precision = 1/1 = 1, Recall = 1/15 = 0.067이 된다.
Threshold 값을 91%로 했다면, 자동차 2대가 검출된 것으로 판단할 것이고, 이때 Precision = 2/2 = 1, Recall = 2/15 = 0.13이 된다.
Treshold 값을 각 Confidence 레벨들에 맞춰 낮춰가면 아래와 같이 Precision과 Recall이 계산되게 된다.
 그리고 Recall값을 x축으로 하고, Precision 값을 y축으로 하여 그래프를 그리면 아래와 같다.
그리고 Recall값을 x축으로 하고, Precision 값을 y축으로 하여 그래프를 그리면 아래와 같다.
import matplotlib.pyplot as plt
# x축(Recall)과 y축(Precision) 값
x = [0.067, 0.13, 0.2, 0.27, 0.33, 0.33, 0.4, 0.47, 0.47, 0.47]
y = [1, 1, 1, 1, 1, 0.83, 0.86, 0.88, 0.78, 0.7]
# 그래프 그리기
plt.plot(x, y, marker='o')
# 제목, 축 이름 설정
plt.title('PR-Curve')
plt.xlabel('Recall')
plt.ylabel('Precision')
# 그래프 시각화
plt.show()
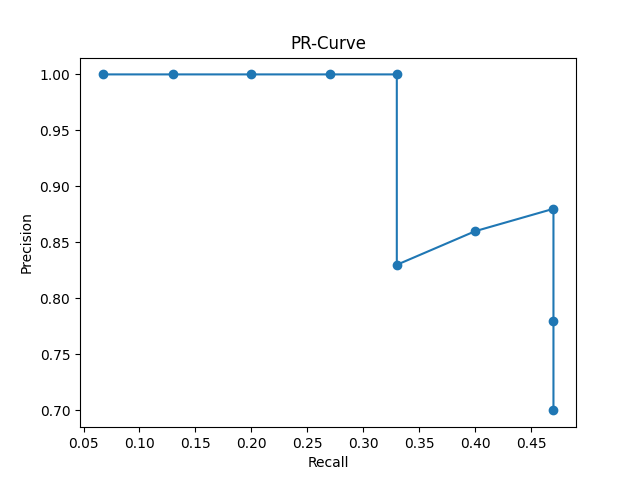 이 그래프가 바로 PR 곡선이다. PR 곡선에서는 Recall 값의 변화에 따른 Precision 값을 확인할 수 있다.
이 그래프가 바로 PR 곡선이다. PR 곡선에서는 Recall 값의 변화에 따른 Precision 값을 확인할 수 있다.
Recall이 증가할수록 Precision이 조금만 떨어져야 좋은 성능을 가진 모델이라고 할 수 있다. 즉, 그래프 아래의 영역이 넓을수록 좋은 모델이라고 할 수 있다.
AP(Average Precision)
PR 곡선은 모델의 성능을 평가하는 매우 좋은 지표이지만, 하나의 숫자로 정략적으로 성능을 평가할 수 있다면 훨씬 더 이상적일 것이다. 이러한 이유로 나온 것이 AP이다. AP는 PR 곡선에서 곡선 아래쪽의 면적으로 계산된다.
보통 계산 전에 PR 곡선을 살짝 수정하여 PR 곡선을 단조적으로 감소하는 그래프가 되게 해준다.
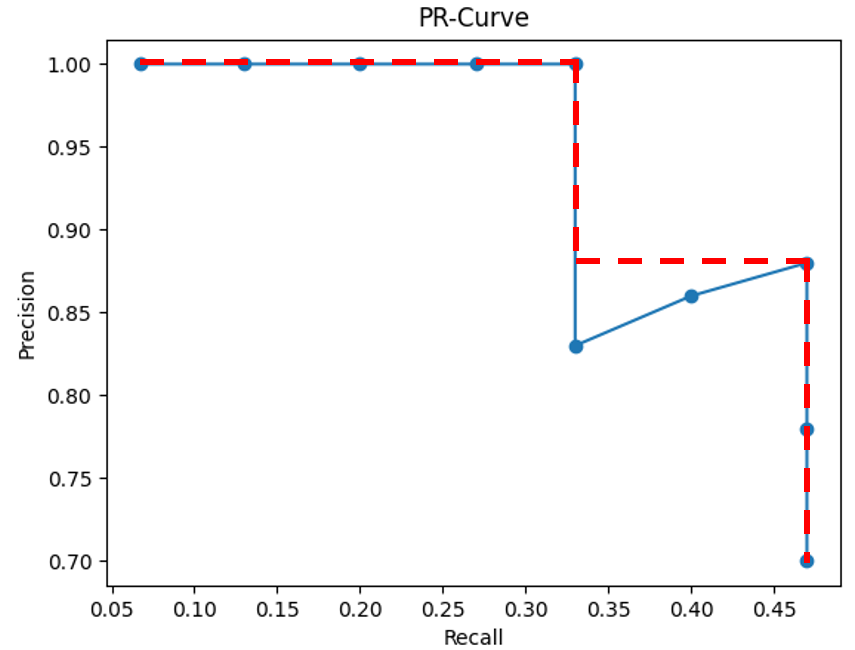 이렇게 수정해준 후 빨간색 그래프 아래 영역의 면적을 계산하면 그 값이 바로 AP 값이다. 컴퓨터 비전 분야에서 Object Detection 및 Image Classification 모델의 성능은 대부분 이 AP로 평가한다. Object 클래스가 여러 개인 경우 각 클래스당 AP를 구한 다음에 그것을 모두 합한 다음에 물체 클래스의 갯수로 나눠줌으로 알고리즘의 성능을 평가한다. 이것을 바로 가장 처음에 설명한 mAP(mean average precision)이다.
이렇게 수정해준 후 빨간색 그래프 아래 영역의 면적을 계산하면 그 값이 바로 AP 값이다. 컴퓨터 비전 분야에서 Object Detection 및 Image Classification 모델의 성능은 대부분 이 AP로 평가한다. Object 클래스가 여러 개인 경우 각 클래스당 AP를 구한 다음에 그것을 모두 합한 다음에 물체 클래스의 갯수로 나눠줌으로 알고리즘의 성능을 평가한다. 이것을 바로 가장 처음에 설명한 mAP(mean average precision)이다.
Reference
물체 검출 알고리즘 성능 평가방법 AP(Average Precision)의 이해: https://bskyvision.com/465
고양이 사진 출처(무료): https://pixabay.com/ko/users/dominikrh-12119308/
