(24년 12월 추가)
글 내용과 관련해 강의를 런칭하였습니다. 더 많은 정보가 필요하신 분들은 참고해주세요!!
▪ 쿠폰코드: PRDTEA241202_auto
▪ 할인액: 4만원 (~25/1/5 까지 사용가능)
▪ 강의링크: https://bit.ly/3BayH1F
1. 실험 배경
혹자는 말한다. 청킹은 RAG의 3대 요소라고.
또, AutoRAG에서 청킹 최적화는 다루지 않냐는 질문을 많이 받았다.
그렇다면 청킹은 RAG 답변 성능에 얼마나 영향을 미칠까?
그래서 우리는 청킹이 RAG에서 얼마나 중요한 요소인지 알아보기 위해, 실험을 해보기로 한다.
빠른 실험을 위해 한국어로 실험을 진행해보기로 한다.
2. 실험 설계
- 사실 관계를 명확하게 확인할 수 있는 질문 데이터셋 40개를 준비한다.
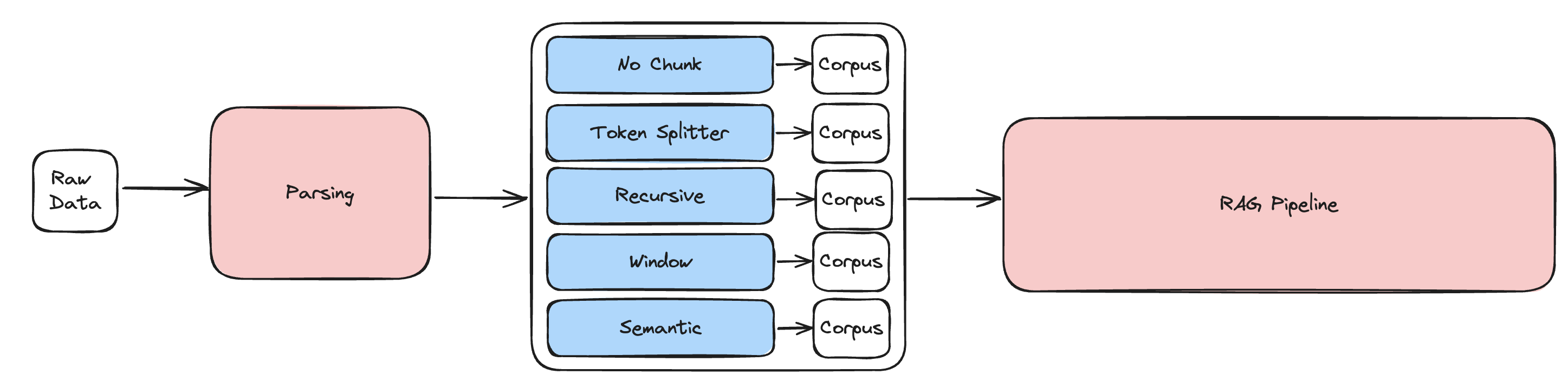
- 파싱, RAG 파이프라인은 고정하고, 청킹만 바꿔가면서 실험한다.
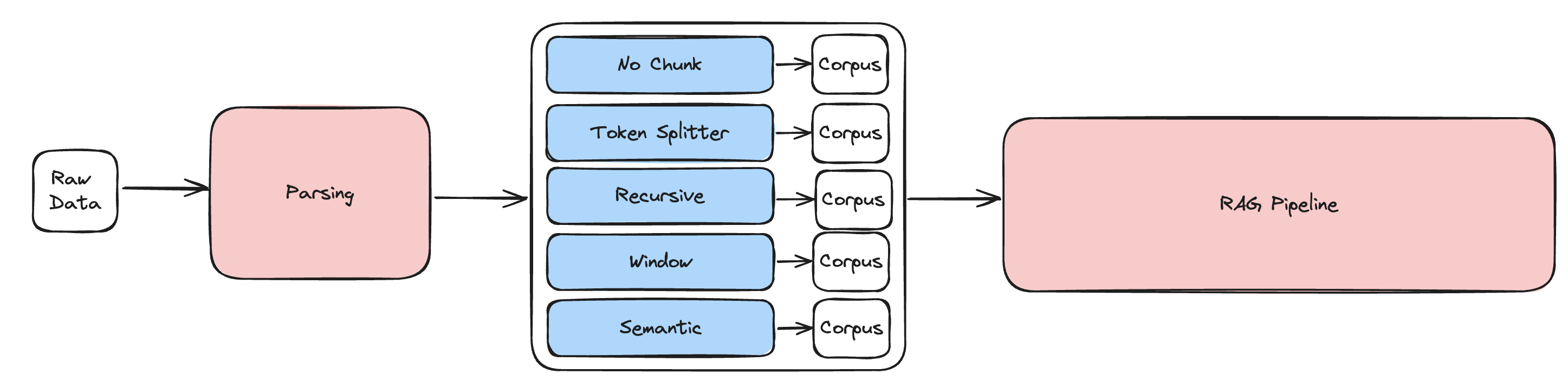
- 청킹은 RAG에서 자주 사용되는 5가지 청킹 방법을 실험한다.
No Chunk: PDF 파일을 페이지 단위로만 잘라서 파싱Token Splitter: 토큰 단위로 자르고, overlapRecursive: 한번 청킹한 것을 다시 더 잘게 청킹하여 검색 성능을 높임Window: 잘게 잘라서 검색성능을 높인 뒤, LLM에 들어갈 때 단락에 window(맥락 정보)를 함께 제공Semantic(openai embedding): 임베딩 모델로 의미론적으로 비슷한 단락끼리 묶음
-
성능 평가 지표는 G-Eval Consistency를 사용한다.
- G-Eval Consistency가 더 궁금하다면?
=> LLM은 얼마나 일관적으로 평가할까?
- G-Eval Consistency가 더 궁금하다면?
-
AutoRAG를 사용해서 실험을 진행한다.
세부 파라미터 정보
혹시 실험에 더 궁금증이 있는 분들을 위해 실험에 사용한 청킹 모듈들의 세부 정보를 공유하려고 한다.
1, 2, 4, 5번 모듈은 라마인덱스의 모듈을 사용했고, 3번은 랭체인의 모듈을 사용했다!
- No Chunk
- Token Splitter
chunk_size: 1024chunk_overlap: 24
- Recursive
- Window
window_size: 3
- Semantic
embed_model: openai
3. 실험 결과
| Score | |
|---|---|
| 1. No Chunk | 3.0769 |
| 2. Token Splitter | 3.2308 |
| 3. Recursive | 3.3077 |
| 4. Window | 3.3590 |
| 5. Semantic | 3.5128 |
다음과 같은 결과가 나왔다.
G-Eval의 스케일이 1~5점인 걸 감안했을 때, 생각했던 것 보다 점수 간의 차이가 크게 나왔다
G-Eval은 LLM이 평가하는 지표이기 때문에, 점수 차이가 난 질문들을 골라 직접 확인해 볼 필요가 있다고 느꼈다.
그래서 점수 차이가 난 17개의 질문을 골라서 다시 정성평가를 진행해보았다.
정성평가 기준
평가 기준은 다음과 같이 잡았다
-
1점: 정확하게 대답했을 때 -
0.5점: 애매할 때 -
0점: 모른다고 대답했을 때 -
-1점: 환각증상을 보였을 때
RAG에서는 차라리 모른다고 하는 게 틀린 답을 얘기하는 것 보다 중요하다고 생각해, 다음과 같은 기준으로 정성평가를 해보았다.
정성평가 결과
| No Chunk | Token | Recursive | Window | Semantic | |
|---|---|---|---|---|---|
| 1 | 11 | 11 | 12 | 12 | 13 |
| 0.5 | 0 | 2 | 0 | 0 | 3 |
| 0 | 1 | 3 | 1 | 3 | 0 |
| -1 | 5 | 1 | 4 | 2 | 1 |
| 평균 | 0.3529 | 0.6471 | 0.4706 | 0.5882 | 0.7941 |
| G-Eval 평균 | 2.4706 | 3.3529 | 3.1176 | 3.3529 | 3.7647 |
4. 결과 해석
No Chunk에 비해 모든 청킹이 유의미한 성적 향상을 보였다.- ‘G-Eval Consistency’가 같은 대답이라도 최대 0.15점까지는 튀는 걸 감안하더라도 모든 청킹이 유의미한 성적 향상을 보였다.
- 특히 임베딩 모델을 사용하는
Semantic청킹은 다른 청킹 방법들에 비해서도 높은 성적을 보였다- 다만,
Semantic청킹은 다른 청킹에 비해 오래 걸린다.- 코퍼스 만드는 데 걸린 시간:
- 나머지 다른 청킹 (3~10초)
Semantic청킹 (9분)
- 코퍼스 만드는 데 걸린 시간:
- 임베딩모델로 OpenAI를 사용해 유료이기도 하다.
- 다만,
5. 결론
실험에 사용한 질문 데이터가 40개 뿐이었고, 정성평가는 17개만으로 평가했기 때문에 비판적으로 결과를 바라봐야 한다.
하지만, '청킹은 한국어 RAG의 답변 성능에 얼마나 영향을 미칠까?' 라는 의문에서 시작한 이 실험에서 '한국어 RAG 답변 성능에 꽤 많은 영향을 미칠 수 있겠다.' 정도의 답을 얻기에는 충분했다고 생각한다.
