YOLOv8로 object detection 해보기 2
지난 번에 'YOLOv8로 object detection 해보기' 에서 직접 수집한 가벼운 데이터셋으로 barcode detection을 수행했었다. 가벼운 데이터셋과 모델로 학습을 진행했기 때문에 학습된 모델이 제대로 추론을 하지 못 하는 현상이 발생했었다. 해당 포스트 링크는 아래에 첨부하겠다.
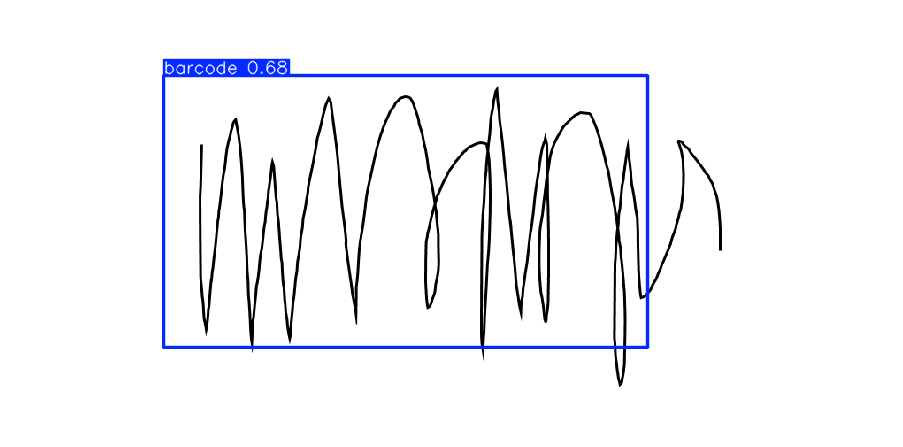
 위처럼 바코드가 아닌 사진을 바코드로 인식하거나, 사진 전체가 바코드로 채워져있는 사진에 여러개의 바코드가 있다고 인식하는 문제가 발생했었다. 이 문제들을 해결하기 위해 데이터셋의 양을 늘려 다시 학습을 진행해야 한다고 판단했다.
위처럼 바코드가 아닌 사진을 바코드로 인식하거나, 사진 전체가 바코드로 채워져있는 사진에 여러개의 바코드가 있다고 인식하는 문제가 발생했었다. 이 문제들을 해결하기 위해 데이터셋의 양을 늘려 다시 학습을 진행해야 한다고 판단했다.
그러나 바코드 이미지를 몇천장 단위로 수집하는 것은 쉬운 일이 아니다. 집에 있는 물건들도 한정되어있을 뿐만 아니라, 바코드 이미지 수집만을 위해 분리수거장이나 근처 마트에 간다면 매우 번거롭고 민폐가 될 수 있기 때문이다..
그러므로 Roboflow Universe에 있는 공개 데이터셋을 이용하기로 결정했다.
Dataset
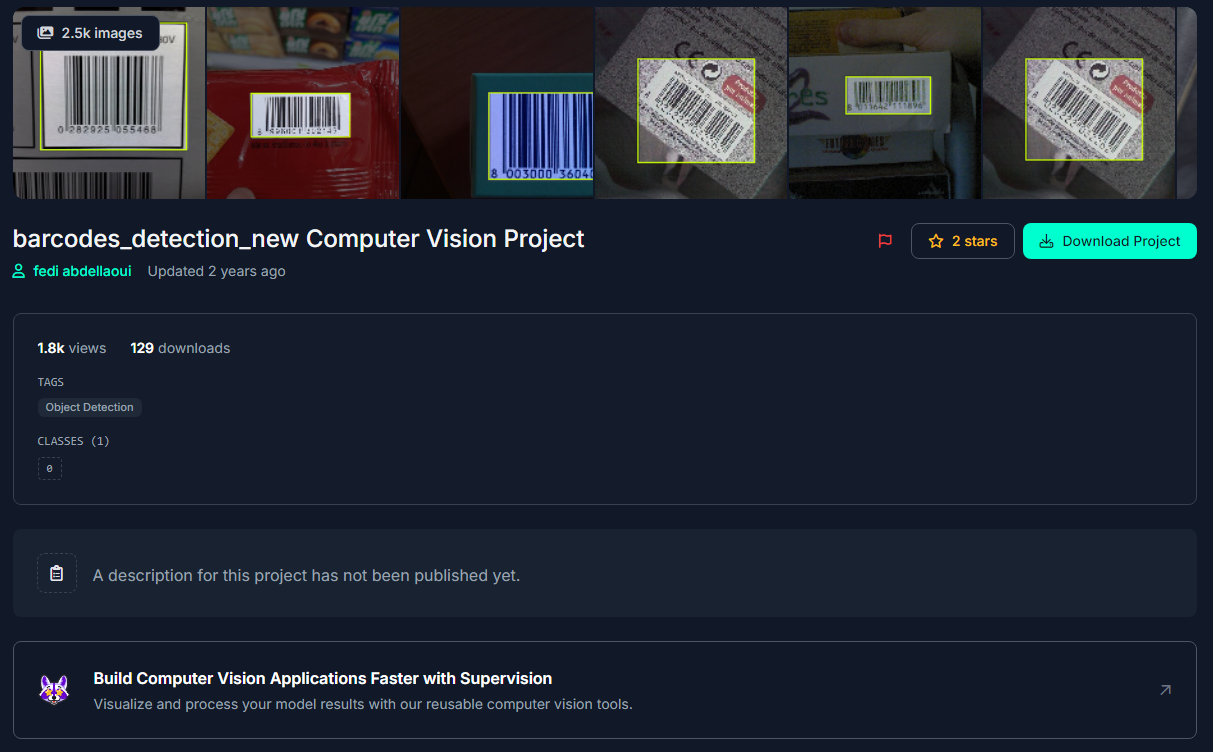 위 데이터셋을 이용하기로 했다. 이미지도 약 2500장으로 충분하다고 생각했고, Preprocessing과 Augmentation 또한 모두 완료되어 있었기 때문이다. 해당 데이터셋의 링크는 바로 아래에 첨부하도록 하겠다.
위 데이터셋을 이용하기로 했다. 이미지도 약 2500장으로 충분하다고 생각했고, Preprocessing과 Augmentation 또한 모두 완료되어 있었기 때문이다. 해당 데이터셋의 링크는 바로 아래에 첨부하도록 하겠다.
https://universe.roboflow.com/fedi-abdellaoui-3f2u9/barcodes_detection_new
 Flip, Rotate, Shear, Brightness 조절 등의 다양한 Augmentation 작업이 진행되었던 것을 확인할 수 있다.
Flip, Rotate, Shear, Brightness 조절 등의 다양한 Augmentation 작업이 진행되었던 것을 확인할 수 있다.
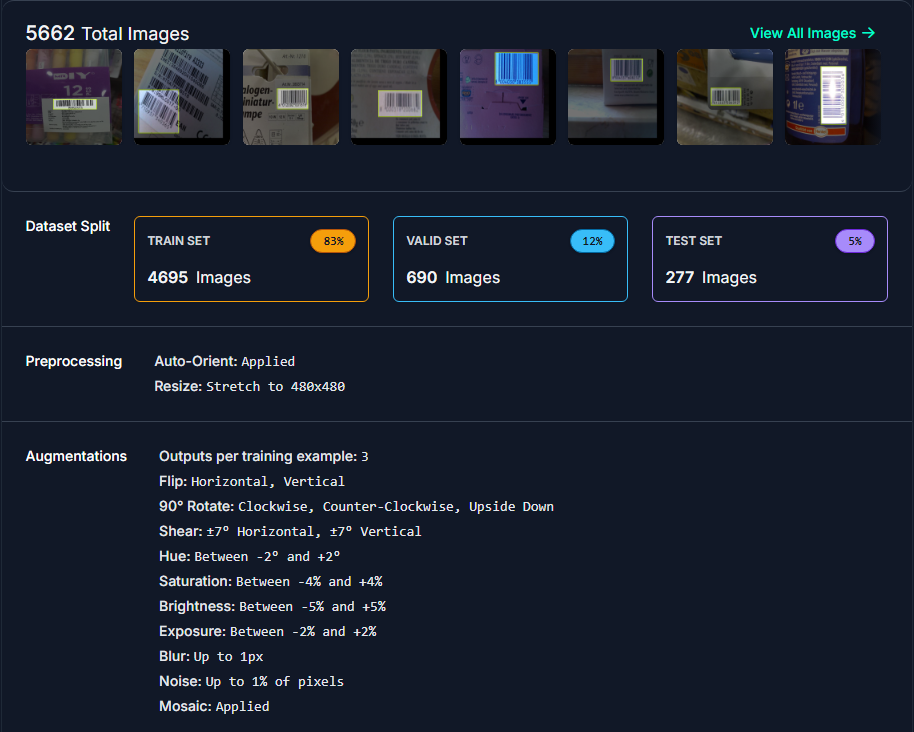 Augmentation 진행되었으므로 전체 이미지도 5562장으로 증가한 것을 볼 수 있다. 데이터셋이 Train : Valid : Test = 8.3 : 1.2 : 0.5 정도로 나눠져있다.
Augmentation 진행되었으므로 전체 이미지도 5562장으로 증가한 것을 볼 수 있다. 데이터셋이 Train : Valid : Test = 8.3 : 1.2 : 0.5 정도로 나눠져있다.
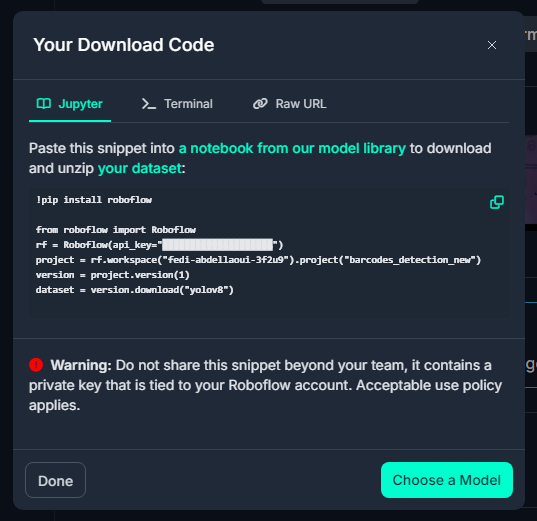 Format을 YOLOv8로 설정하고 데이터셋을 코드를 통해 다운로드 할 것이다. 위와 같은 코드를 복사하여 다운로드하면 된다.
Format을 YOLOv8로 설정하고 데이터셋을 코드를 통해 다운로드 할 것이다. 위와 같은 코드를 복사하여 다운로드하면 된다.
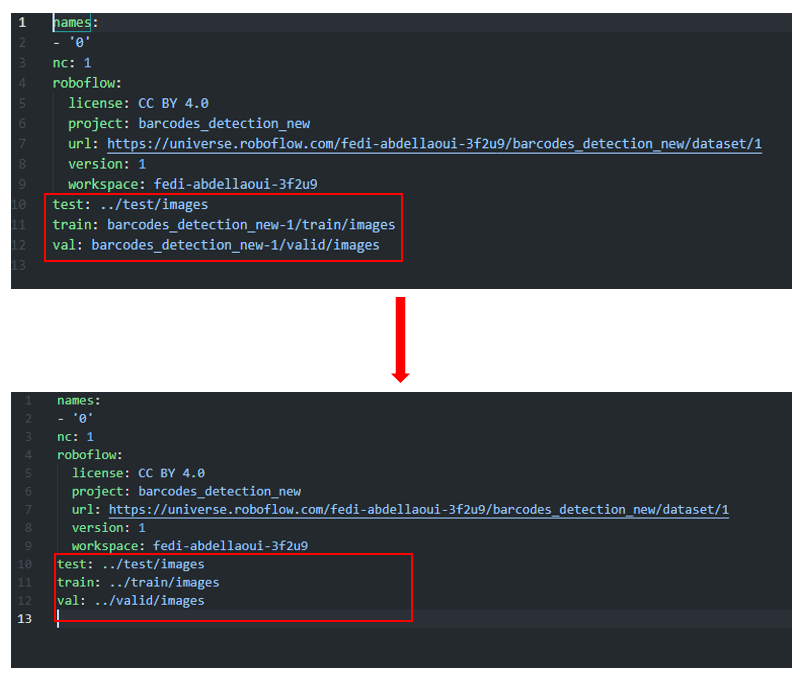 이전과 같은 방식으로 다운로드된 데이터셋 폴더 내의 data.yaml 파일에서 test, train, val 폴더 내의 images 폴더를 가리키도록 경로를 수정해준다.
이전과 같은 방식으로 다운로드된 데이터셋 폴더 내의 data.yaml 파일에서 test, train, val 폴더 내의 images 폴더를 가리키도록 경로를 수정해준다.
Train
from ultralytics import YOLO
model = YOLO('yolov8m.pt')YOLO 모델을 사용하기 위해 ultralytics에서 YOLO를 import 해준다. 이번에는 yolov8s.pt가 아닌 yolov8m.pt를 이용하여 학습을 진행해볼 것이다.
model.train(data='path/to/data.yaml, epochs = 100, batch = 20, imgsz = 480)data에는 데이터셋 폴더 내의 data.yaml 파일의 경로를 입력해준다. 이미지 사이즈는 480, epochs는 100번 진행할 것이고 batch는 20으로 지정해준다.
 학습이 끝날 때 까지 기다려주면 된다.
학습이 끝날 때 까지 기다려주면 된다.
Predict
이제 가장 긴장되고 기대되는 작업이다! 성능이 잘 나오는지 확인하기 위해 이전처럼 아래 이미지들을 추론해볼 것이다.


하나는 바코드가 아닌 랜덤한 선이 그려진 이미지이고, 다른 하나는 사진 전체가 바코드로 채워져있는 사진이다.
우선 선이 그려진 이미지를 추론해보겠다.
model.predict(source='path/to/line_img', save=True)source에 추론하고 싶은 이미지의 경로를 입력하면 된다.
저장하지 않고 바로 결과를 확인하고 싶다면 아래와 같이 입력하면 된다.
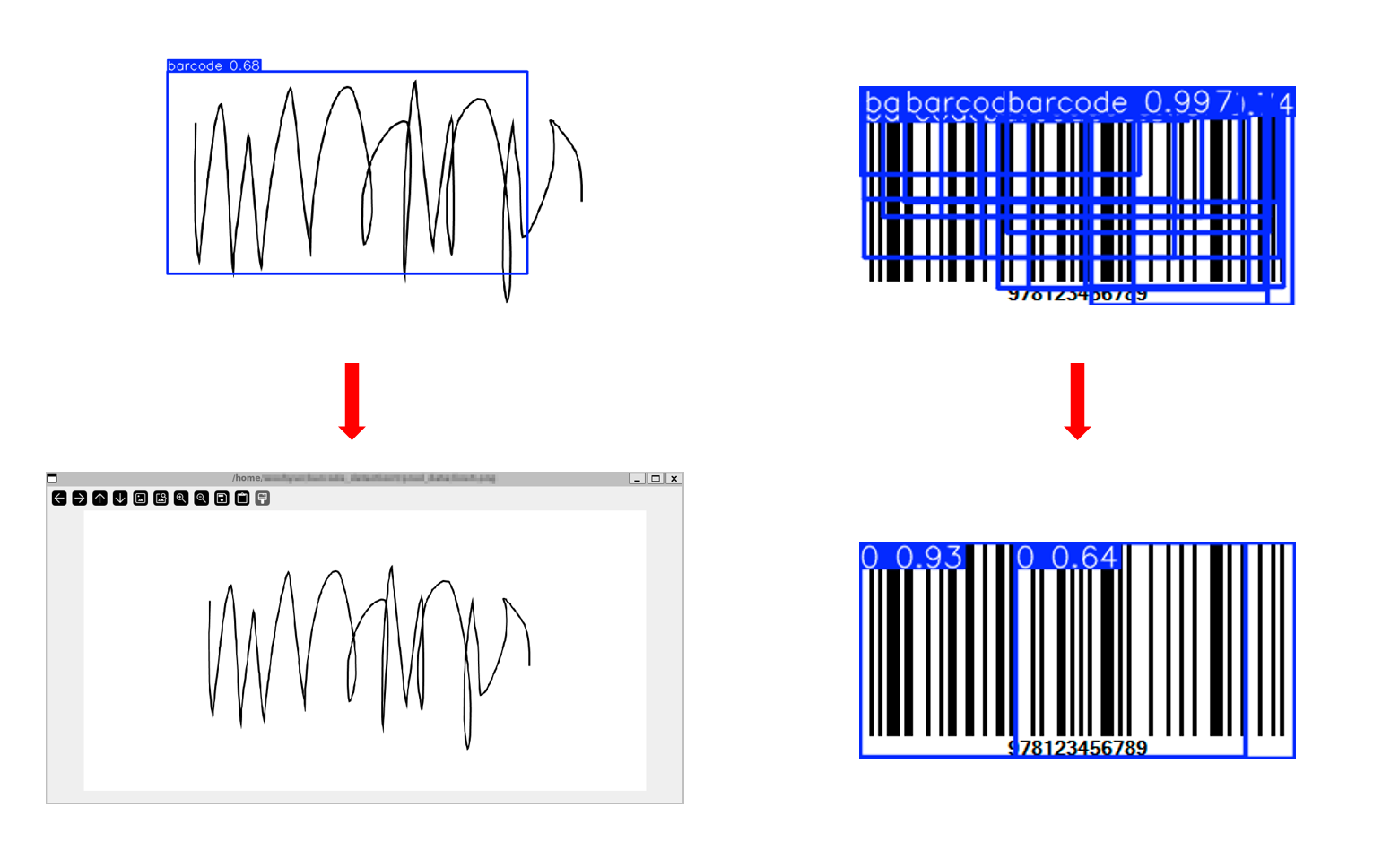
model.predict(source='path/to/line_img', show=True)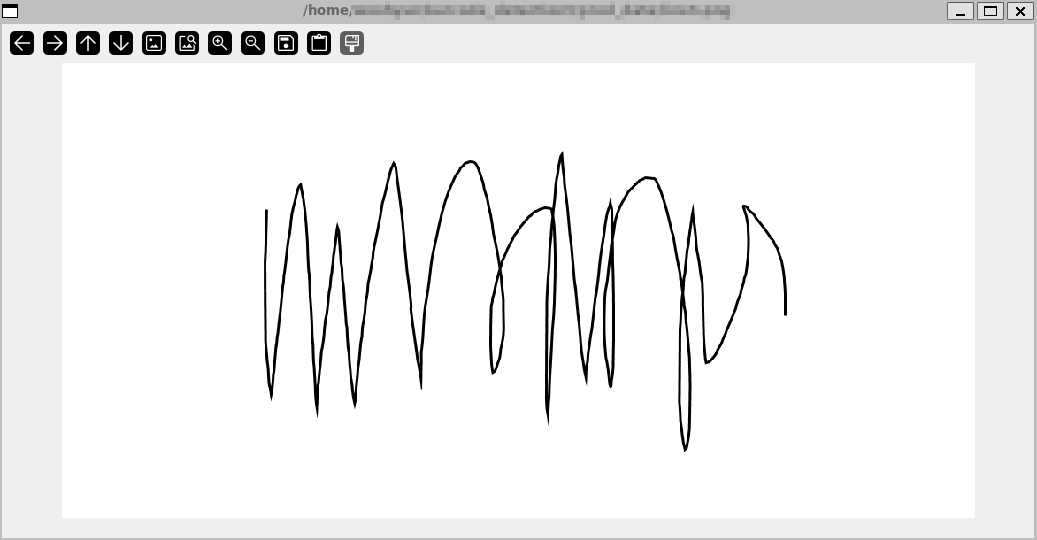 바코드로 인식하지 않게 된다.
바코드로 인식하지 않게 된다.
이제 그 다음 이미지를 추론해보겠다.
 여전히 바코드가 2개라고 인식하지만 이전보다는 훨씬 좋은 성능을 보인다.
여전히 바코드가 2개라고 인식하지만 이전보다는 훨씬 좋은 성능을 보인다.
이전의 결과들과 비교한 사진은 아래와 같다.
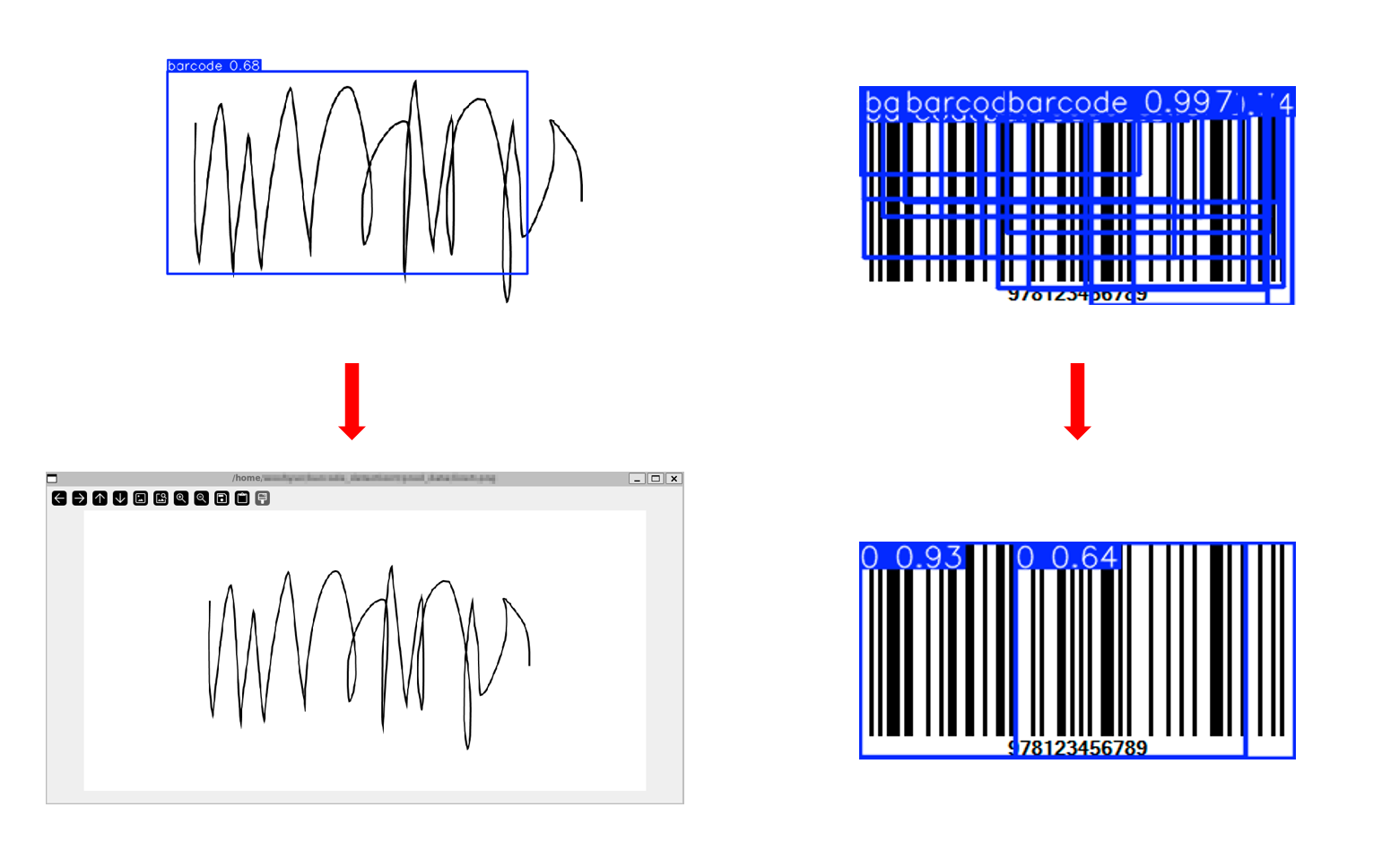 데이터 수집량을 늘리고 Augmentation까지 진행한 후에 학습을 진행하면 성능이 향상된다는 것을 알 수 있다. 이를 통해 데이터의 양, 다양성, 퀄리티 등이 딥러닝 모델 학습에 중요한 영향을 끼친다는 것을 알 수 있다.
데이터 수집량을 늘리고 Augmentation까지 진행한 후에 학습을 진행하면 성능이 향상된다는 것을 알 수 있다. 이를 통해 데이터의 양, 다양성, 퀄리티 등이 딥러닝 모델 학습에 중요한 영향을 끼친다는 것을 알 수 있다.
